







参考
1、https://zhuanlan.zhihu.com/p/223048748
2、https://www.cnblogs.com/xinbaby829/p/6955687.html
3、https://zhuanlan.zhihu.com/p/37639563
1、bleu
BLEU (全称为Bilingual Evaluation Understudy)的意思是双语评估替补。尽管最开始作为翻译的指标而被发明,但bleu也可以用于image caption的评估。
假如给定标准译文为reference,预测的句子是candidate,句子长度为n,candidate中有m个单词出现在reference,m/n就是bleu的1-gram的计算公式。
根据n-gram可以把bleu划分为多种评价指标,比如BLEU-1、BLEU-2、BLEU-3、BLEU-4......其中n-gram指的是连续的单词个数为n。
BLEU-1衡量的是单词级别的准确性,更高阶的bleu可以衡量句子的流畅性。
计算公式如下
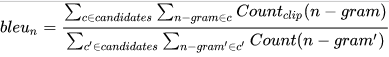
pytorch中,利用包nltk可以计算bleu值
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
smooth = SmoothingFunction() # 定义平滑函数对象
# reference可以有多个,注意接受的格式是 -> [reference1,reference2]
# 中文的reference和candidate要用空格进行分词或划分汉字
# reference = reference.replace('.', ' . ').replace(',', ' , ').split()
bleu1 = sentence_bleu([reference], candidate, weights=(1,0, 0,0), smoothing_function=smooth.method1)
bleu2 = sentence_bleu([reference], candidate, weights=(0,1, 0,0), smoothing_function=smooth.method1)
bleu3 = sentence_bleu([reference], candidate, weights=(0,0, 1,0), smoothing_function=smooth.method1)
bleu4 = sentence_bleu([reference], candidate, weights=(0,0, 0,1), smoothing_function=smooth.method1)2、meteor
METEOR可以计算为对应最佳候选译文和参考译文之间的准确率和召回率的调和平均,其结果和人工判断的结果有较高相关性。
METEOR还可以实现同义词匹配的功能。(需要先检查是否安装了wordnet同义词词库,没安装可以用 nltk.download('wordnet') 安装)
pytorch中,利用包nltk计算meteor值
from nltk.translate.meteor_score import meteor_score
meteor = meteor_score([reference],candidate)3、CIDEr(Consensus-based Image Description Evaluation)
cider把每个句子都看作“文档”,将其表示成 tf-idf 向量的形式,然后计算参考caption与模型生成的caption的余弦相似度,作为打分。
这么计算可以参考一下这个https://github.com/msanders/cider
4、rouge
自动文本摘要系统评价的主流方法。受BLEU的启发,不同之处在于,采用召回率来作为指标。
rouge-n计算生成的摘要与标注摘要的n-gram召回率,通常用ROUGE-1/2来评估。
rouge-l计算匹配两个文本单元之间的最长公共序列(LCS,Longest Common Sub sequence)。
pytorch中利用包rouge计算这个指标
from rouge import Rouge
rouge_score = rouge.get_scores(candidate, reference) 













 672
672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









