






 本文介绍了如何通过API进行通用文字识别,包括获取API凭据、调用过程中的JSON返回结构,以及在处理网络图片时的注意事项,如错误码解析和文件上传要求。
本文介绍了如何通过API进行通用文字识别,包括获取API凭据、调用过程中的JSON返回结构,以及在处理网络图片时的注意事项,如错误码解析和文件上传要求。
一. API调用
 在工作台中右上角点击获取机器人,进入产品市场,可以看到所有支持识别的类型,这里以通用文字识别为例,点进去后可以发现新用户有免费的1000次额度。
在工作台中右上角点击获取机器人,进入产品市场,可以看到所有支持识别的类型,这里以通用文字识别为例,点进去后可以发现新用户有免费的1000次额度。
然后点击API文档查看详细使用说明及示例代码
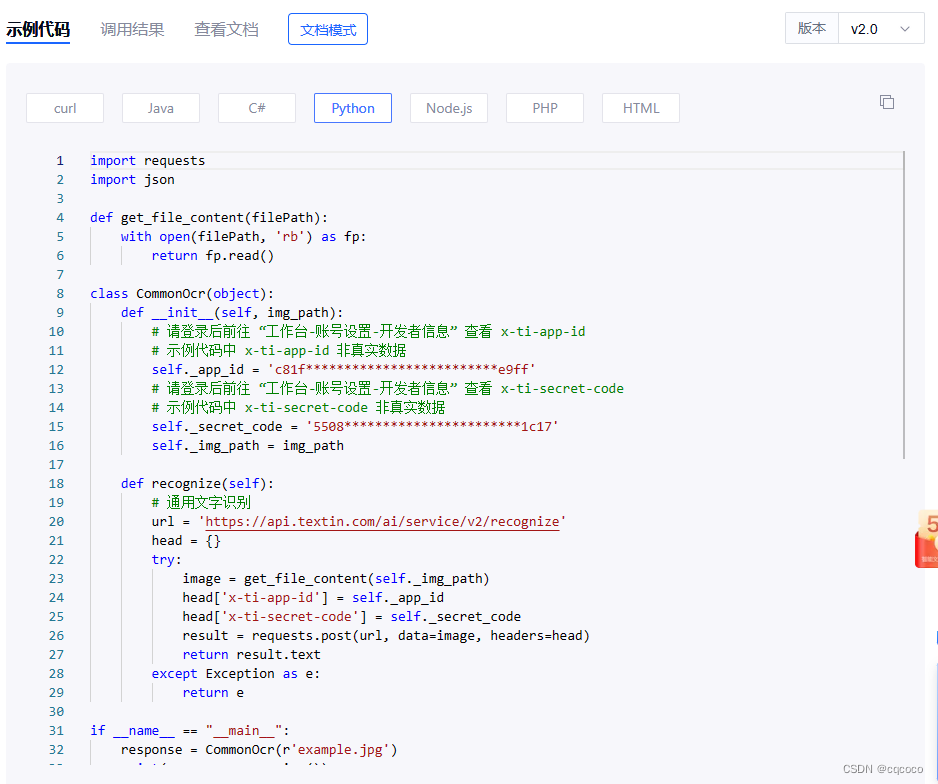
CommonOcr类中的id和和secret_code输入自己的Id和密码,即可实现API调用,非常简单
二. 获取文本
返回的是JSON类型,如下所示
{
"code": 200,
"message": "success",
"version": "v2.0.0",
"duration": 871.5,
"result": {
"angle": 90,
"width": 1280,
"height": 1440,
"lines": [
{
"text": "这是一个例子。",
"score": 0.99,
"type": "text",
"position": [
0,
0,
50,
0,
50,
30,
0,
30
],
"angle": 90,
"direction": 1,
"handwritten": 1,
"char_scores": [
0.99,
0.98,
0.95,
0.95,
0.99,
0.93,
0.87
],
"char_centers": [
[
20,
10
],
[
30,
10
],
[
40,
10
],
[
50,
10
],
[
60,
10
],
[
70,
10
],
[
80,
10
]
],
"char_positions": [
[
18,
8,
22,
8,
22,
12,
18,
12
],
[
28,
88,
32,
8,
32,
12,
28,
12
],
[
38,
88,
42,
8,
42,
12,
38,
12
],
[
48,
88,
52,
8,
52,
12,
48,
12
],
[
58,
88,
62,
8,
62,
12,
58,
12
],
[
68,
88,
72,
8,
72,
12,
68,
12
],
[
78,
88,
82,
8,
82,
12,
78,
12
]
],
"char_candidates": [
[
"这"
],
[
"是"
],
[
"一",
"-"
],
[
"个"
],
[
"例"
],
[
"子"
],
[
"。",
"O"
]
],
"char_candidates_score": [
[
0.99
],
[
0.99
],
[
0.95,
0.05
],
[
0.99
],
[
0.99
],
[
0.99
],
[
0.89,
0.11
]
]
}
]
}
}其中大部分是无用信息,只有text是我们要的识别内容字符串,为了获取其中的内容,可以执行以下代码:
ans = CommonOcr(img).recognize()
# 将识别的文字转换为字典
data = json.loads(ans)
# 从结果中提取文字
text_list = [line["text"] for line in data["result"]["lines"]]text_list就是我们要的字符串了,其余参数可以在文档里查看详细介绍
三. 避坑
有时候我们不是传入本地图片,而是传入url,我们如果直接调用request,然后用PIL的Image读取会产生报错,这是因为请求体的数据格式为文件的二进制流。解决办法是创建一个临时文件,将字节对象写进临时文件上传读取,具体代码如下:
import requests
from io import BytesIO
import json
from tempfile import NamedTemporaryFile
# 定义一个函数来识别图片上的文字
def recognize_text(image_url):
# 发送GET请求到图片URL
response = requests.get(image_url)
# 检查请求是否成功
if response.status_code == 200:
# 使用BytesIO将响应内容转换为字节对象
image_bytes = BytesIO(response.content)
# 创建一个临时文件
with NamedTemporaryFile(delete=False) as tmp_file:
# 将字节对象写入临时文件
tmp_file.write(image_bytes.read())
# 调用TextIn API来识别文字
ans = CommonOcr(tmp_file.name).recognize()
# 将识别的文字转换为字典
data = json.loads(ans)
# 从结果中提取文字
text_list = [line["text"] for line in data["result"]["lines"]]
# 返回识别到的文字列表
return text_list
else:
# 如果请求失败,返回一个错误信息
return f"获取图片失败,状态码:{response.status_code}"错误码说明
| 错误码 | 描述 |
| 40101 | x-ti-app-id 或 x-ti-secret-code 为空 |
| 40102 | x-ti-app-id 或 x-ti-secret-code 无效,验证失败 |
| 40103 | 客户端IP不在白名单 |
| 40003 | 余额不足,请充值后再使用 |
| 40004 | 参数错误,请查看技术文档,检查传参 |
| 40007 | 机器人不存在或未发布 |
| 40005 | 机器人未开通,请至市场开通后重试 |
| 40301 | 图片类型不支持 |
| 40302 | 上传文件大小不符,文件大小不超过 10M |
| 40303 | 文件类型不支持 |
| 40304 | 图片尺寸不符,图像宽高须介于 20 和 10000(像素)之间 |
| 40305 | 识别文件未上传 |
| 30203 | 基础服务故障,请稍后重试 |
| 500 | 服务器内部错误 |

















 3681
3681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









