







R语言的入门学习
本文首发在知识星球上(BrainTechnology星球),此文章中所有链接均通过博客进行访问。
本文学习主要为打卡内容使用,非教程。
内容来源:本学习教程来源在线网址:https://rlearning.netlify.app/
本学习内容课程大纲
Task00:熟悉规则与R语言入门(1天)
- 安装
- 环境配置
Task01 数据结构与数据集 (3天)
- 编码基础
- 数据类型
- 特殊数据类型
- table like 数据类型
- 加载数据 (csv, rds, excel, Rdata)
- 实例
Task02 数据清洗与准备 (3天)
- 重复值处理
- 缺失值识别与处理
- 异常值识别与处理
- 特征处理
- 规范化与偏态数据
Task03 基本统计分析 (3天)
- 多种方法获取描述性统计量
- 分组计算描述性统计
- 频数表和列联表
- 相关
- 方差分析
Task04 数据可视化(3天)
- ggplot2包介绍
- 散点图
- 直方图
- 柱状图
- 饼状图
- 折线图
- ggplot2扩展包主题
Task05 模型(3天)
- 回归模型
- 分类模型
本次学习根据课程大纲安排,将在2021年8月16日-2021年8月31日完成学习
Task00 R/Rstudio的安装
R语言下载网址:https://cloud.r-project.org/,R 语言是一门用于统计计算与绘图的编程语言和开源软件
RStudio下载网址:https://www.rstudio.com/products/rstudio/ 它包括一个控制台、语法突出显示的编辑器、直接执行代码的支持,以及用于绘图、历史记录、调试和工作区管理的工具。
对于安装过程,可百度进行。
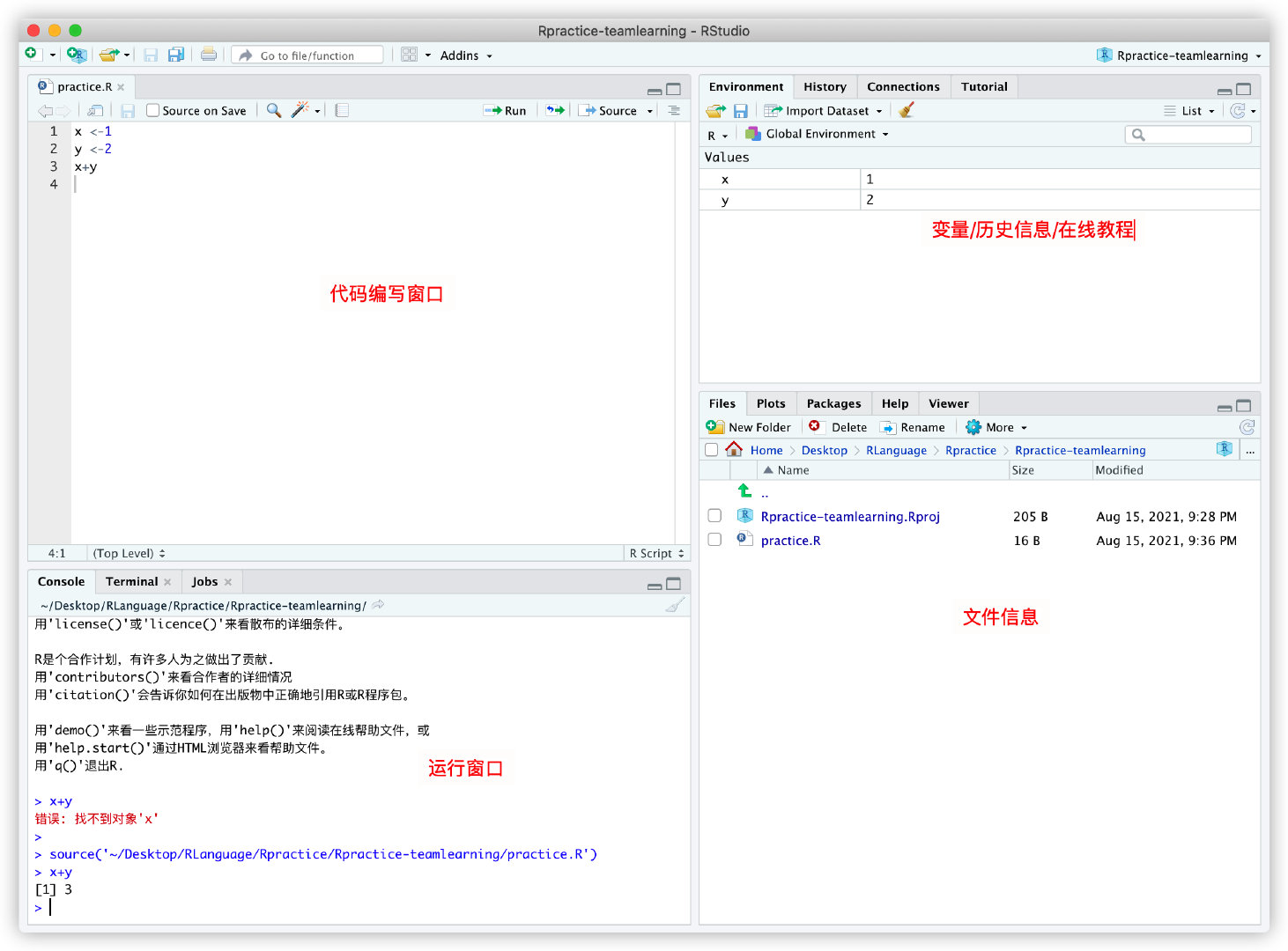
在console窗口中可查询包的用法信息,通过输入首字母然后可通过键盘按键Tab进行补全包的名称。
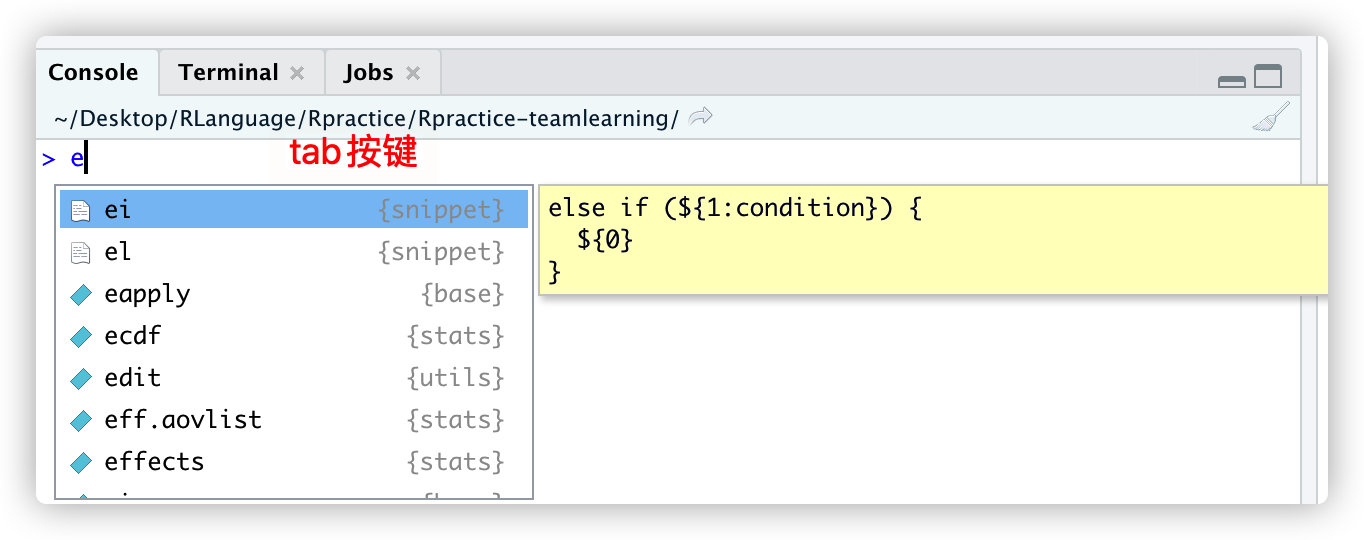
可通过在Console输入getwd()函数来获取当前工作路径
右下角图展示的当前项目中的文件数据等
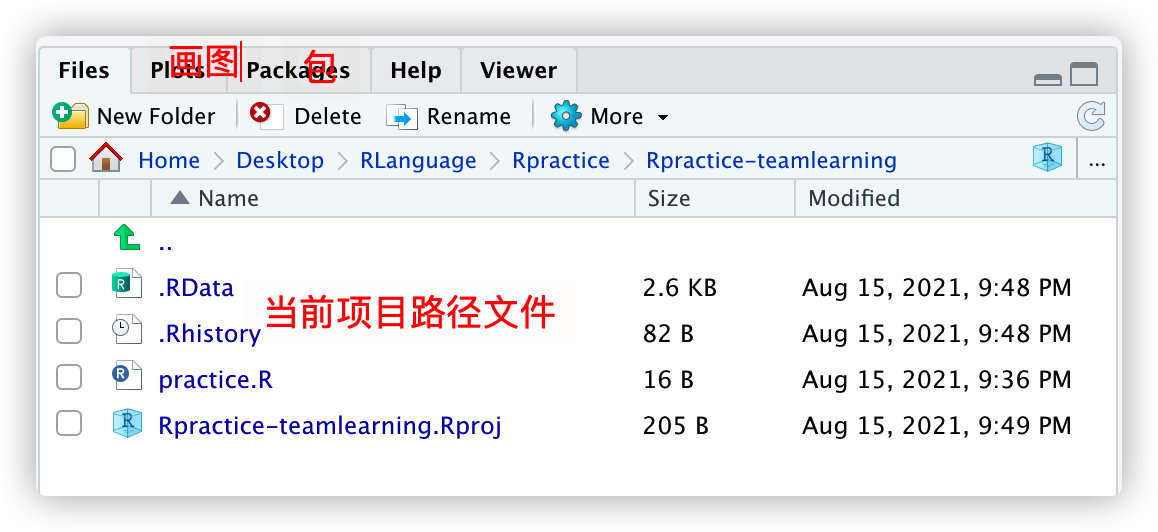
调整写代码的颜色主题:
Global Options-Appearance-RStudio Theme
快捷按键:
window:
control + 🔼 可一次性查询历史记录
alt+shift+k
MacOS:
Command + 🔼 可一次性查询历史记录
option+shift+k 查询所有快捷操作
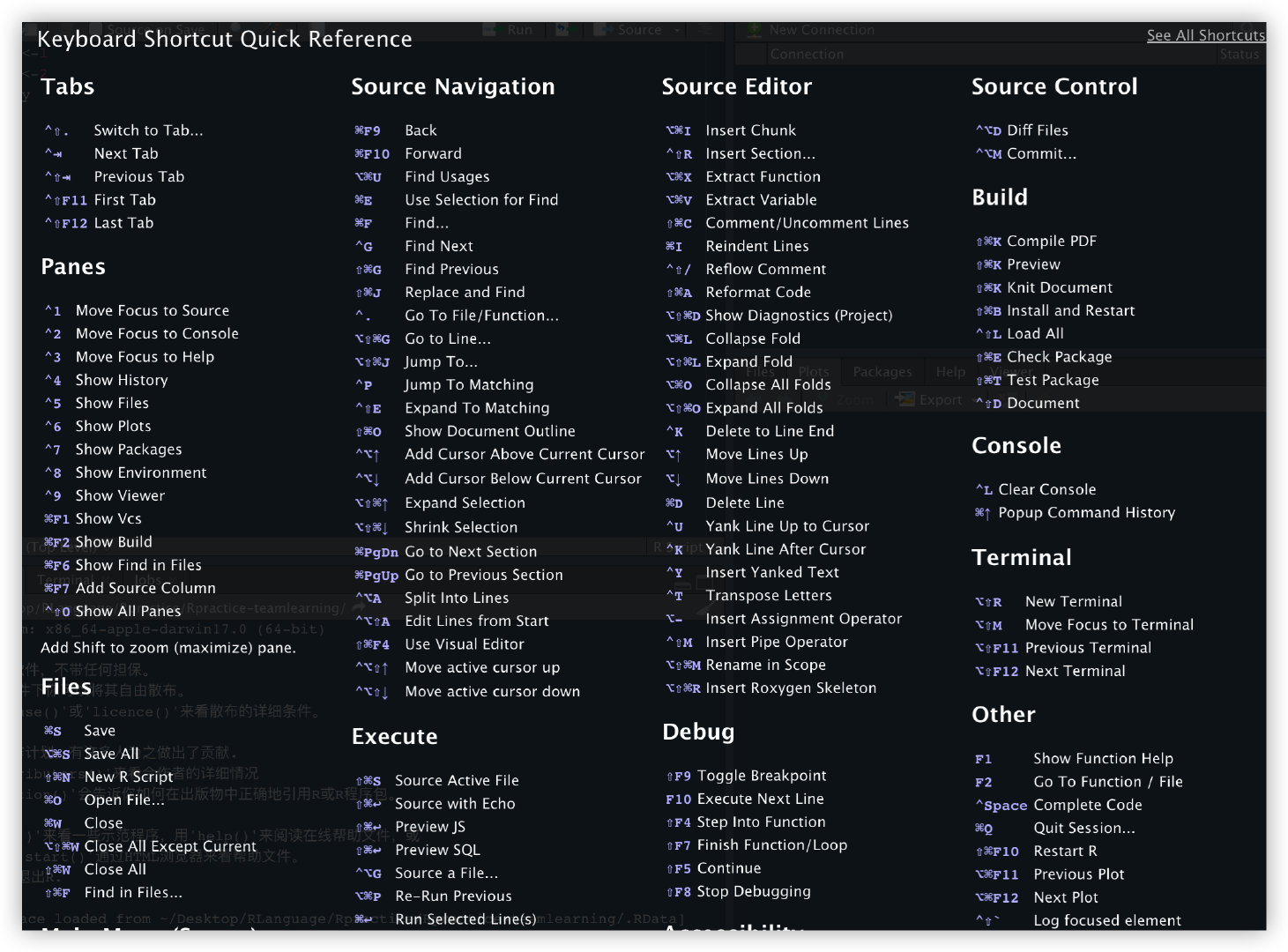
ESC中断语句进行
cltr + L清除console中的记录
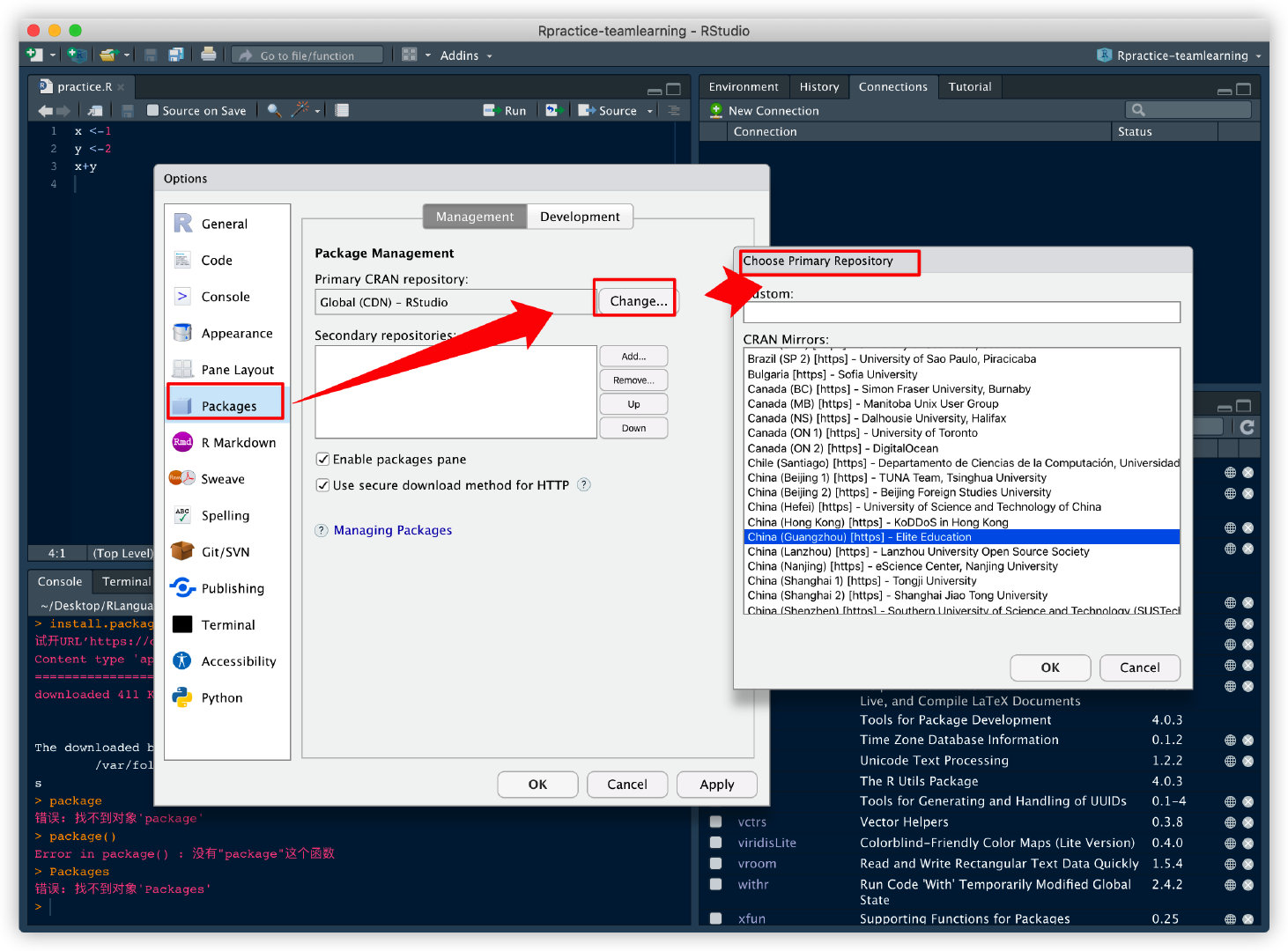
切换镜像源:
由于网速慢的原因,有时安装包会安装失败。
通过将包安装切换至中国镜像来解决:点【Tools】→【Global Options…】→【Packages】→【Change…】→【选中一个中国镜像】→【OK】→【OK】。如下图,以后安装包都会通过这个镜像。
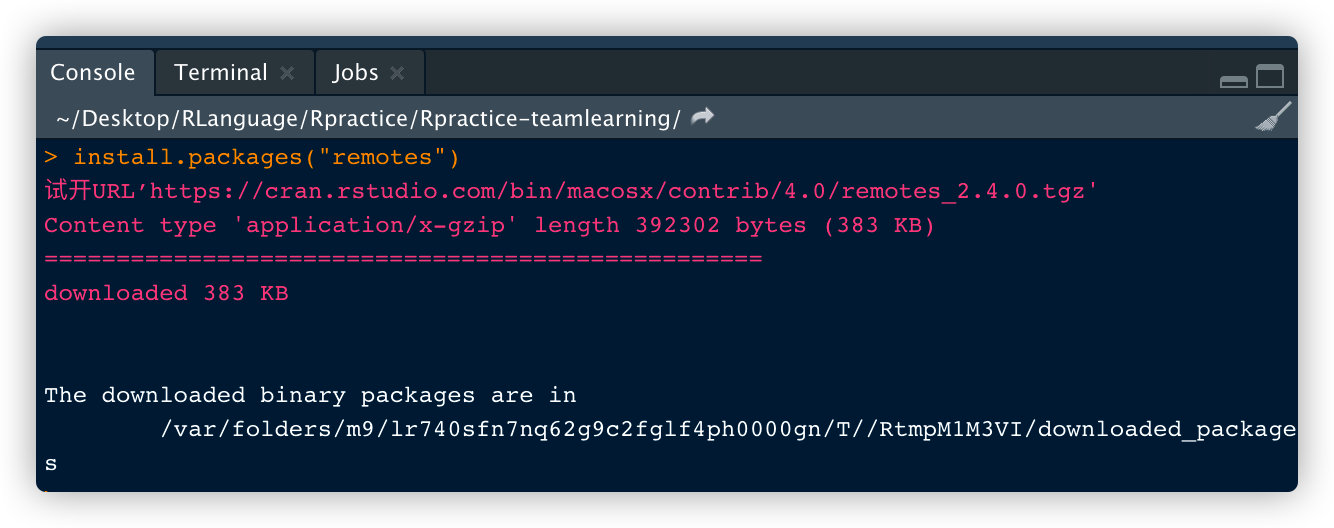
R包的安装:
在选中合适的镜像源后,可在console窗口,输入命令
在线安装:
install.packages("包名称")
离线安装:
下载好安装文件后,通过packages-install-选择安装路径

查看已安装的全部R包:
.packages(all.available = T)
查看单独的包:
library("包名")
Task01 数据结构与数据集
Getwd()获取路径
在 R Studio 中可以使用快捷键
window:
Alt + -来输入<-
Mac:
option + -来输入<-
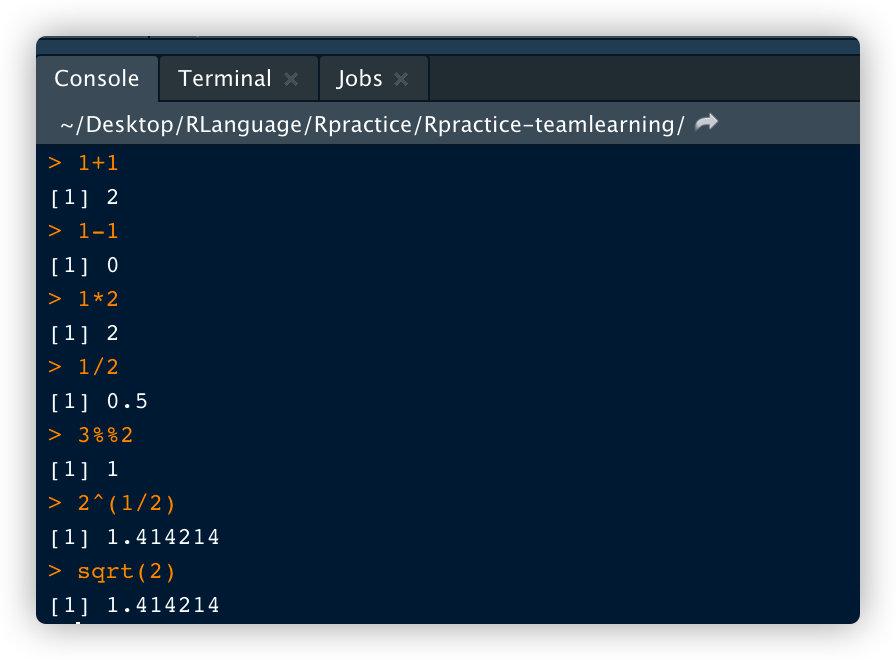
在R语言中的基础运算符号过程
赋值:
在 R 中基础赋值的符号有三种:
- 一个向左的箭头
<-表示将箭头右方的值取名叫做箭头左侧的名字,或者将箭头右侧的值存储在箭头左侧的名字里; - 一个向右的箭头
->表示将箭头左侧的值储存在箭头右侧的名字里; - 一个等号
=表示将箭头右侧的值存储在箭头左侧的名字里。
x <-1
y <-2
x+y
函数:其实就是某些功能的赋值,比如addone此时就是函数
addone <- function(x = 0) {
x + 1
}
loop循环:
R 中的循环函数包括for,while,和repeat
for用法:
for (variable in vector) {
}
在console窗口输入?for即可查找相关用法,或在help栏中输入也可
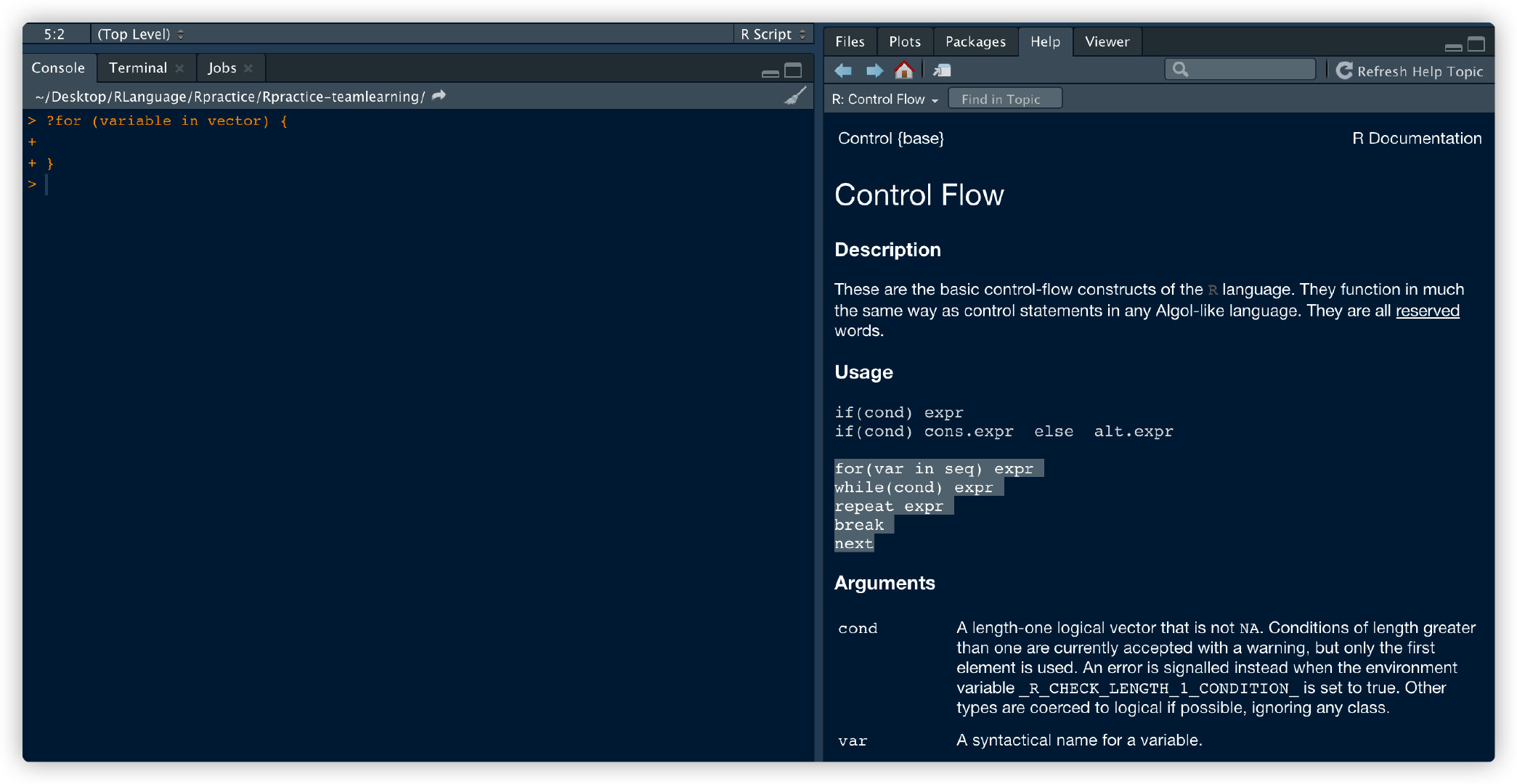
此处R中的loop用法跟Python中的很像,主要是条件的判断。
管道pipe:说起来就是简化函数的定义,能更方便的修改和识别函数。
可以参考此篇文章的解答:https://zhuanlan.zhihu.com/p/43423747和https://zhuanlan.zhihu.com/p/339107871
数据类型:
在R中有五种基础数据类型,包括三个数值型、一个逻辑型和一个字符型。
数值型数据包括三种,分别是默认的实数数值型数据(double)、整数类型(integer)和复数类型(complex):
#numeric
a<-1000.111
#integer
b<-1000
#complex
c<-2 + 3i
判断数值类型:
typeof()
逻辑型(logical)数据只包括两个值,TRUE(T) 和 FALSE(F):
字符型数据(character)可以总结为“任何带引号的值”。在Python中表示未字符串类型string
向量vector,向量是由一组相同类型的值组成的一维序列。vec_num <- c(1, 2, 3),在向量中可使用sum、mean等函数进行计算。sum(vec_num) = 6
因子(factor),可以使用函数factor和c组合来创建。它与字符向量的主要区别在于因子向量的独特值(levels)是有限个数的。
数值类型转换:
按照自由程度将已经提到的几种向量以从高到低的排序可得
字符>数值>逻辑
在数值型内的排序从自由度高到低为
复数>实数>整数
三种截取子集的符号:[、[[ 和 $(其中$不能用在基础向量上)
特殊数据类型
日期:处理的包(lubridata)
时间序列time series,首先要确保安装了forecast包
library(forecast)
gas %>%
auto.arima() %>%
forecast(36) %>%
autoplot()
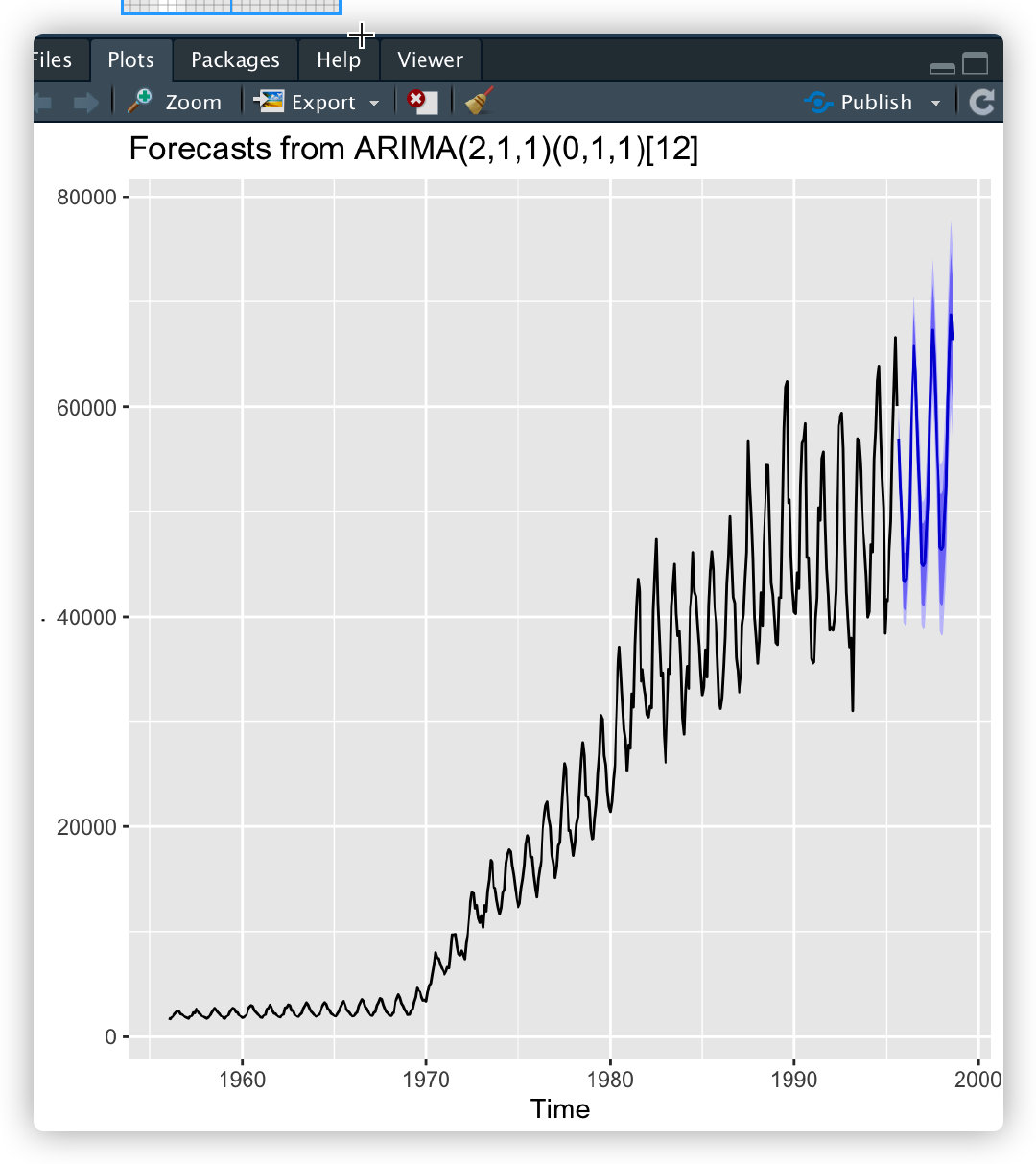
矩阵(matrix)
在R里,矩阵是一个按照长方阵列排列的、有着固定行数和列数的、包含同一类型数据的集合。可使用函数matrix
对于一个矩阵来说,主要的命名集中于行名rownames和列名colnames:
列表(list)
它和向量或者矩阵不一样,在一个列表中可以储存各种不同的基本数据类型。你既可以存三个数字,也可以把数值型、字符型、逻辑型混合
数据表(data frame与tibble)
一个数据表(data frame)的本质是一个列表(list)
内置数据集
使用data命令来查看、使用可用数据集
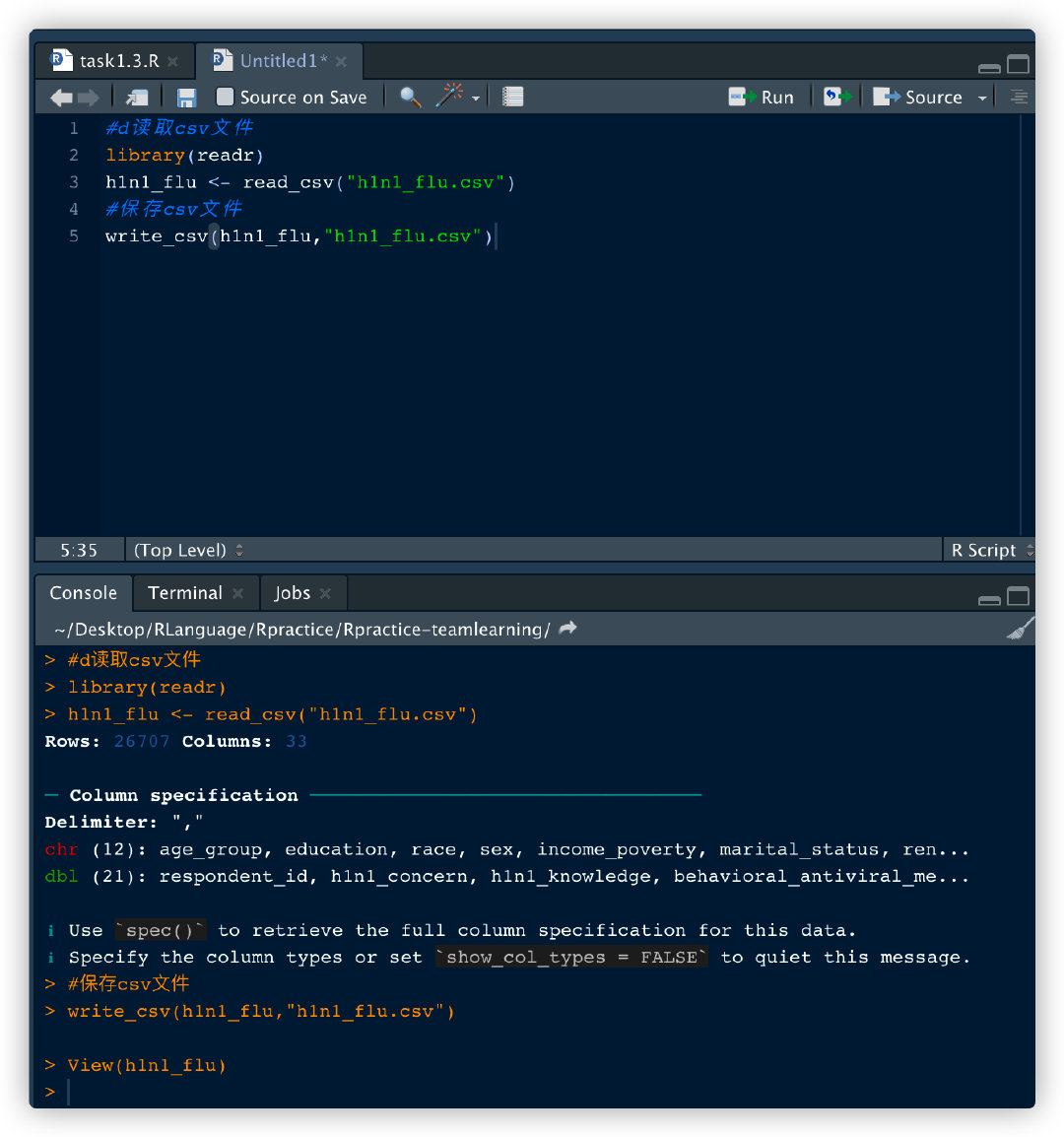
读取数据文件
# 读取csv文件
library(readr)
h1n1_flu <- read_csv("h1n1_flu.csv")
# 保存csv文件
write_csv(h1n1_flu, "h1n1_flu.csv")
R也可以直接读取其他软件的数据类型。这里列举使用haven包读写 SPSS 的 sav 和 zsav、 Stata 的 dta、SAS 的 sas7bdat 和 sas7bcat。
library(haven)
#SPSS
read_spss()
write_spss()
对于函数的介绍,可参考文章《R语言函数总结》
练习题
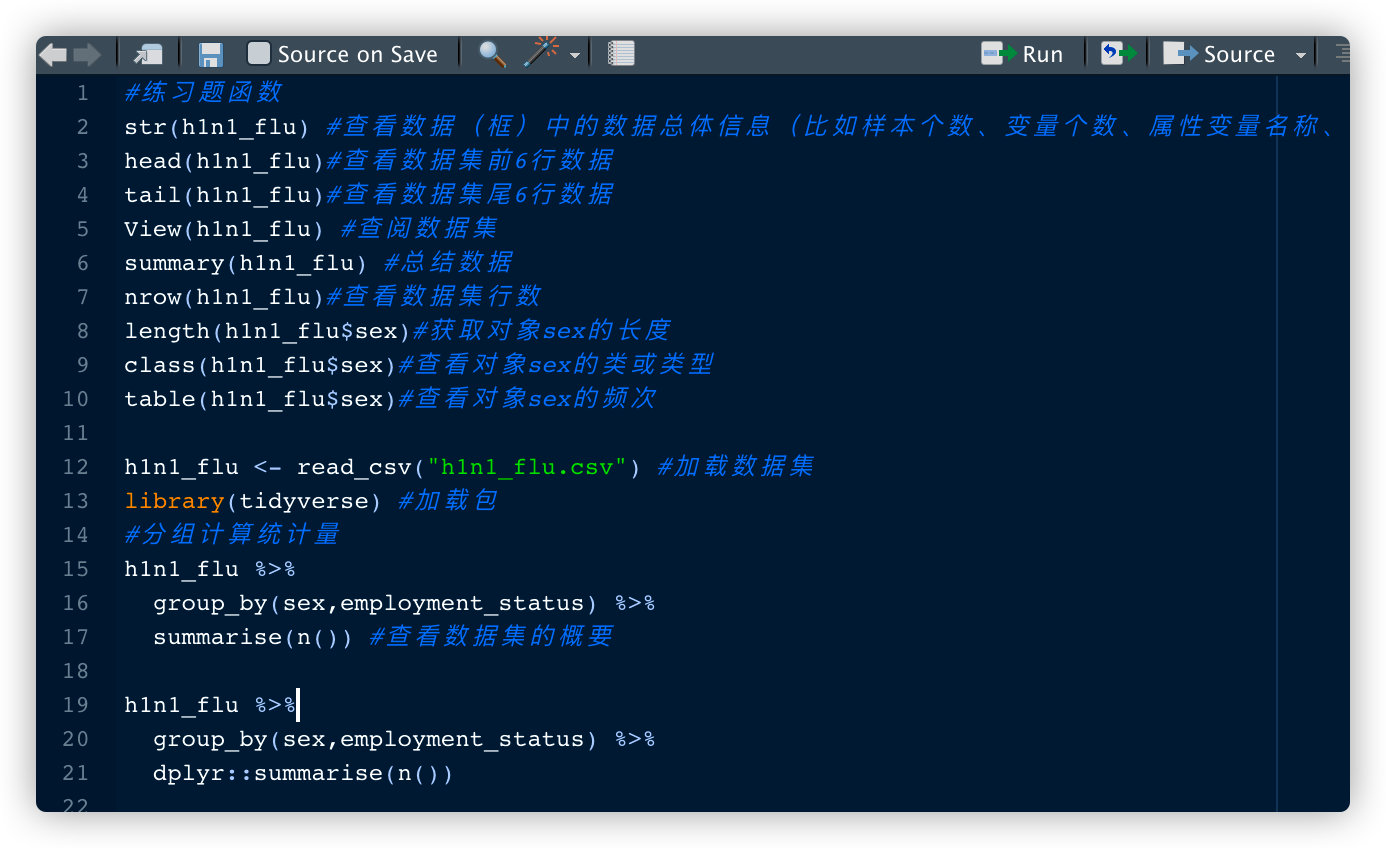
Task02 数据清洗与准备
这一章节有点难,需要花时间来琢磨。主要是对包的加载和使用其中的函数不了解。
环境配置(包加载)
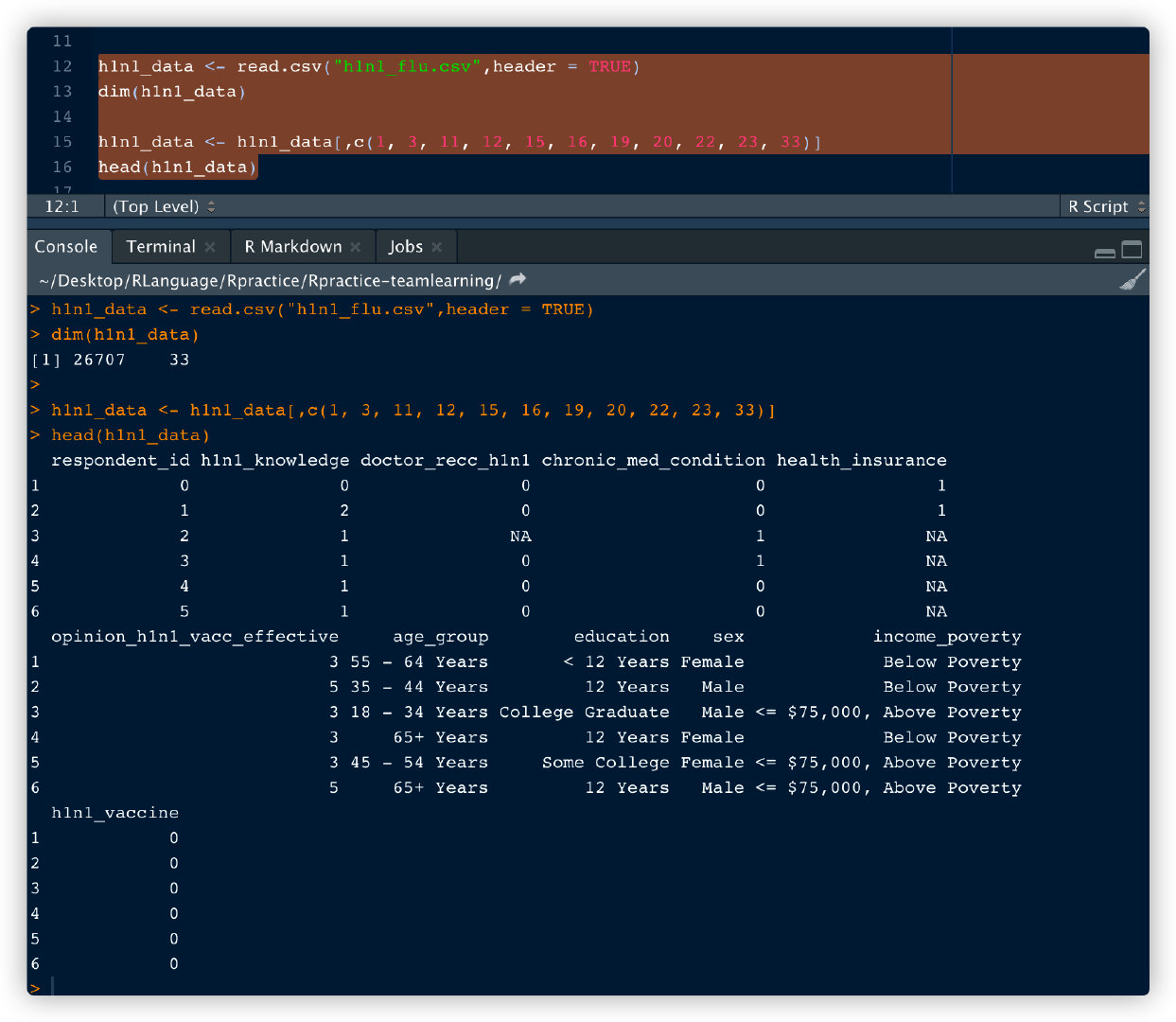
数据集1:加载数据(本地文件h1n1_flu.csv)和查看部分数据(从33个特征中筛选出10个特征用于后续处理)
h1n1_data <- read.csv("h1n1_flu.csv",header = TRUE)
dim(h1n1_data)
h1n1_data <- h1n1_data[, c(1, 3, 11, 12, 15, 16, 19, 20, 22, 23, 33)]
head(h1n1_data)
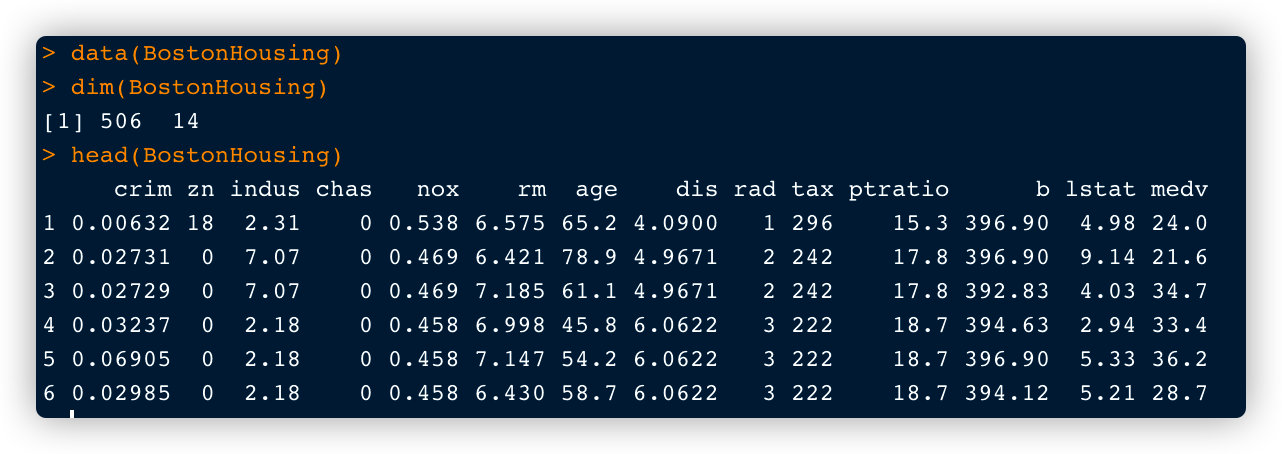
数据集2:波士顿房价数据集(mlbench包中)(13个特征+1个预测字段)
data(BostonHousing)
dim(BostonHousing)
head(BostonHousing)
重复值处理
unique()函数可以对数据进行整体去重,distinct()函数可以针对某些列去重。
# 整体去重
h1n1_data_de_dup1 <- unique(h1n1_data)
# 指定根据列respondent_id,h1n1_knowledge去重,并保留所有列
h1n1_data_de_dup2 <- distinct(h1n1_data, respondent_id, h1n1_knowledge, .keep_all = T)
缺失值识别和处理
常用方法:
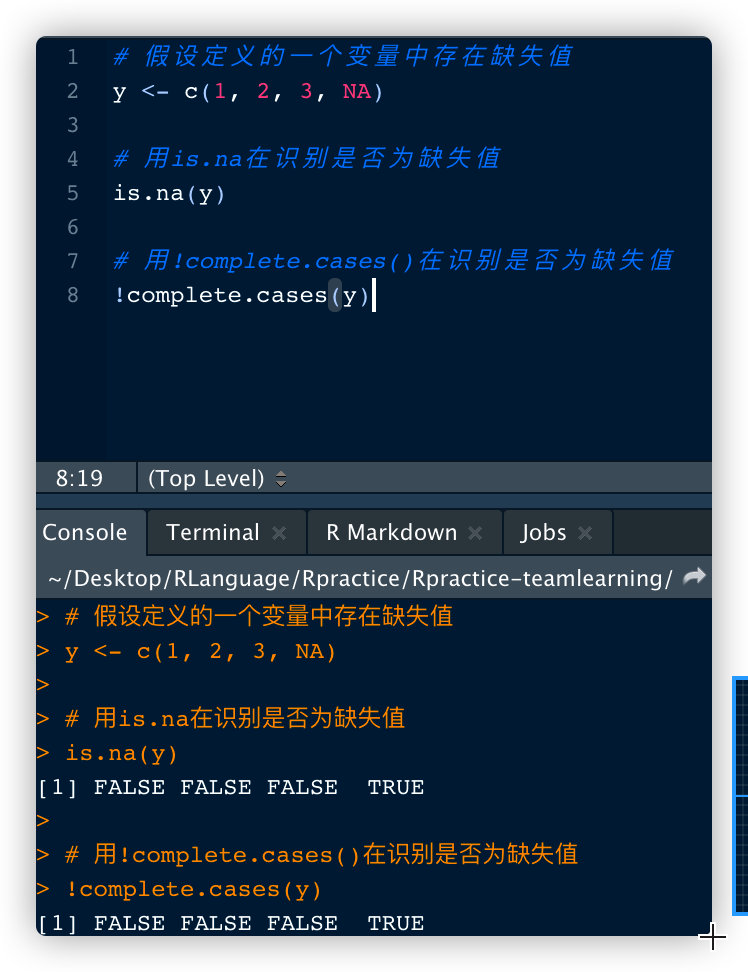
在R语言中,惯用会把缺失值表示为NA,一般可使用is.na(a),!complete.cases(a)来识别a是否为缺失值
# 假设定义的一个变量中存在缺失值
y <- c(1, 2, 3, NA)
# 用is.na在识别是否为缺失值
is.na(y)
# 用!complete.cases()在识别是否为缺失值
!complete.cases(y)
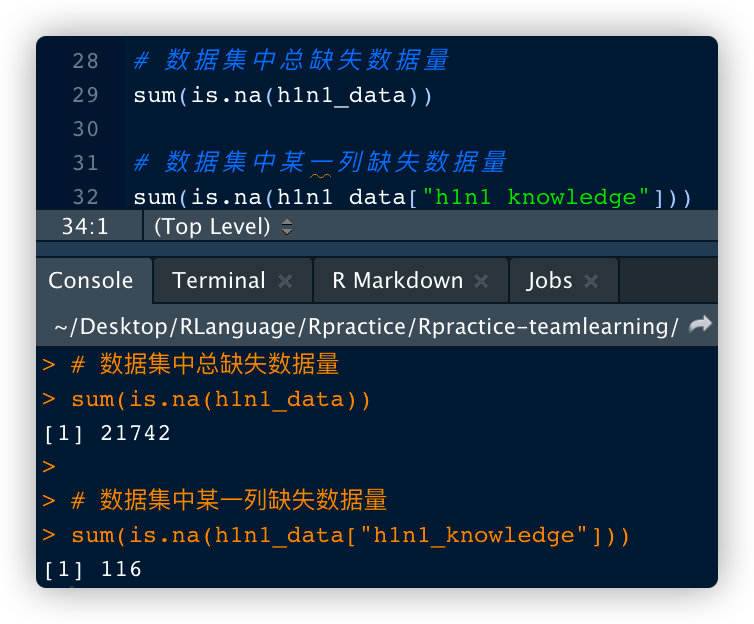
缺失值统计(使用is.na(x))
# 数据集中总缺失数据量
sum(is.na(h1n1_data))
# 数据集中某一列缺失数据量
sum(is.na(h1n1_data["h1n1_knowledge"]))
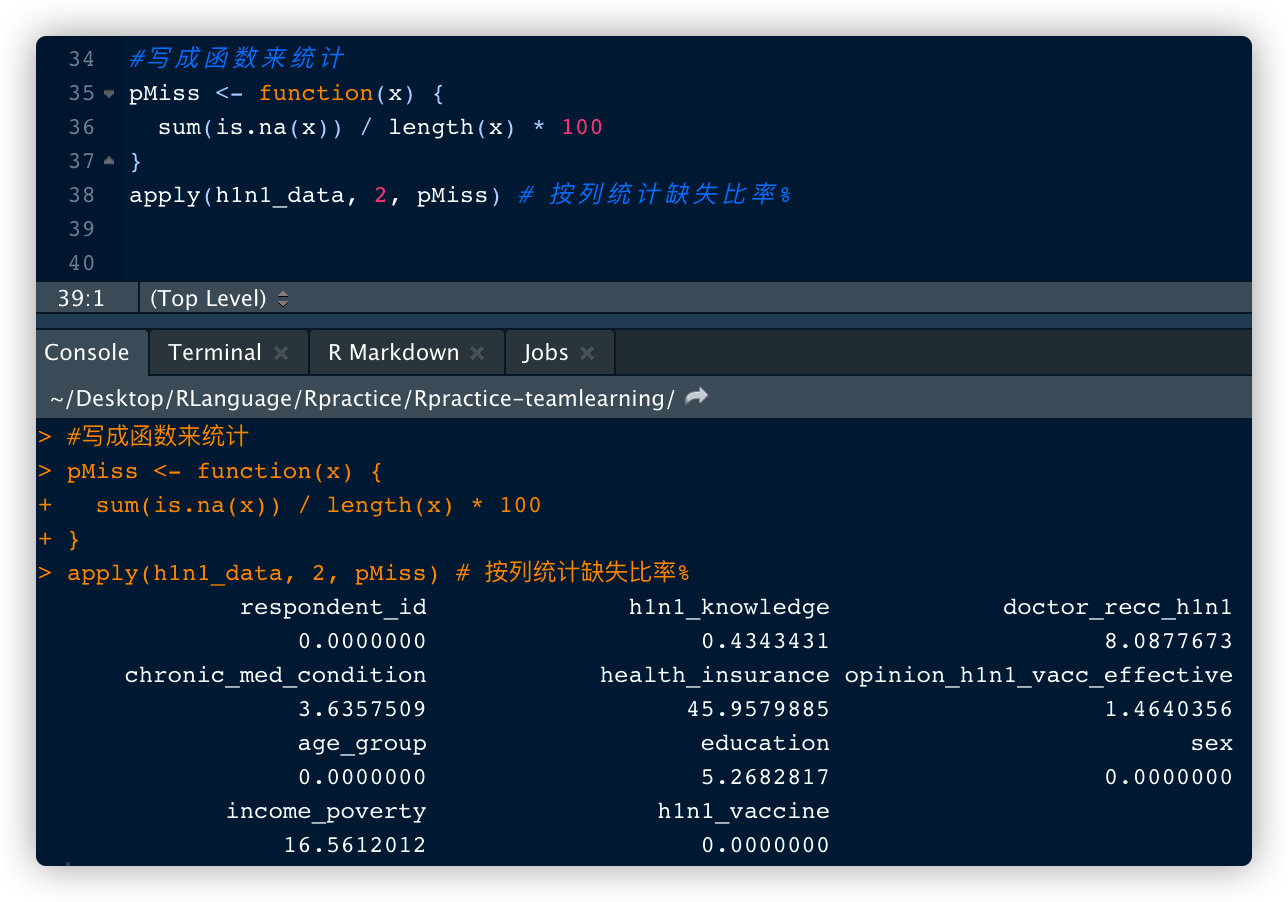
数据中某一行来统计。
pMiss <- function(x) {
sum(is.na(x)) / length(x) * 100
}
apply(h1n1_data, 2, pMiss) # 按列统计缺失比率%
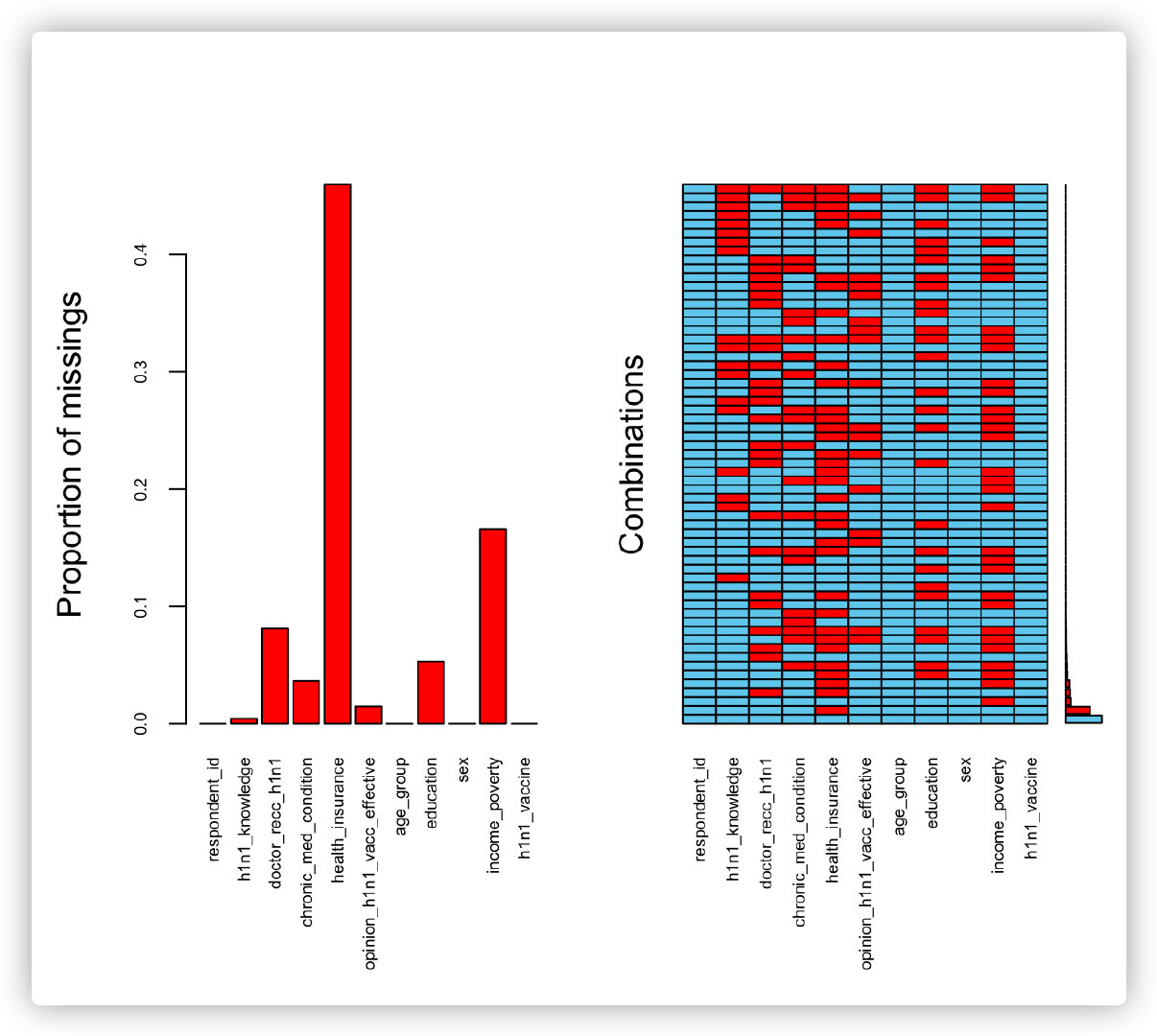
还可以 调用现成的包。
缺失值机制与分析:
分为完全随机缺失(MCAR),随机缺失(MAR)和非随机缺失(MNAR)
(1)完全随机缺失:缺失现象完全随机发生,与自身或其他变量的取值无关。
(2)随机缺失:缺失数据的发生与数据库中其他无缺失变量的取值有关。如果缺失和观测值之间存在系统关系,则为MAR
(2)非随机缺失:若缺失数据不属于MCAR和MAR,数据的缺失依赖于不完全变量本身,则数据为非随机缺失。
可视化分析缺失数据关联的方法:
使用VIM中的aggr函数:
# cex.axis调整轴字体大小,oma调整外边框大小
aggr(h1n1_data, cex.axis = .6, oma = c(9, 5, 5, 1))
# 先简单处理一下一些类别变量的顺序
h1n1_data_matplt <- h1n1_data
h1n1_data_matplt$age_group <- factor(h1n1_data_matplt$age_group)
h1n1_data_matplt$education <- factor(h1n1_data_matplt$education, levels = c("", "< 12 Years", "12 Years", "Some College", "College Graduate"))
h1n1_data_matplt$sex <- factor(h1n1_data_matplt$sex)
h1n1_data_matplt$income_poverty <- factor(h1n1_data_matplt$income_poverty, levels = c("18 - 34 Years", "<= $75,000, Above Poverty", "> $75,000"))
# levels(h1n1_data_matplt$age_group) # 查看顺序
# 矩阵图可视化
par(mar = c(9, 4.1, 2.1, 2.1)) # x轴标签太长,调用par()函数调整外边框的大小
matrixplot(h1n1_data_matplt, sortby = "chronic_med_condition", cex.axis = 0.7) # cex.axis为调整坐标轴字体大小
shadow_mat <- as.data.frame(abs(is.na(h1n1_data[, -1])))
head(shadow_mat)
# 可提取含缺失值的变量
shadow_mat <- shadow_mat[which(apply(shadow_mat, 2, sum) > 0)]
# 计算相关系数
cor(shadow_mat)
# 相关系数热力图
heatmap(cor(shadow_mat))
缺失值处理:
1.将缺失值作为变量值使用
2.删除法
3.插补法
教程介绍了删除和插补法:
1.删除法:
行删除使用函数:complete.cases()或na.omit()
h1n1_data_row_del1 <- h1n1_data[!complete.cases(h1n1_data), ]
h1n1_data_row_del2 <- na.omit(h1n1_data)
列删除:dataset[,-5]或 subset(dataset, select = -c(col1, col2))
#比如删除health_insurance
h1n1_data_col_del1 <- subset(h1n1_data, select = -c(health_insurance))
2.插补法:简单插补法、拟合插补法、多重插补法
还需要多查找资料了解:
多重插补法: 处理缺失值之多重插补(Multiple Imputation)https://zhuanlan.zhihu.com/p/36436260
异常值识别
识别:有几种常用方法,包括可视化图形分布识别(箱线图)、z-score识别、局部异常因子法(LOF法)、聚类法等。
z-score是一种一维或低维特征空间中参数异常检测方法。它假定数据是高斯分布,异常值是分布尾部的数据点,因此远离数据的平均值。一般将z-score低于-3或高于3的数据看成是异常值。
局部异常因子法(LOF),是一种无监督的离群检测方法,是基于密度的离群点检测方法中一个比较有代表性的算法。适用于在中等高维数据集上执行异常值检测。——来源学习教程
特征编码
特征编码其实在很多程序语言中都会使用到,它是对一类特征的一种归类,能更好的用于后续的数据处理。
1.独热编码/哑编码
One-hot encoding 和 dummy,是将类别变量扩充为多个只显示0,1的变量,每个变量代表原类别变量中的一个类。 ——来源学习教程
2.标签编码
标签编码(Label Encoder)是将类别变量转换成连续的数值型变量,通常对有序的变量进行标签编码,既保留了顺序信息,也节约了空间(不会扩充变量)
3.手动编码
即自定义编码,可以用特定的函数进行处理,比如case_when()
规范化与偏态数据
为什么要数据规范化?简单来说是为了去除数据量纲和数据大小的差异,确保数据是在同一量纲或者同一数量级下进行比较,一般用在机器学习算法之前。数据规范化又可以使用0-1规范化,Z-score等方法。
为什么要处理偏态数据?。很多模型会假设数据或参数服从正态分布。例如线性回归(linear regression),它假设误差服从正态分布。——来源学习教程
规范化的方法:
1.0-1规范化
2.Z-score标准化
3.对数转换(log transform)
4.Box-Cox
规范化: 规范化、标准化、归一化、正则化 https://blog.csdn.net/u014381464/article/details/81101551
附录:参考资料
理论资料
数据的预处理基础: 如何处理缺失值 https://cloud.tencent.com/developer/article/1626004
多重插补法: 处理缺失值之多重插补(Multiple Imputation)https://zhuanlan.zhihu.com/p/36436260
异常值检测: R语言–异常值检测 https://blog.csdn.net/kicilove/article/details/76260350
异常值检测之LOF: 异常检测算法之局部异常因子算法-Local Outlier Factor(LOF) https://blog.csdn.net/BigData_Mining/article/details/102914342
规范化: 规范化、标准化、归一化、正则化 https://blog.csdn.net/u014381464/article/details/81101551
什么样的模型对缺失值更敏感?: https://blog.csdn.net/zhang15953709913/article/details/88717220
R语言函数用法示例
funModeling用法示例:https://cran.r-project.org/web/packages/funModeling/vignettes/funModeling_quickstart.html
tidyverse官方文档:https://www.tidyverse.org/
VIM教学网页:https://www.datacamp.com/community/tutorials/visualize-data-vim-package
mice使用文档(Multivariate Imputation by Chained Equations):https://cran.r-project.org/web/packages/mice/mice.pdf
mice使用中文解释:https://blog.csdn.net/sinat_26917383/article/details/51265213
mice检验结果解释:http://blog.fens.me/r-na-mice/
caret包数据预处理:https://www.cnblogs.com/Hyacinth-Yuan/p/8284612.html
R语言日期时间处理:https://zhuanlan.zhihu.com/p/83984803
基于R语言进行Box-Cox变换:https://ask.hellobi.com/blog/R_shequ/18371
R中数据集分割:https://zhuanlan.zhihu.com/p/45163182
Task03 基本的统计分析
准备工作,下载所需包
install.packages("pastecs")
install.packages("psych")
install.packages("ggm")
本节内容主要在代码实现统计方法,本章节还需要多补充写统计方法的原理介绍。
#加载包
library(pastecs)
library(psych)
library(ggm)
#读取数据文件
flu <- read.table("h1n1_flu.csv", header = TRUE, sep = ",")
housing <- read.csv("BostonHousing.csv", header = TRUE)
#通过summary函数计算max,min,mean,median
summary(flu[c("household_children", "sex")])
summary(flu[c("h1n1_concern", "h1n1_knowledge")])
#通过sapply()计算描述性统计
mystats <- function(x, na.omit = FALSE) {
if (na.omit) {
x <- x[!is.na(x)]
}
m <- mean(x)
n <- length(x)
s <- sd(x)
skew <- sum((x - m)^3 / s^3) / n
kurt <- sum((x - m)^4 / s^4) / n - 3
return(c(n = n, mean = m, stdev = s, skew = skew, kurtosis = kurt))
}
sapply(flu[c("h1n1_concern", "h1n1_knowledge")], mystats)
#拓展包
#pastecs包中的 stat.desc()函数计算描述性统计量
stat.desc(flu[c("household_children", "sex")])
#通过psych包中的describe()计算描述性统计量
describe(flu[c("household_children", "sex")])
#分组计算描述性统计
#使用aggregate()分组获取
#分组计算不同性别
aggregate(flu[c("income_poverty")], by = list(sex = flu$sex), length)
#房价的中位数
aggregate(housing$medv, by = list(medv = housing$chas), FUN = mean)
#使用by()分组计算
by(flu[c("income_poverty", "sex")], flu$sex, length)
#频数表和列联表
table(flu$sex)
#相关计算
#相关类型:包括Pearson相关系数、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(polychoric)相关系数和多系列(polyserial)相关系数
#计算房价数据的相关系数,默认是Pearson相关系数。
cor(housing)
#指定计算Spearman相关系数
cor(housing, method = "spearman")
#城镇人均犯罪率与房价的相关系数
x <- housing
y <- housing[c("medv")]
cor(x, y)
#偏相关
#可使用ggm包中的pcor()函数计算偏相关系数
#相关性的显著性检验
cor.test(housing[, c("crim")], housing[, c("medv")])
#方差分析
#方差分析(ANOVA)又称“变异数分析”或“F检验”,用于两个及两个以上样本均数差别的显著性检验。
#单因素方差分析
#检验查尔斯河对房价的影响
fit <- aov(housing$medv ~ housing$chas)
summary(fit)
#多因素方差分析
#查看因子对房价的影响
fit <- aov(housing$medv ~ housing$crim * housing$b)
summary(fit)
Task04 数据可视化
#生成pdf的文件保存
pdf("xxx.pdf")#打开某文件
plot(XXX)#画图
dev.off()#关闭语句
#生成png文件
png("xxx.png")#打开某文件
plot(XXX)#画图
dev.off()#关闭语句
#生成jpg文件
jpeg("xxx.jpg")#打开某文件
plot(XXX)#画图
dev.off()#关闭语句
#如果中文编码有问题,就添加encoding = "UTF-8"
ggplot2包
#安装
install.package("ggplot2")
ggplot2包的目标是提供一个全面的、基于语法的、连贯一致的图形生成系统,允许用户创建新颖的、有创新性的数据可视化图形。
ggplot2参考链接:
- https://ggplot2.tidyverse.org/reference/
- https://ggplot2-book.org/
- 知乎问题关于《如何使用ggplot2》
#读取流感数据集
#h1n1流感问卷数据集是关于h1n1流感问卷调查的一个数据,属于外部数据
#数据集包含26,707个受访者数据,共有32个特征+1个标签(是否接种h1n1疫苗)
h1n1_data <- read.csv("h1n1_flu.csv", header = TRUE)
#读取波士顿房价数据集
boston_data <- read.csv("BostonHousing.csv", header = TRUE)
散点图
在知乎上又发现一个R语言系列教程《R语言与统计分析》,
散点图通常是用来表述两个连续变量之间的关系。同时散点图中常常还会拟合一些直线,以用来表示某些模型。
#散点图
# 读取数据
boston_data <- read.csv("BostonHousing.csv", header = TRUE)
# 绘制简单的散点图 x轴选择的是lstat ,y轴选择的是medv
ggplot(data = boston_data, aes(x = lstat, y = medv)) + geom_point()
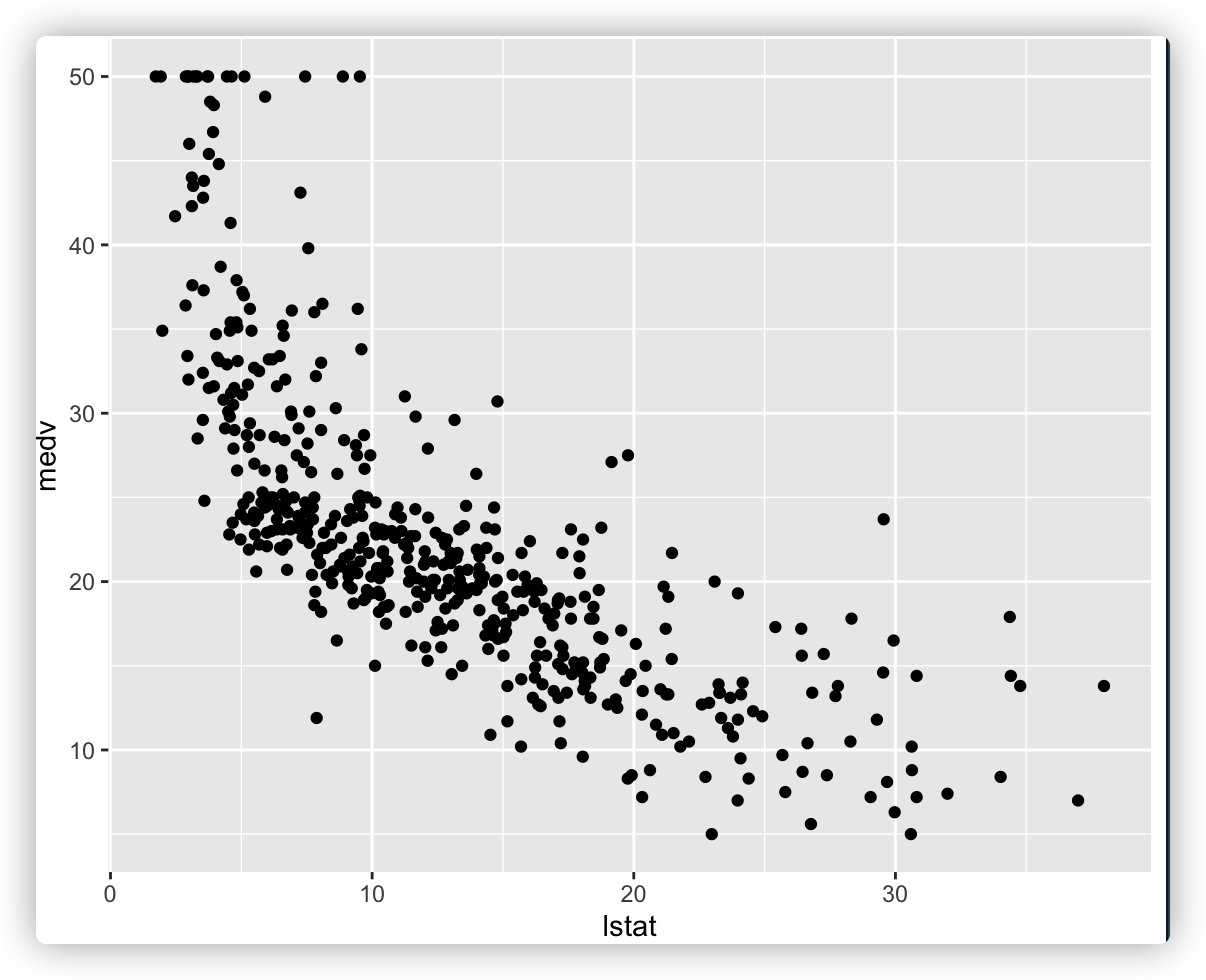
上图选择的是lstat为x轴,medv为y轴绘制的散点图,x轴表示弱势群体人口所占比例,y轴表示房屋的平均价格,通过图上的数据可以看到,弱势人群的比例增加会影响房价,这2个变量呈现一定的负相关。

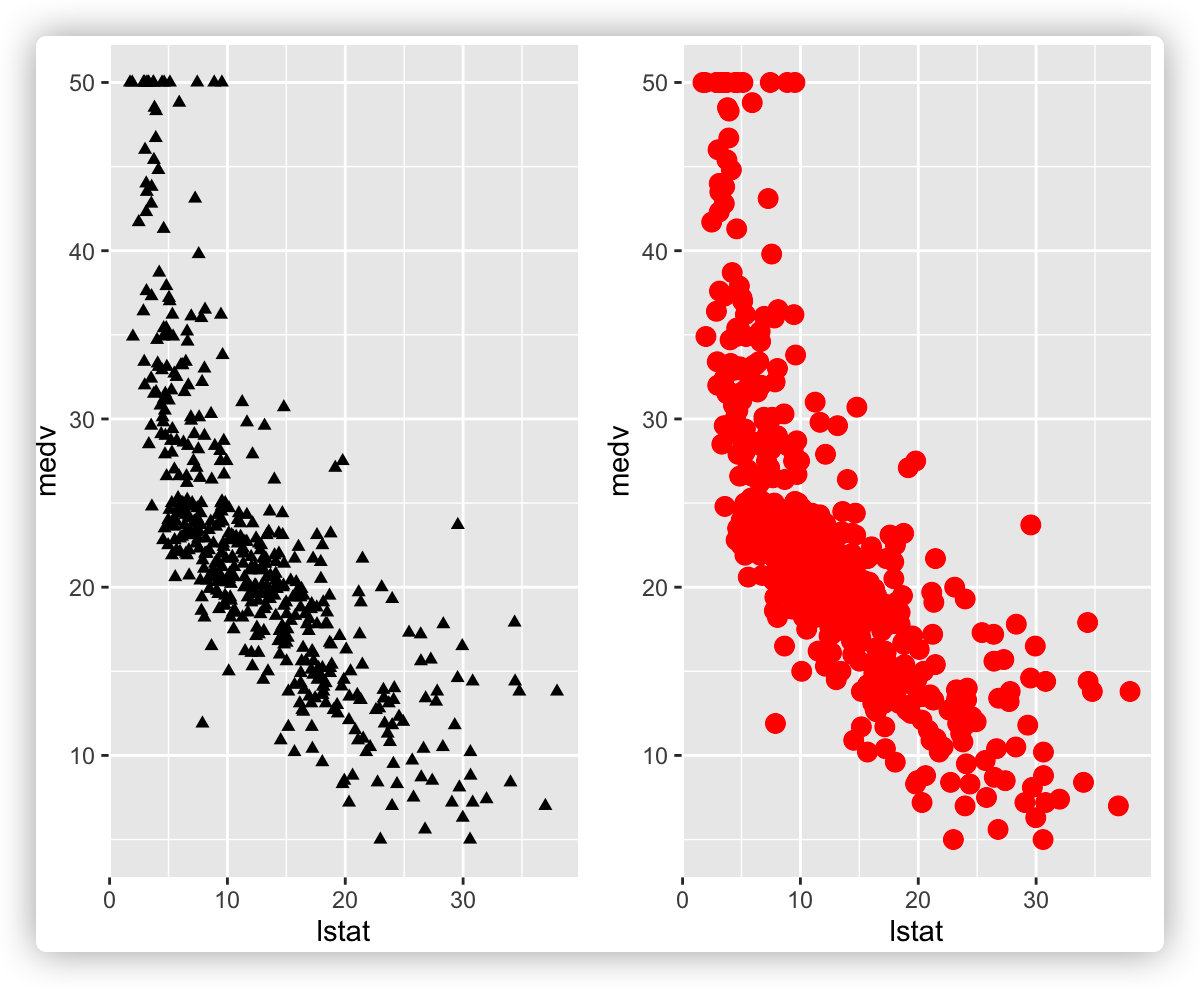
#size参数修改点的大小,color参数修改点的颜色
# 使用第17号形状
p1 <- ggplot(data = boston_data, aes(x = lstat, y = medv)) + geom_point(shape = 17)
# size参数修改点的大小,color参数修改点的颜色
p2 <- ggplot(data = boston_data, aes(x = lstat, y = medv)) + geom_point(size = 3, color = "red")
ggarrange(p1, p2, nrow = 1)
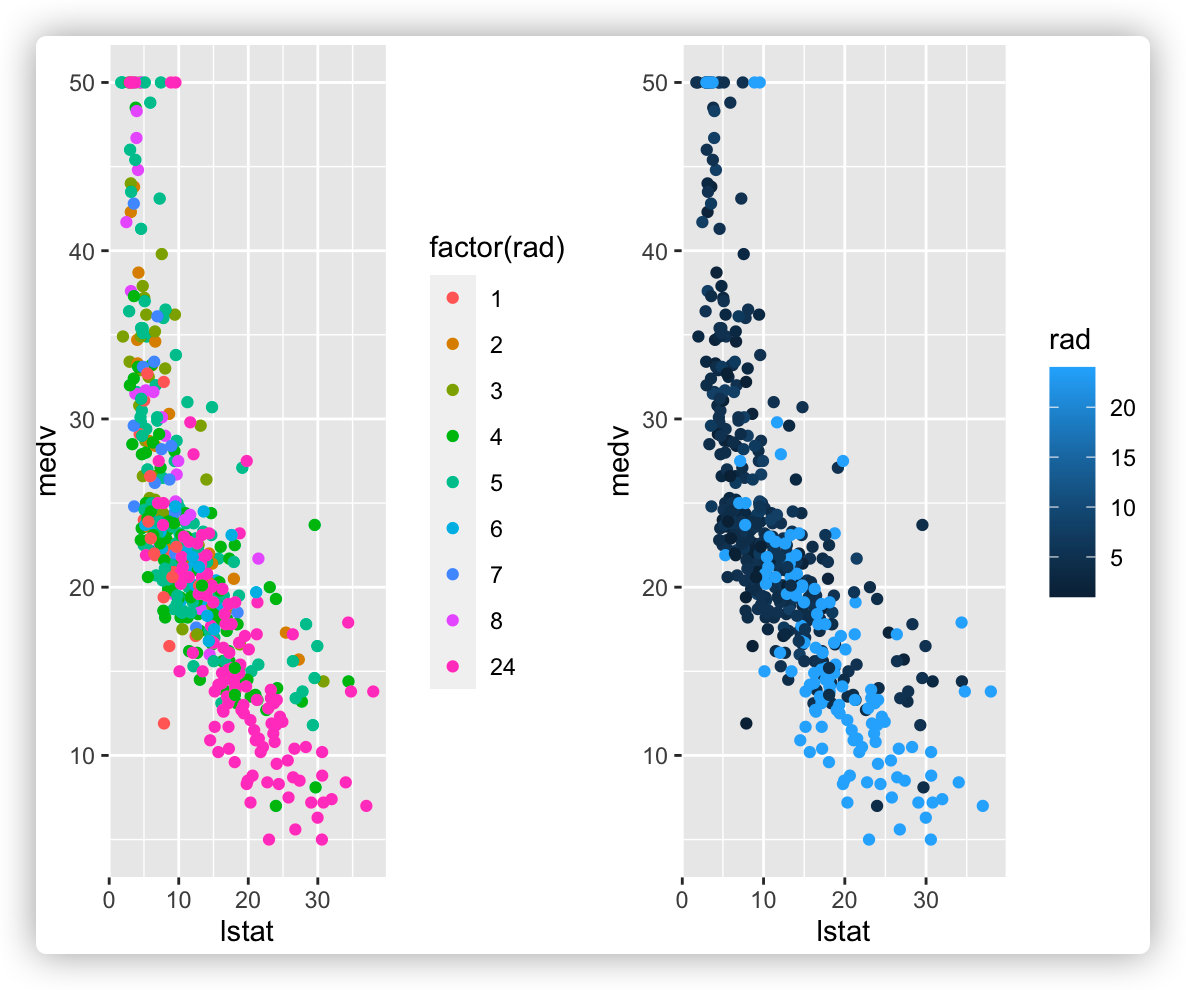
#映射到其它颜色上
p3 <- ggplot(data = boston_data, aes(x = lstat, y = medv, colour = factor(rad))) +
geom_point()
p4 <- ggplot(data = boston_data, aes(x = lstat, y = medv, colour = rad)) +
geom_point()
ggarrange(p3, p4, nrow = 1)
ggplot2关于散点图详细介绍,参考链接:https://ggplot2.tidyverse.org/reference/geom_point.html
直方图
直方图的RGB网址:http://www.mgzxzs.com/sytool/se.htm
#直方图
#rad变量作图
ggplot(data = boston_data, aes(x = rad)) + geom_histogram()
#对颜色进行变化
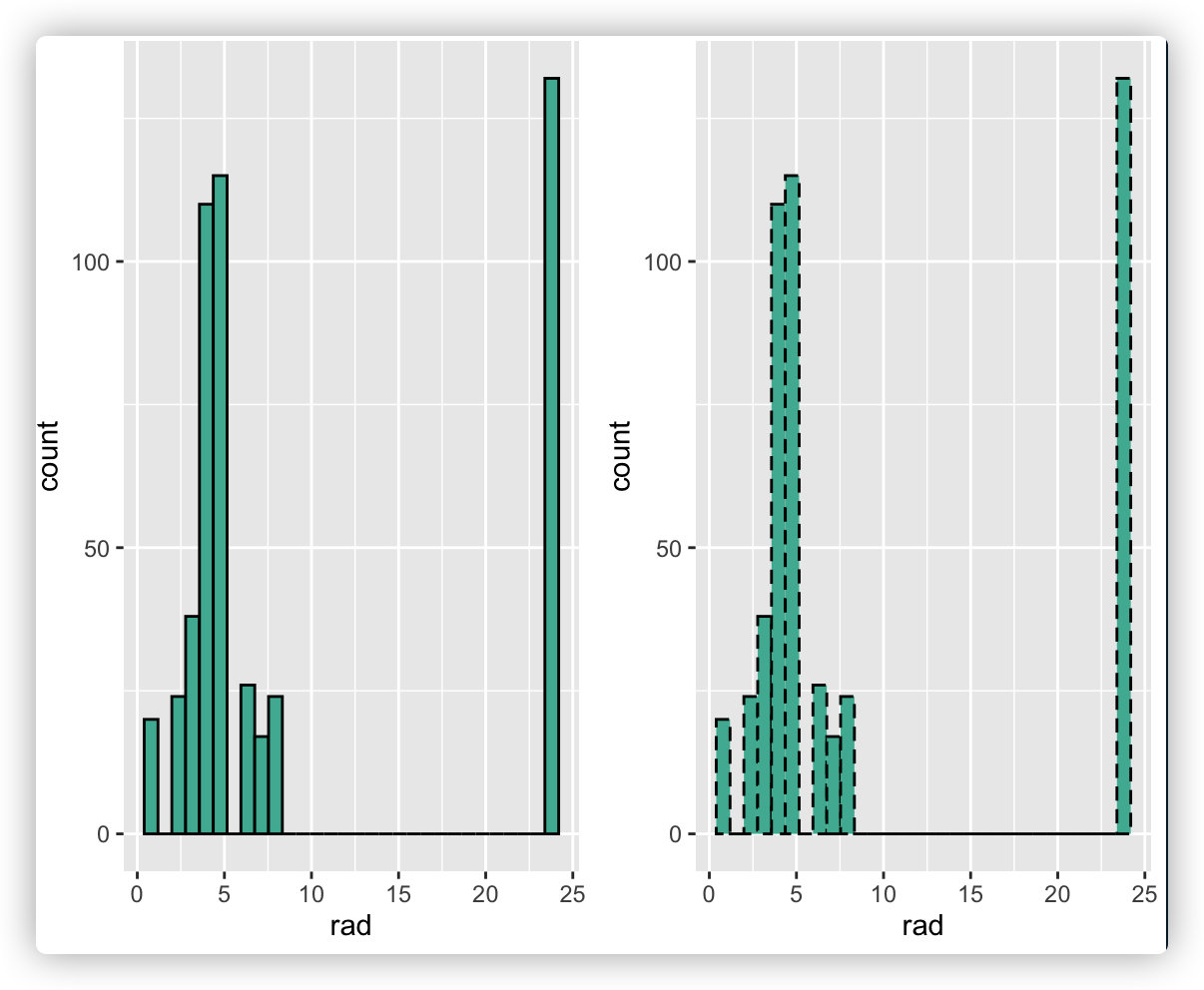
p5 <- ggplot(data = boston_data, aes(x = rad)) + geom_histogram(color = "black", fill = "#69b3a2")
p6 <- ggplot(data = boston_data, aes(x = rad)) + geom_histogram(color = "black", fill = "#69b3a2", linetype = "dashed")
ggarrange(p5, p6, nrow = 1)
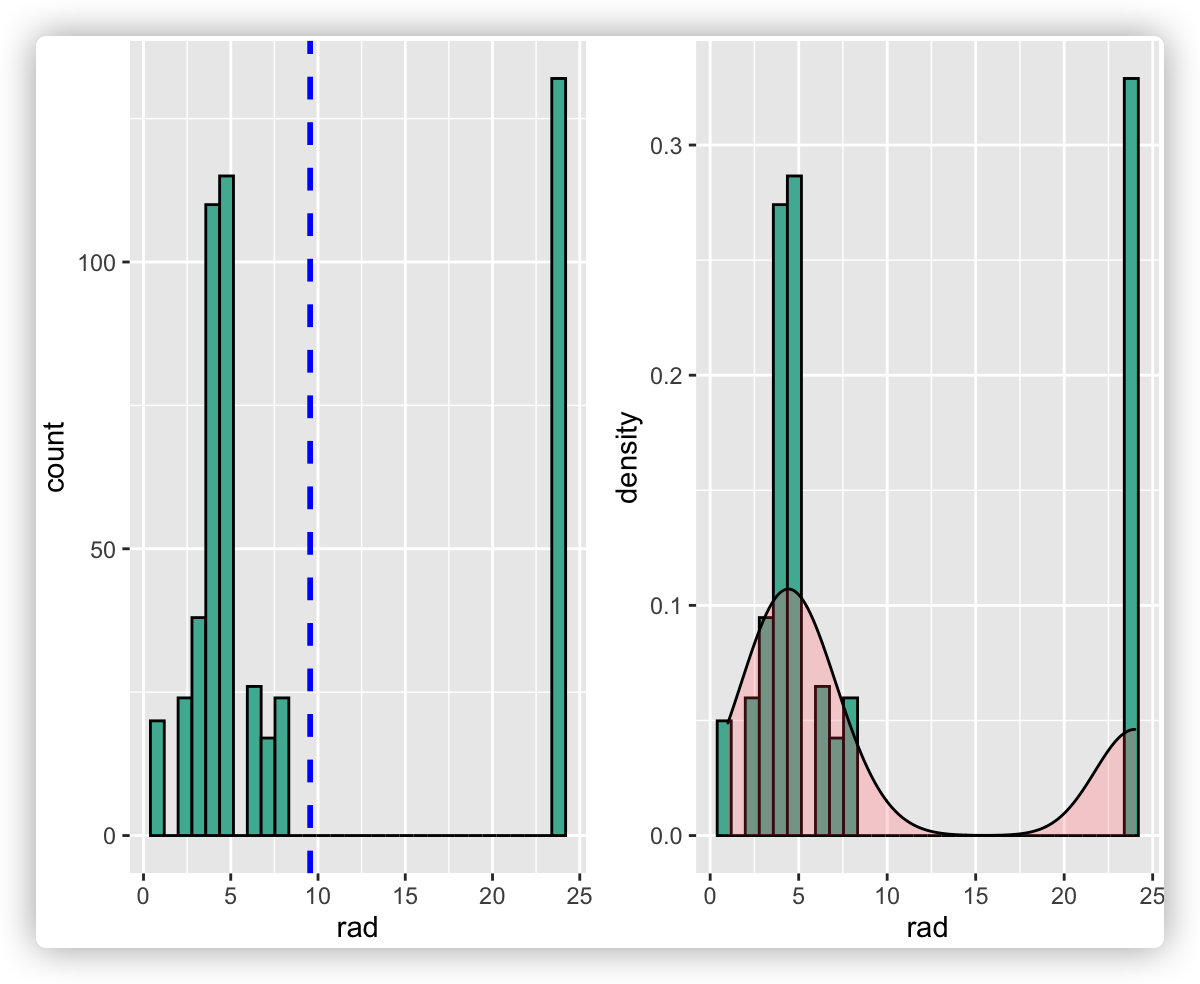
#添加平均线和密度图
p7 <- p5 + geom_vline(aes(xintercept = mean(rad)), color = "blue", linetype = "dashed", size = 1)
p8 <- ggplot(data = boston_data, aes(x = rad)) + geom_histogram(color = "black", fill = "#69b3a2", aes(y = ..density..)) + geom_density(alpha = .2, fill = "#FF6666")
ggarrange(p7, p8, nrow = 1)
ggplot2关于直方图详细介绍,参考链接:https://ggplot2.tidyverse.org/reference/geom_histogram.html
柱状图,又称长条图
#柱状图,又称长条图
#使用plyr包中的count对edcation进行计数统计
data <- count(h1n1_data["race"])
p <- ggplot(data, aes(x = race, y = freq)) + geom_bar(stat = "identity")
# 也可以进行水平放置
p1 <- p + coord_flip()
ggarrange(p, p1)
#旋转底部文字45°
data <- count(h1n1_data["race"])
ggplot(data, aes(x = race, y = freq)) + geom_bar(stat = "identity") + theme(axis.text.x = element_text(angle = 45, hjust = 1))
# 更改条的宽度和颜色:
# 更改条的宽度
p2 <- ggplot(data, aes(x = race, y = freq)) +
geom_bar(stat = "identity", width = 0.5) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# 改变颜色
p3 <- ggplot(data, aes(x = race, y = freq)) +
geom_bar(stat = "identity", color = "blue", fill = "white") +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# 最小主题+蓝色填充颜色
p4 <- ggplot(data, aes(x = race, y = freq)) +
geom_bar(stat = "identity", fill = "steelblue") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# 选择要显示的项目
p5 <- p + scale_x_discrete(limits = c("White", "Black")) + theme(axis.text.x = element_text(angle = 45, hjust = 1))
ggarrange(p2, p3, p4, p5)
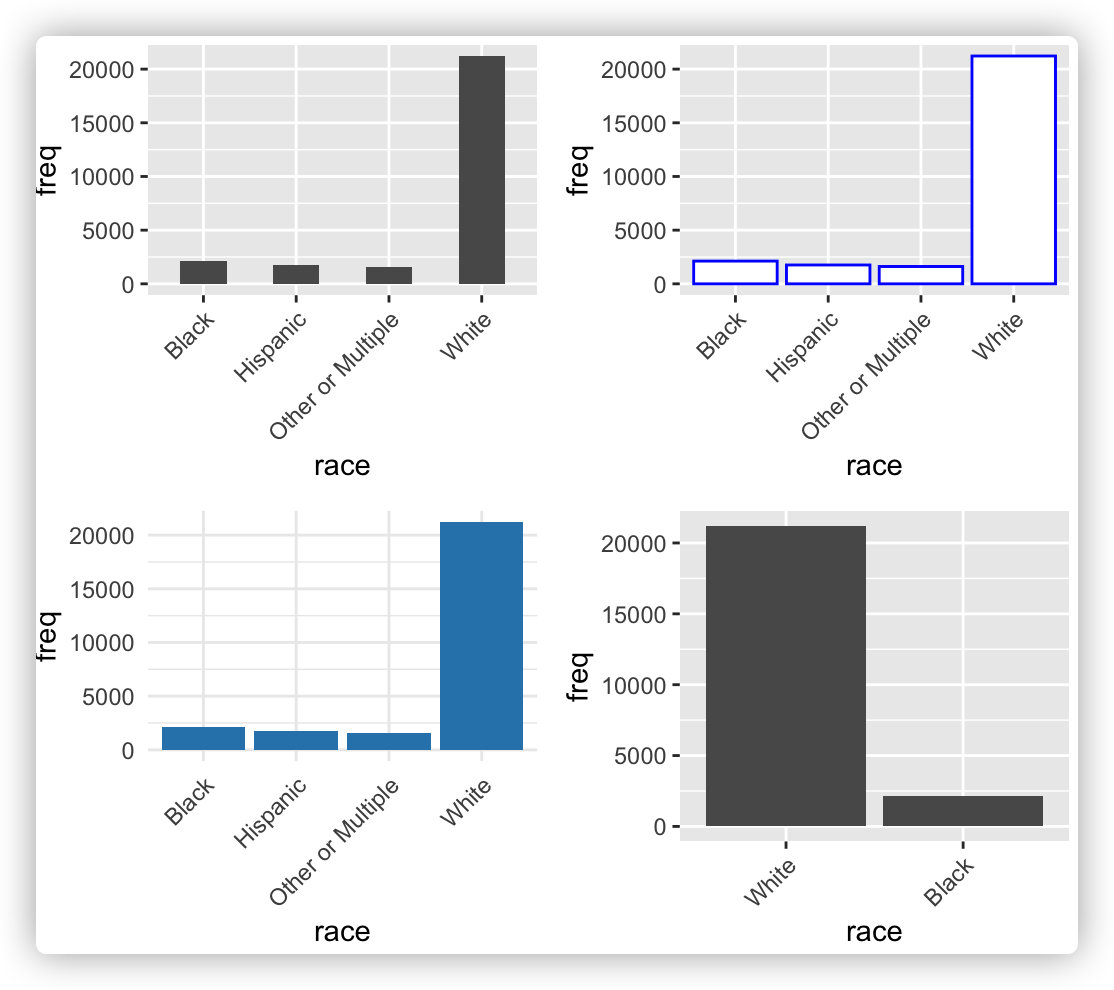
ggplot2关于柱状图详细的介绍,参考链接: https://ggplot2.tidyverse.org/reference/geom_bar.html
饼状图
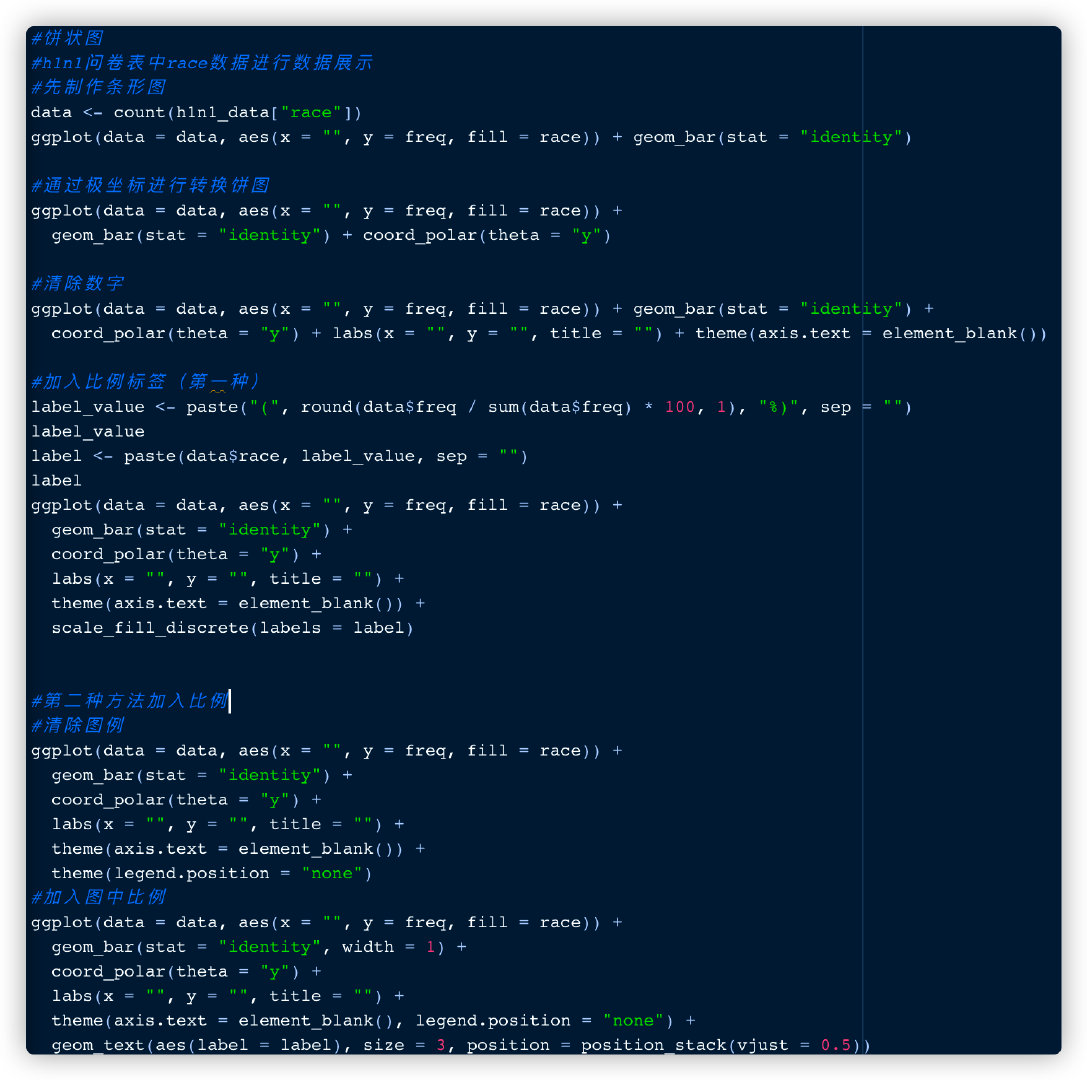
折线图
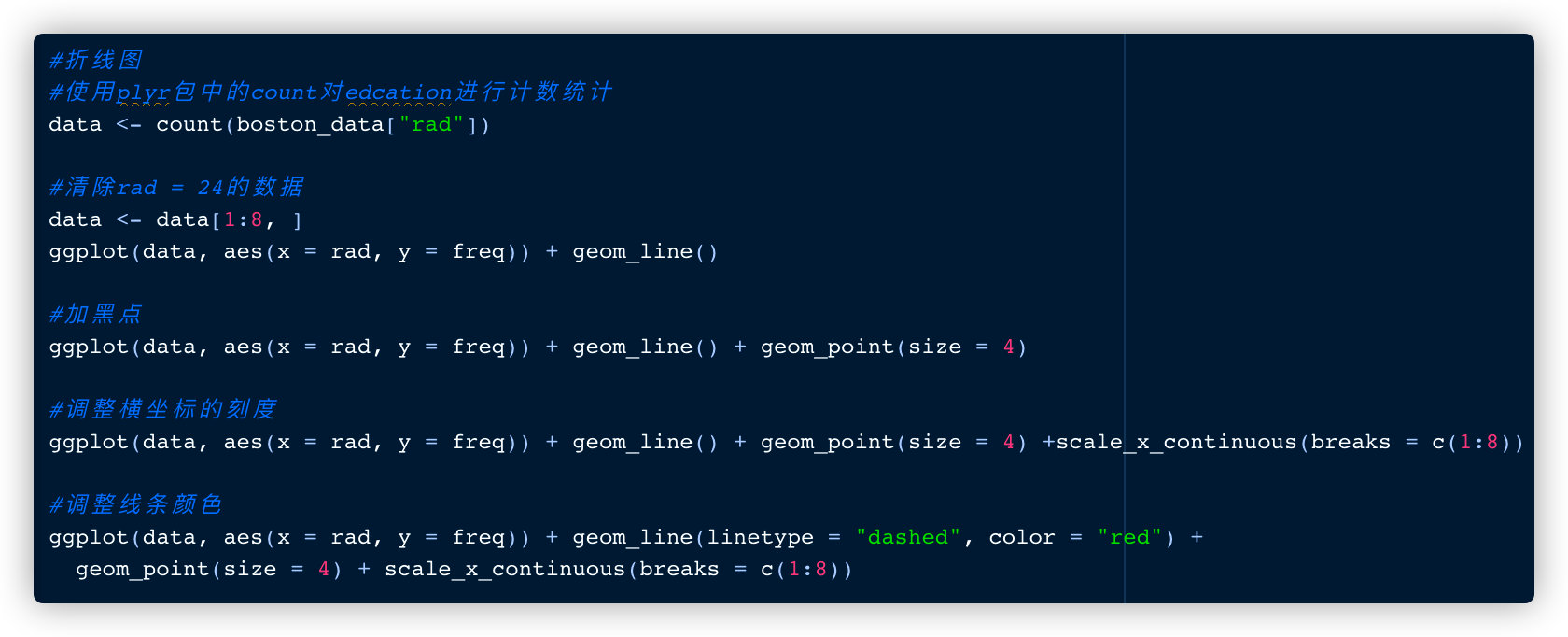 ggplot2关于折线图的参考链接: https://ggplot2.tidyverse.org/reference/geom_abline.html
ggplot2关于折线图的参考链接: https://ggplot2.tidyverse.org/reference/geom_abline.html
扩展学习资料(网络来源):
ggplot2入门大全(从菜鸟到高手):https://blog.csdn.net/weixin_45331620/article/details/107680919
ggplot2在线书籍:https://ggplot2-book.org/index.html
Task05 模型
待学习更新
![]()
![]()
![]()
谢谢大家观看,如有帮助,来个喜欢或者关注吧!
本文作者:陈锐
博客地址 : Chen Rui Blog
知乎地址 : 知乎专栏
书店地址 : 书店主页
知识星球 : 星球主页














 7808
7808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









