







smooth L1的定义如下:

一般smooth L1用于回归任务。
对x求导:
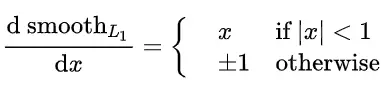
smooth L1 在 x 较小时,对 x 的梯度也会变小,而在 x 很大时,对 x 的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。 smooth L1 完美地避开了 L1 和 L2 损失的缺陷。
最近研究一些图像生成任务(比如视频编解码)时,常用的损失也是MSE和L1。用L1损失时,因为L1对x的导数是常数,导致在训练到生成图片与ground truth很接近时,模型很难继续收敛(学习率已经调到极小);用MSE作损失时,在训练初期,由于MSE对离群点比较敏感,刚开始训练时有可能对网络的反向指导出现错误,甚至把网络训练飞。于是对传统的smooth L1做了以下改变:
引入th参数,当生成图像与ground truth比较相近时,采用作为损失,以进一步收敛,否则,采用
。
pytorch代码如下:
def smooth_l1_loss_my(input, target, th = 1./128):
# type: (Tensor, Tensor) -> Tensor
t = torch.abs(input - target)
return torch.where(t < th, 0.5 * t ** 2, t - 0.5)
我本人实验的结果是用了改进的smooth L1损失后,重构图片的指标相对于L1(一开始我一直在用L1损失)有明显提升。














 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









