







07分布式
Flat file system 平面文件系统
文件服务器架构
- 1. 抽象DFS架构
- 2. Flat FileService
- 3.目录服务
- 4.客户端模块
- 文件组
Sun NFS
- 虚拟文件系统(VFS):
- NFS File Handles
- The Mount Protocol
- 硬软挂载
- 路径名
Flat file system 平面文件系统
平面文件:
在文件系统中,每个文件必须具有唯一名称,并且文件之间没有层次结构或目录组织。在平面文件系统中,所有文件都存在于同一层级,没有子目录的概念。
举例来说,在一个平面文件系统中,如果有两个文件需要命名为 “document.txt”,则系统将无法区分它们,因为文件名相同,系统无法确定它们的位置或属于哪个文件。因此,平面文件系统中通常要求每个文件都有唯一的名称,以便避免冲突。
文件服务器架构
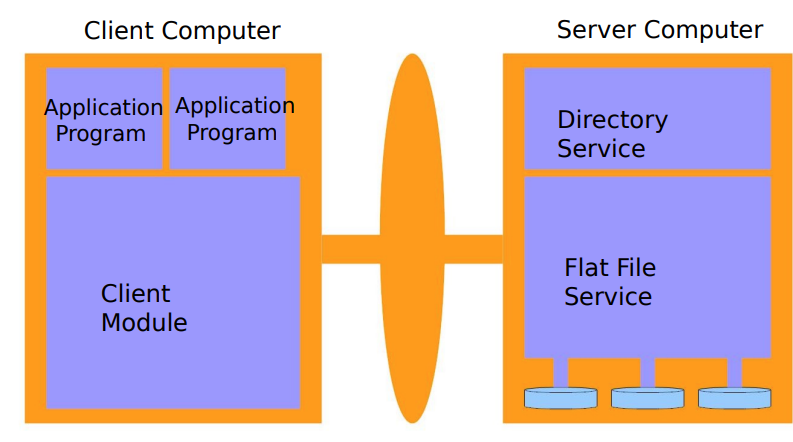
1. 抽象DFS架构
- Network File System (NFS) 和 Andrew File System (AFS) 的基础,它被设计为一个无状态的实现
- 有三个核心组件
- Flat File Service平面文件服务
- 负责文件的存储和检索,确保文件的独一无二性,每个文件必须有唯一的名称。
- Directory Service目录服务
- 管理文件和目录的层次结构,为文件提供组织和查找的方式。
- Client Module客户端模块
- 提供了标准化的接口,可以轻松地适应不同的操作系统
- Flat File Service 和 Directory Service)分别规定了导出的接口,配合相关的远程过程调用(RPC)接口,提供了完整的DFS操作集
- Flat File Service平面文件服务
- 这种架构的设计允许DFS在不同的操作系统上运行,通过标准化的接口,可以轻松地适配和集成到各种环境中。同时,架构的无状态特性使得系统更容易扩展和维护。
-
2. Flat FileService
- 使用唯一标识符来引用文件UFIDs
- UFID的特性:
- UFIDs是一长串的比特序列,它们被设计为在DFS中是唯一的,确保每个文件都有一个与众不同的UFID。
- 这种唯一性保证了在DFS中每个文件都能被准确定位,无论文件的名称或路径如何。
- 处理新文件的请求:
- 当平面文件服务(Flat File Service,FFS)接收到一个新文件的请求时:
- 它会生成一个新的UFID,确保它在DFS中是唯一的。
- 然后,FFS将这个新生成的UFID返回给请求方。
- 当平面文件服务(Flat File Service,FFS)接收到一个新文件的请求时:
3.目录服务
- 用于在文件的文本名称和唯一文件标识符(UFID)之间建立映射关系。
- 客户端获取UFID:
- 客户端可以通过提供文件的文本名称,从这个服务中获取对应的UFID。
这个映射服务提供了以下功能支持:
-
生成新目录(Generating new directories):
- 服务允许创建新的目录,并为每个新目录生成一个独特的UFID。
-
将新文件名添加到目录中(Adding new file names to directories):
- 客户端可以将新的文件名和相应的UFID添加到已有的目录中。
-
从目录中移除UFID(Removing UFIDs from directories):
-
如果需要,服务还提供了从目录中移除特定UFID的功能。
通过这个映射服务,DFS中的文件可以用文本名称来标识,并且这些文本名称可以被映射到唯一的UFID。这种映射关系的建立使得客户端能够方便地使用文件的文本名称进行文件操作,而无需关心底层的UFID。
4.客户端模块
略
文件组
-
在分布式文件系统中,一个文件组指的是存储在服务器上的一组文件。一个服务器可以拥有多个文件组,但是文件不能改变它们所属的文件组。
- 文件组的用途:
- 文件组被用来支持将文件分配到更大的逻辑单元中的文件服务器。
- UFID的扩展:
- 在支持文件组的分布式文件系统中,唯一文件标识符(UFID)需要被扩展,以便包含文件组标识符。这个扩展的UFID可能包括IP地址和时间戳等信息。
- IP地址的限制:
- IP地址不能用于定位文件组,因为文件组可能会在不同的服务器之间移动。
- 文件服务的映射维护:
- 文件服务必须维护文件组和服务器之间的映射关系,以确保文件组中的文件能够被正确地定位和访问。
通过引入文件组的概念,分布式文件系统可以更有效地管理文件的分配和存储,提供了更灵活的文件组织结构,使得在大规模系统中能够更好地管理文件资源。
- 文件组的用途:
Sun NFS
NFS是一种用于在网络工作站之间共享文件系统的协议,它使用客户端-服务器模型。以下是NFS的主要特点和功能:
- 客户端和服务器模型:
- NFS允许每个工作站既可以是客户端又可以是服务器。工作站可以请求其他工作站上的文件(客户端操作),同时也可以共享本地文件供其他工作站访问(服务器操作)。
- 客户端集成于内核:
- NFS客户端通常集成到操作系统的内核中,使得用户和应用程序可以像访问本地文件一样访问远程文件。
- 关键协议:
- NFS使用两个关键的协议:挂载协议(Mount Protocol)用于连接到远程文件系统,NFS协议用于实际的文件操作。
- 无状态操作:
- NFS采用无状态操作,这意味着每个请求都是独立的,服务器不会维护客户端的状态信息。这种无状态性使得系统更容易扩展和维护。
- 标准化协议:
- NFS遵循RFC 1813标准,确保了不同实现之间的互操作性。
NFS的设计使得网络中的工作站可以方便地共享和访问文件,实现了分布式环境下的文件共享和协作。
虚拟文件系统(VFS):
VFS是UNIX内核的关键组件,它通过将通用文件系统操作与具体实现分离,实现了访问透明性。以下是VFS的主要特点和功能:
- 访问透明性:
- VFS通过将通用文件系统操作与底层实现分离,实现了对文件访问的透明性。无论是本地文件系统还是远程文件系统,用户和应用程序都可以使用相同的接口来访问文件。
- 文件系统可用性追踪:
- VFS会跟踪当前可用的所有文件系统,无论是本地文件系统还是远程文件系统。它知道有哪些文件系统可以访问,包括本地和远程的。
- 文件系统模块调用:
- VFS负责调用相关的文件系统模块来执行文件操作。根据文件的位置(本地还是远程),它会调用相应的文件系统模块来处理请求。
- 基于vnode的实现结构:
- VFS的实现基于一个称为vnode的文件实现结构。vnode结合了一个指示器,用于确定文件是本地还是远程的,以及一个唯一的文件引用。
- 对于本地文件,文件引用是一个inode标识符。
- 对于远程文件,文件引用是一个NFS文件句柄(file handle)。
- VFS的实现基于一个称为vnode的文件实现结构。vnode结合了一个指示器,用于确定文件是本地还是远程的,以及一个唯一的文件引用。
VFS的设计使得UNIX系统能够处理各种不同类型的文件系统,同时提供了统一的文件系统接口,使得用户和应用程序无需关心底层的文件系统实现细节,从而实现了高度的灵活性和可扩展性。
NFS File Handles

The Mount Protocol

硬软挂载


路径名




















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









