







1. 运行环境要求
1.1、硬件环境
| 序 | 名称 | 建议配置 |
|---|---|---|
| 1 | CPU | Intel I7 |
| 2 | 显卡 | NVIDIA GeForce RTX 4090 |
| 3 | 内存 | 16G |
| 4 | 系统 | Ubuntu20.04 + |
注:根据微调的模型参数大小不同,显存要求也会不一样,参考值如下:
| 方法 | 精度 | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
Full (bf16 or fp16) | 32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
Full (pure_bf16) | 16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
1.2、软件环境
| 序 | 名称 | 版本 |
|---|---|---|
| 1 | Python | 3.10 |
| 2 | CUDA | 12.2 |
| 3 | JupyterLab | 3.5+ |
2. LLaMA Factory安装
在Jupyterlab中新建或打开一个命令行终端,本小节通过这个终端执行相关命令。
2.1、创建并配置虚拟环境
创建Conda新环境,名称可自定义,这里以微调英文缩写"llamafac"为例:
$ conda create -n llamafac python=3.10 ipykernel -y
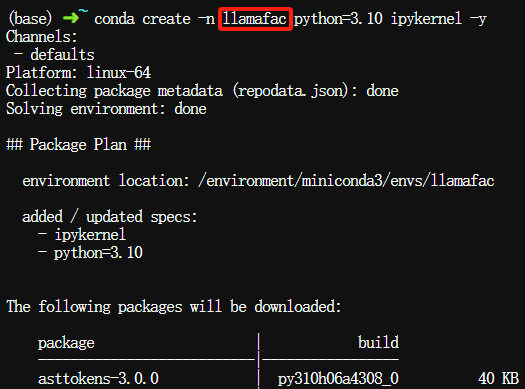
激活新建的环境:
$ conda activate llamafac

激活后,终端提示符通常会显示环境名称(llamafac),表示您已在该环境当中。
将llamafac虚拟环境加入到Jupyterlab的内核中,以便后续Jupyterlab可选到该环境:
$ python -m ipykernel install --user --name=llamafac --display-name "llamafac"

2.2、通过LLaMA-Factory源码安装
克隆LLaMA-Factory仓库到本地,会在当前目录下会生成LLaMA-Factory的文件夹
$ git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
- --depth 1:仅克隆最近一次提交版本,不包含完整历史记录,但可以节省时间和磁盘空间。
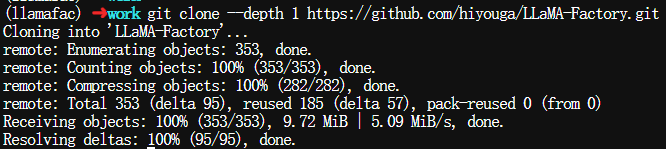
进入刚刚克隆的目录,所有后续命令将在 LLaMA-Factory 目录下执行:
$ cd LLaMA-Factory
![]()
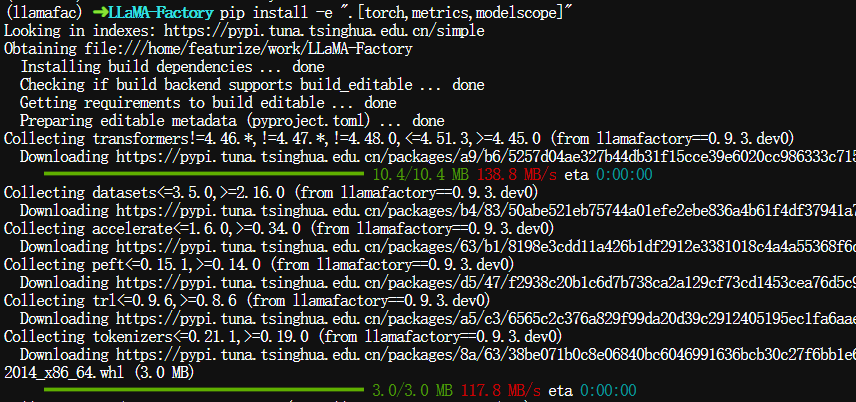
以"可编辑模式(或开发模式)"安装项目及其依赖库。
$ pip install -e ".[torch,metrics,modelscope]"
发现出现环境冲突,使用 pip install --no-deps -e . 解决
$ pip install --no-deps -e .
注:取消可编辑模式可以用 pip uninstall <包名>,然后正常安装(pip install .)
2.3、通过Pip安装LLaMA-Factory
$ pip install llamafactory
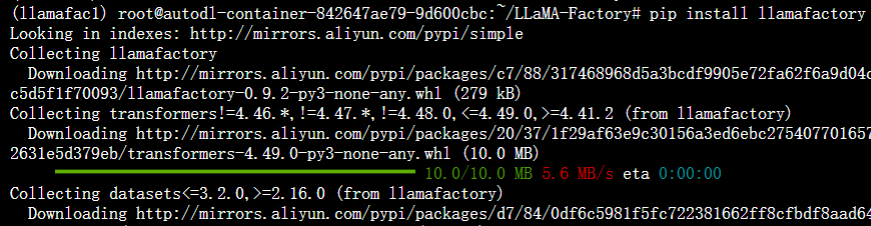
2.4、LLaMA-Factory验证
完成安装后,可以通过使用以下命令来快速验证安装是否成功。
$ llamafactory-cli version
个别环境如果出现socksio包未安装提示,执行提示的安装命令,接着继续执行版本查看命令。

$ pip install "httpx[socks]"

如果您能成功看到类似下面的界面,就说明安装成功了。

LLaMA-Factory安装成功后,默认提供了llamafactory-cli命令行工具,该工具提供了便捷的方式执行模型训练/微调、推理和管理等操作,无需深入代码细节。其中工具包含了多个子命令如下:
输入带-h参数,列出工具包含哪些子命令。
$ llamafactory-cli -h
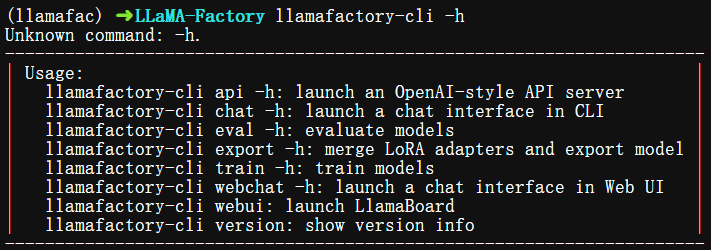
- llamafactory-cli train:用于训练微调模型;
- llamafactory-cli eval:评估模型性能(如准确率、推理速度等);
- llamafactory-cli export:合并 LoRA 等适配器并导出成完整模型;
- llamafactory-cli webchat:启动一个以"网页版"形式的聊天界面;
- llamafactory-cli chat:启动一个以"命令行"形式的聊天界面;
- llamafactory-cli api:启动一个 OpenAI 风格的 API 服务器;
- llamafactory-cli webui:启动一个由Gradio构造的、"网页版"形式的 LlamaBoard 界面,将模型训练、评估、模型管理等全部可视化操作,适合零代码用户。
3. LLaMA Board可视化WebUI启动&设置
第二小节已提到过,LLaMA-Factory支持通过 WebUI 可视化界面零代码训练、微调大模型。该WebUI全称LLaMA Board,使用Gradio库构造,其交互体验效果好,支持模型训练全链路的一站式平台,一个好的功能离不开好的交互,Stable Diffusion的大放异彩的重要原因除了强大的内容输出效果,就是它有一个好的WebUI,这个LLaMA Board将训练大模型主要的链路和操作都在一个页面中进行了整合,所有参数都可以可视化地编辑和操作。
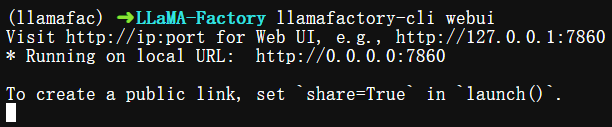
在完成LLaMA-Factory安装后,可以通过以下命令进入WebUI。
$ llamafactory-cli webui
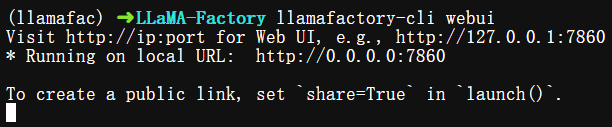
注:但目前webui只支持单机单卡和单机多卡,如果是多机多卡请使用LLaMA Factory CLI。
命令会启动一个默认监听7860端口的可视化WebUI(简称LLaMA Board),可通过浏览器访问http://localhost:7860来查看。如果要监听其它端口,可以设置GRADIO_SERVER_PORT环境变量,比如更改为8860端口,同时设置USE_MODELSCOPE_HUB为1,表示模型从 ModelScope 魔搭社区下载,避免从 HuggingFace下载导致网速不畅。
CTRL + C结束上面的进程,重新运行以下命令:
$ export USE_MODELSCOPE_HUB=1 GRADIO_SERVER_PORT=8860 && llamafactory-cli webui

通过ModelScope下载的模型,默认存储路径为~/.cache/modelscope/hub,也可以通过设置MODELSCOPE_CACHE环境变量来修改。
相关的环境变量有哪些呢?打开一个新命令行终端,查看项目的根目录下的.env.local文件(这里罗列了LLAMA Factory的所有环境变量的参考)
cat .env.local
# api API_HOST= API_PORT= API_KEY= API_MODEL_NAME= API_VERBOSE= FASTAPI_ROOT_PATH= MAX_CONCURRENT= # general DISABLE_VERSION_CHECK= FORCE_CHECK_IMPORTS= ALLOW_EXTRA_ARGS= LLAMAFACTORY_VERBOSITY= USE_MODELSCOPE_HUB= # 是否使用ModelScope Hub下载模型,默认为0 USE_OPENMIND_HUB= USE_RAY= RECORD_VRAM= OPTIM_TORCH= NPU_JIT_COMPILE= # torchrun FORCE_TORCHRUN= MASTER_ADDR= MASTER_PORT= NNODES= NODE_RANK= NPROC_PER_NODE= # wandb WANDB_DISABLED= WANDB_PROJECT= WANDB_API_KEY= # gradio ui GRADIO_SHARE= # 是否开启公网访问,默认为False GRADIO_SERVER_NAME= GRADIO_SERVER_PORT= # 监听的端口,默认为7860 GRADIO_ROOT_PATH= # 指定WebUI部署的路径 GRADIO_IPV6= # setup ENABLE_SHORT_CONSOLE= # reserved (do not use) LLAMABOARD_ENABLED= LLAMABOARD_WORKDIR=
在新的命令行终端中输入nvidia-smi,观察此时显存占用情况:
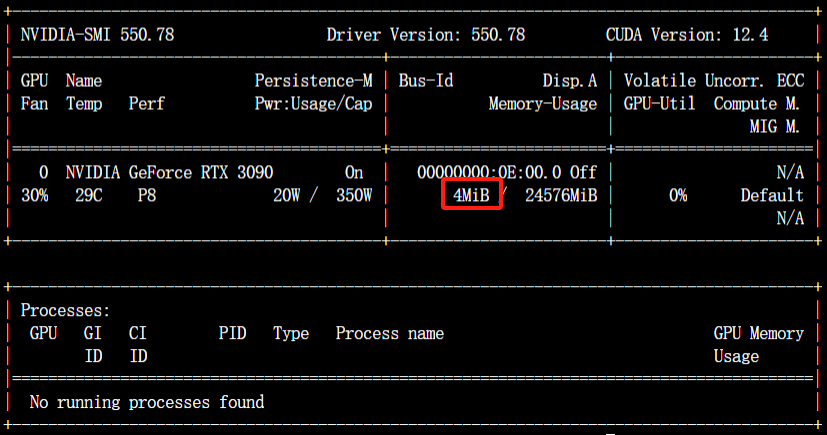
如果想以后台进程运行,可以结合一些nohup和守护进程工具。
nohup bash -c 'export USE_MODELSCOPE_HUB=1 GRADIO_SERVER_PORT=8860 && llamafactory-cli webui' > llamaboard.log 2>&1 &
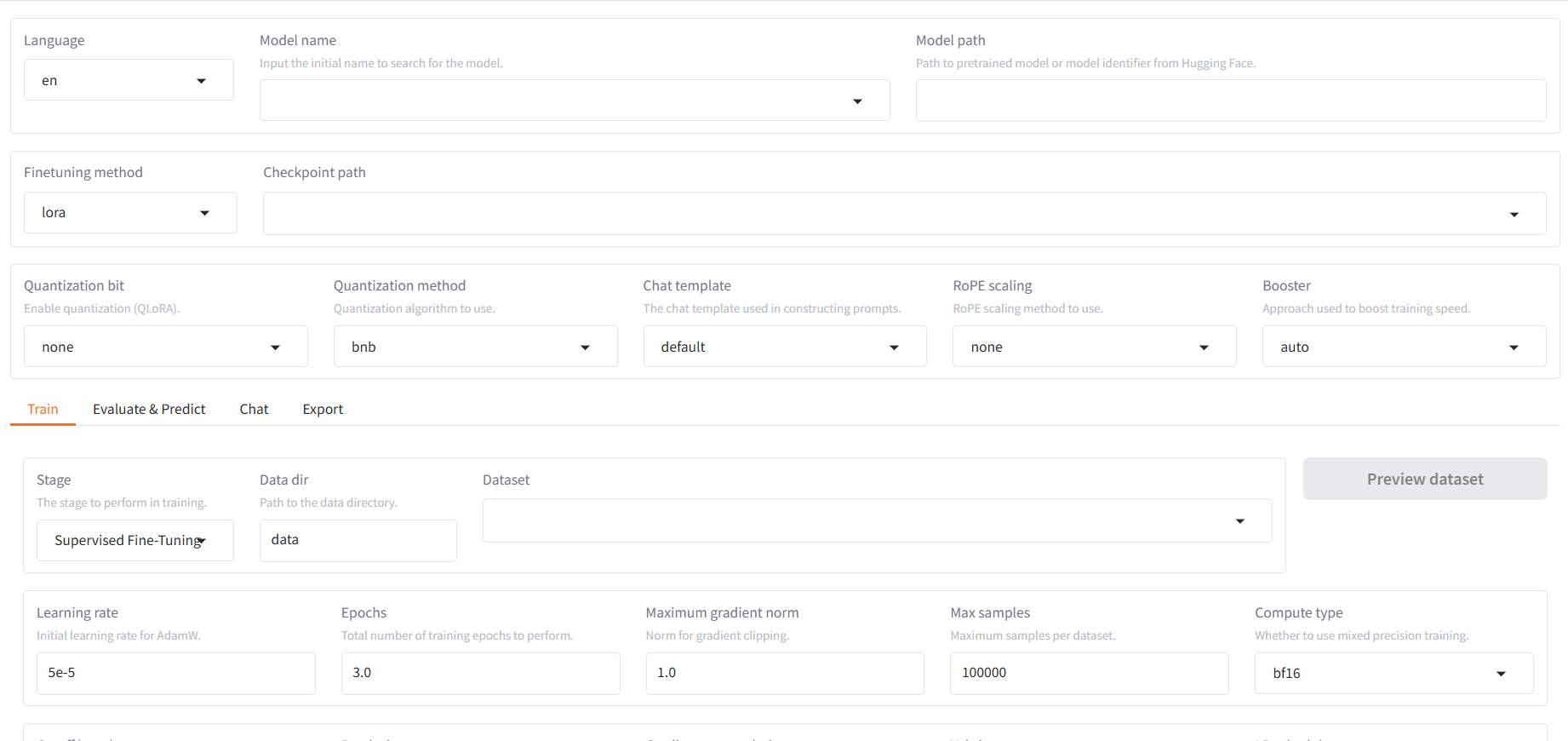
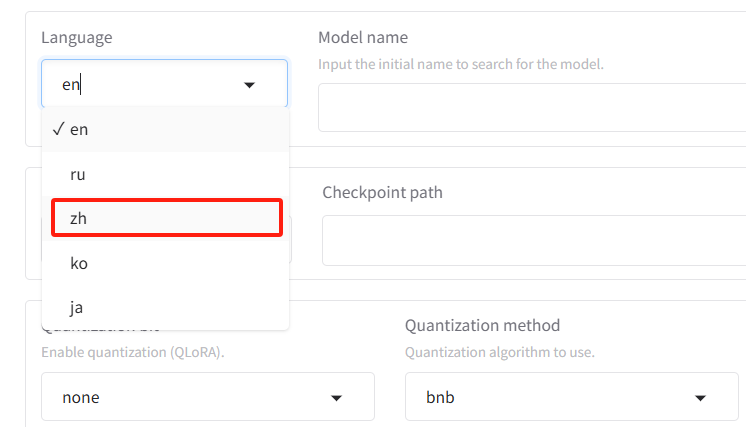
初次浏览,发现界面是不是很复杂,功能很多,不用担心,我们后续会通过具体的模型微调案例,来来介绍如何使用。我们第一步就是把语言更改为友好的中文。左上角Language选择中文:
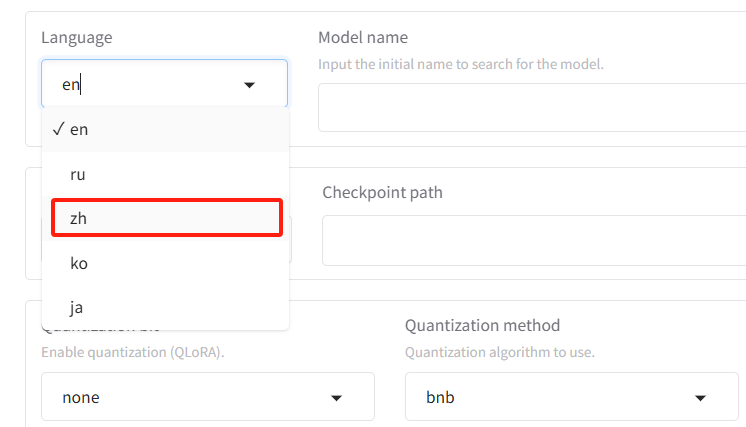
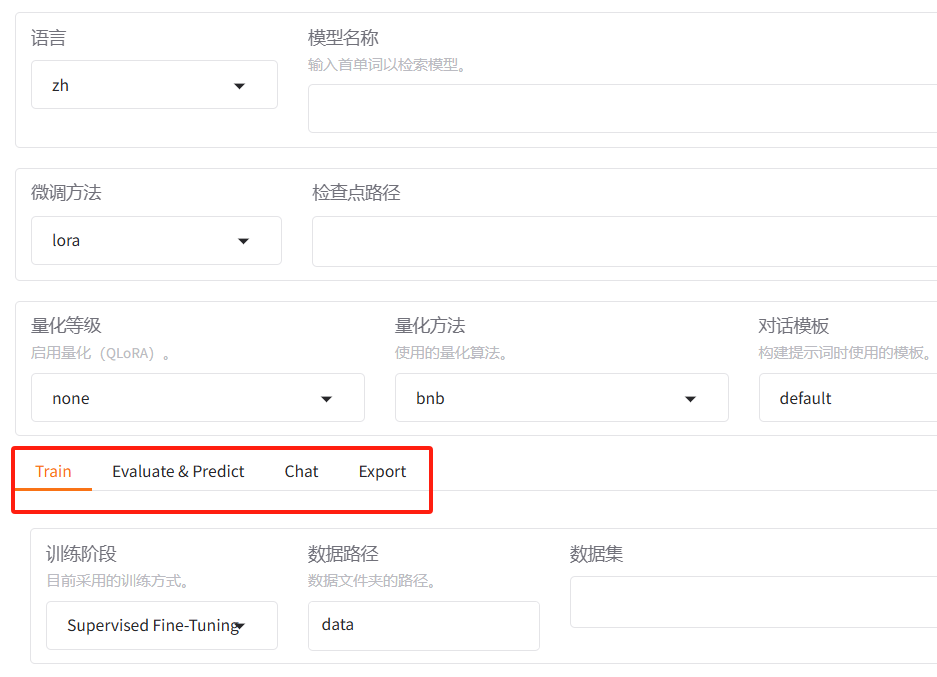
接着我们简单预览一下,它包含了哪个功能,归类一下有四个功能(tab界面):
- 训练(train):模型训练;
- 评估与预测(Evaluate & Predict):模型训练完后,可指定 模型 及 适配器 的路径通过该界面在指定数据集上进行评估;
- 对话(Chat):模型训练完后,可指定 模型 及 适配器 的路径,通过该界面进行可视化对话;
- 导出(Export):如果对模型微调效果满意并需要导出模型,可指定模型、适配器、量化等参数通过该界面后导出模型。
5. 微调Qwen2-VL多模态模型构建文旅大模型
该案例基于通义千问团队开源的多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 LLaMA Factory 训练框架完成文旅领域大模型的微调及构造。
5.1、原模型对话
在进行微调之前,我们先进行原始模型推理,先验证一下原始模型在对于文旅领域的回答效果。
在LLaMA-Board页面:
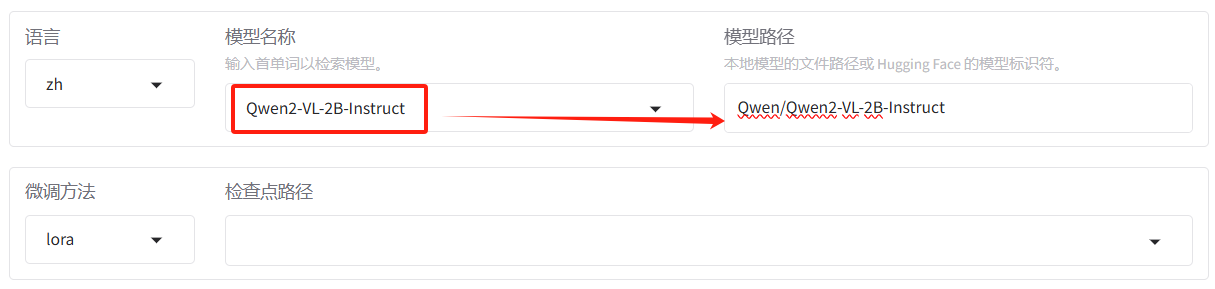
- 模型名称:选择
Qwen2-VL-2B-Instruct, - 模型路径:会自动显示出在Hugging Face的模型标识符
Qwen/Qwen2-VL-2B-Instruct。
接着切换到对话(Chat)页面:
- 推理引擎:选择hugging face的推理引擎,会使用原生transformers库;
- 推理数据类型:选择auto,会自动根据下载的模型配置文件
config.json识别出数据类型;
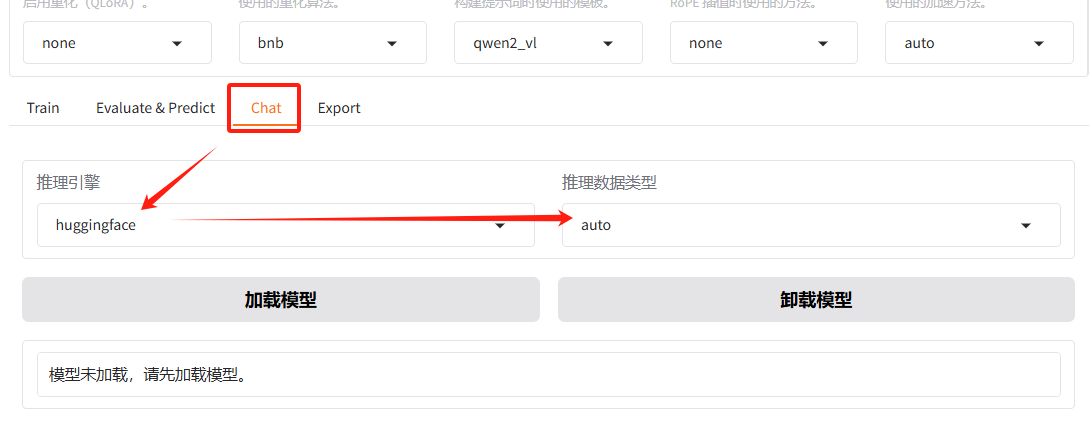
点击加载模型按钮,等待默认下载...
此时观察启动LLaMA Board的命令行终端,可以看到如下日志输入,代表正在下载模型(如果LLaMA Board是通过nohup启动,tail -f llamaboard.log可查看日志输出):

当显示模型已加载,则代表下载成功,如果失败,可以重复点击加载模型或检查网络。
新建一个命令行终端,输入以下命令查看已下载的模型:
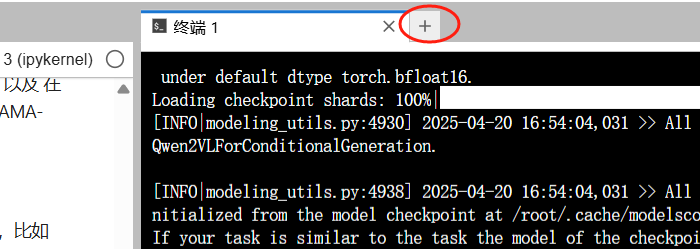
$ ls ~/.cache/modelscope/hub/models/Qwen/


某种情况下,为了统一管理模型,建议通过modelscope或git手动下载,存放到指定路径,然后后续使用时使用绝对路径来控制使用哪个模型,比如刚刚的模型,通过modelscope下载。
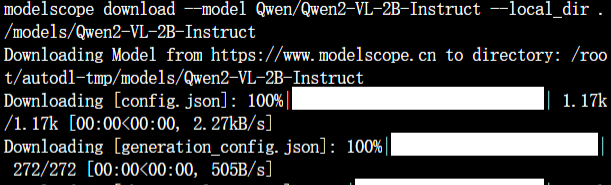
$ modelscope download --model Qwen/Qwen2-VL-2B-Instruct --local_dir ./models/Qwen2-VL-2B-Instruct
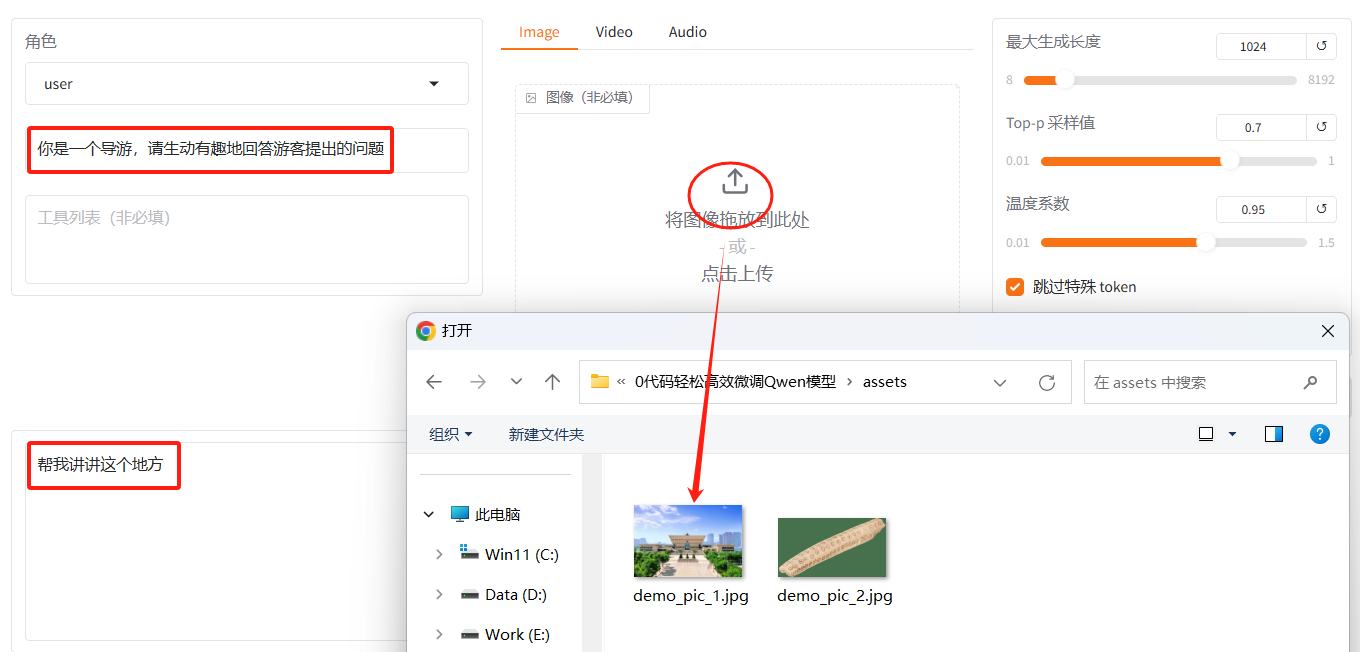
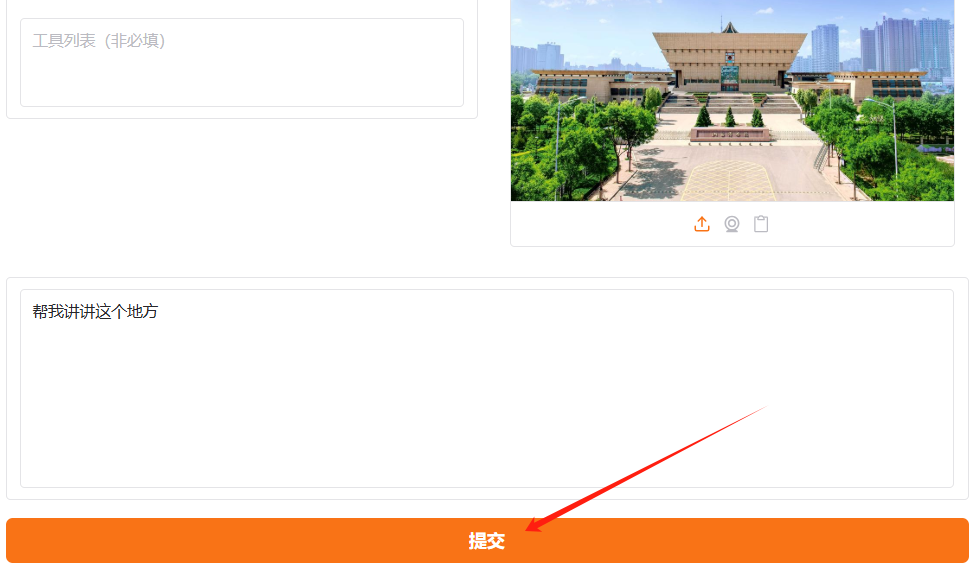
与LLaMA-Factory同级有个assets目录,存放着一些素材样图,选择demo_pic_1.jpg上传至对话框的图像区域,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。在页面底部的对话框输入“帮我讲讲这个地方”对话内容,点击提交即可发送消息。
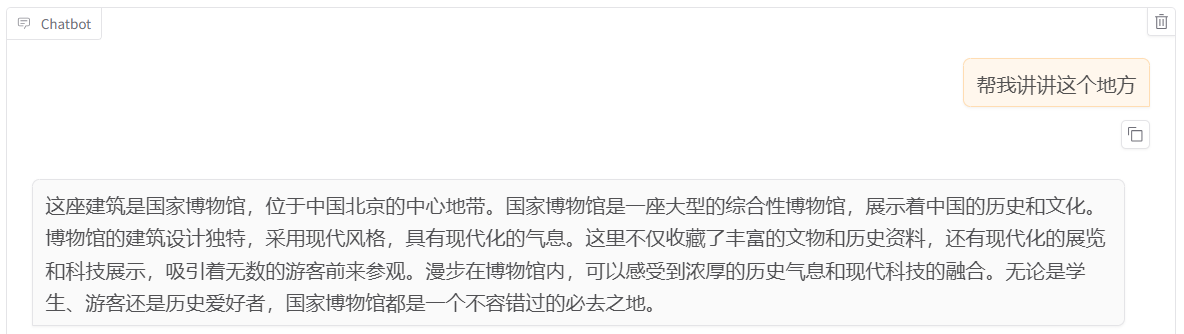
发送后模型会逐字生成回答,观察模型生成的内容,记录起来供后续对比(当然此时模型未学习到特定领域的知识,回答的相对比较笼统)。
为了不影响后续微微训练显存不足情况,建议将对话的模型卸载释放显存。
点击对话(Chat)窗口中的卸载模型按钮,即可卸载模型。
5.2、微调数据集准备
打开一个新的命令行终端,进入到教程根目录(LLaMA-Factory同级目录)。
本小节准备了一份基于ShareGPT格式的文旅方面的多模态图像数据集tourism-vl.zip,存放在datasets目录下:
通过unzip解压到tourism-vl目录下。
$ unzip datasets/tourism-vl.zip -d datasets/tourism-vl
3. LLaMA Board可视化WebUI启动&设置
第二小节已提到过,LLaMA-Factory支持通过 WebUI 可视化界面零代码训练、微调大模型。该WebUI全称LLaMA Board,使用Gradio库构造,其交互体验效果好,支持模型训练全链路的一站式平台,一个好的功能离不开好的交互,Stable Diffusion的大放异彩的重要原因除了强大的内容输出效果,就是它有一个好的WebUI,这个LLaMA Board将训练大模型主要的链路和操作都在一个页面中进行了整合,所有参数都可以可视化地编辑和操作。
在完成LLaMA-Factory安装后,可以通过以下命令进入WebUI。
$ llamafactory-cli webui
注:但目前webui只支持单机单卡和单机多卡,如果是多机多卡请使用LLaMA Factory CLI。
命令会启动一个默认监听7860端口的可视化WebUI(简称LLaMA Board),可通过浏览器访问http://localhost:7860来查看。如果要监听其它端口,可以设置GRADIO_SERVER_PORT环境变量,比如更改为8860端口,同时设置USE_MODELSCOPE_HUB为1,表示模型从 ModelScope 魔搭社区下载,避免从 HuggingFace下载导致网速不畅。
CTRL + C结束上面的进程,重新运行以下命令:
$ export USE_MODELSCOPE_HUB=1 GRADIO_SERVER_PORT=8860 && llamafactory-cli webui

通过ModelScope下载的模型,默认存储路径为~/.cache/modelscope/hub,也可以通过设置MODELSCOPE_CACHE环境变量来修改。
相关的环境变量有哪些呢?打开一个新命令行终端,查看项目的根目录下的.env.local文件(这里罗列了LLAMA Factory的所有环境变量的参考)
cat .env.local
# api API_HOST= API_PORT= API_KEY= API_MODEL_NAME= API_VERBOSE= FASTAPI_ROOT_PATH= MAX_CONCURRENT= # general DISABLE_VERSION_CHECK= FORCE_CHECK_IMPORTS= ALLOW_EXTRA_ARGS= LLAMAFACTORY_VERBOSITY= USE_MODELSCOPE_HUB= # 是否使用ModelScope Hub下载模型,默认为0 USE_OPENMIND_HUB= USE_RAY= RECORD_VRAM= OPTIM_TORCH= NPU_JIT_COMPILE= # torchrun FORCE_TORCHRUN= MASTER_ADDR= MASTER_PORT= NNODES= NODE_RANK= NPROC_PER_NODE= # wandb WANDB_DISABLED= WANDB_PROJECT= WANDB_API_KEY= # gradio ui GRADIO_SHARE= # 是否开启公网访问,默认为False GRADIO_SERVER_NAME= GRADIO_SERVER_PORT= # 监听的端口,默认为7860 GRADIO_ROOT_PATH= # 指定WebUI部署的路径 GRADIO_IPV6= # setup ENABLE_SHORT_CONSOLE= # reserved (do not use) LLAMABOARD_ENABLED= LLAMABOARD_WORKDIR=
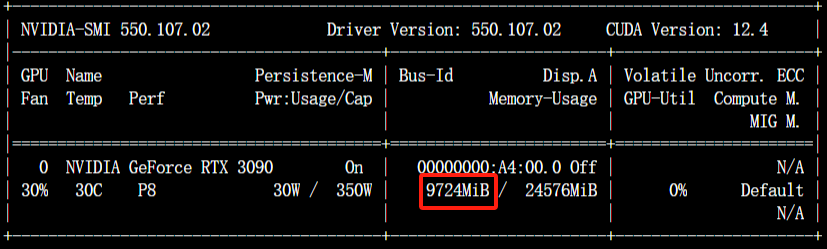
在新的命令行终端中输入nvidia-smi,观察此时显存占用情况:
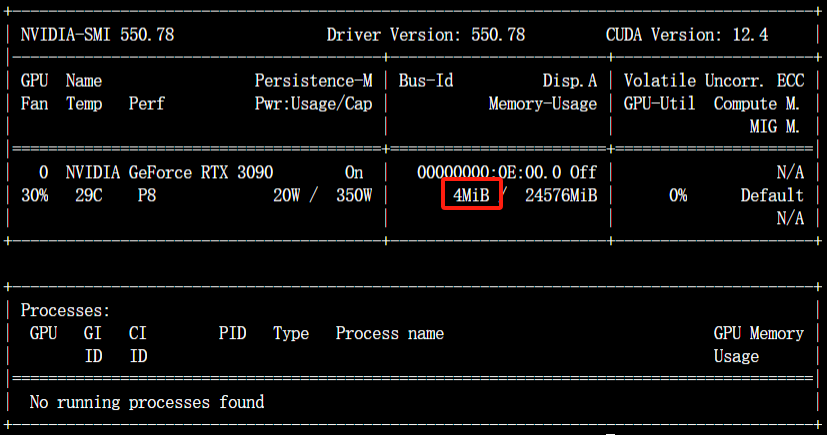
如果想以后台进程运行,可以结合一些nohup和守护进程工具。
nohup bash -c 'export USE_MODELSCOPE_HUB=1 GRADIO_SERVER_PORT=8860 && llamafactory-cli webui' > llamaboard.log 2>&1 &
初次浏览,发现界面是不是很复杂,功能很多,不用担心,我们后续会通过具体的模型微调案例,来来介绍如何使用。我们第一步就是把语言更改为友好的中文。左上角Language选择中文:
接着我们简单预览一下,它包含了哪个功能,归类一下有四个功能(tab界面):
- 训练(train):模型训练;
- 评估与预测(Evaluate & Predict):模型训练完后,可指定 模型 及 适配器 的路径通过该界面在指定数据集上进行评估;
- 对话(Chat):模型训练完后,可指定 模型 及 适配器 的路径,通过该界面进行可视化对话;
- 导出(Export):如果对模型微调效果满意并需要导出模型,可指定模型、适配器、量化等参数通过该界面后导出模型。
解压完在tourism-vl目录下将生成如下文件:
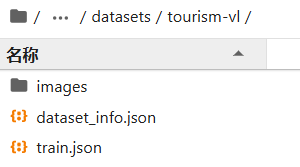
分别对应:
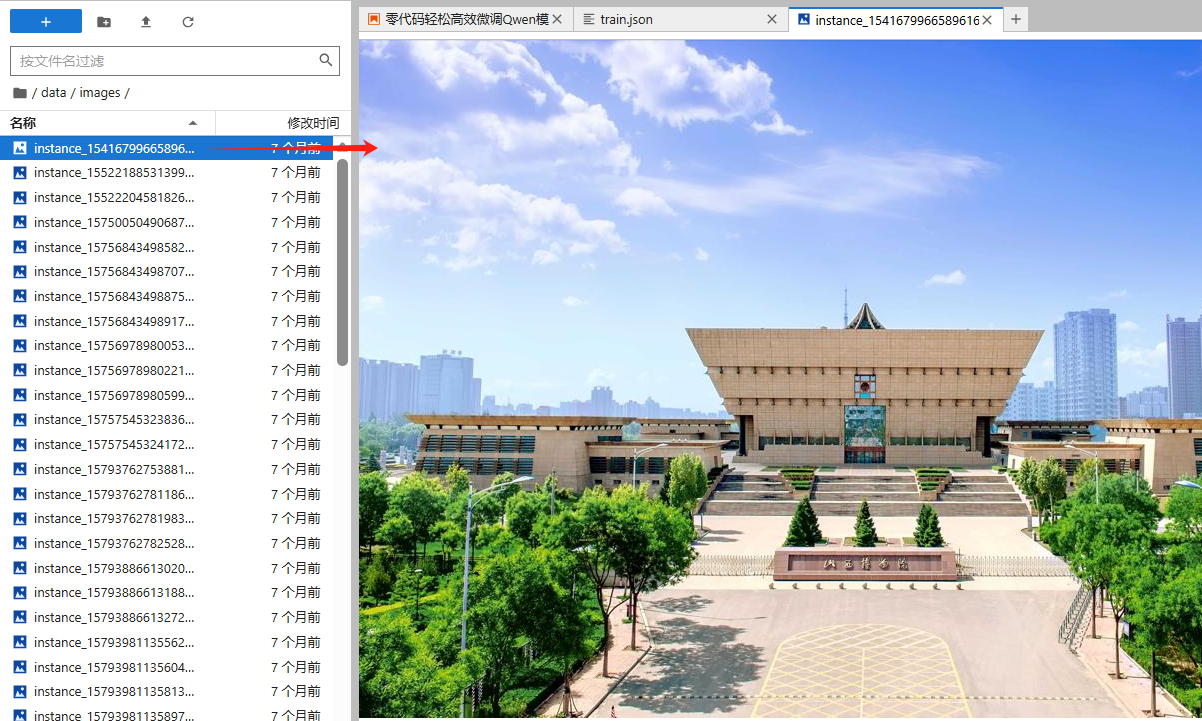
- train.json:数据集文件,数据集中的样本为单轮对话形式,含有 261 条样本,每条样本都由一条系统提示、一条用户指令和一条模型回答组成,微调过程中模型不断学习样本中的回答风格,从而达到学习文旅知识的目的。数据样例如下所示:

- images:数据集对应的图片文件
- dataset_info.json:只包含文旅游数据集的描述文件

以前内容对于LLaMA-Factory来说,已是完整的一个数据集,因此我们可以直接拷贝到LlaMA-Factory目录下。为了保存LlaMA-Factory目录下的原始内置数据集,我们先将原始数据集重命名为rawdata,再移动过去。
$ mv LLaMA-Factory/data LLaMA-Factory/rawdata && mv datasets/tourism-vl LLaMA-Factory/data


5.3、模型全参数微调
确认已启动LLaMA Board,若未启动,请移步至第3小节。
按照以下内容设置表单:
- 模型名称:Qwen2-VL-2B-Instruct;
- 模型路径:Qwen/Qwen2-VL-2B-Instruct。之前在推理时已下载了模型。若未下载启动微调时会自动下载。也可以手动下载,然后指定一个绝对路径;
- 微调方法:选择full,针对小模型使用全参微调方法能带来更好的效果,对显存的要求会更高(参考开头表格),可选的还有freeze, lora;
- 对话模板:一般每种模型都有自己的对话模板,选择模型名称时会自动识别出对应的对话模板;
- 加速方式:auto。
- flashattn2:能够加快注意力机制的运算速度,同时减少对内存的使用,需要特定GPU硬件支持;
- Unsloth:若使用HuggingFace + LoRA,适合快速部署,显存节省明显,但当前仅支持 Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen等大语言模型;
- liger_kernel:需手动集成,但对复杂模型和长序列任务优化更彻底;
- 操作页面:选择训练(Train);
- 训练阶段:选择Supervised Fine-Tuning(sft,监督微调);可选的还有Pre-Training(pt,预训练)、Reward Modeling(奖励模型训练)、PPO(强化学习训练)、DPO(非强化学习训练);
- 训练数据集:选择train;
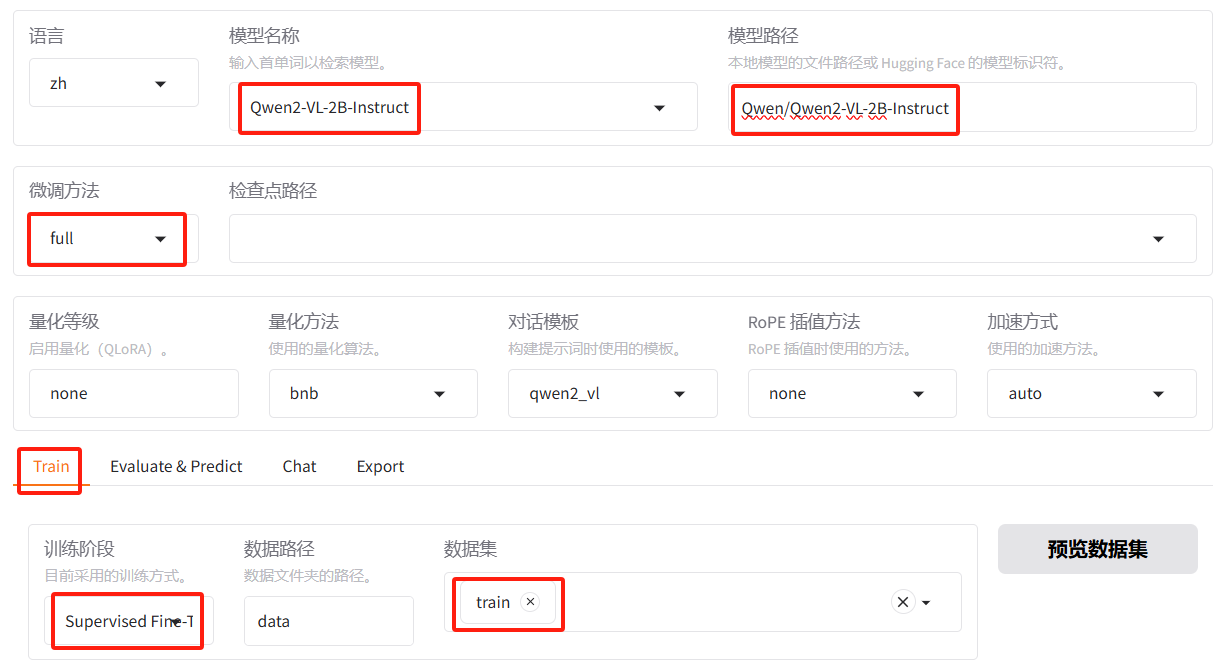
可以点击「预览数据集」,点击关闭返回训练界面。
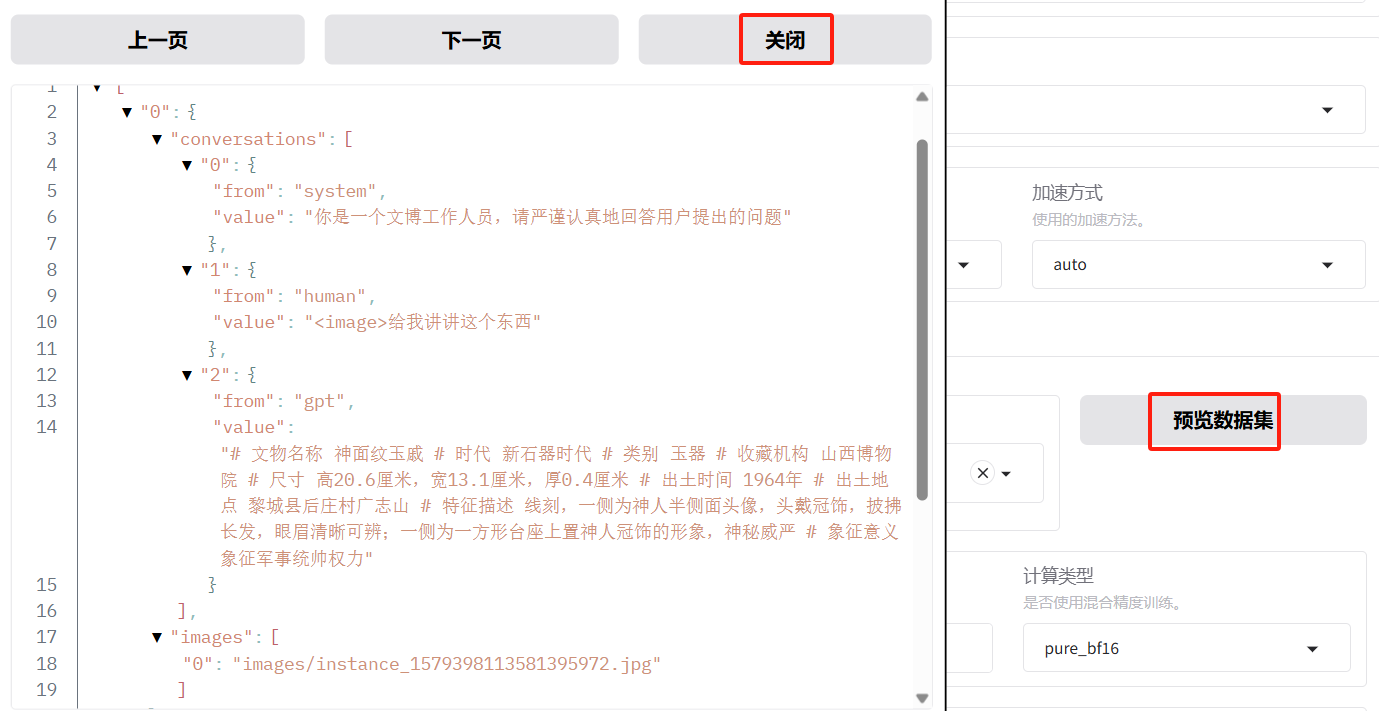
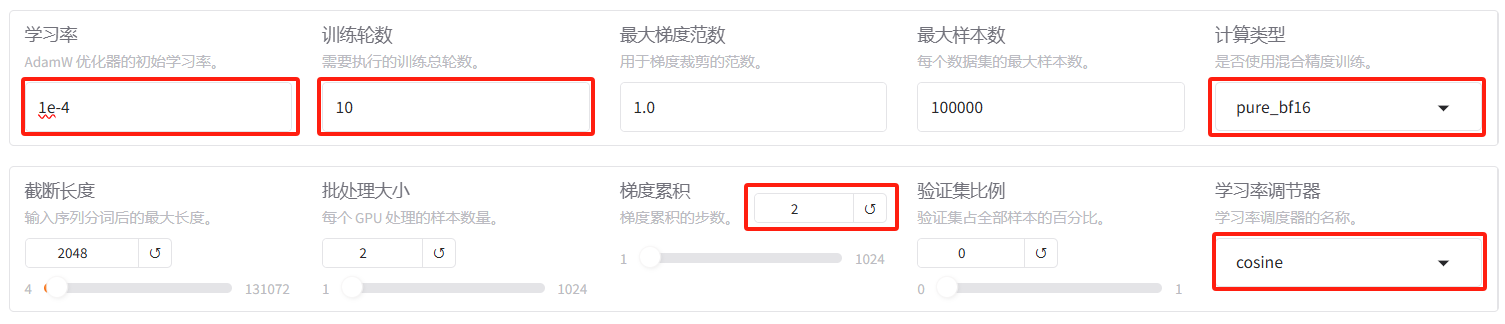
- 学习率:1e-4。过高易导致发散,过低则收敛缓慢,数据集越多越大。
- 训练轮数:10;
- 计算类型:pure_bf16。强制所有计算完全在 bf16 精度下进行,不依赖 FP32 辅助;
- 梯度累积:设为 2。有利于模型拟合;
- 学习率调节器:cosine,可选 linear, polynomial, constant 等。
在其他参数设置区域,根据情况进行设置,如:
- 保存间隔:1000。节省硬盘空间。
- 启用外部记录面板:none。虽然选择none,但还是会默认使用LlamaBoard自带的Loss曲线看板。可选的有tensorboard、wandb等,wandb需要设置相关的环境变量,所以一定要选择个,建议启动
使用SwanLab,可以在可视化界面设置API Key,参考SwanLab参数设置。
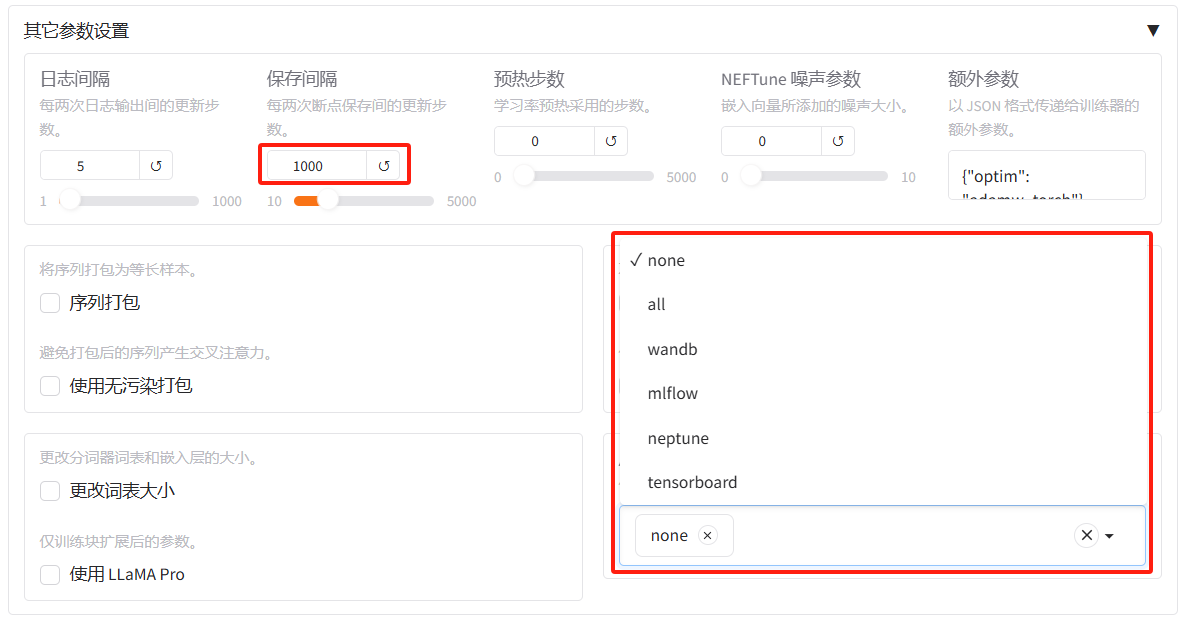
- SwanLab参数设置:暂时不启用。如若启用打钩,并填写项目名、SwanLab API密钥。

将输出目录修改为train_qwen2vl,训练后的模型权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,您如果想通过代码运行微调,可以复制这段命令,在命令行运行。
点击「开始」启动模型微调。
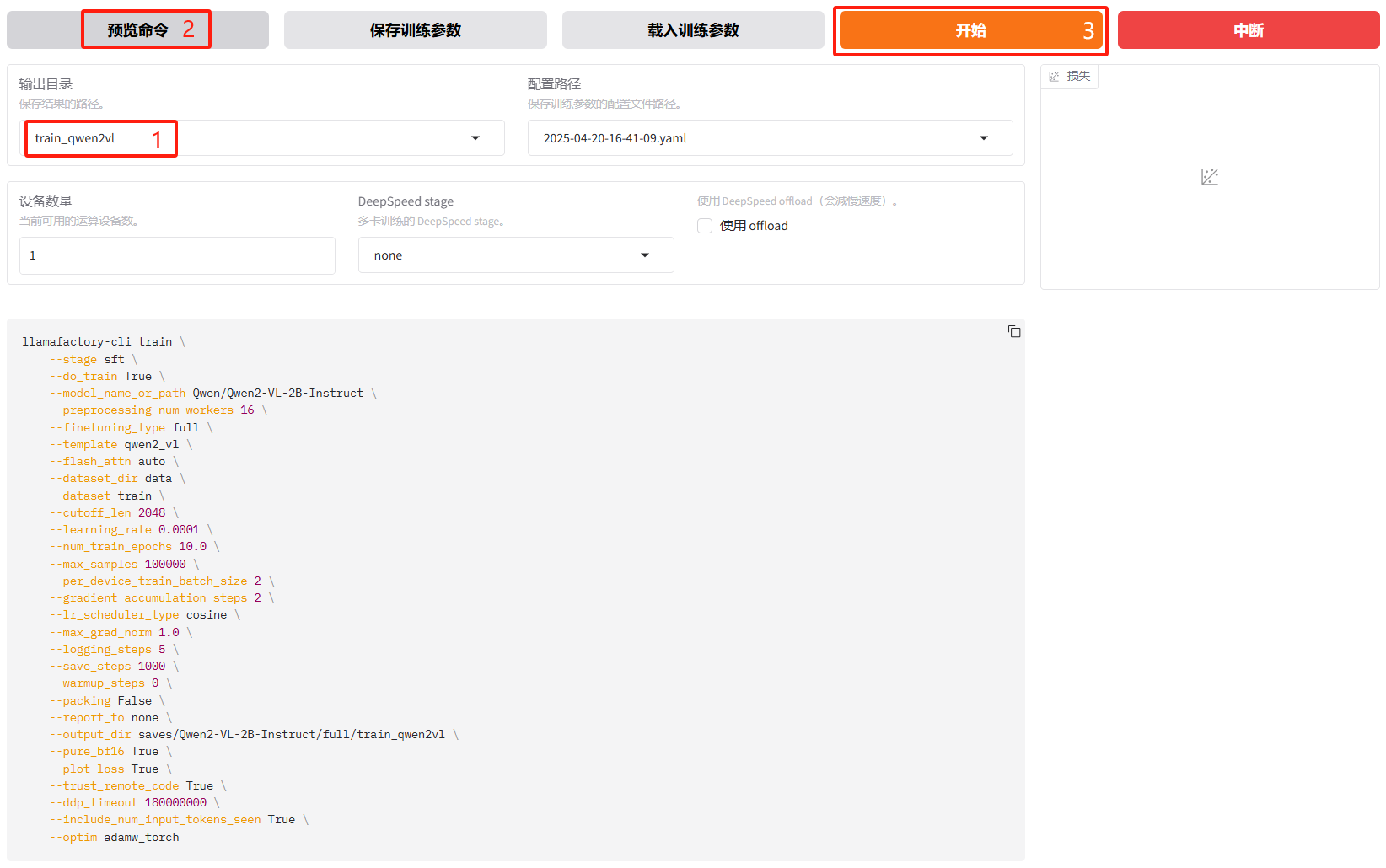
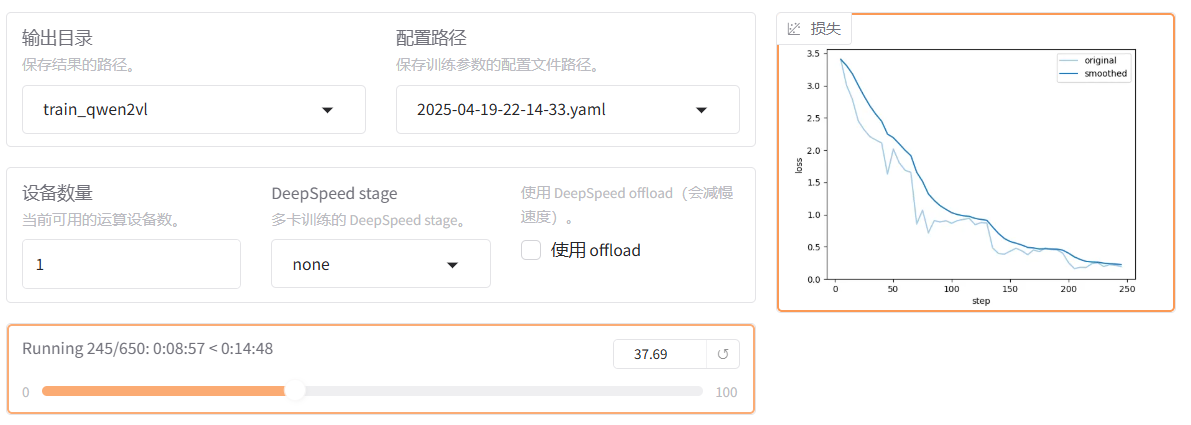
启动微调后需要等待一段时间,可在界面观察到日志、训练进度和损失曲线,输入nvidia-smi观察显存占用情况。
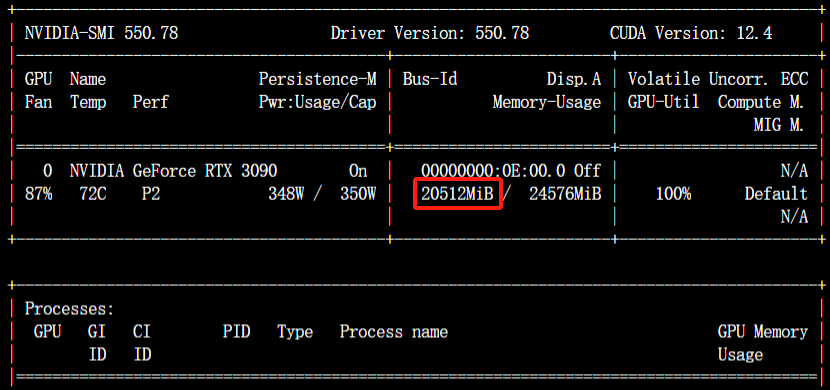
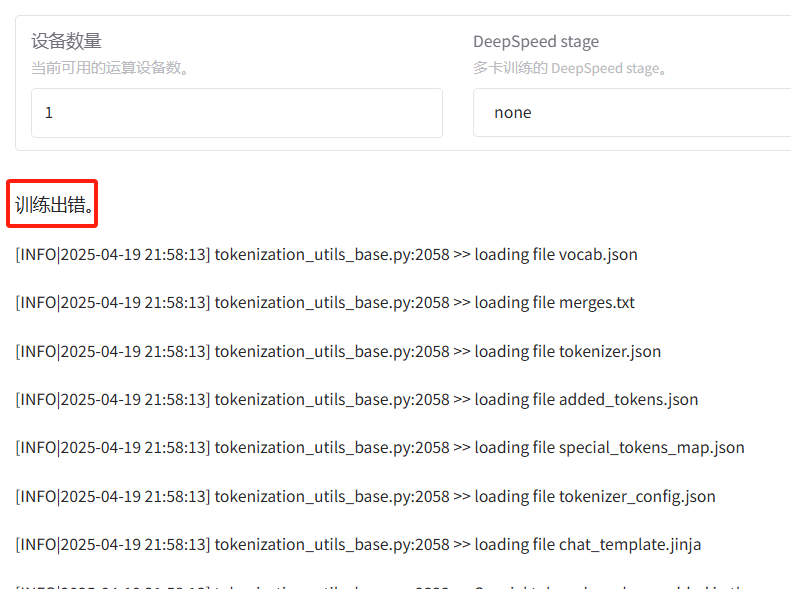
如果过程中出现错误,请结合页面日志以及终端日志进行排查。比如以下OOM(显存移除)错误,就需要增加显存或更失小点的模型。

观察之前已经使用对话(Chat)页面加载模型进行了一次推理,输入nvidia-smi查看显存占用情况。
$ nvidia-smi
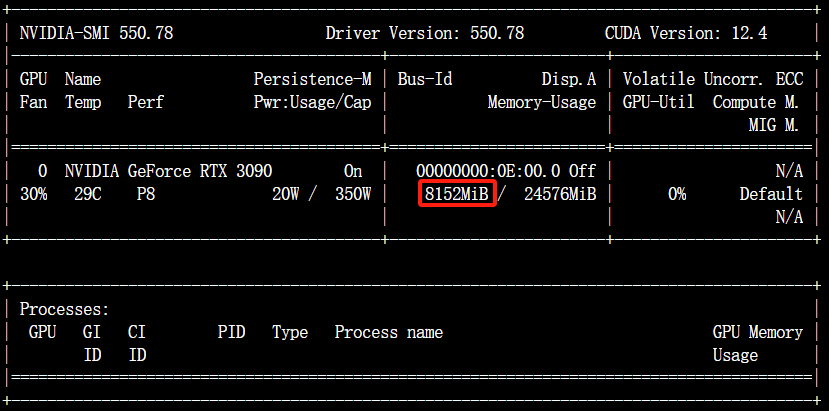
观察到此时有8G的显存占用,我们点击卸载模型,释放显存。
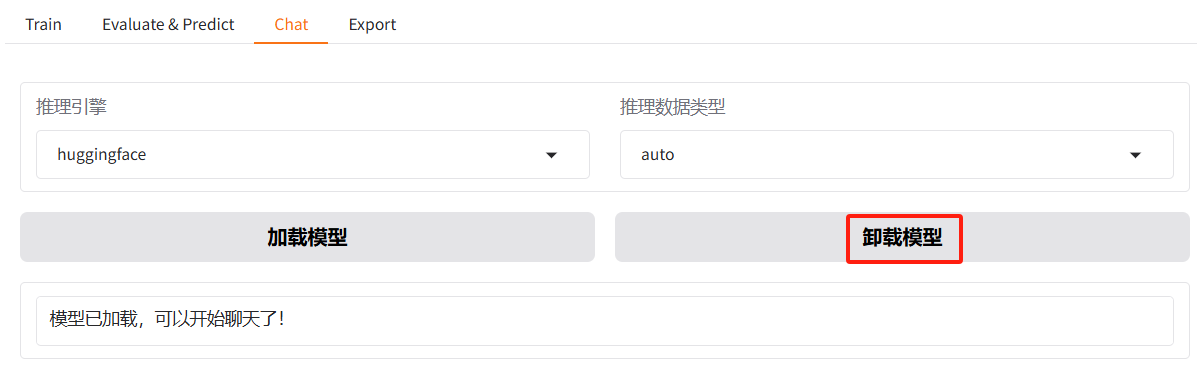
再次输入nvidia-smi,观察显存是否已降下来。
最后,一切顺利,模型微调大约需要 15 分钟,显示“训练完毕”代表微调成功。权重文件被保存在 LLaMA-Factory/saves/Qwen2-VL-2B-Instruct/full 目录下。
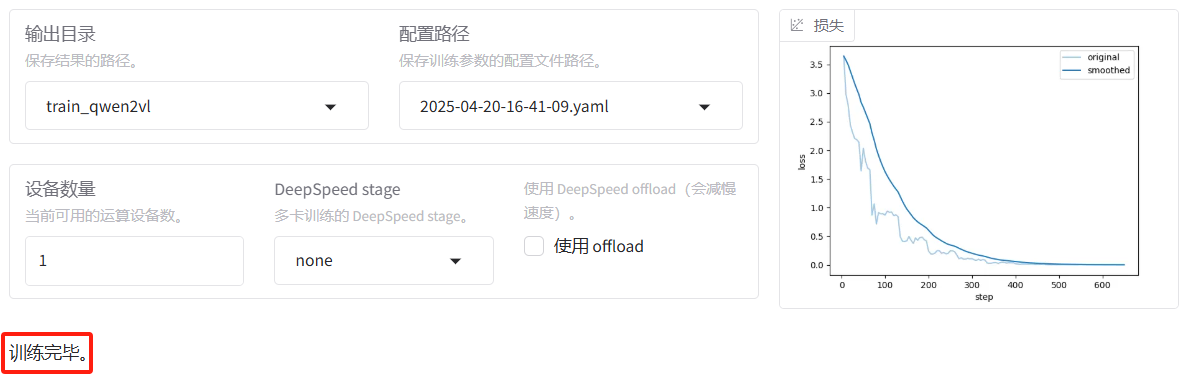
从结果大致可以看到,损失还是比较平稳的下滑,效果不错。
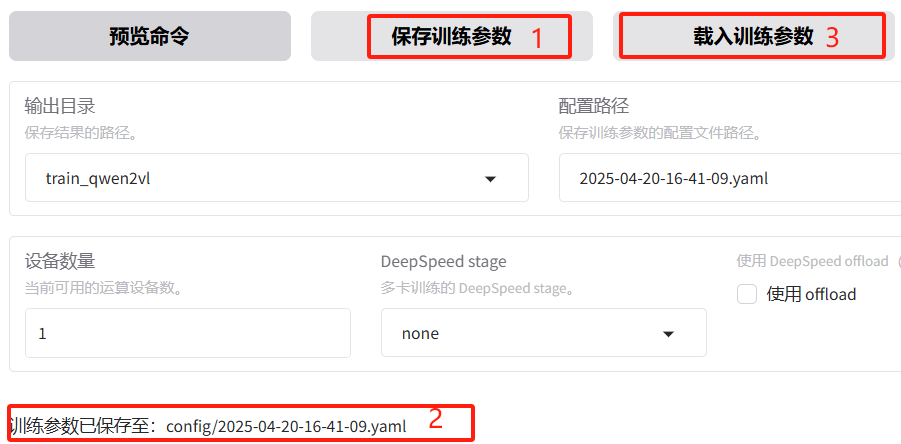
为了后续可以方便的进行再次训练,可以把这次的训练参数保存成.yaml文件,方便下次直接加载。
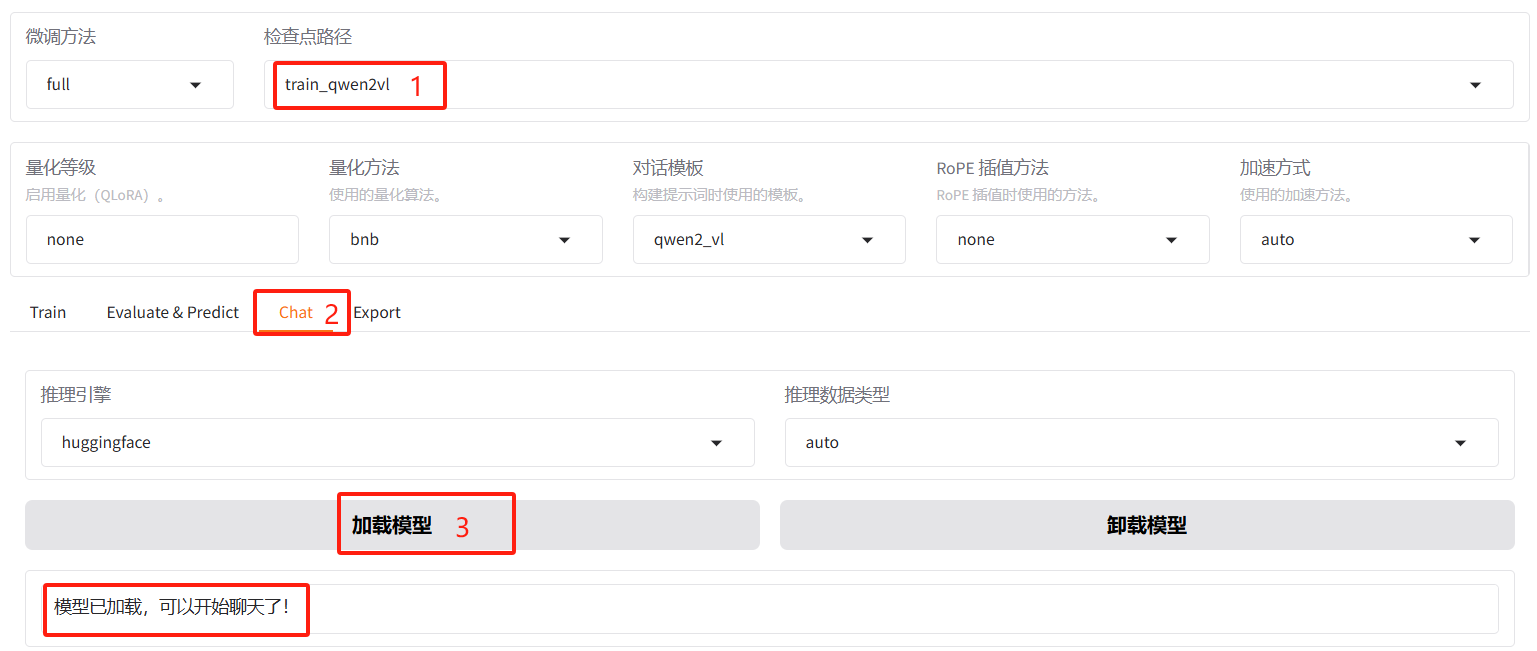
5.4、微调后的模型对话
选择「Chat」栏,将检查点路径改为 train_qwen2vl,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
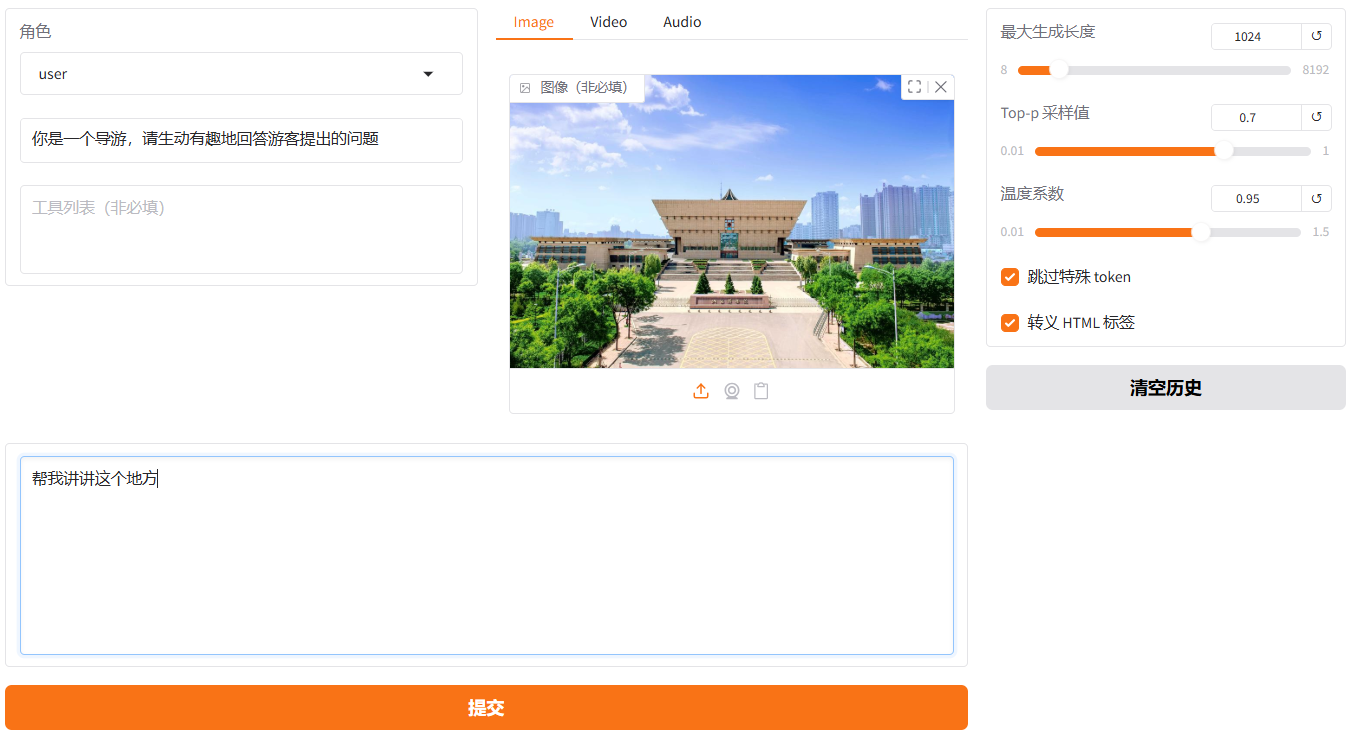
与原始模型推理步骤一样,选择相同的图片并上传,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。在页面底部的对话框输入“帮我讲讲这个地方”,点击提交即可发送消息。
发送后微调后的模型,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿导游的语气介绍图中的山西博物院。
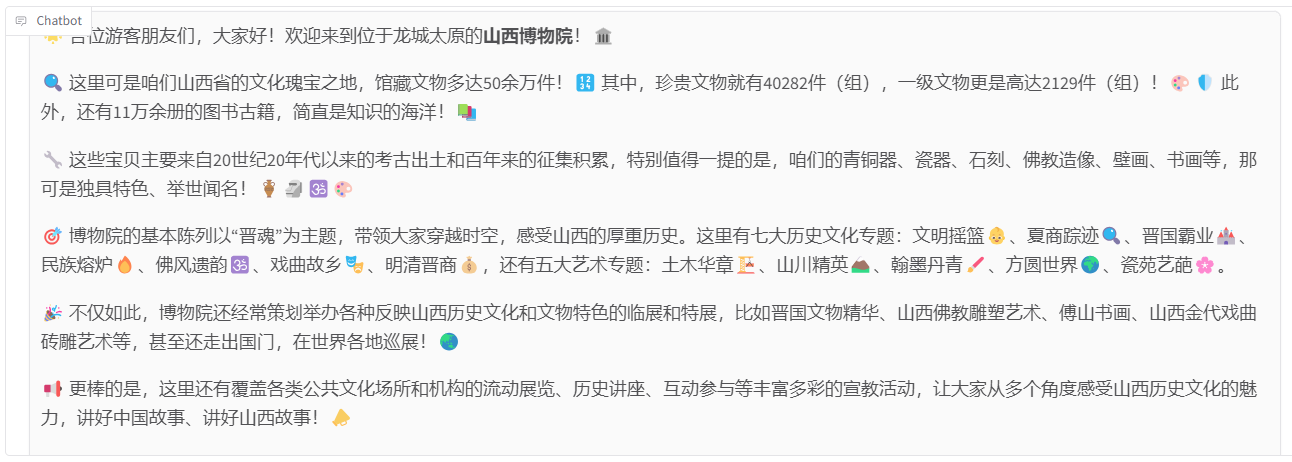
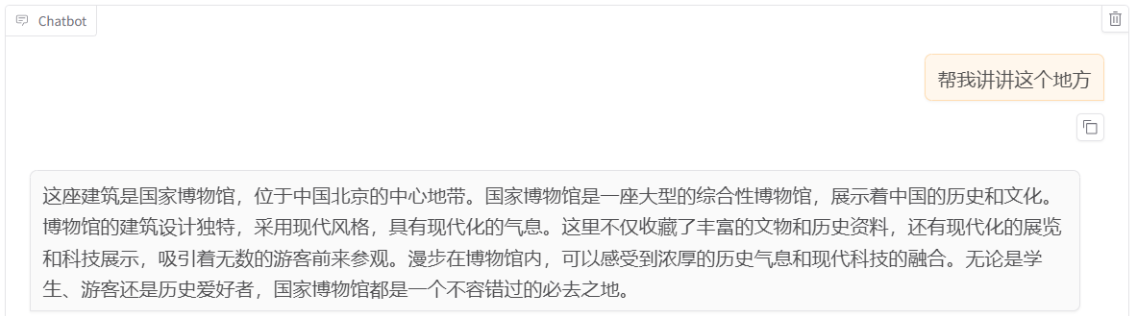
对微调前的回答对比,可以发现微调后的模型更加符合真实场景。
注:如果需要进行其它实验,由于显存的限制,建议用完卸载模型。

5.5、模型合并导出
虽然全参数微调后的新检查点/权重文件,不需要再进行合并,但为了整理成符合huggingface标准的模型仓库格式,可以进行一次导出。
使用LLaMA Board可安智网化界面可以方便的进行模型导出。
- 模型名称:Qwen2-VL-2B-Instruct;须与微调时的基座模型名称保持一致;
- 模型路径:Qwen/Qwen2-VL-2B-Instruct;须与微调时的模型路径保持一致;
- 检查点路径:train_qwen2vl;即全参数微调后的新检查点/权重文件路径;

点击导出(Export)标签页。
- 最大分块大小(GB):4,模型会被分成多个文件存储,每个文件大小不会超过指定大小;
- 导出量化等级:none,不进行量化;
- 导出设备:cpu,这个地方选择什么影响不大;
- 导出目录:../models/Qwen2-VL-2B-Tourism,../代表可以导出到LLaMA-Factory的上级目录,这里为了统一管理。
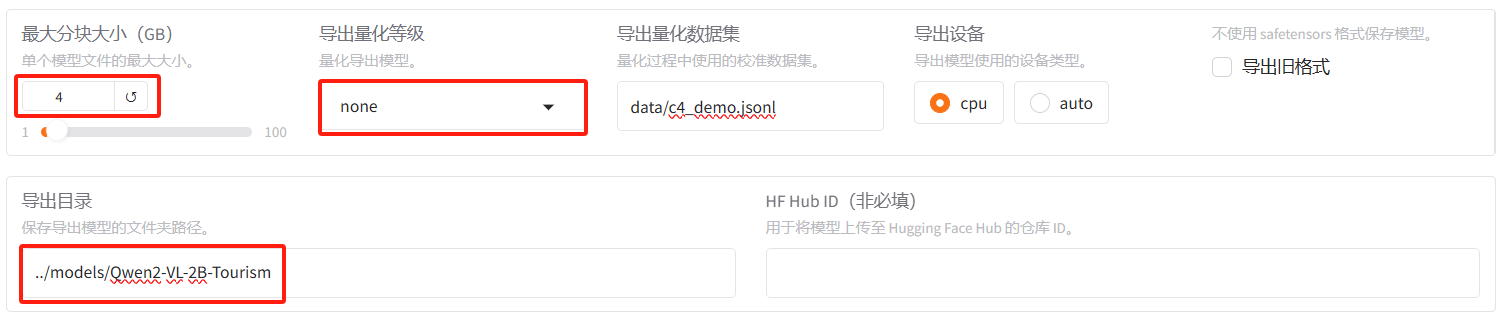
最后点击「导出」按钮,开始导出模型。

经过短暂的等待,页面状态提示导出完成。

通过FinalShell等远程工具,登录机器,可以看到在models目录下重新生成了Qwen2-VL-2B-Tourism文件夹。
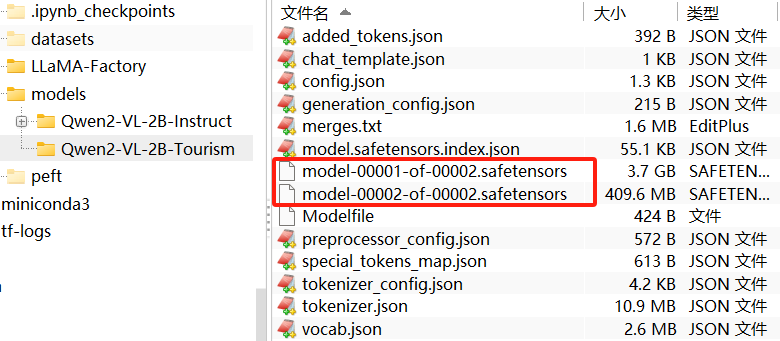
其中还生成了使用Ollama部署的Modelfile文件。



















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











