







引入 Gemini 2.0 Flash(检索增强生成(RAG)的终结者?)
原文链接: https://medium.com/everyday-ai/goodbye-rag-gemini-2-0-flash-have-just-killed-it-96301113c01f

好吧!!
谷歌刚刚发布了 Gemini 2.0 Flash,老实说?
这可能是目前性价比最高的 AI 模型。
我写了很多关于 RAG 的文章,认为它可能不再需要,也看到人们在讨论。
有些人理解了,有些人没理解,还有些人真的很担心。
所以让我们澄清一下。
- RAG 到底是什么?
- 为什么我们过去认为需要 RAG 的方式可能不再需要?
- 而且,如果你正在开发人工智能相关的东西——或者只是好奇——你为什么应该关心这个问题?
RAG 到底是什么?
如果你是人工智能领域的新人,RAG 代表检索增强生成。
它是一种常用的技术,用于帮助像 ChatGPT 这样的人工智能模型访问它们原始训练数据之外的信息。
你可能在不知不觉中见过它的实际应用。
曾经使用过 Perplexity 或必应的 AI 搜索吗?
当它们在回答你的问题时查找信息,那就是 RAG 在起作用。
甚至当你上传文件到 ChatGPT 并询问有关它们的问题时,也是 RAG。
RAG 变得如此重要的原因是,过去的人工智能模型的内存窗口非常小。
早在 2023 年初,模型只能处理大约 4,000 个标记(大约 6 页文本)。
这意味着,如果你有大量的信息,而人工智能无法仅仅“记住”所有内容——你就必须将其拆分,以特殊的方式存储(嵌入、向量数据库、分块等),
然后在需要时检索正确的部分。
但现在?
忘掉那些吧。
传统 RAG 流程就是这样。
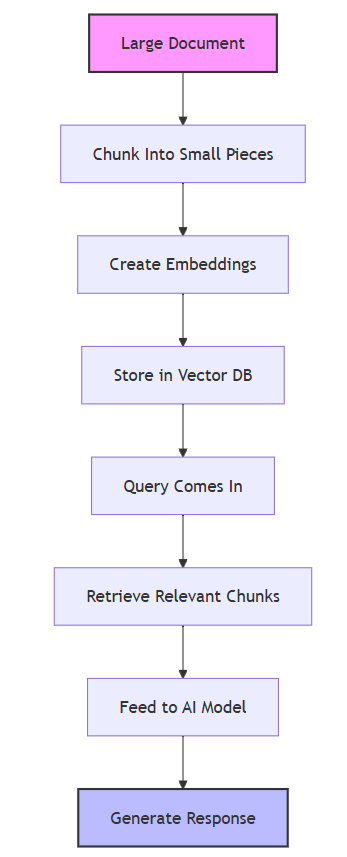
Gemini 2.0时代
没错,你没听错!!!
如今,所有的人工智能模型都能够一次性处理大量信息。
但是 Gemini 2.0 呢?
它能够处理多达 100 万个标记(token)。
一些模型甚至能够处理 200 万个标记。
这意味着,你无需再将数据切割成微小的片段,也无需思考如何检索这些片段,现在你只需将整个数据输入模型,让它一次性对所有内容进行推理即可。
最关键的是 —— 这些更新的模型不仅能够记住更多内容,而且其准确性也大大提高。
谷歌最新的模型拥有我们所见过的最低的幻觉率(也就是编造内容的概率)。
仅凭这一点就带来了巨大的改变。
(Gemini 2.0 直接文档处理,作者供图)

为什么这会改变一切
让我们举一个现实世界的例子。
假设你有一份财报电话会议的文字记录 —— 长达 5 万个标记(这已经非常长了)。
如果你使用的是传统的检索增强生成(RAG)技术,那么你就必须将其分割成一个个 512 个标记的小片段,然后存储起来。
然后,当有人提出问题时,你会尝试提取最相关的片段,并将它们输入到人工智能中。
问题出在哪里呢?你无法对整个文档进行推理。
想象一下这样提问:
“这家公司的收入与去年相比如何?”
如果你只是提取一些小的文本片段,那么你可能无法获得完整的情况。
但是,如果你将整个文字记录输入到 Gemini 2.0 中呢?
它可以查看所有内容 —— 从首席执行官的开场介绍,到中间的具体数据,再到他们如何回答分析师的问题 —— 然后为你提供一个更好、更周全的答案。
所以当我说 “RAG 已死” 时,
我的意思是:
传统的 RAG 做法(将单个文档分割成片段)已经过时了。
你不再需要这样做了。
只需将所有内容输入到一个大型模型中,然后让它施展魔法即可。
不过,等等,RAG 并没有完全消亡
现在,有些人会问:
“如果我有 10 万份文档呢?”
这是个合理的问题!
如果你要处理海量的数据集 —— 比如苹果公司过去十年的所有财报 —— 你仍然需要一种方法来对这些数据进行筛选。
但即便在这种情况下,方法也有所不同。
现在,我不会再将所有内容分割成微小的片段,而是会这样做:
- 首先搜索相关文档(比如只提取苹果公司 2020 年至 2024 年的财报电话会议内容)。
- 将完整的文档分别、并行地输入到人工智能模型中。
- 合并这些模型给出的回复,得出最终答案。
这种方法比传统的分割片段的方法要准确得多。
它让人工智能能够真正地对整个文档进行思考,而不是迫使它处理那些不连贯的片段。
下面是一个与处理大型文档集的现代方法相关的流程图。
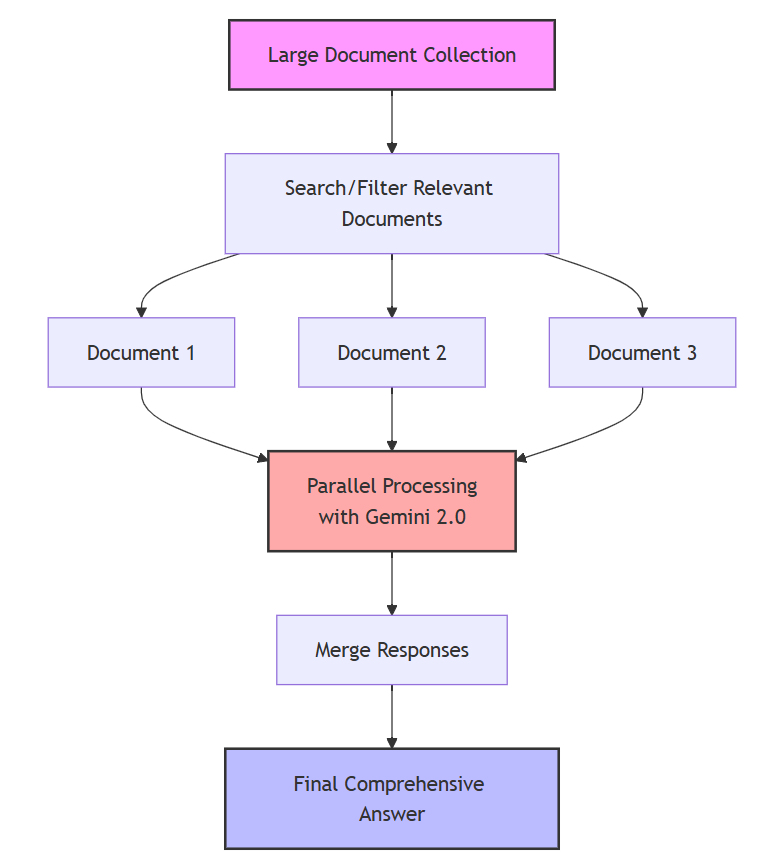
(作者供图)
重要结论(takeaway)
如果你正在开发人工智能产品,或者只是在进行实验,那么请保持简单。
很多人在不需要的时候把事情弄得过于复杂了。
只需将完整的文档上传到 Gemini 2.0(或任何具有大上下文处理能力的人工智能)中,然后让它来处理推理工作。
一年后情况还会发生变化吗?很可能会。
人工智能模型正变得越来越便宜、越来越智能、越来越快速。
但就目前而言呢?传统的 RAG 方法已经过时了。
只需将你的数据输入到谷歌的新模型中,就能以更少的麻烦获得更好的结果。
如果你有文档需要分析,不妨试一试。
你可能会惊讶地发现,一切变得如此简单。
祝好!
搬运者思考🤔
所以后续如果模型上下文能力越来越强,就不太需要rag了?
但是目前切分,检索排序,仍然是切实可行的路线,后续走着瞧。
注:这个版本是使用豆包翻译的,感觉可以接受,但是翻译质量仍然生涩,人机味浓,后续我换GPT或者Claude模型试试。
我也尝试了KIMI翻译的版本,原文结尾处的peace,甚至翻译成了“和平”,你说,这这这 …

















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









