






【能力目标】
- 掌握使用Docker部署Qwen2.5-Omni多模态模型以及它的使用;
- 了解vLLM进行Qwen2.5-Omni的推理;
【任务描述】
本任务通过部署一个gradio可视化界面的 Qwen2.5-Omni 多模态模型,通过离线图片、音频及视频的交互体验,了解Qwen2.5-Omni模型的特点,并使用vLLM进行简单推理评侧,掌握它的能力。
【知识储备】
1. Qwen2.5-Omni简介
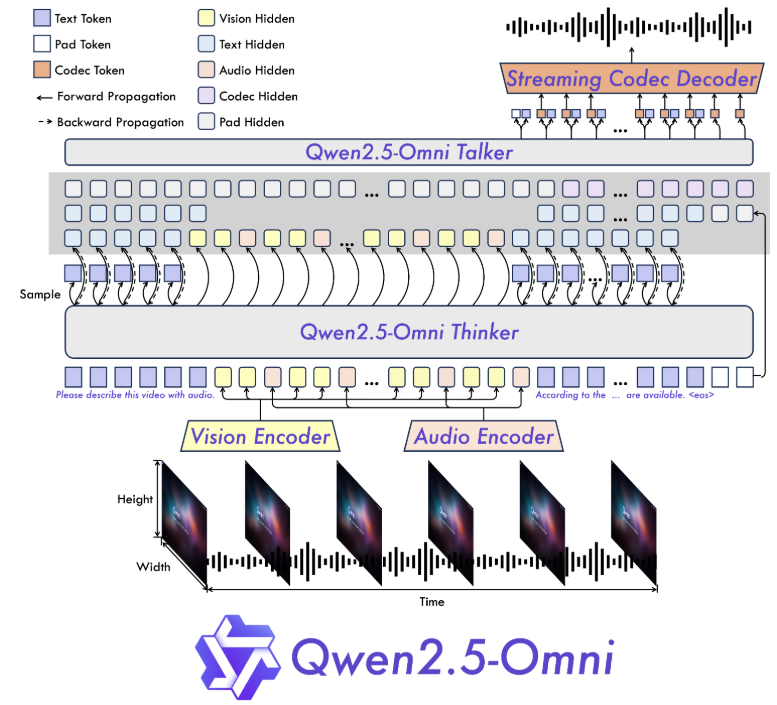
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。其中7B参数的版本是公开的。它的主要特点是:
- 全能创新架构:
- 提出了一种全新的Thinker-Talker架构,是一种端到端的多模态模型,端到端是一种系统设计方法,指的是从输入到输出的完整流程由一个统一的模型或系统完成,无需中间环节的人工干预或分阶段处理。在传统机器学习中,复杂任务通常被拆分为多个子任务(如预处理、特征提取、分类等),每个子任务由独立模块处理。而端到端方法直接用单一模型学习从原始输入到最终输出的映射。
- 提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
- 实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
- 自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。
- 全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。
- 卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。
【任务实施】
1. 硬件要求及Qwen2.5-Omni模型下载
1.1、建议的最小GPU显存需求:
| 精度 | 15(s) 音频 | 30(s) 音频 | 60(s) 音频 |
|---|---|---|---|
| FP32 | 93.56 GB | 不推荐 | 不推荐 |
| BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
注意: 上述的表格所展示的只是使用transformers进行推理的理论最小值,并且BF16的结果是在attn_implementation="flash_attention_2"的情况下测试得到的,但是在实际中,内存使用通常比这个值要高至少1.2倍。
推理及训练的便捷硬件资源计算器,可以从这里获取
1.2、环境搭建
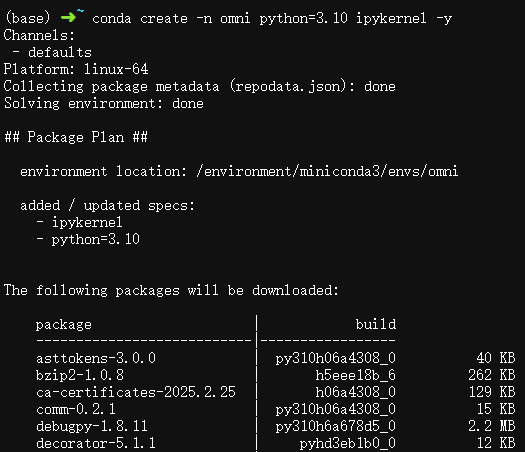
创建虚拟环境:
$ conda create -n omni python=3.10 ipykernel -y
进入虚拟环境:
$ conda activate omni
将omni虚拟环境添加到Jupyter内核中
$ python -m ipykernel install --user --name=omni

在虚拟环境安装依赖包:
$ pip install modelscope
1.3、下载Qwen2.5-Omni模型
打开魔搭社区,按模型名称搜索,连接放这里。
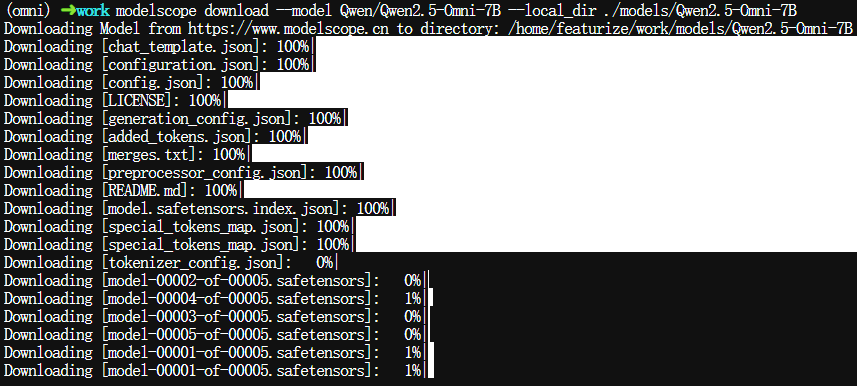
$ modelscope download --model Qwen/Qwen2.5-Omni-7B --local_dir ./models/Qwen2.5-Omni-7B
2. Docker部署Qwen2.5-Omni多模态模型
模型在DockerHub的名称如下,使用的是CUDA12.1构建的:
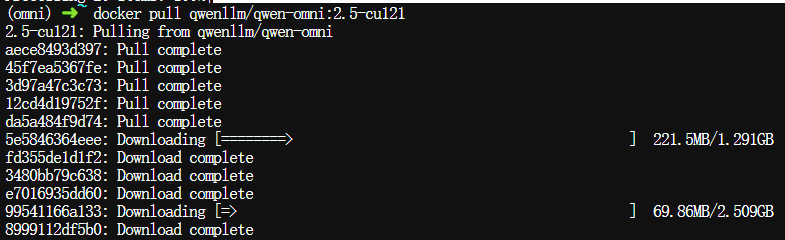
2.1、拉取镜像文件
$ docker pull qwenllm/qwen-omni:2.5-cu121
这个镜像有22G,没有开代理,也可以从网盘上获取然后上传到服务器:

然后通过 docker load 加载到服务器本地:
docker load -i mirror-image/qwen-omni.tar
镜像依赖nvidia-container-toolkit,因此需事先安装,本教程提供了一健安装nvidia-container-toolkit.sh的脚本。
#!/bin/bash
available() { command -v $1 >/dev/null; }
error() { echo "ERROR $*"; exit 1; }
SUDO=
if [ "$(id -u)" -ne 0 ]; then
# 以root用户运行,不需要sudo
if ! available sudo; then
error "该脚本需要超级用户权限,请以root身份重新运行."
fi
SUDO="sudo"
fi
echo "准备开始安装nvidia container toolkit..."
echo "获取GPG密钥..."
# 使用curl命令获取GPG公钥
# 并使用gpg --dearmor命令将其转换为二进制格式,保存到/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg文件中
# curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | $SUDO gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -fsSL https://mirrors.ustc.edu.cn/libnvidia-container/gpgkey | $SUDO gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
echo "获取nvidia-container-toolkit软件源列表..."
# 获取nvidia-container-toolkit软件源列表
# 使用sed修改软件源列表,在其中的【deb https://】两字符中间添加【[signed-by=....gpg]】这串内容,用于验证软件包的GPG密钥位置
# 最后保存到/etc/apt/sources.list.d目录下
curl -s -L https://mirrors.ustc.edu.cn/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
$SUDO sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
$SUDO tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 查找包含experimental字符串的行,并删除这些行开头的#号
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
echo "更新软件包列表..."
$SUDO apt-get update
echo "正式安装nvidia container toolkit..."
$SUDO apt-get install -y nvidia-container-toolkit
echo "修改Dcoker的配置文件并重启Docker..."
# 使用nvidia-ctk命令修改【/etc/docker/daemon.Json】文件,以便Docker可以使用NVIDIA容器运行时
$SUDO nvidia-ctk runtime configure --runtime=docker
$SUDO systemctl restart docker
echo "nvidia container toolkit安装成功."
以上保存为install-nvidia-container-toolkit.sh,并赋予执行权限:
$ chmod +x install-nvidia-container-toolkit.sh
运行以下命令:
$ bash install-nvidia-container-toolkit.sh
再次确认nvidia-container-toolkit是否安装成功:
$ nvidia-container-toolkit --version

如果有正常打印出版本号,则安装成功。

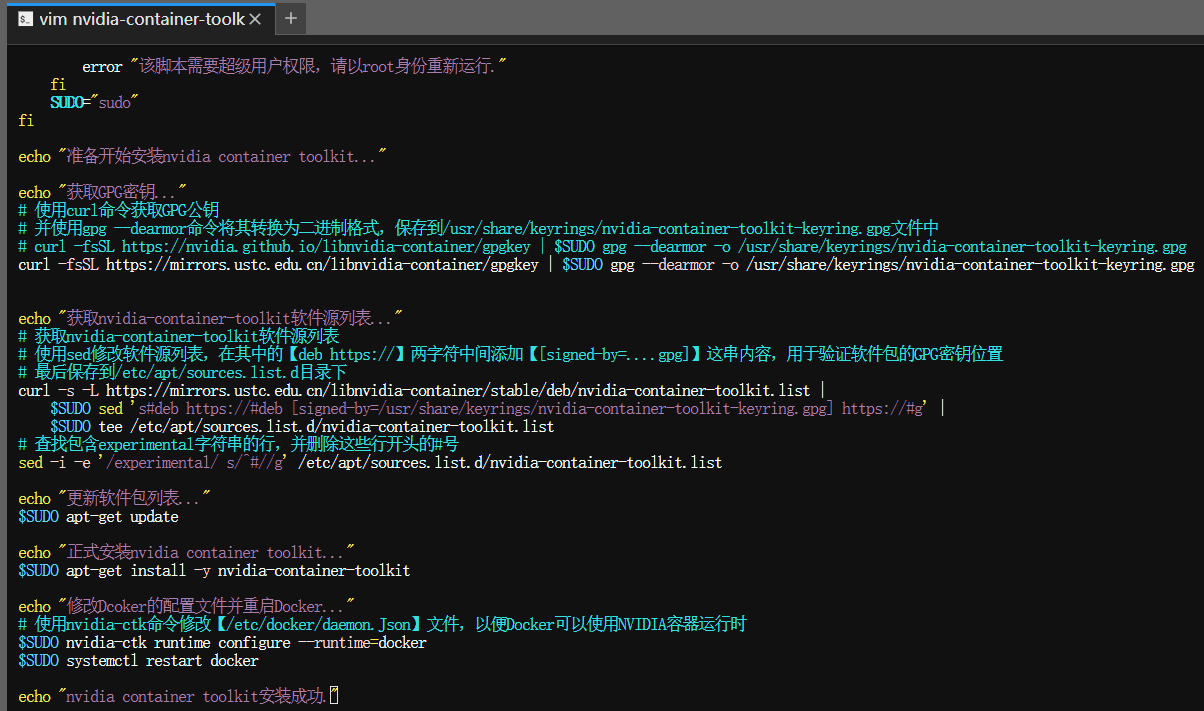
开始正式使用Docker部署Qwen2.5-Omni-7B全模态模型:
$ docker run \
--gpus all \
-id \
-v ./models/Qwen2.5-Omni-7B:/data/shared/Qwen/Qwen2.5-Omni-7B \
-p 8901:8901 \
--ipc=host \
--name omni \
--restart always \
qwenllm/qwen-omni:2.5-cu121 \
python web_demo.py \
--server-port 8901 \
--server-name 0.0.0.0 \
--checkpoint-path /data/shared/Qwen/Qwen2.5-Omni-7B \
--ui-language zh \
--flash-attn2
命令的几个关键参数解释如下:
- --gpus all:允许容器使用宿主机的所有 GPU(需已安装nvidia-container-toolkit)
- --ipc=host:共享宿主机的 IPC命名空间,提升 GPU 计算效率
- -v ./Qwen2.5-Omni-7B:/data/shared/Qwen/Qwen2.5-Omni-7B:将宿主机的 Qwen2.5-Omni-7B 模型目录挂载到容器的 /data/shared/Qwen/Qwen2.5-Omni-7B 目录下,方便模型加载
- web_demo.py :启动的入口文件
- --server-port 8901:服务监听端口
- --server-name 0.0.0.0:允许任意 IP 访问(默认只允许本地)
- --checkpoint-path:指定模型路径(需与 -v 挂载路径一致)
- --ui-language zh:启动中文界面的WEBUI
- --flash-attn2:启用 Flash Attention 2 加速推理。为了获得更好的性能和效率,尤其是处理大量图像和视频的场景下,我们强烈建议使用 FlashAttention-2。FlashAttention-2 提供了显存使用和速度的显著改进,因此对于处理大型模型和数据处理的场景,它非常合适。但是需要注意的是,FlashAttention-2 目前仅支持以下架构的 GPU:
- 支持Ampere、Ada 或 Hopper架构的 GPU(例如 A100、RTX 3090、RTX 4090、H100);
- 对图灵(Turing)架构的 GPU(T4、RTX 2080)的支持即将推出,如果是这个类型的,以上命令请删除
--flash-attn2;
通过查看容器持续输出日志,观察运行状态:
$ docker logs -f omni
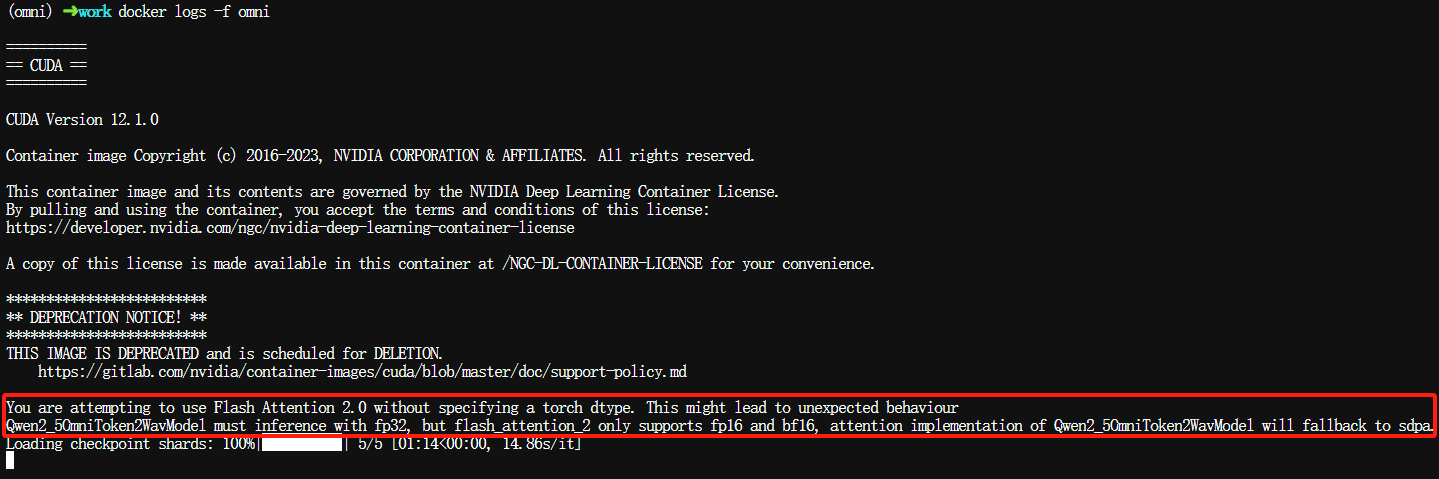
如果最终出现 Loading checkpoint shards: 100%,则表示容器中的模型权重已加载成功,就可以访问 WEBUI。
此时查看下GPU占用情况:
$ nvidia-smi
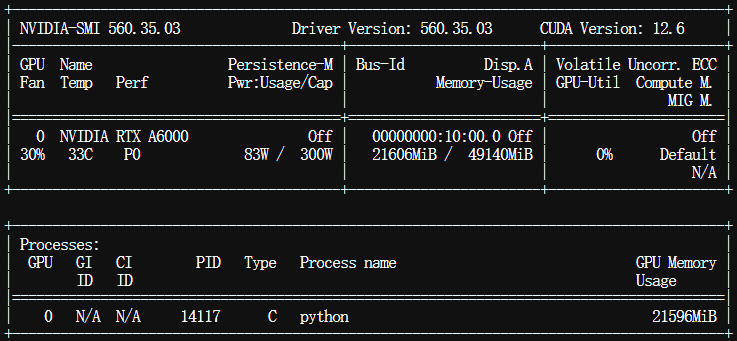
说明一开始只是加载了模型的权重文件,GPU显存占用为基本与模型的大小一致。
如果可能中出错误,要删除容器重新创建通过以下命令先删除:
$ docker rm -f omni
3. 和Qwen2.5-Omni对话
打开浏览器访问http://localhost:8901,即可打开一个由Gradio构造的WEB界面。
3.1、(可选)设置模型输出使用哪种音色去播放
该程序推理后,支持输出文字和音频,因此您可以选择播放音频的音色类型,目前支持两种如下两种音色类型:
| 音色类型 | 性别 | 描述 | ||
|---|---|---|---|---|
| Chelsie(默认) | 女 | 甜美,温婉,明亮,轻柔 | ||
| Ethan | 男 | 阳光,活力,轻快,亲和 |
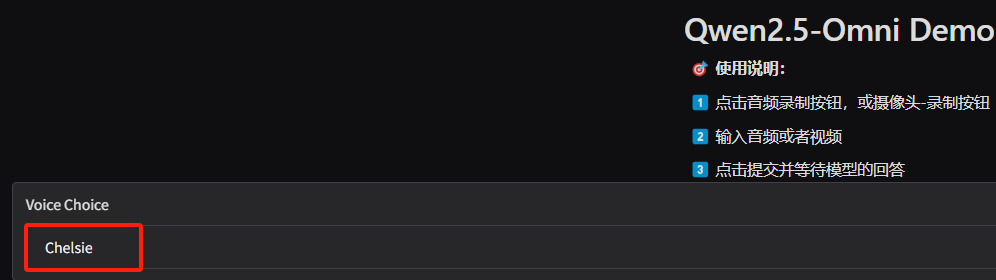
3.2、15秒内的离线音频文件对话
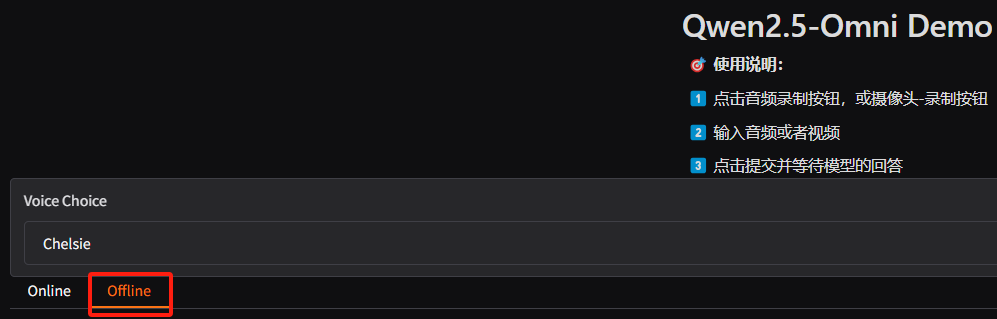
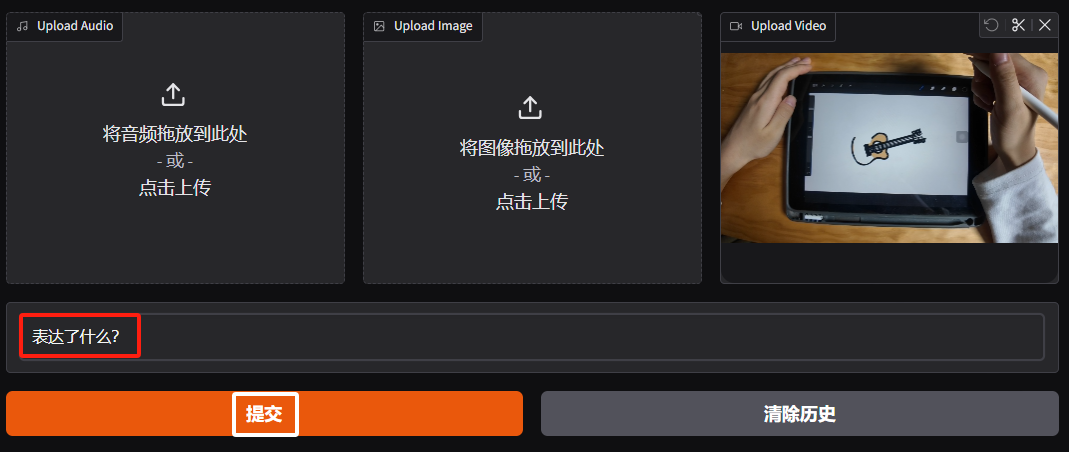
选择offline标签页,准备上传本地的音频、视频、图片和Qwen2.5-Omni模型进行对话。
鼠标滑动到页面底部,在upload Audio上传本地一个音频文件。
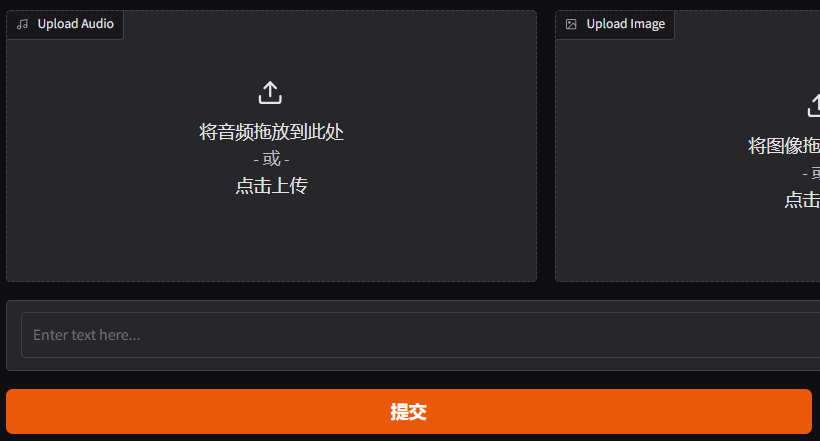
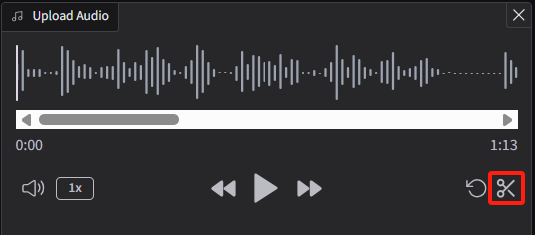
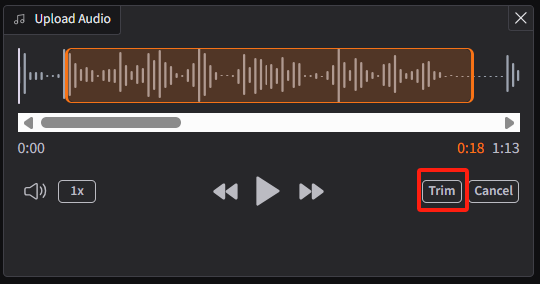
如果你的音频大于15秒,可以上传后通过页面自带的修剪按钮变短。
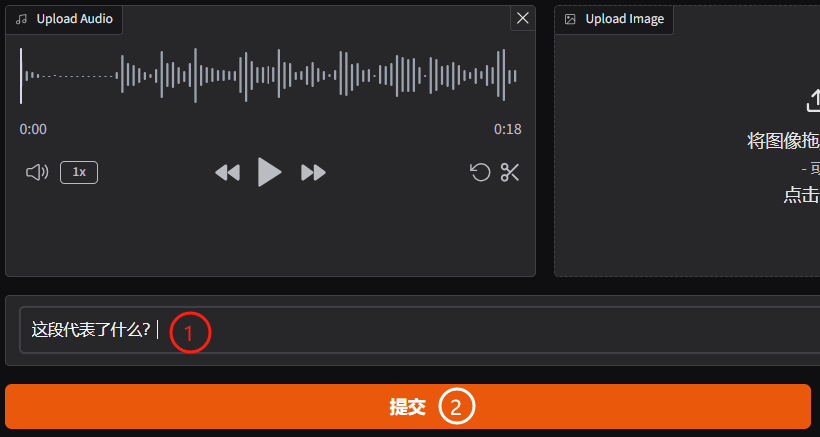
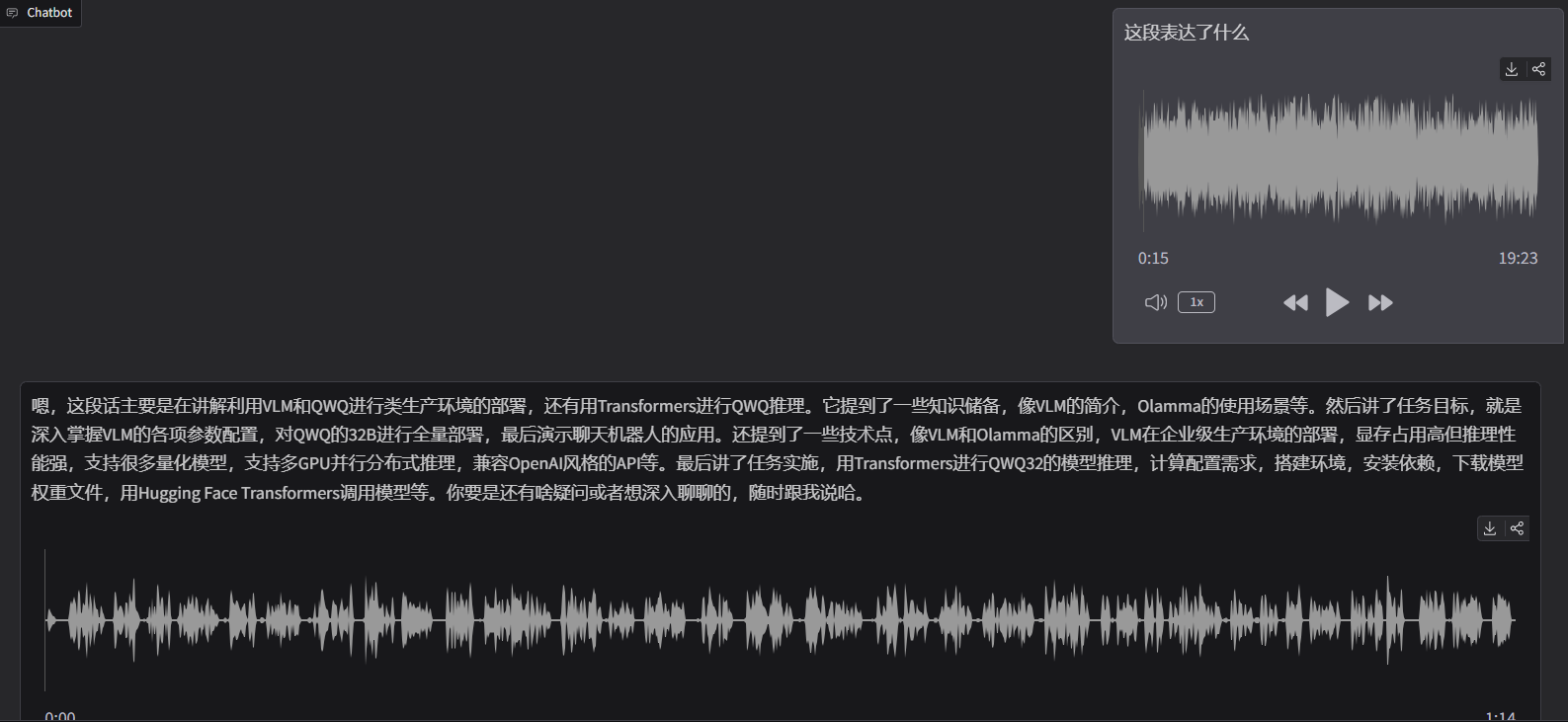
之后在文本输入框输入这段表述了什么?,点击提交按钮:
观察容器日志窗口,新生成了一条:

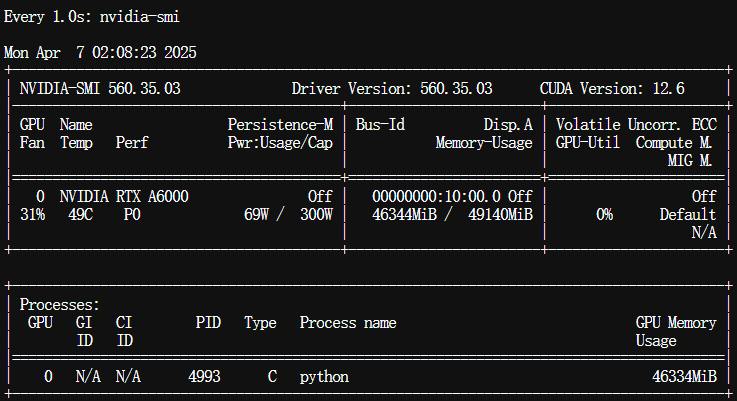
观察下GPU使用情况,大概在24G左右:
$ watch -n 1 nvidia-smi
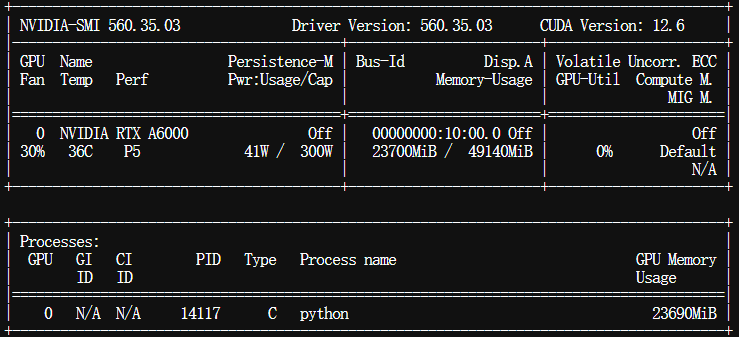
大概过了15秒后,模型输出了文字及音频的效果:

3.3、1分钟左右的离线音频文件对话
继续点击上传音频文件按钮,选择本地的音频文件,输入提示词:
模型的输出如下:
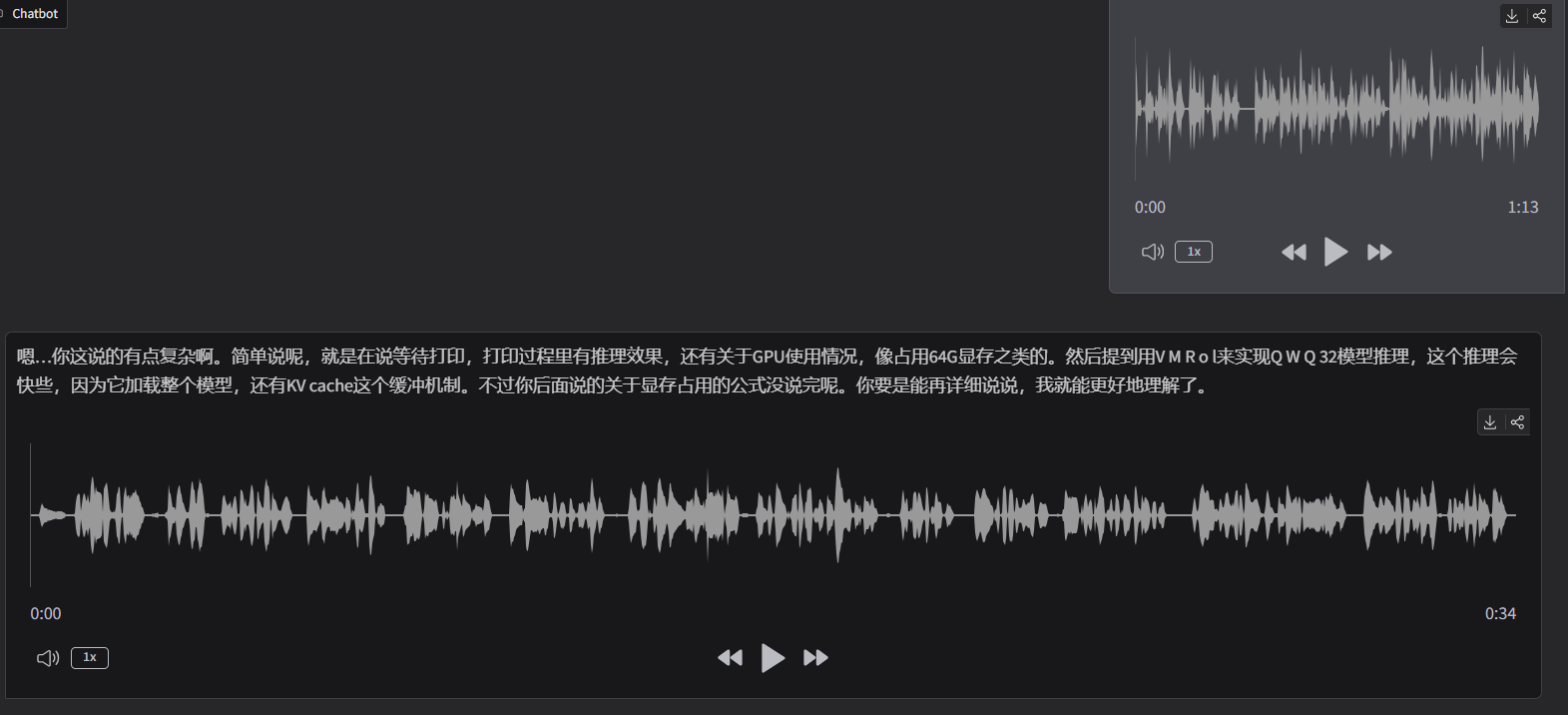
生成过程大约30来秒左右,GPU显存占用情况:
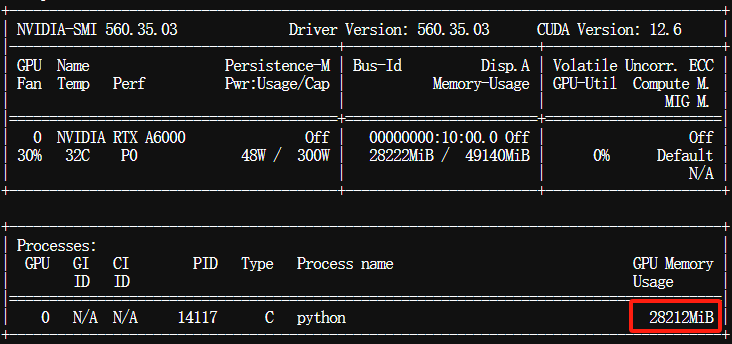
注:音频时长超过10分钟的,生成大约了5分钟,显存占用情况:
3.4、离线图片文件对话
继续使用图片作为演示,在upload image栏点击上传按钮:
选择任一一张图片,输入同样的提示词,点击提交按钮
也是需要经过10秒左右输出,如下图所示:
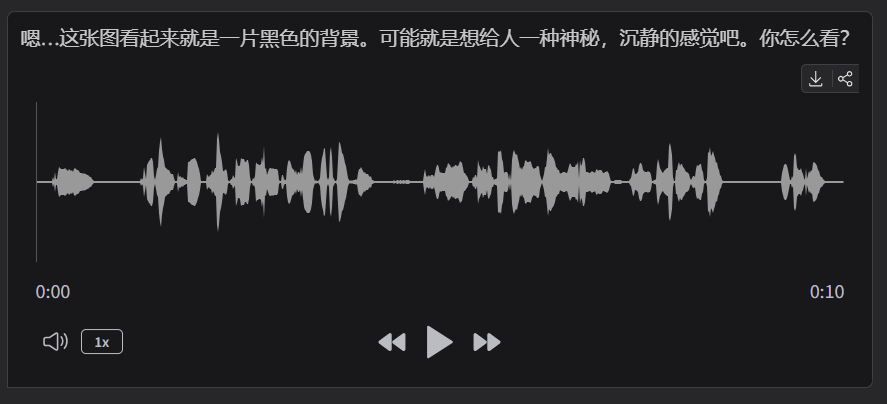
3.5、离线视频文件对话
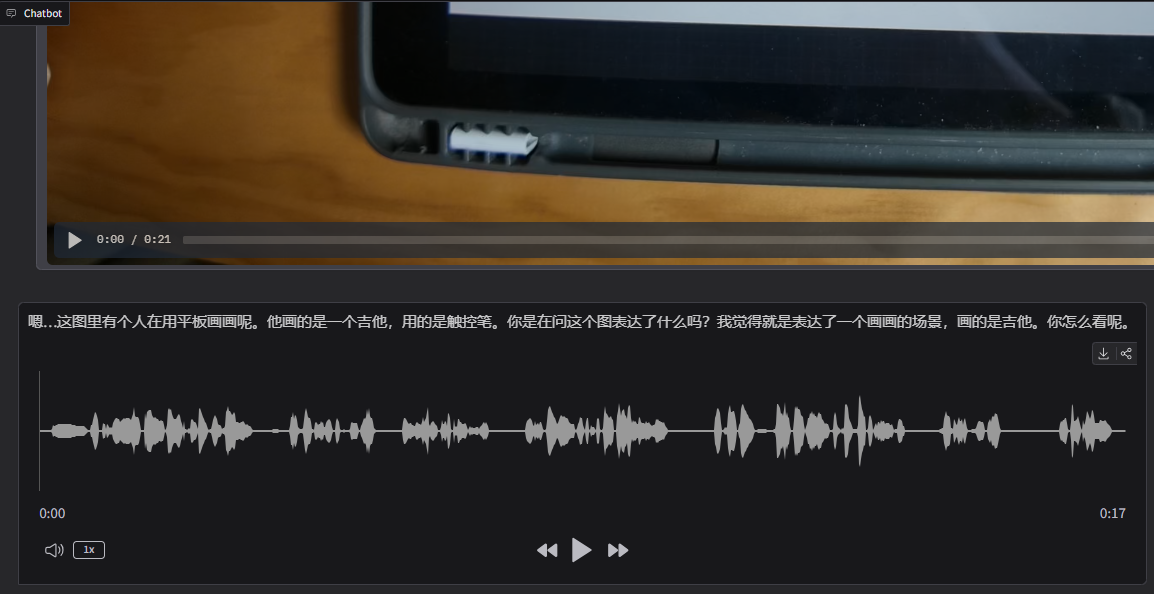
我们最后使用一个20秒左右的视频作为演示,你可以替换成你自己的视频文件。
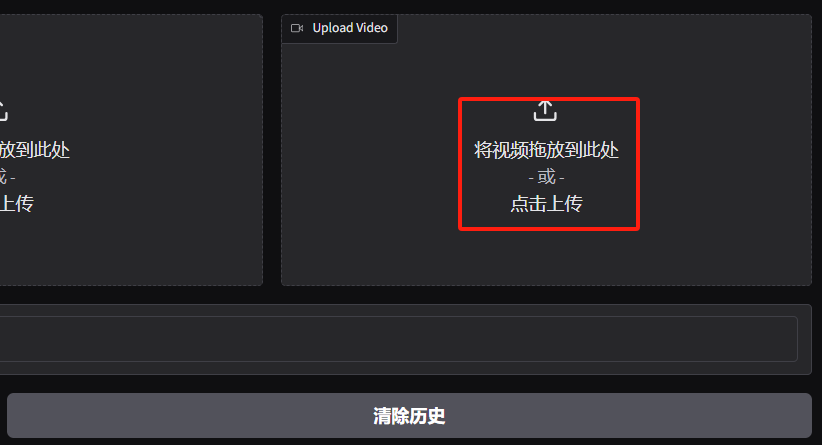
观察容器日志,发现一个错误输出:
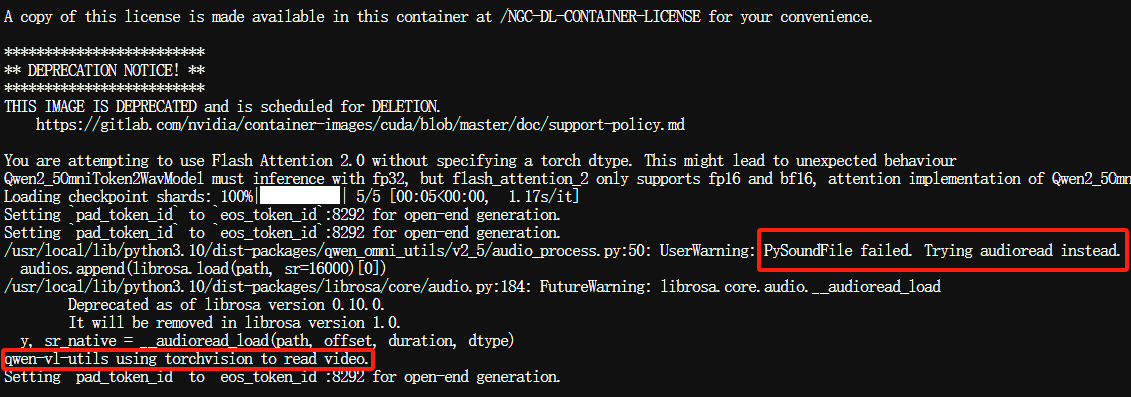
大概的意思是,准备用soundfile库读取视频,但失败,回退到使用audioread读取,效率上会有所下降。由于只是演示,就不重新去搭建。
生成过程大约15秒左右,最终输出如下:
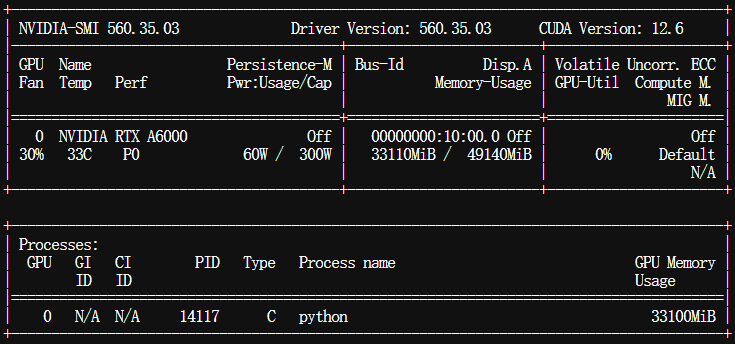
观察GPU占用情况,说明与音频同等时长的视频,GPU占用会多那么一些:
3.6、去除输出时生成音频,提升速度。
其实以上的操作不管是哪种文件格式的输入,主要是模型输出时会把文本重新生成成音频文件再输出,因此占用了太多的时间,我修改了web_demo.py代码,默认不生成音频输出,从而提升速度。
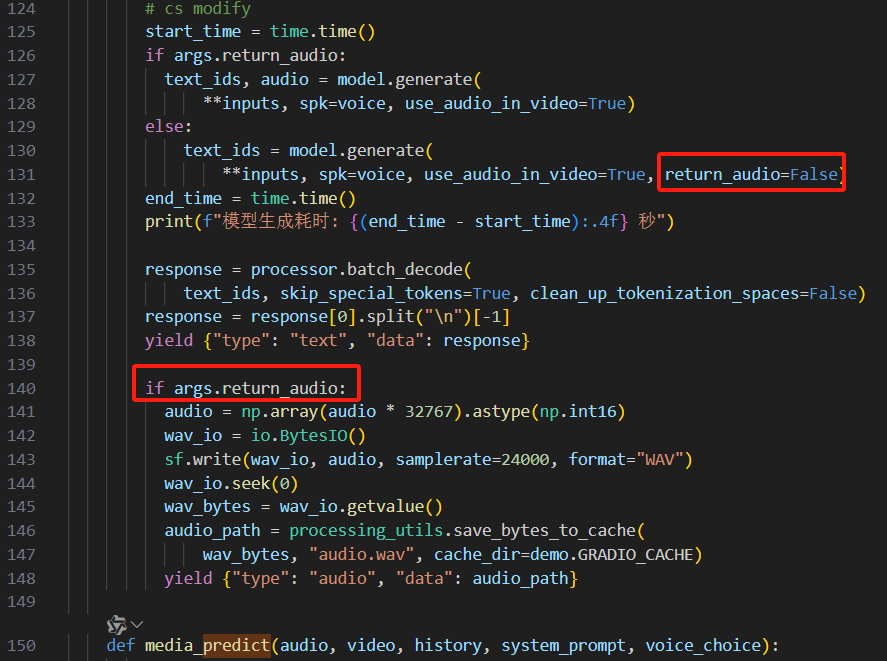
将当前目录下的web_demo.py拷贝进omni容器,此举会覆盖容器里面的web_demo.py文件:
$ docker cp web_demo.py omni:/data/shared/Qwen
![]()
然后重新启动容器,让容器重新运行替换过的web_demo.py文件:
$ docker restart omni
再次上传图片、音频或视频文件观察GPU占用及输出速度,看有什么变化。
最后体验总结一下:
- 模型的能力还是比较强:对于音视频以及图片的识别、感知效果还是很强的,图像,音频,音视频等各种模态下的表现都优于类似大小的单模态模型以及封闭源模型,例如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro。在多模态任务Qwen2.5-Omni达到了SOTA的表现
- 全能创新架构:它提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。我们提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步
- 自然流畅的类人语:包括拟声词、音律等,同时以流式的方式生成文本和自然语音响应。
4. vLLM推理Qwen2.5-Omni多模态模型
我们建议使用vLLM进行Qwen2.5-Omni的快速部署和推理,但因为目前Transformers、vLLM官方暂时还未支持,所以需要从以下的vLLM开发分支源码构建vLLM以获取对Qwen2.5-Omni支持。
4.1、确保还在omniconda虚拟环境下,执行以下命令从transformers开发版源码安装transformers:
$ pip install git+https://github.com/huggingface/transformers@f742a644ca32e65758c3adb36225aef1731bd2a8
注意:官方原始给的https://github...@d40f54fc2f1524458669048cb40a8d0286f5d1d2这个是不行的,用上面给的。
继续安装加速库和阿里的omni工具包:
$ pip install accelerate qwen-omni-utils
4.2、克隆vLLM开发分支源代码,从vLLM开发分支源码构建vLLM:
$ git clone -b qwen2_omni_public_v1 https://github.com/fyabc/vllm.git
vLLM源码包也已放在网盘上:
进入vLLM源码目录,安装vLLM:
$ cd vllm && pip install .
安装过程会特别漫长,占用资源特别巨大,有时也会卡住、有时候还要等待几个小时,经过二次折腾,最终晚上挂在哪里,第二天成功安装。所以我不建议大家安装,看我的成果就好了,等待vLLM官方正式版本的支持,再通过pip安装。
4.3、完成完成,使用vLLM本地离线推理Qwen2.5-Omni,目前只支持vllm的thinker部分,只能输出的模型只能是文本。今后会支持模型的其他部分以实现音频输出。
在Jupyterlab中切换到omni内核:
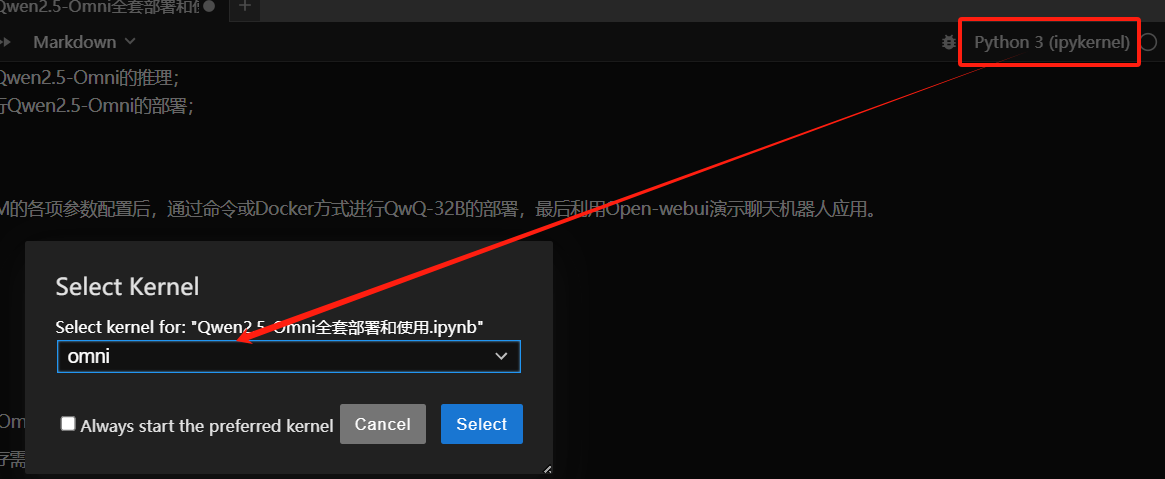
In [ ]:
# 导入库 import os import torch from transformers import Qwen2_5OmniProcessor from vllm import LLM, SamplingParams from qwen_omni_utils import process_mm_info
In [ ]:
# 定义环境变量及常量 os.environ['VLLM_USE_V1'] = '0' MODEL_PATH = "models/Qwen2.5-Omni-7B"
In [ ]:
# 实例化vLLM及采样参数,temperature设极低(确定性高,减少随机性)
llm = LLM(
model=MODEL_PATH,
trust_remote_code=True,
gpu_memory_utilization=0.9,
tensor_parallel_size=torch.cuda.device_count(), # 多卡并行
limit_mm_per_prompt={'image': 1, 'video': 1, 'audio': 1},
seed=1234,
)
sampling_params = SamplingParams(
temperature=1e-6,
max_tokens=512,
)
In [ ]:
# 定义消息列表(使用官方一个20秒的视频)
messages = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
In [ ]:
# 使用transformers的多模态输入(文本、图像、视频、音频)的预处理工具
processor = Qwen2_5OmniProcessor.from_pretrained(MODEL_PATH)
# 使用模型自带的对话模板格式化
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 使用千问自带的qwen_omni_utils工具提取视频/音频/图像数据
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
In [ ]:
# 定义模型输入为以上处理过的数据
inputs = {
'prompt': text[0],
'multi_modal_data': {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}
if images is not None:
inputs['multi_modal_data']['image'] = images
if videos is not None:
inputs['multi_modal_data']['video'] = videos
if audios is not None:
inputs['multi_modal_data']['audio'] = audios
In [ ]:
# 生成输出
outputs = llm.generate(inputs, sampling_params=sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"生成文本: {generated_text!r}")
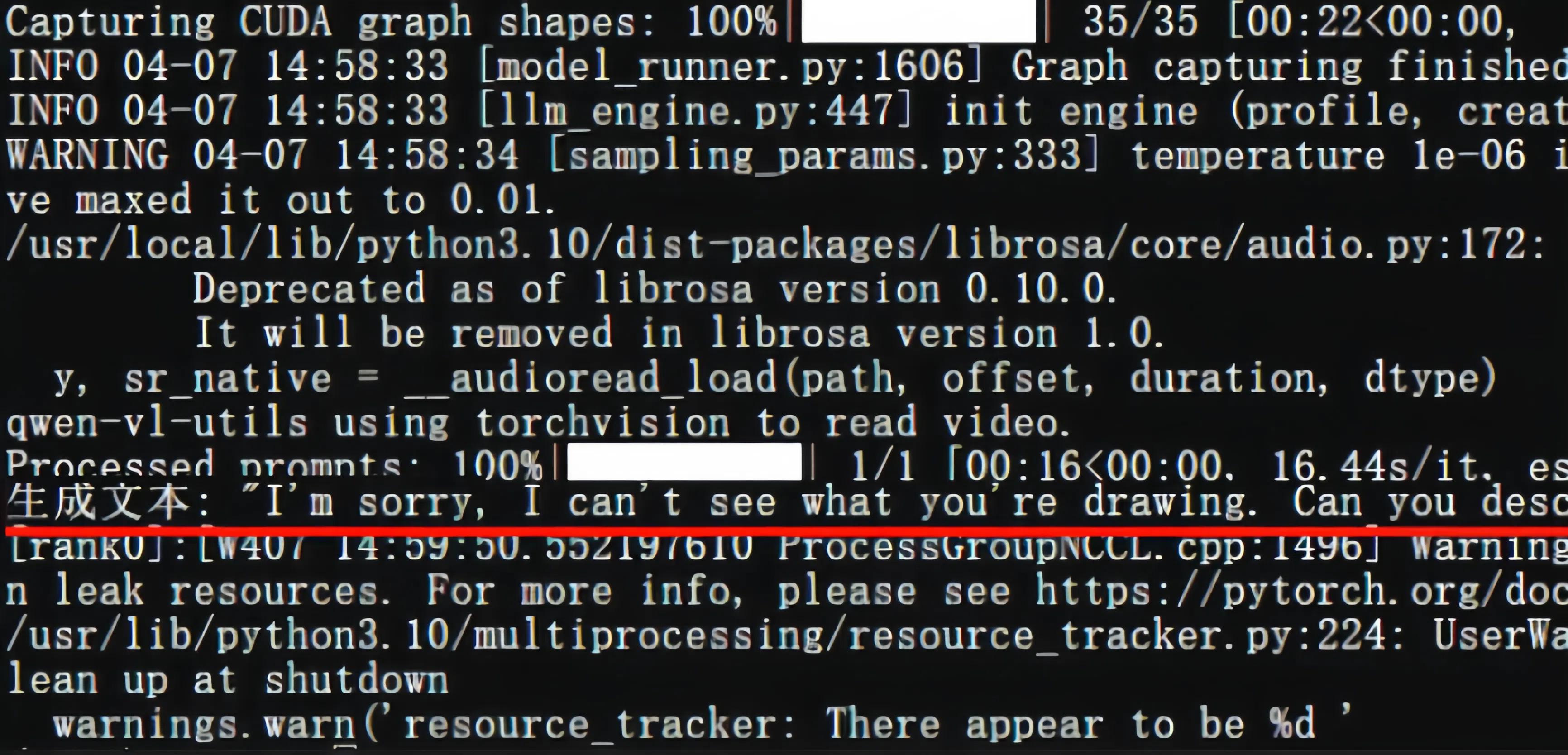
观察GPU使用情况:
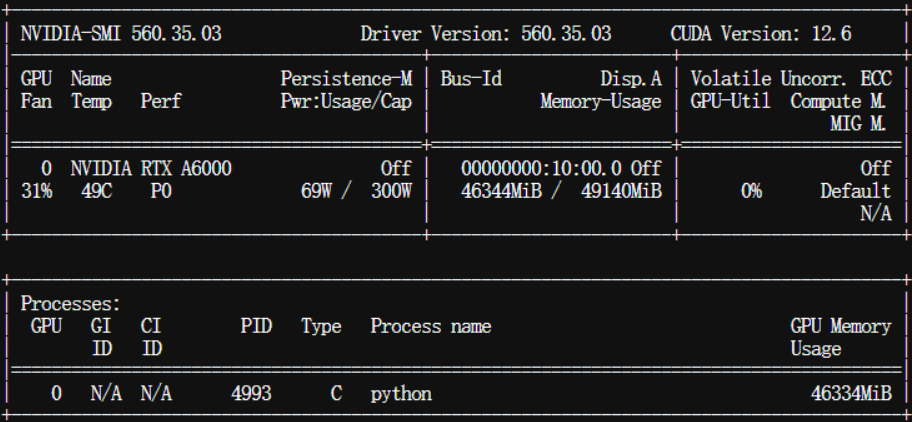
5. Omni镜像自带的vLLM进行Qwen2.5-Omni推理
qwenllm/qwen-omni镜像本身带有Qwen自己团队修改的vLLM版本,来支持omni的推理,但暂未被使用。我们就利用一下来做演示,避免自行安装浪费大量时间。
vllm_omni.py完成代码如下:
# 导入库
import os
import torch
from transformers import Qwen2_5OmniProcessor
from vllm import LLM, SamplingParams
from qwen_omni_utils import process_mm_info
import time
# 定义环境变量及常量
os.environ['VLLM_USE_V1'] = '0'
MODEL_PATH = "/data/shared/Qwen/Qwen2.5-Omni-7B"
# 实例化vLLM及采样参数,temperature设极低(确定性高,减少随机性)
llm = LLM(
model=MODEL_PATH,
trust_remote_code=True,
gpu_memory_utilization=0.9,
tensor_parallel_size=torch.cuda.device_count(),
limit_mm_per_prompt={'image': 1, 'video': 1, 'audio': 1},
seed=1234,
)
sampling_params = SamplingParams(
temperature=1e-6,
max_tokens=512,
)
# 定义消息列表(使用官方一个20秒的视频)
messages = [
{
"role": "system",
"content": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.",
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# 使用transformers的多模态输入(文本、图像、视频、音频)的预处理工具
processor = Qwen2_5OmniProcessor.from_pretrained(MODEL_PATH)
# 使用模型自带的对话模板格式化
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
# 使用千问自带的qwen_omni_utils工具提取视频/音频/图像数据
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
# 定义模型输入为以上处理过的数据
inputs = {
'prompt': text[0],
'multi_modal_data': {},
"mm_processor_kwargs": {
"use_audio_in_video": True,
},
}
if images is not None:
inputs['multi_modal_data']['image'] = images
if videos is not None:
inputs['multi_modal_data']['video'] = videos
if audios is not None:
inputs['multi_modal_data']['audio'] = audios
# 计时开始
start_time = time.time()
# 生成输出
outputs = llm.generate(
inputs, sampling_params=sampling_params)
# 计时结束
end_time = time.time()
# 计算耗时(秒)
execution_time = end_time - start_time
print(f"生成耗时: {execution_time:.4f} 秒")
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"生成文本: {generated_text!r}")
将当前目录下的vllm_omni.py拷贝进omni容器,此举会覆盖容器里面的web_demo.py文件:
$ docker cp vllm_omni.py omni:/data/shared/Qwen/web_demo.py
在宿主机打开一个新的终端,然后重启容器:
$ docker restart omni
![]()
打开一个新终端查看容器控制台输出:
$ docker logs -f omni
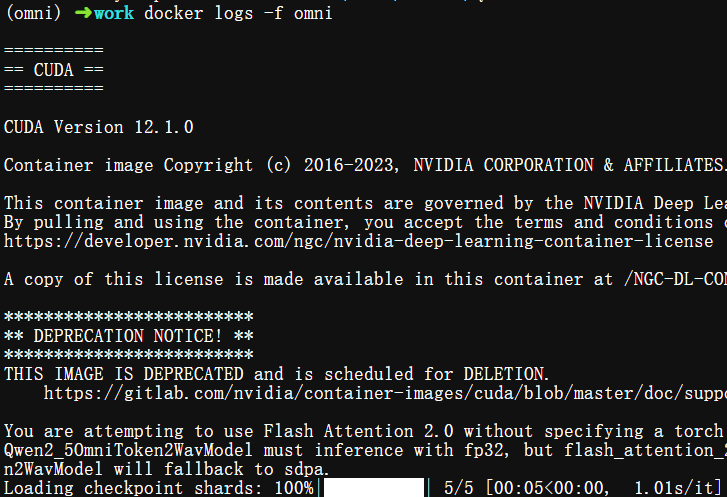
观察控制台输出以及GPU使用情况:
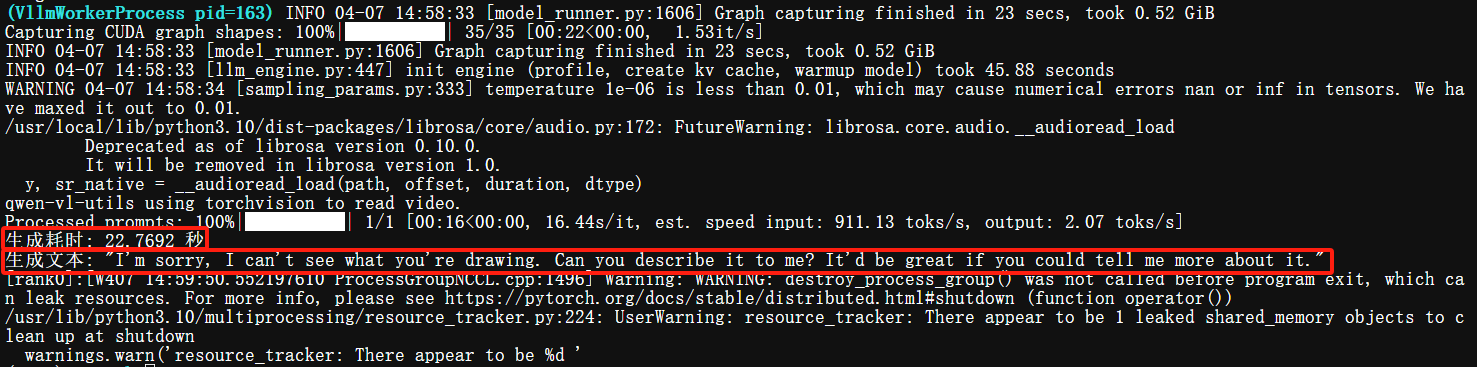
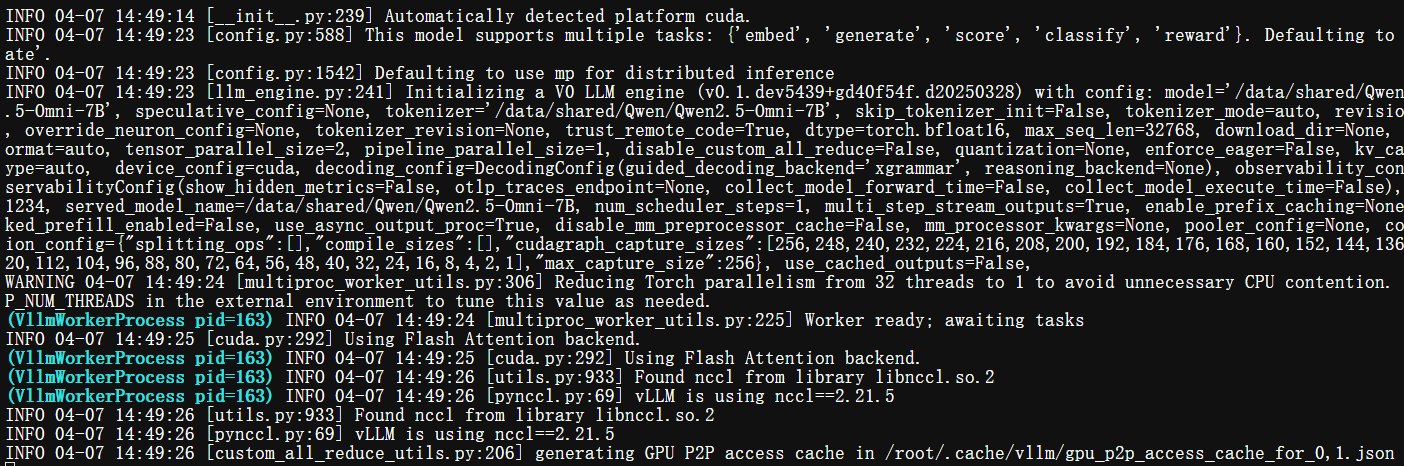
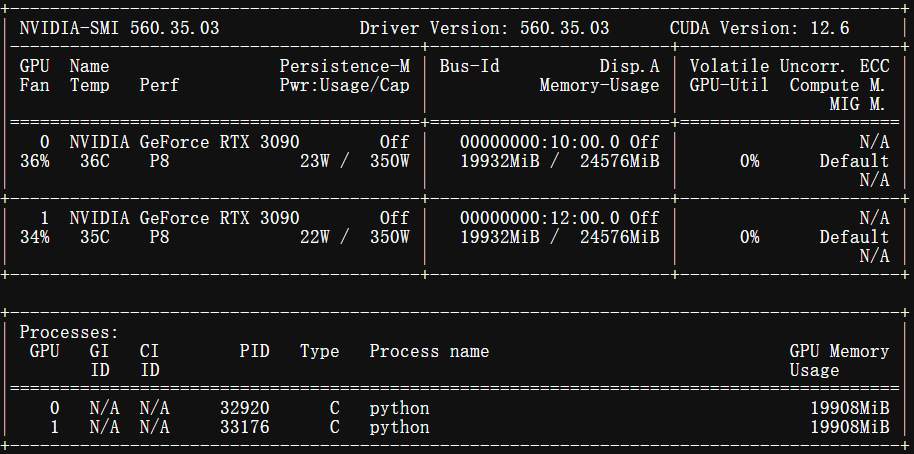
你也可以自行更换图像、音视频地址,体验它的效果。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











