







 本文介绍了使用StableDiffusion生成逼真人脸的三个关键技巧:基础提示工程、升级至SDXL模型的参数调整和CivitAIRealVisXLV2.0的自定义模型微调。通过实例展示如何优化图像质量和细节。
本文介绍了使用StableDiffusion生成逼真人脸的三个关键技巧:基础提示工程、升级至SDXL模型的参数调整和CivitAIRealVisXLV2.0的自定义模型微调。通过实例展示如何优化图像质量和细节。
大家好,你是否曾想过,为什么别人可以使用AI图像生成技术生成如此逼真的人脸,而自己的尝试却充满了错误和瑕疵,让人一眼看出是假的。尝试过调整提示和设置,但似乎仍无法与他人的质量相匹配。
本文将带大家了解使用Stable Diffusion生成超逼真人脸的3个关键技巧。首先将介绍提示工程的基础知识,帮助使用基础模型生成图像。接下来,将探讨升级到Stable Diffusion XL模型后,如何通过更多的参数和训练来显著提高图像质量。最后,为大家介绍一种专门用于生成高质量人物肖像而微调的自定义模型。
1. 提示工程
首先,我们将学习如何编写正面和负面的提示来生成逼真的人脸。我们将使用Hugging Face Spaces上提供的Stable Diffusion版本2.1演示。它是免费的,并且可以在不做任何设置的情况下开始使用。
【链接】:hf.co/spaces/stabilityai/stable-diffusion
在创建正面提示时,确保包含图像的所有必要细节和风格。在本例中,我们希望生成一张年轻女子在街上行走的图像。我们将使用一个通用的负面提示,但是可以添加其他关键词以避免图像中的重复错误。
正面提示:“A young woman in her mid-20s, Walking on the streets, Looking directly at the camera, Confident and friendly expression, Casually dressed in modern, stylish attire, Urban street scene background, Bright, sunny day lighting, Vibrant colors”。
负面提示:“disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w, cartoon, painting, illustration, worst quality, low quality”。
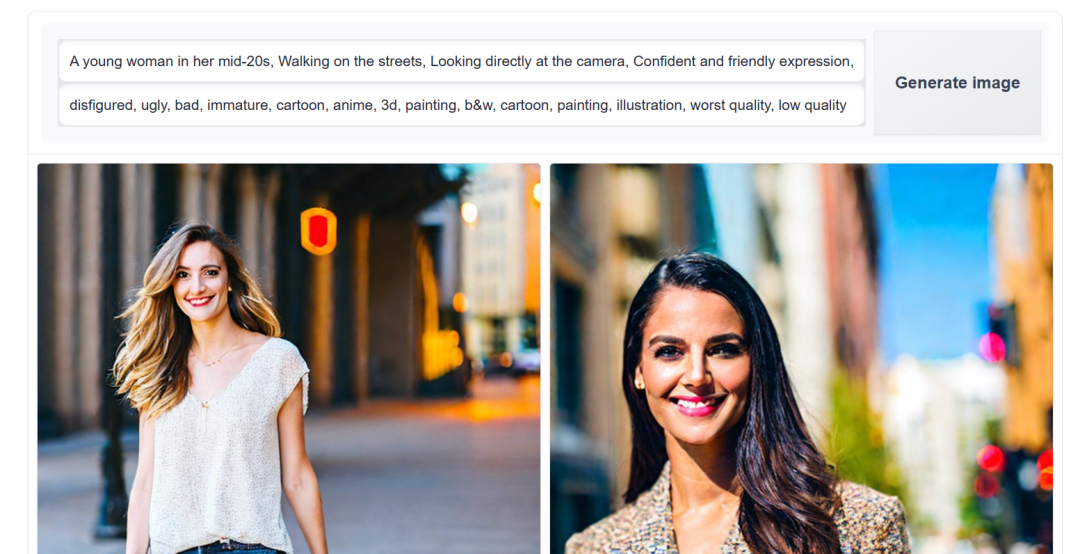

我们有了一个良好的开端。图像是准确的,但图像质量可以更好。可以尝试调整提示,但这已经是基础模型能够提供的最好效果了。
2. Stable Diffusion XL
我们将使用Stable Diffusion XL(SDXL)模型生成高质量图像。它通过使用基础模型生成潜在图像,然后使用一个细化器对其进行处理,从而生成详细而精确的图像。
【链接】:hf.co/spaces/hysts/SD-XL
在生成图像之前,我们将向下滚动并打开“Advanced options(高级选项)”。我们将添加一个负面提示,设置种子,并应用细化器以获得最佳的图像质量。
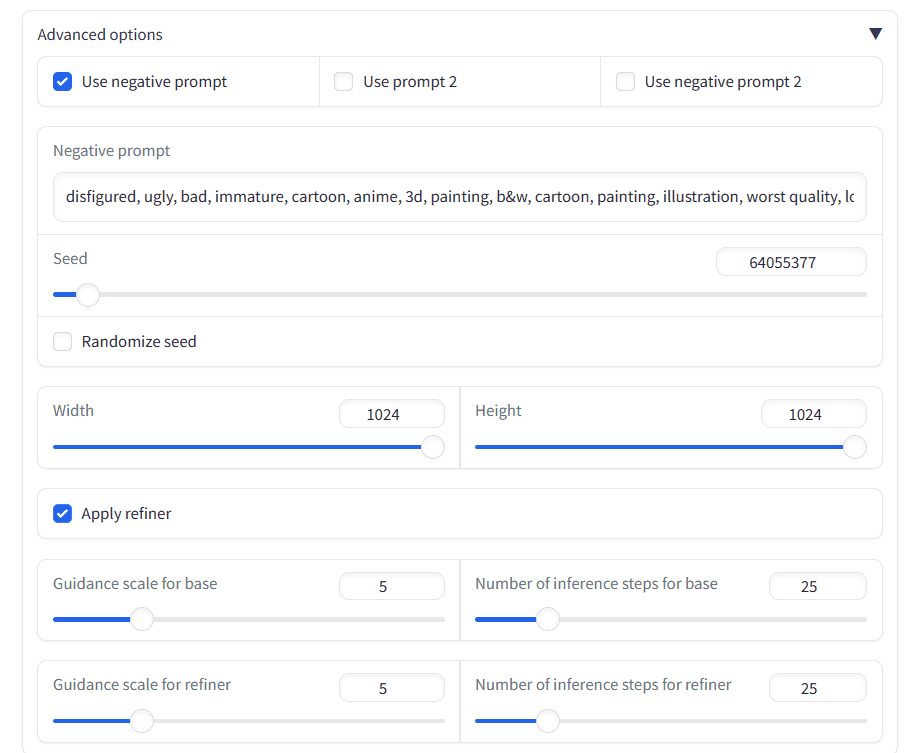
然后,我们将以与之前略有不同的方式编写相同的提示。我们将生成一个年轻的印度女子的图像,而不是普通的年轻女性。

这个结果有了很大的改进。面部特征非常完美。让我们尝试生成其他民族的图像,检查是否存在偏差,并比较结果。

我们得到了逼真的人脸,但所有图片都使用了Instagram滤镜。通常,现实生活中的皮肤并不光滑,而是有粉刺、印记、雀斑和细纹等。
3. CivitAI: RealVisXL V2.0
在这部分,我们将生成带有痕迹和真实肌肤的详细人脸。为此,我们将使用CivitAI的自定义模型(RealVisXL V2.0),该模型经过优化,用于生成高质量肖像。
【链接】:civitai.com/models/139562/realvisxl-v20
可以通过点击“Create(创建)”按钮在线使用该模型;也可以下载它,以在Stable Diffusion WebUI上本地使用。
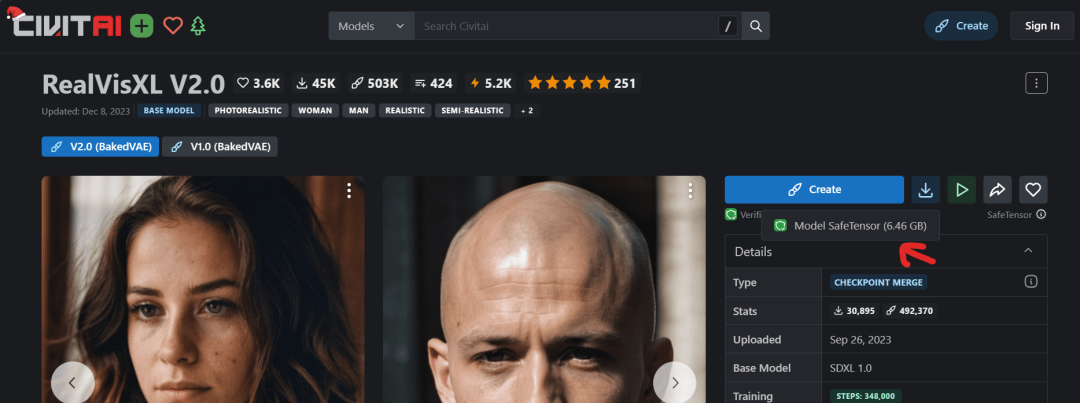
首先,下载模型并将文件移动到Stable Diffusion WebUI模型目录:C:\WebUI\webui\models\Stable-diffusion。
要在WebUI上显示模型,需要按下刷新按钮,然后选择“realvisxl20…”模型检查点。
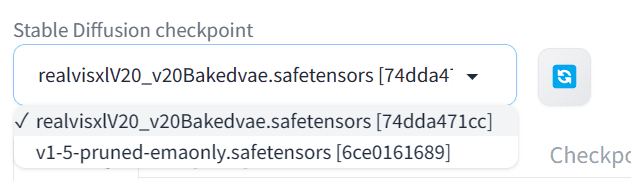
我们将从编写相同的正面和负面提示开始,并生成一张高质量的1024X1024图像。

图像看起来非常完美,为了充分利用自定义模型,我们需要更改提示。

新的正面和负面提示可以通过滚动模型页面并点击喜欢的真实图像来获得。CivitAI上的图像具有正面和负面提示以及高级转向功能。
正面提示:“An image of an Indian young woman, focused, decisive, surreal, dynamic pose, ultra highres, sharpness texture, High detail RAW Photo, detailed face, shallow depth of field, sharp eyes, (realistic skin texture:1.2), light skin, dslr, film grain”。
负面提示:“(worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), open mouth”。
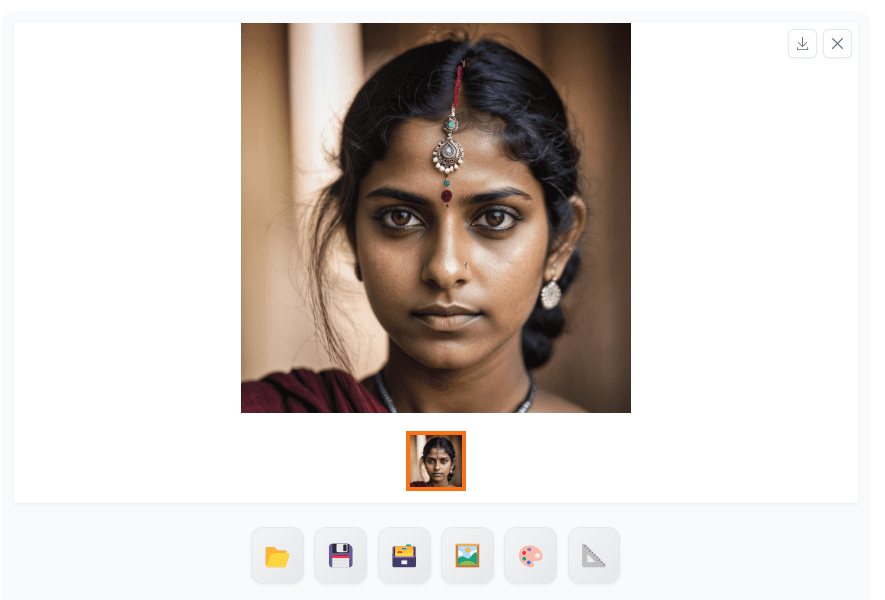
我们有了一张具有真实肌肤的印度妇女的详细图像。与基础SDXL模型相比,这是一个改进版本。
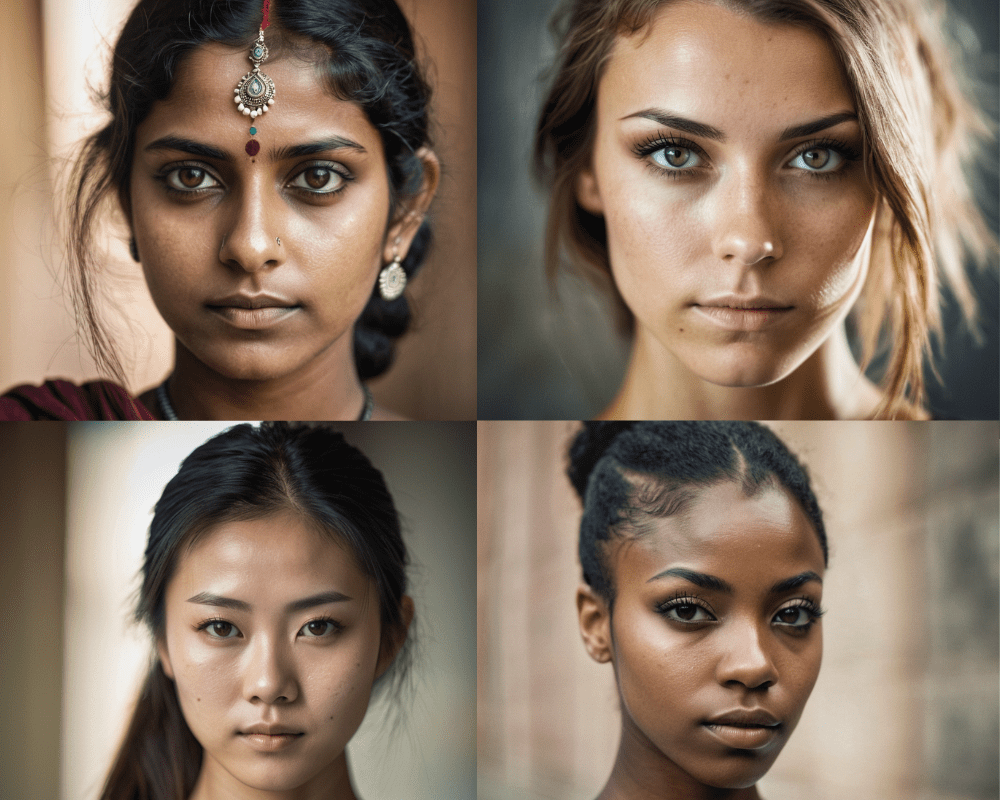
我们又生成了三张不同民族的图像,以比较结果。结果非常出色,包含皮肤痕迹、多孔皮肤和准确的特征。


















 5574
5574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











