







数据集介绍
- EMO-DB数据集是由柏林工业大学录制的德语情感语音库
- 535条语音文件(一共有十名演员其中五男五女)其中语句内容包含日常生活用语的5个短句和5个长句,具有较高情感自由度,不包含某一特定情感倾向。采用16kHZ采样,16bit量化,并以WAV格式保存文件。
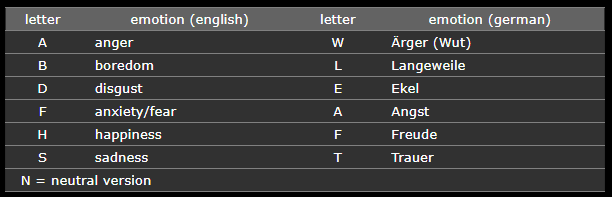
- 其中情绪组成:anger, neutral, fear, boredom, happiness, sadness, disgust.

主要是用到这个语音标签 audio 文件的XXXWa.wav中W就是情绪
提取相关特征
import feature
import os
import pickle
import tqdm
def extract_emodb(file_name:str):
label = file_name.split('.')[0][-2]
feature_27 = feature.extract_mfcc_feature(file_name)
return (label,feature_27)
database_dir = "H:\dataset\EM-DB\wav"
feature_tuple =()
dir_file = os.listdir(database_dir)
for i in tqdm.tqdm(dir_file):
file_path = os.path.join(database_dir,i)
feature_tuple = feature_tuple+ (extract_emodb(file_path),)
with open('emo_db.pkl', 'wb+') as file:
pickle.dump(feature_tuple,file)
工具
def read_file(filename):
"""
input a filename and get wave data and time,framerate
:param filename:
:return:
"""
file = wave.open(filename, 'r')
params = file.getparams()
nchannels, sampwidth, framerate, wav_length = params[:4]
str_data = file.readframes(wav_length)
wavedata = np.fromstring(str_data, dtype=np.short)
time = np.arange(0, wav_length) * (1.0 / framerate)
file.close()
return wavedata, time, framerate
def extract_mfcc_feature(filename):
"""
input a filename extract mfcc from audio
:param filename:
:return:
"""
data, time, rate = read_file(filename)
mel_spec = ps.logfbank(data, rate, nfilt=13)
np.set_printoptions()
time = mel_spec.shape[0]
if time <= 300:
part = mel_spec
part = np.pad(part, ((0, 300 - part.shape[0]), (0, 0)), 'constant',
constant_values=0)
mfcc = dct(part)
else:
begin = 0
end = 300
part = mel_spec[begin:end, :]
mfcc = dct(part)
return mfcc
总结
这个数据集还是比较简单,明了,听不懂。















 7215
7215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









