







【能力目标】
- 掌握运用vLLM进行QWQ模型的生产环境部署;
- 掌握Transformers推理的基本流程;
【任务描述】
本任务要求详细理解vLLM的各项参数配置后,通过命令或Docker方式进行QwQ-32B的部署,最后利用Open-webui演示聊天机器人应用。
【知识储备】
1. vLLM简介
vLLM 是一个快速且易于使用的库,专为大型语言模型 (LLM) 的推理和部署而设计。相比ollama、llama.cpp,vLLM更加适合企业级高并发应用场景,但对应的,显存占用也会更高,vLLM项目主页:https://github.com/vllm-project/vllm

vLLM的核心特性包括:
- 最先进的服务吞吐量
- 使用 PagedAttention 高效管理注意力键和值的内存
- 量化:GPTQ, AWQ, INT4, INT8, 和 FP8
vLLM 的灵活性和易用性体现在以下方面:
- 具有高吞吐量服务以及各种解码算法,包括并行采样、束搜索等
- 支持张量并行和流水线并行的分布式推理
- 提供与 OpenAI 兼容的 API 服务器
- 支持 NVIDIA GPU、AMD CPU 和 GPU、Intel CPU 和 GPU、PowerPC CPU、TPU 以及 AWS Neuron
- 前缀缓存支持
- 支持多LoRA
【任务实施】
1.利用Transformers进行QwQ-32B模型推理
利用Transformers进行QwQ-32B模型推理,默认从魔塔下载的权重文件是FP16的,所以需要显存占用在64G以上,以下为建议的机器配置,机器可以从featurize 或 AutoDL上面租赁。
| 精度位数 | 模型推理 | 模型高效微调 | 模型全量微调 | |||
|---|---|---|---|---|---|---|
| 显存占用 | 最低配置 | 显存占用 | 最低配置 | 显存占用 | 最低配置 | |
| FP16 | 64G | RTX3090*4(94G) | 92G | RTX3090*4(94G) | 350G | A100*6(480G) |
| Q_4_K_M | 20G | RTX3090(24G) | 30G | RTX3090*2(48G) | - | - |
1.1、环境搭建
$ conda create -n qwq32 python=3.10 ipykernel -y
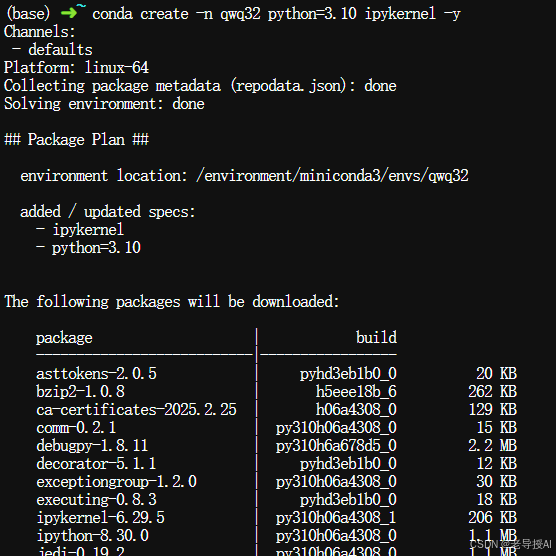
进入 conda 环境:
$ conda activate qwq32

将qwq32虚拟环境添加到Jupyter内核中
![]()
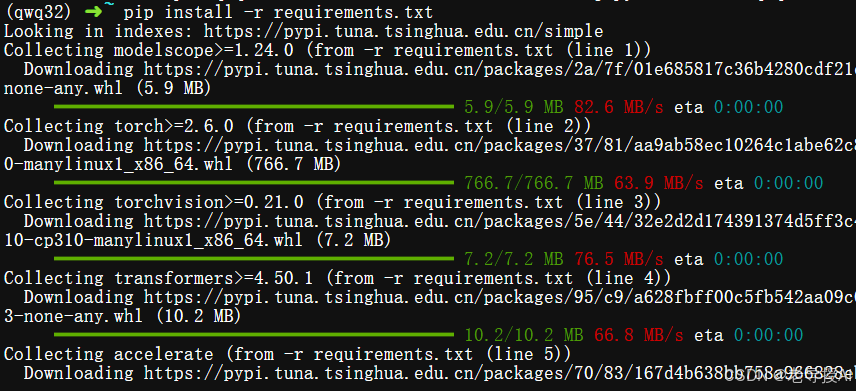
安装依赖包:
$ pip install -r requirements.txt
1.2、QWQ-32B模型下载
$ modelscope download --model Qwen/QwQ-32B --local_dir ./QwQ-32B
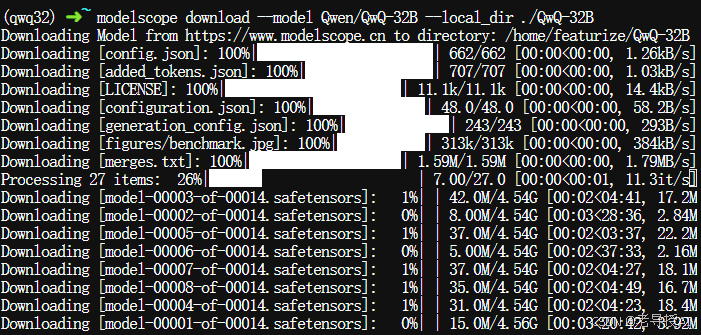
下载完成后,在QwQ-32B目录下,可以看到很多以.safetensors结尾的模型权重文件,默认是精度位为FP16。
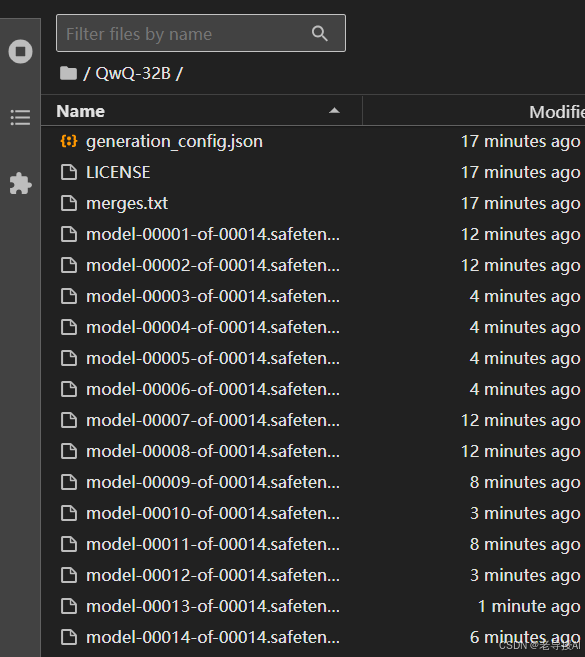
1.3、使用transformers原生库调用QWQ-32B
在Jupyter中右上角切换到qwq32内核,然后分别运行以下代码。
- 导入模型加载器和分词器
In [ ]:
from modelscope import AutoModelForCausalLM, AutoTokenizer
- 指定模型并加载
In [ ]:
model_name = "./QwQ-32B"
# 强制FP16:torch_dtype=torch.float16
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(next(model.parameters()).dtype)
- 准备提示词和输入文本
In [ ]:
prompt = "使用纯HTML生成贪食蛇游戏代码,要有随机的LOGO,界面美观,生成全部在一个HTML文件中"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
- 编码输入并移至模型设备
In [ ]:
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
- 生成、解码结果并打印
In [ ]:
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
-(可选)流式生成的结果
In [ ]:
from transformers import TextStreamer
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
streamer=streamer,
)
实时推理会等待一段时间,比如慢耐心等待,最终运行效果如下:
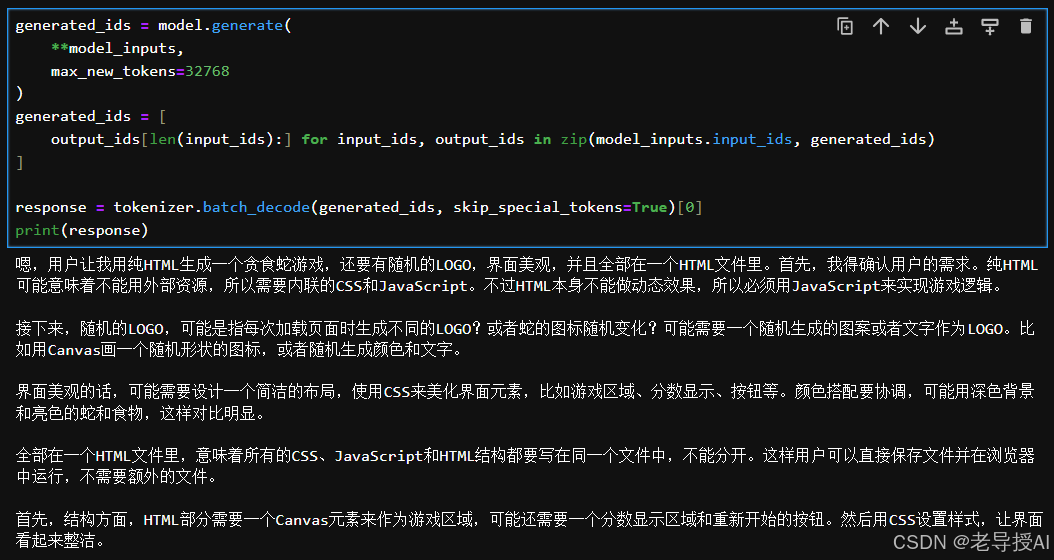

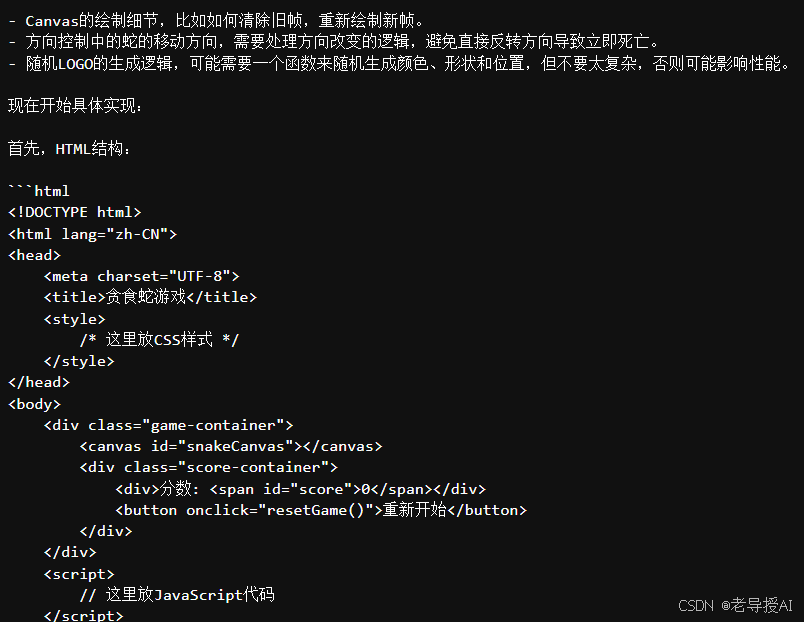
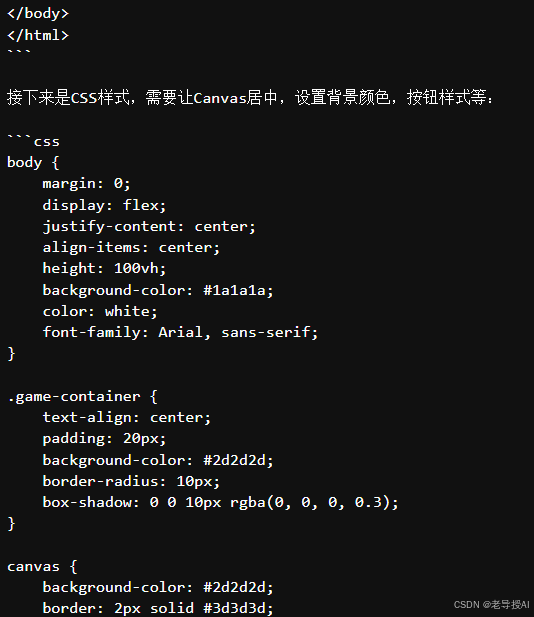
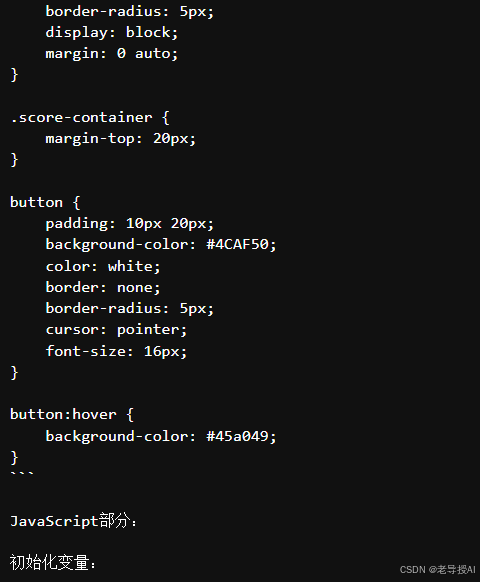
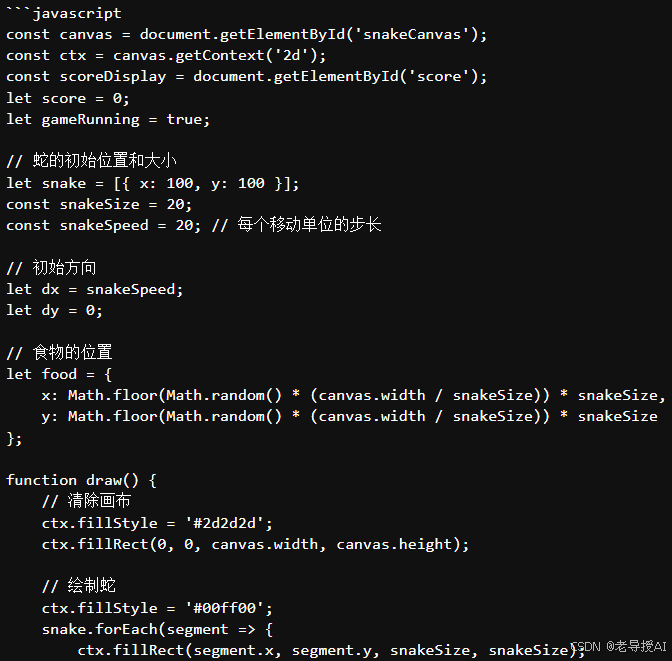
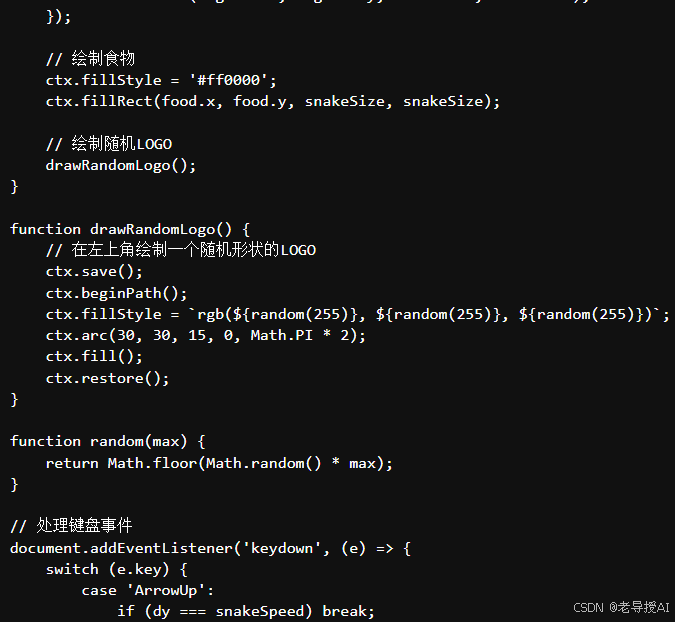
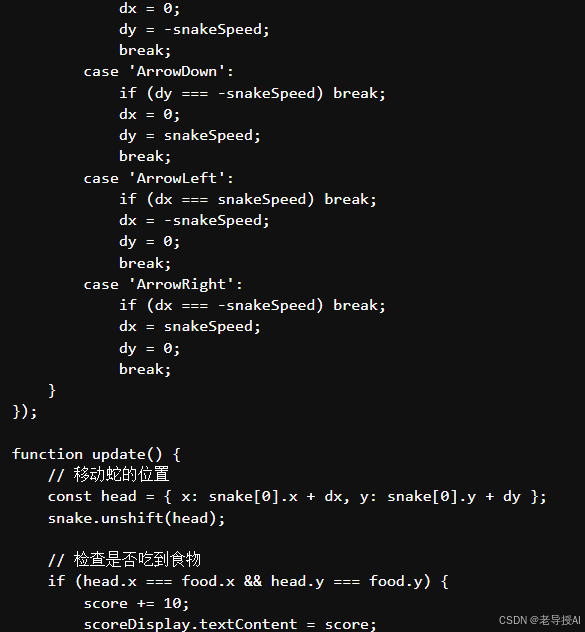
...此处省略了中间相关代码

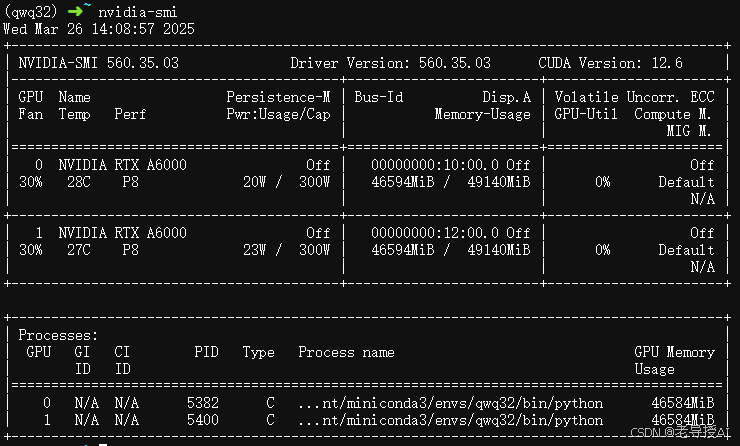
通过nvidia-smi命令查看GPU使用情况,发现大概使用64G显存左右。
nvidia-smi
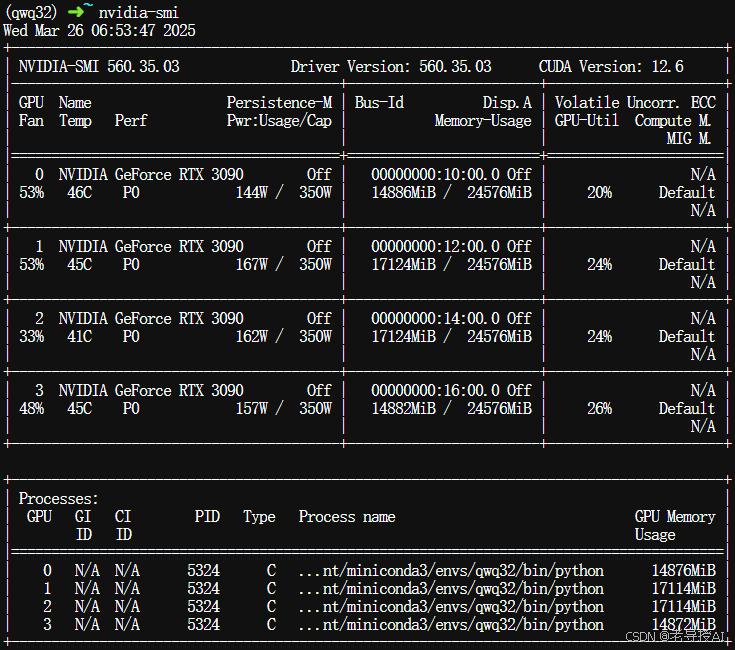
2.基于vLLM实现QwQ-32B模型推理
利用vLLM实现模型推理需要的显存大小主要由以下两部分组成:
- 模型参数占用:参数显存=32B * 2 Bytes(FP16) ≈ 64 GB,Q4_K_M的 ≈ 20 GB
- KV Cache:依赖上下文长度,2 * 32768(32K) * 64(层数) * 5120(维度) * 2 Bytes(FP16) ≈ 40 GB,由于QwQ-32B有8个KV头共享,显存减少了1/5,KV Cache显存占用大约在32G。
2.1、安装vLLM
建议使用全新的 conda 环境安装 vLLM,如果已经环境就略过。进入虚拟环境后,通过pip安装vLLM,默认安装的是带有 CUDA 12.1 的 vLLM:
$ pip install vllm
2.2、QwQ-32B模型推理
首先确认模型是vLLM已支持的模型列表,可以在模型支持列表中通过关键字查找:Supported Models — vLLM
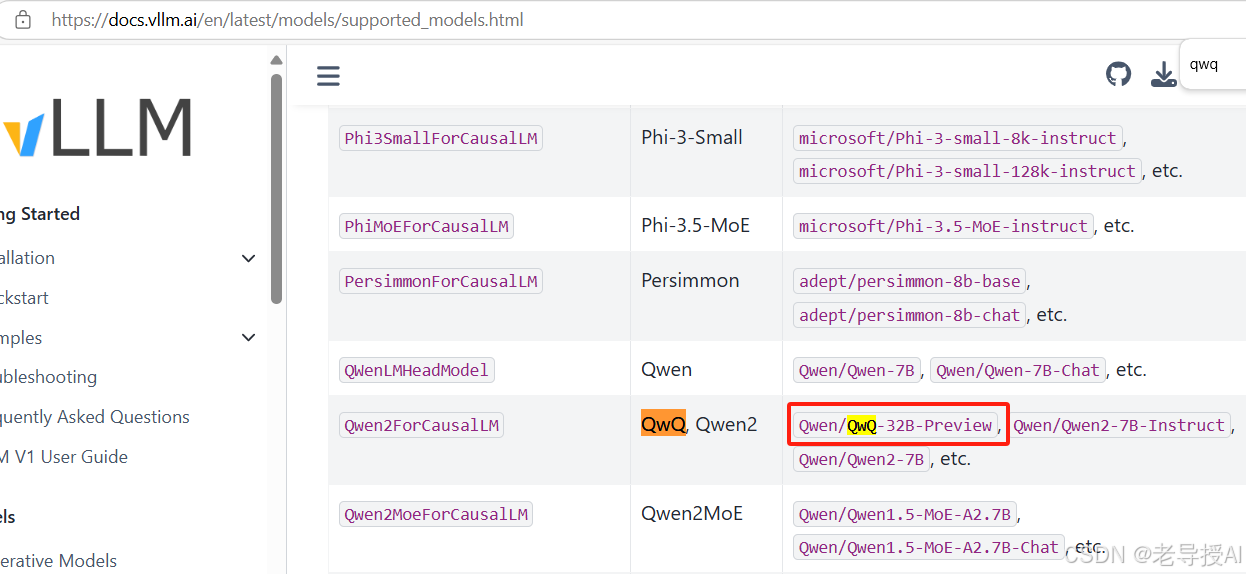
说明vLLM已支持QwQ-32B模型,接下来:
- vLLM 导入 LLM 和 SamplingParams:
In [ ]:
from vllm import LLM, SamplingParams
- 定义提示词和实例化采样参数
In [ ]:
prompts = [
"福建的省会城市是哪里",
"人工智能的英文是什么",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
- 使用QwQ-32B模型初始化 vLLM 引擎
In [ ]:
llm = LLM(
model="./QwQ-32B",
tensor_parallel_size=2,
max_model_len=32768,
enable_prefix_caching=True
)
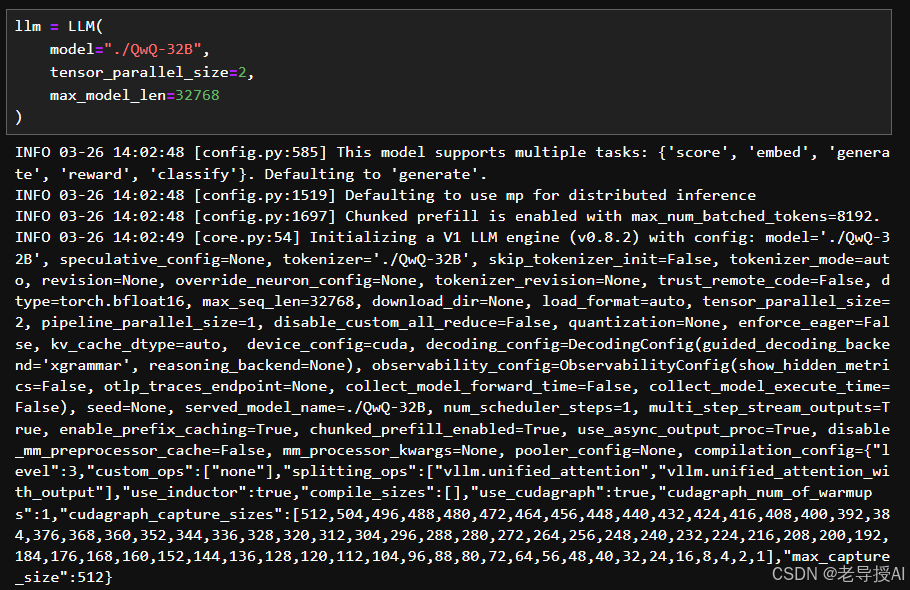
- 调用llm.generate生成输出
In [ ]:
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"提示词: {prompt!r}, 生成文本: {generated_text!r}")
最终输出结果如下:
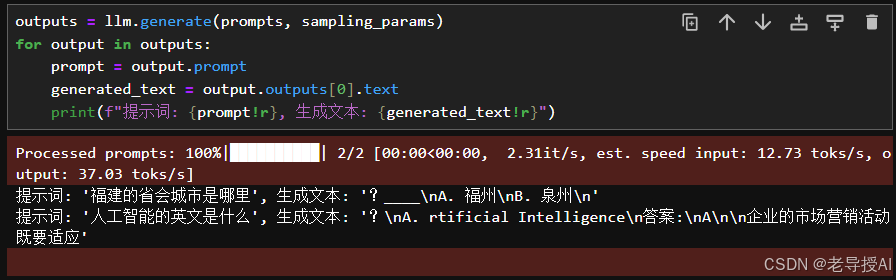
查看GPU使用率,2张RTX A6000(48G)共96G,占用93G。如果max_model_len设更大,显存占用将更多。
3.基于vLLM构建OpenAI API兼容的生产环境HTTP服务
3.1、QwQ-32B AWQ(4bit)量化版本的模型下载
$ modelscope download --model Qwen/QwQ-32B-AWQ --local_dir ./QwQ-32B-AWQ
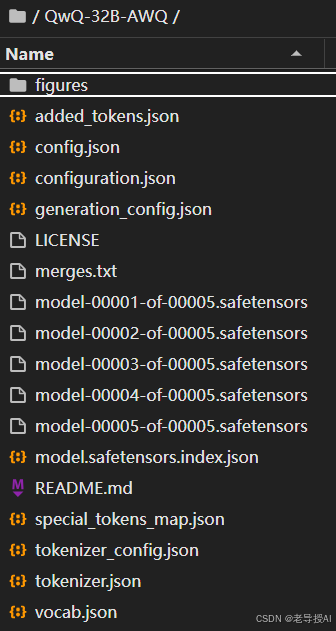
下载完成后,主要文件如下:
vLLM 提供了一个实现 OpenAI Completions 和 Chat API 的 HTTP 服务。可以使用 命令行 或 Docker 来启动:
3.2、方式一:使用vLLM命令行启动
vllm serve ./QwQ-32B-AWQ \ --host 0.0.0.0 \ --port 8000 \ --dtype auto \ --max-model-len 32768 \ --tensor-parallel-size 2 \ --api-key abcd123456
关健几个命令行参数解释如下:
- model:模型所在路径,如HuggingFace平台的
Qwen/QwQ-32B或本地相对路径如./QwQ-32B。HuggingFace平台的路径,vLLM会自动下载,但如果您想在 ModelScope下载,请将环境变量export VLLM_USE_MODELSCOPE=True写入到~/.bashrc中; - chat-template:要使用的聊天模板文件,默认会从model指定的路径中查找预定义聊天模板,如果没有聊天模板,服务器将无法处理聊天请求,所有聊天请求将出错。vLLM 社区也提供了主流模型的聊天模板,可以在示例目录这里找到它们。
- tensor-parallel-size:多GPU时,指定的GPU数量;
- pipeline-parallel-size:多节点多GPU时,指定的节点数量;
- max-model-len:控制模型推理时的最大Token长度(包括输入+输出)。如果未指定,将自动从模型配置中推导出来,设定值需≤模型最大上下文长度,主要影响显存占用;
- quantization:用于量化权重的方法,可选项:aqlm、awq、gptq、deepspeedfp、tpu_int8、fp8、gguf、bitsandbytes等;如果模型已预量化,不指定会自动检测,否则会自动动态量化(较慢,不推荐生产环境);
- enable-prefix-caching:是否开启前缀缓存,默认为False;
- gpu-memory-utilization:用于模型执行器的 GPU 内存比例,其范围从 0 到 1;
- disable-custom-all-reduce:vLLM的custom_allreduce仅适用于单GPU、双GPU或者≥3块启用NVLink/NVSwitch的GPU,但是如果是>2块的PCIe的GPU,则需要关闭custom_allreduce,设为True否则会出现报错。
- host:服务监听的IP地址,即所有IP地址设为0.0.0.0;
--uvicorn-log-level:日志级别,默认info,可选项:debug, info, warning, error, critical, trace
运行后,经过1分钟左右,服务返回以下信息,代表成功启动服务:
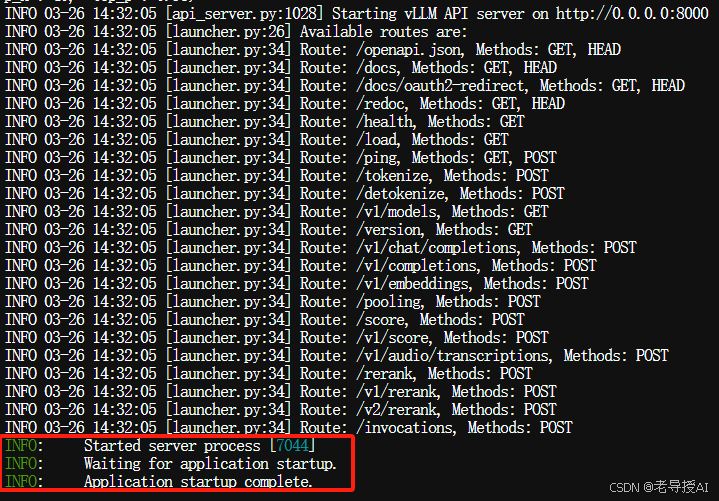
反之也有经常会报OOM(out of memory)错误,就是显存不够用,可以尝试日志中的调整gpu-memory-utilization,但根据之前的显存占用预算公式云计算,如果局限性在GPU,则调整参数作用不大,大家可以自行验证。
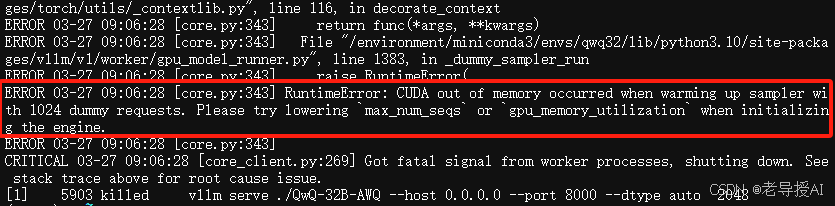
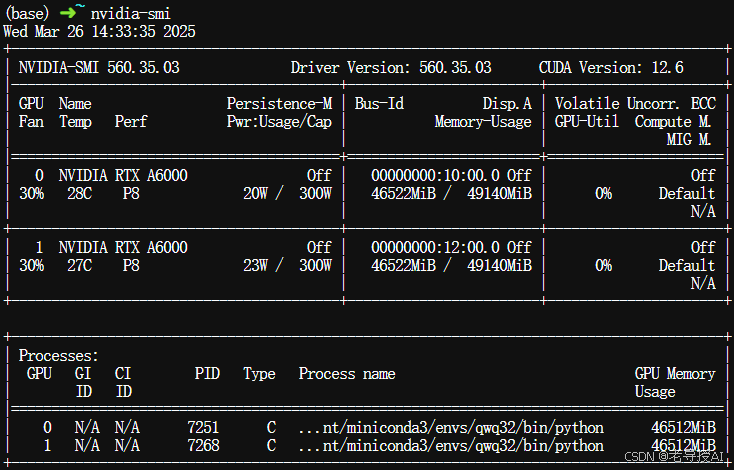
此时查看显存占用情况:
使用OpenAI标准SDK库编写相关代码调用以上服务
- 安装OpenAI库
$ pip install openai "httpx[socks]"
- 导入OpenAI库,创建一个OpenAI对象,并设置API密钥
In [ ]:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="abcd123456",
)
In [ ]:
completion = client.chat.completions.create(
model="./QwQ-32B-AWQ",
messages=[
{"role": "user", "content": "编写一个Python程序,输出Hello World!"}
]
)
print(completion.choices[0].message)
最终运行效果如下:

查看运行日志,可以看出平均18.2 tokens/s。

3.2、方式二:使用vLLM Docker启动
vLLM 提供了一个官方 Docker 镜像用于启动模型服务。该镜像提供的HTTP服务也是兼容OpenAI风格的API,镜像名为vllm/vllm-openai,大小在8G左右。

vllm/vllm-openai镜像依赖nvidia-container-toolkit,因此需事先安装,本教程提供了一健安装nvidia-container-toolkit的脚本。
运行以下命令:
$ bash scripts/install-nvidia-container-toolkit
接着拉取vllm/vllm-openai镜像:
$ docker pull vllm/vllm-openai
没有开代理,也可以从网盘上获取然后上传到服务器:
然后通过 docker load 加载到服务器本地:
docker load -i mirror-image/vllm-openai.tar
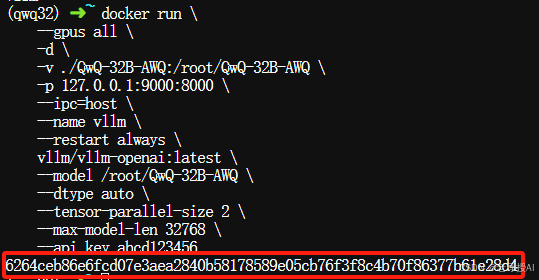
接着通过以下命令启动基于QwQ-32B-AWQ部署的容器:
$ docker run \
--gpus all \
-d \
-v ./QwQ-32B-AWQ:/root/QwQ-32B-AWQ \
-p 127.0.0.1:9000:8000 \
--ipc=host \
--name vllm \
--restart always \
vllm/vllm-openai:latest \
--model /root/QwQ-32B-AWQ \
--dtype auto \
--tensor-parallel-size 2 \
--max-model-len 32768 \
--api_key abcd123456
其中镜像的后面的跟着参数与使用vllm serve的一致。
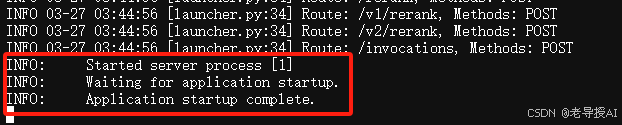
通过实时打印容器日志,查看是否成功启动服务,如果显示如下图所示,代表成功:
$ docker logs -f vllm
通过curl传递API-KEY调用查询模型信息API验证:
$ curl http://localhost:9000/v1/models \
-H "Authorization: Bearer abcd123456"

3.3、方式三:编写Docker Compose一键部署聊天机器人应用
聊天机器人应用的WEB UI我们使用open-webui进行二次开发的、可扩展、功能丰富、用户友好的自托管web,旨在完全离线运行。它支持各种LLM运行程序,包括与openai兼容的api。web使用Svelte做为前端框架、TypeScript为脚本、使用Python为后端语言。
教程已提供打包了shengge2004/ics-web离线的镜像包,存放在mirror-image目录下,文件名为ics-web.tar,使用以下命令加载进来:
$ docker load -i ./mirror-image/ics-web.tar

接着,要使用到的yaml文件已整理好,列表如下:

部分内容如下:
services:
vllm-openai:
volumes:
- ./Qwen2.5-7B-Instruct-AWQ:/root/Qwen2.5-7B-Instruct-AWQ
container_name: vllm
ipc: host
ports:
# 限制只能本地访问,去除127.0.0.1都可访问
- 127.0.0.1:8000:8000
command: |
--model=/root/Qwen2.5-7B-Instruct-AWQ
--dtype=auto
--max-model-len=32768
--api_key abcd123456
--host 0.0.0.0
restart: unless-stopped
image: vllm/vllm-openai:${VLLM_DOCKER_TAG-latest}
ics-web:
image: shengge2004/ics-web:latest
container_name: ics-web
volumes:
- ics-web:/app/backend/data
depends_on:
- vllm-openai
ports:
- ${ICS_WEB_PORT-8080}:8080
environment:
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ics-web: {}
运行如下命令启动:
$ docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml up -d

同样要监控下vllm容器的日志,大概等1分钟后,会启动服务:
$ docker logs -f vllm
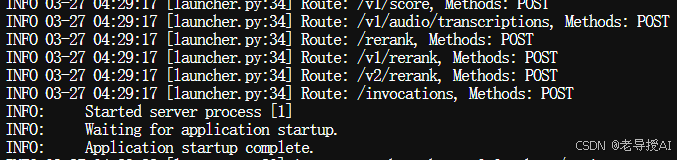
通过访问http://localhost:8080,即可打开一个聊天机器人WEBUI网页,如下图所示:
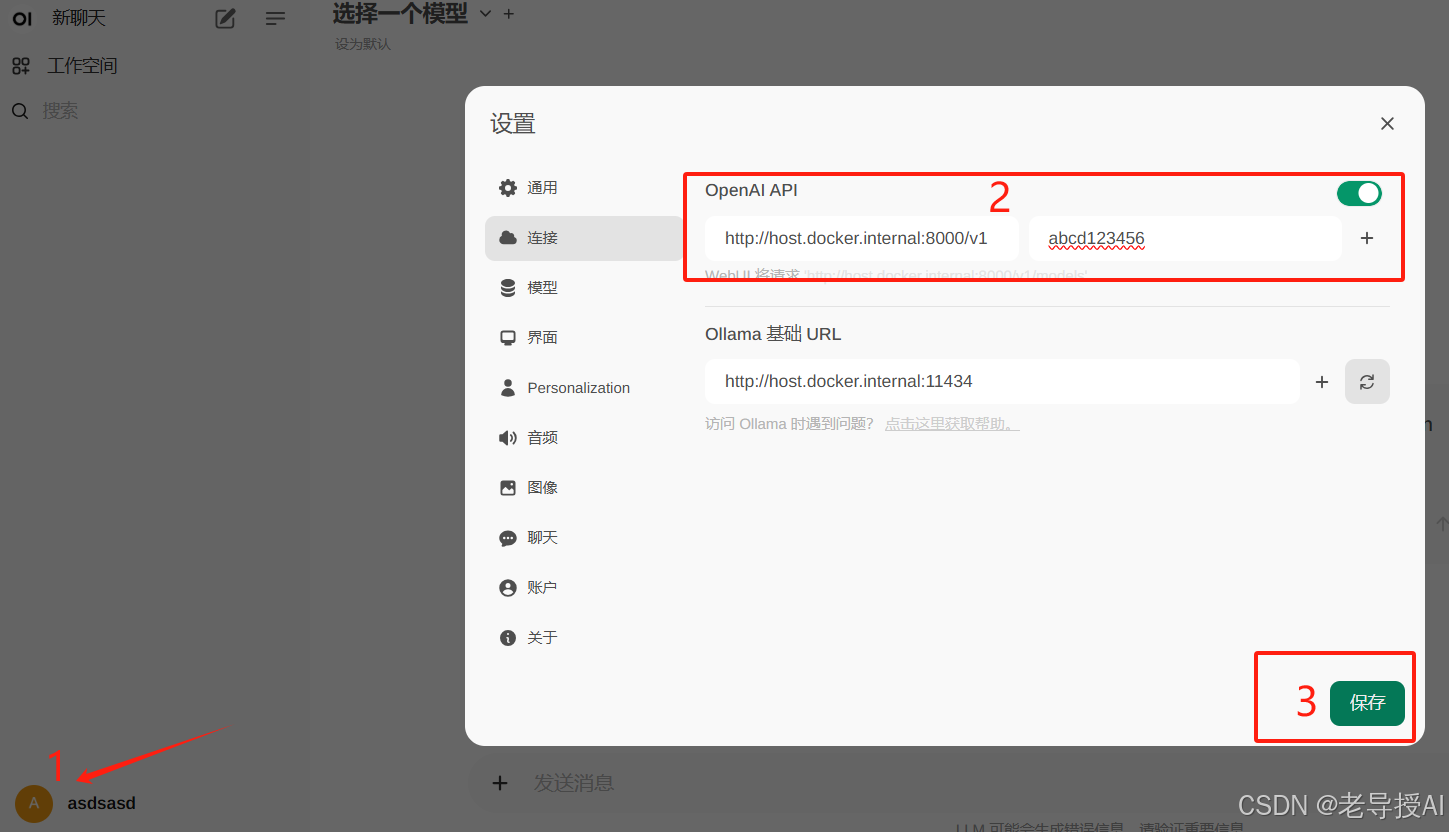
注册一个帐号即可登录进入,在设置中选择中文语言以及设置调用的API服务,地址填写http://host.docker.internal:8000/v1 或 http://vllm-openai:8000/v1,API密钥设置为启动时的值。
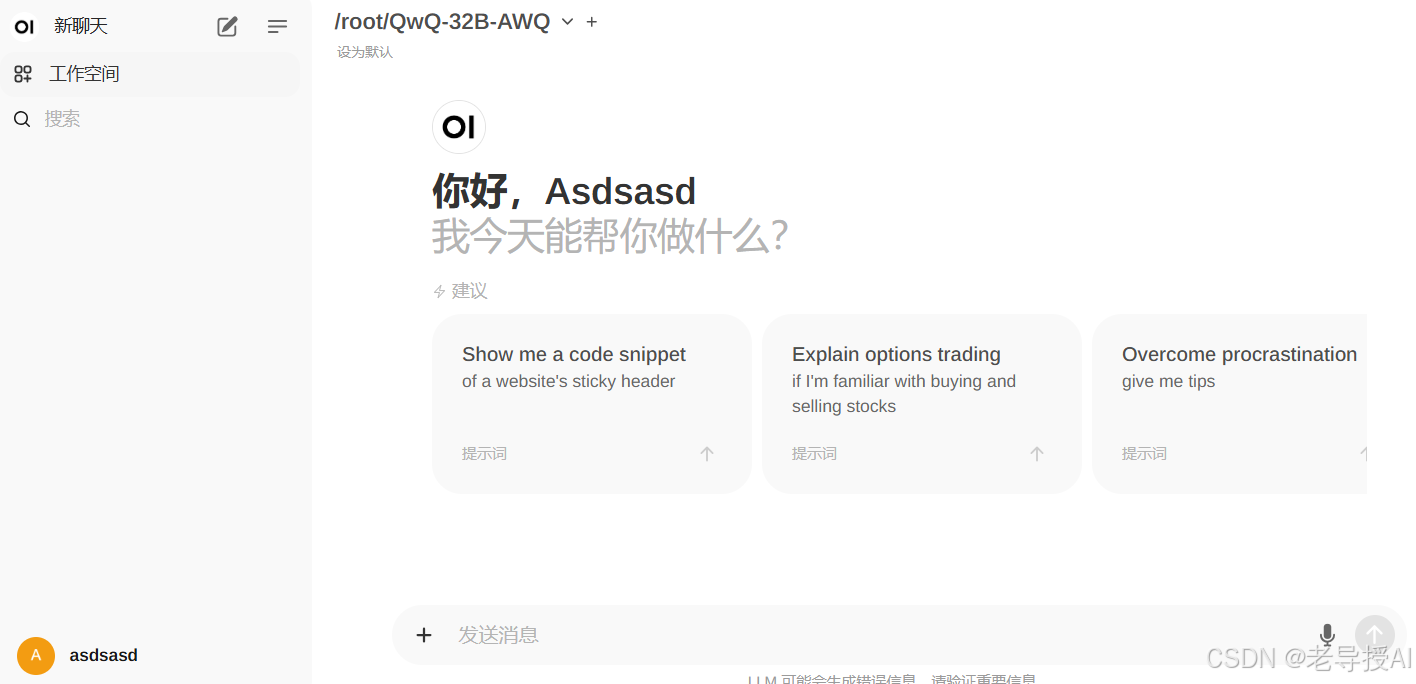
之后就可以类似使用ChatGPT等AI助手进行聊天了。
最后,如果要卸载以上使用Docker Compose创建的容器、数据卷及网络,运行以下命令:
$ docker compose down -v --remove-orphans



















 586
586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











