







对于内存中的1000万个整数排序,使用C++算法库里的并行排序函数sort(execution::par, vec_data.begin(), vec_data.end()),只需要0.08秒即可完成排序。在CSDN的鼓励下,我们将这个速度再提高2倍。主要使用多线程,同时对多个容器里的数据进行排序。在排序之前,我们需要将数据分配到多个容器中。如果每个容器中数据量差别不大,多线程的加速效果明显,反之,如果绝大多数数据分配到了一个容器中,加速效果会比较差。待排序的数据量越大(亿以上),CPU的核心数越多,多线程的加速效果将非常明显。
#include <vector>
#include <execution>
#include <thread>
#include <iostream>
using namespace std;
void SortThread(vector<int> vec_data[], int tid);
int main()
{
const int thread_num = 20;
const int num_max_limit = 10000000;
FILE* fp_read = NULL;
fopen_s(&fp_read, "e:\\1000w.txt", "r");
if (fp_read == NULL)
{
cout << "open read file error" << endl;
return -1;
}
FILE* fp_write = NULL;
fopen_s(&fp_write, "e:\\1000w_sort_multi_thread.txt", "w");
if (fp_write == NULL)
{
cout << "open file error" << endl;
return -1;
}
clock_t t1 = clock();
vector<int> vec_data[thread_num];
char line[20];
while (!feof(fp_read))
{
fgets(line, 20, fp_read);
int num = atoi(line);
int nums_per_vector = num_max_limit / thread_num;
vec_data[num / nums_per_vector].push_back(num);
}
clock_t t2 = clock();
cout << "读取1000万数据,用时" << (double(t2) - double(t1)) / CLOCKS_PER_SEC << "秒" << endl;
//(execution::par, vec_data.begin(), vec_data.end());
thread td[thread_num];
for (int i = 0; i < thread_num; i++)
{
td[i] = thread(&SortThread, vec_data, i);
}
for (int i = 0; i < thread_num; i++)
{
td[i].join();
}
clock_t t3 = clock();
cout << "1000万整数排序,用时" << (double(t3) - double(t2)) / CLOCKS_PER_SEC << "秒" << endl;
for (int i = 0; i < thread_num; i++)
{
for (auto& element : vec_data[i])
{
char data[20];
_itoa_s(element, data, 10);
fputs(data, fp_write);
fputs("\n", fp_write);
}
}
clock_t t4 = clock();
cout << "1000万已排序整数写入文件,用时" << (double(t4) - double(t3)) / CLOCKS_PER_SEC << "秒" << endl;
cout << "总共用时" << (double(t4) - double(t1)) / CLOCKS_PER_SEC << "秒" << endl;
return 0;
}
void SortThread(vector<int> vec_data[], int tid)
{
sort(execution::par, vec_data[tid].begin(), vec_data[tid].end());
}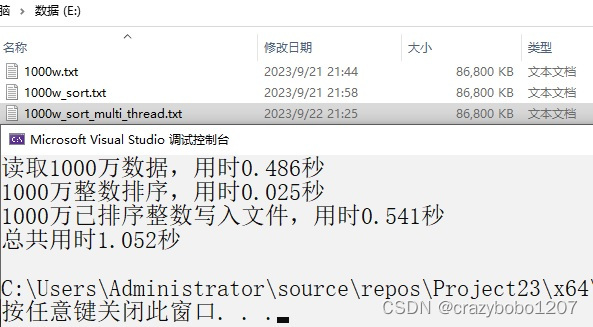
相比上个帖子的0.082秒,排序时间变成了0.025秒,速度提高了2倍多。
多线程的程序一不小心就会有bug,主要源于多个线程对同一块数据有“写操作”,上述程序多个线程对多个容器分别进行写操作,好像、可能、大概没有问题,嘿嘿,不过谁能保证没错呢?还是检查一下采用多线程排序的结果文件和之前的排序结果是否完全一致,下面比较两个文件的内容。
#include <iostream>
using namespace std;
int main()
{
clock_t t1 = clock();
FILE* fp1 = NULL;
fopen_s(&fp1, "e:\\1000w_sort.txt", "r");
if (fp1 == NULL)
{
cout << "open file error" << endl;
return -1;
}
fseek(fp1, 0, SEEK_END);
int filesize1 = ftell(fp1);
cout << "1000w_sort filesize: " << filesize1 << endl;
FILE* fp2 = NULL;
fopen_s(&fp2, "e:\\1000w_sort_multi_thread.txt", "r");
if (fp2 == NULL)
{
cout << "open file error" << endl;
return -1;
}
fseek(fp2, 0, SEEK_END);
int filesize2 = ftell(fp2);
cout << "1000w_sort_multi_thread filesize: " << filesize2 << endl;
if (filesize1 != filesize2)
{
cout << "两个文件内容不一致";
return -100;
}
char line1[100];
char line2[100];
int lines = 0;
fseek(fp1, 0, SEEK_SET);
fseek(fp2, 0, SEEK_SET);
while (!feof(fp1) && !feof(fp2))
{
fgets(line1, 100, fp1);
fgets(line2, 100, fp2);
if (strcmp(line1, line2) != 0)
{
cout << "两个文件内容不一致";
return -200;
}
lines++;
}
clock_t t2 = clock();
cout << "已比较" << lines << "行,两个文件内容一致,用时" << (double(t2) - double(t1)) / CLOCKS_PER_SEC << "秒" << endl;
return 0;
}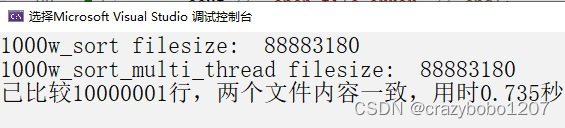
1000万零1行?多出来的一行是因为写文件时,最后一次写入的'\n'。
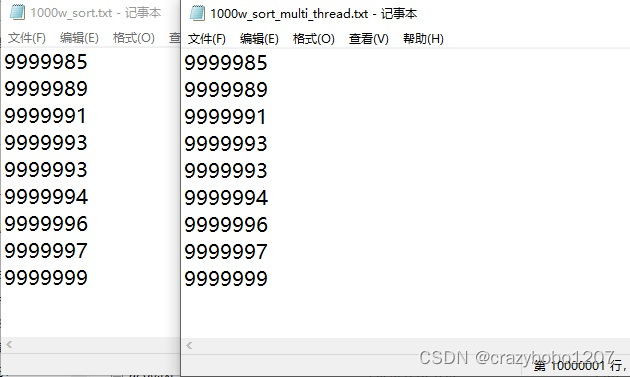
目前看上去没有错,但是多线程的bug总是很隐蔽,也许运行1000次才错一次,嘿嘿。
到此为止,数据在内存中排序速度提升了不少,1000万整数排序,26毫秒,这速度刚刚的,挺不错了,应该还有提升的空间,嘿嘿。另外,文件读写操作速度没有提升,下一篇帖子,准备用多线程来加速文件读写操作。















 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









