






CUDA 执行模型
Nvidia的并行编程模型被命名为CUDA(Computing Unified Device Architecture,统一计算架构模型)。CUDA的基本思想是尽量得开发线程级并行(Thread Level Parallel),这些线程能够在硬件中被动态的调度和执行。CUDA编程模型的重点是将CPU做为终端(Host),而GPU做为服务器(Server)或协处理器(Coprocessor),或者设备(Device),从而让GPU来运行一些能够被高度线程化的程序。所以,GPU只有在计算高度数据并行任务时才能发挥作用。在这类任务中,需要处理大量的数据,数据的储存形式类似于规则的网格,而对这写数据的进行的处理则基本相同。这类数据并行问题的经典例子有:图像处理,物理模型模拟(如计算流体力学),工程和金融模拟与分析,搜索,排序。而需要复杂数据结构的计算如树,相关矩阵,链表,空间细分结构等,则不适用于使用GPU进行计算。找到程序中的计算并行度后,就能将一部分程序移植到GPU上。运行在GPU上的程序被称为Kernel(核)。核并不是完整的程序,而是整个程序中的若干基本的关键数据并行计算步骤。
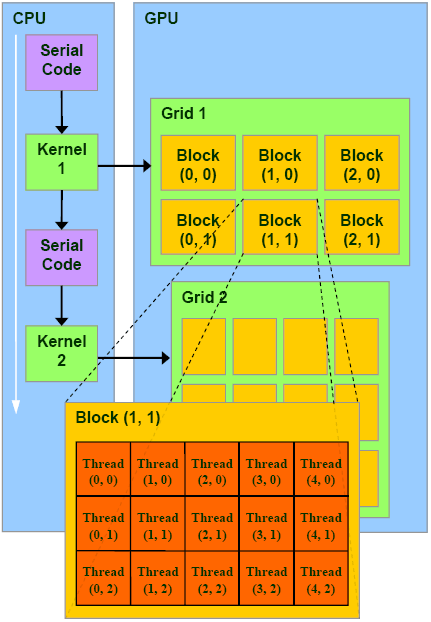
图1 CPU与GPU 串行程序,核,网格和线程块
除了数据并行的核以外,程序中也有标准的串行程序。如表一所示,在两个核之间运行的就是串行代码(如果两个核函数之间没有串行代码,它们就可以被合并为一个)。理论上,串行代码的作用只是清理上个核,启动下一个核。但由于目前的GPU的功能仍然十分有限,串行部分的工作仍然十分可观。
核以网格(Grid)的形式执行,每个网格由若干个线程块(block)组成,每一个线程块又由最多512个线程(thread)组成。属于同一线程块的线程拥有相同的指令地址,能够并行执行,并且能够通过共享存储器(Shared memory)和同步栅(barrier)进行线程块内通信。同一线block中的thread开始于相同的指令地址,理论上能够以不同的分支执行。但实际上,在block内的分支因为性能方面的原因被大大限制了。
核实质上是以block的形式执行的。CUDA引入了grid这个概念来表示一系列能够(并不一定)完全并行执行的线程块的集合。线程块的执行没有顺序,完全并行。这是CUDA的一个很杰出的特性:无论是在一次只能处理一个线程块的GPU上,还是在一次能处理数十乃至上百个线程块的GPU上,这一模型都能很好的适用。
目前,一个核函数只对应一个网格,但是未来这一限制极有可能会被解除。实际使用中在一个网格访问数据的同时,如果能够进行另一个网格的计算,则可以有效的提高设备的利用率。但现在网格以串行代码划分了边界,不能很好的隐藏访存延迟(Memory Access Latency)。
因为同一线程块中的线程需要共享数据,因此它们必须在同一个处理器(Nvidia称之为Streaming Mulitporcessor,流多处理器,缩写SM)中发射。线程块中的每一个线程被发射到一个执行单元(Nvidia称之为Streaming Processor,流处理器,缩写SP)。这里涉及到了Nvidia GPU的内部架构,我们将在下一节进行详细说明。
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/22785983/viewspace-619773/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/22785983/viewspace-619773/















 6558
6558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









