







【学习目标】
- 理解Unsloth的核心优化原理与基础实践;
- 掌握基于Unsloth的高效微调工作流。
【知识储备】
1. Unsloth简介
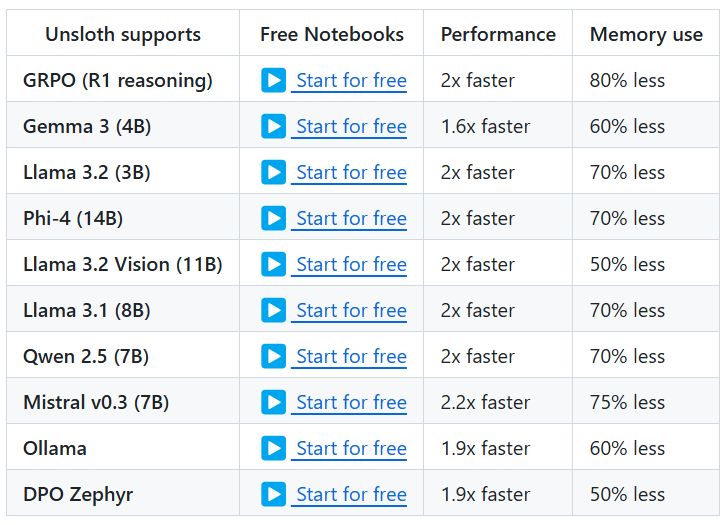
Unsloth是一个专为大型语言模型(LLM)设计的微调框架,旨在提高微调效率并减少显存占用。 它通过手动推导计算密集型数学步骤并手写 GPU 内核,实现了无需硬件更改即可显著加快训练速度。
通过Unsloth微调Qwen2.5-VL实现复杂数学公式的OCR
1. Unsloth简介
Unsloth是一个专为大型语言模型(LLM)设计的微调框架,旨在提高微调效率并减少显存占用。 它通过手动推导计算密集型数学步骤并手写 GPU 内核,实现了无需硬件更改即可显著加快训练速度。
通过Unsloth微调Qwen2.5-VL实现复杂数学公式的OCR

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























