







本文作为入门Video Caption / 视频字幕 的随笔记录,用于查漏补缺和回顾,难免有疏漏和不足指出,烦请指出!
一、指标
Video Caption / 视频字幕常用的标准指标有四种:BLEU-1[1],BLEU-2[1],BLEU-3[1],BLEU-4[1],ROUGE-L[2],METEOR[3],CIDEr[4],SPICE[5],这些指标在论文中又分别可能会记为B@1,B@2,B@3,B@4,R,M,C,S。
1.1、BLEU-n
BLEU,全称为Bilingual Evaluation Understudy,中文意思是双语评估替补,用于机器翻译任务的评价。BLEU的总体思想就是准确率。
假如给定标准译文reference,神经网络生成的句子是candidate,句子长度为n,candidate中有m个单词出现在reference,m/n就是bleu的1-gram的计算公式3。根据n-gram可以划分成多种评价指标。常见的指标有BLEU-1、BLEU-2、BLEU-3、BLEU-4四种,其中n-gram指的是连续的单词个数为n。
例:
【candinate】:the cat sat on the mat
【reference】:the cat is on the mat
计算n-gram的BLEU-n(reference中在candidate中出现的gram个数占reference总gram个数的比值):
BLEU-1 = 5/6 = 0.83333
BLEU-2 = 3/5 =0.6
BLEU-3 =1/4 = 0.25
BLEU-4 = 0/3 = 0
BLEU-1衡量的是单词级别的准确性,更高阶的bleu可以衡量句子的流畅性。 如果两个句子完美匹配 (perfect match), 那么BLEU是1.0, 反之, 如果两个句子完美不匹配 (perfect mismatch), 那么BLEU为0.04。
1.2、ROUGE-L
ROUGE-L是一种用于评估自然语言处理任务的指标,特别是在机器翻译和自动文摘中。ROUGE-L的"L"代表"Longest Common Subsequence",即最长公共子序列。
ROUGE-L的计算利用了最长公共子序列(区别于最长公共子串,这个是连续的,子序列不一定连续,但是二者都是有词的顺序的)。
具体来说,ROUGE-L的计算公式可以表示为:
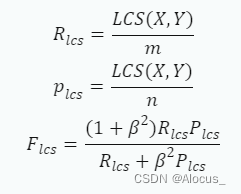
其中,X表示标准答案,Y表示生成答案。m表示X的长度,n表示Y的长度。LCS (X,Y) 表示X和Y的最长公共子序列,β是一个超参数。 ROUGE-L指标主要关注机器生成的摘要或翻译中是否捕捉到了参考摘要或翻译的信息,着重于涵盖参考摘要或翻译的内容和信息的完整性。因此,可用来衡量生成结果和标准结果之间的匹配程度。
例:
参考句子:我喜欢吃苹果。
候选句子:我喜欢苹果。
首先,我们需要找到这两个句子的最长公共子序列。在这个例子中,最长公共子序列是"我喜欢苹果",长度为5。
然后,我们可以计算ROUGE-L的recall和precision:
最后,我们可以计算F-measure。假设我们选择β=1,那么F-measure为:
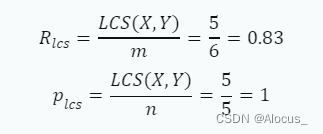
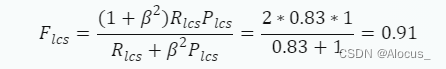
所以,这个候选句子的ROUGE-L得分是0.91。这意味着候选句子与参考句子的匹配程度很高
1.3、METEOR
METEOR,全称为Metric for Evaluation of Translation with Explicit ORdering,中文意思是具有明确排序的翻译评估指标。METEOR的定义和概念主要基于单词级别的准确率和召回率,以及对词序的惩罚,来计算候选文本和参考文本之间的相似度。
METEOR的特点是它不仅考虑了单词的精确匹配,还考虑了词干、同义词和其他语言变体的匹配。它还使用了一个调和平均数来平衡准确率和召回率,以及一个罚分因子来惩罚不流畅或不连贯的文本。它可用来衡量生成结果和标准结果之间的匹配程度。
METEOR的计算公式如下:
![]()
其中,Pen是罚分因子,Fmean是准确率和召回率的调和平均数。假设m为候选译文和参考译文匹配到的总对数 ,候选译文的长度为t,参考译文的长度为r。准确率P和召回率R的计算方式为:
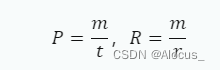
调和平均数Fmean的计算方式为:
![]()
其中,α是一个权重参数。
Pen为惩罚因子,惩罚的是候选翻译中的词序与参考翻译中的词序不同,具体计算方法为:
![]()
#chunks指的是chunk的数量,chunk就是既在候选翻译中相邻又在参考翻译中相邻的被匹配的一元组聚集而成的单位,举个例子:
Candidate: the president spoke to the audience.
Reference: the president then spoke to the audience.
其中,reference中的6个unigram都可以被匹配,但是其在reference中匹配的对象,却只有"the president" 和 "spoke to the audience"这两个字符串是相邻的,而这两个字符串就是两个chunk。
例:
参考句子:我喜欢吃苹果。
候选句子:我喜欢苹果。
首先,我们需要找到这两个句子的最长公共子序列。在这个例子中,最长公共子序列是"我喜欢苹果",长度为5。
然后,计算准确率和召回率:
计算调和平均数Fmean:
最后,我们需要计算罚分因子Pen。在这个例子中,由于候选句子和参考句子的词序一致,所以罚分因子Pen为0。所以,这个候选句子的METEOR得分是:
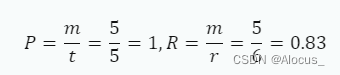
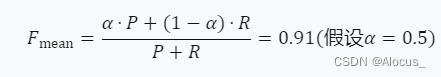
1.4、CIDEr
CIDEr是一种用于评价图像描述 (image caption) 任务的评价指标,它是基于BLEU和向量空间模型的结合。它的主要思想是,将每个句子看成一个文档,利用TF-IDF来给不同长度的n-gram赋予不同的权重,然后计算候选句子和参考句子的n-gram的余弦相似度,再取平均得到最终的评分。 CIDEr还引入了高斯惩罚和长度惩罚来避免不常见单词重复很多次或者生成过短或过长的句子而得到更高的分数,得到了CIDEr-D。
其中,TF-IDF即词频-逆文档频率(Term Frequency-Inverse Document Frequency),是一种用于信息检索与数据挖掘的常用加权技术。它的主要作用是挖掘文章中的关键词,并给每个词分配一个权重,反映该词对文章主题的重要程度。
公式如下:
定义参考句子为
,候选句子为
,n-gram记为
。
表示,在候选句子中出现的次数用
表示。首先计算TF-IDE
,对每一个n-gram进行加权:
其中,Ω 是所有 n-gram 的词汇表,I 是数据集中所有图像的集合。第一项衡量了每个 n-gram
CIDErn 分数是通过计算候选句子和参考句子之间的平均余弦相似度来计算 n-gram 的长度为 n 的分数,这考虑到了精确度和召回率:
其中,
是由所有长度为 n 的 n-gram 对应的
形成的向量,
是向量
的大小。
同理。我们使用更高阶(更长)的 n-gram 来捕捉语法属性以及更丰富的语义。我们将不同长度的 n-gram 的分数组合如下:
论文中认为,
的效果最好, N = 4。
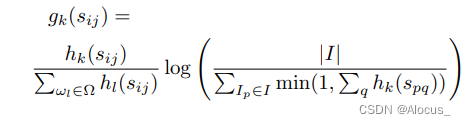
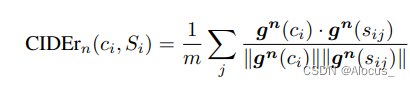

CIDEr的优点是,它可以捕捉到不同长度的n-gram之间的匹配,而且可以通过TF-IDF权重来区分不同n-gram的重要性,它不是像BLEU那样只计算准确率,而是计算余弦相似度。它也可以看作是对BLEU的一种改进和扩展,有效地衡量候选描述与参考描述之间的语义一致性。CIDEr的缺点是,它需要一个大规模的图像描述语料库来计算TF-IDF权重,而且它不能考虑到句子的语法和结构。
1.5、SPICE
在图像描述生成任务中,SPICE(Semantic Propositional Image Caption Evaluation)是一种评价方法。它的主要思想是将图像描述转换为一种基于图的语义表示,然后比较这些表示来评估描述的质量。
SPICE使用如下步骤来评估一个描述:
1.语义解析:首先,SPICE将描述转换为一种基于图的语义表示,称为场景图 (scene graph)。场景图编码了描述中的对象 (objects),属性 (attributes),和关系 (relationships)。
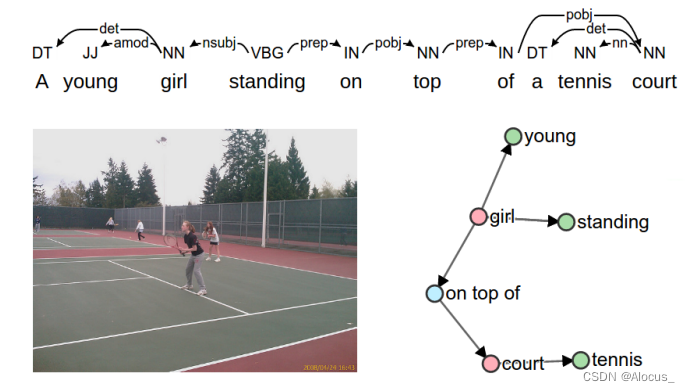
使用the Stanford Scene Graph Parser将caption转换为一个依赖树结构,然后利用九个简单的语言规则将树结构转换为一个scene graph。左边为一幅图和它对于的一些描述,右边为描述生成场景图。红色表示目标集合C,绿色表示属性集合A,蓝色表示关系集合R。公式如下表示:
![]()
其中,![]() 是描述c中提到的对象集合,
是描述c中提到的对象集合,![]() 是表示对象之间关系集合,
是表示对象之间关系集合,![]() 是与对象关联的属性集合。
是与对象关联的属性集合。
2.元组生成:然后,SPICE将场景图转换为一个元组集合 (tuple set)。每个元组都是一个语义命题,可以是一个对象,一个对象和属性的对,或者两个对象和它们之间关系的三元组.。我们定义了一个函数T,它可以从场景图获得元组。
![]()
如上图中元组表示为:
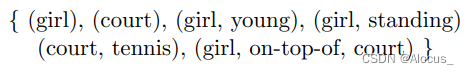
3.匹配和评分:最后,SPICE计算生成的描述和参考描述之间的元组集合的F1分数(利用准确率 P, 召回率 R)。这个分数反映了生成的描述在语义层面上与参考描述的相似度.
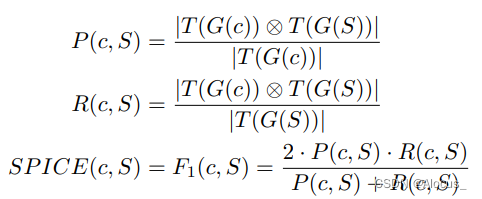
对于匹配的元组,我们采用了METEOR [3]的WordNet同义词匹配方法,即如果元组的词形还原形式相等——允许具有不同词形变化的词进行匹配——或者如果它们在同一个WordNet同义词集中,那么就认为这些元组是匹配的。
这种方法允许我们在更细粒度上评估图像描述的质量,包括对象识别,属性识别,以及对象之间关系的识别。因此,SPICE提供了一种更全面和详细的方式来评估图像描述生成任务的性能。
本文于2023.9.21写毕,数据集部分见专栏更新,预计于2023.9.23日前完成。更新如下
——————————————————————————————————————————
参考文献:
【1】Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318.
【2】Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries.
In Text summarization branches out. 74–81.
【3】Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for
MT evaluation with improved correlation with human judgments. In Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine
translation and/or summarization. 65–72
【4】Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider:
Consensus-based image description evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 4566–4575.
【5】Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016.
Spice: Semantic propositional image caption evaluation. In European conference
on computer vision. Springer, 382–398.

















 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











