









大家好,Pandas库众所周知,适合数据分析新手入门,但在大数据面前却显得处理缓慢。相比之下,开源的DuckDB以其卓越的列式存储性能,在大数据处理上速度惊人,速度远超Pandas。而且,DuckDB配备了Python库,让熟悉SQL的用户能够快速转换,大幅提升数据处理效率,接下来看看这两者在处理超亿级数据时的性能对比。
1.Pandas与DuckDB基准测试设置
下面展示基准测试所用的数据集和Pandas与DuckDB的代码实现。测试基于 M2 Pro MacBook Pro 12/19 核、16 GB 内存设备进行。
1.1 数据集信息
所使用的数据集是纽约市出租车和豪华轿车委员会(TLC)提供的行程记录数据。这些数据是在2024年4月18日从纽约市政府官方网站获取的,可以免费使用(https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page)。有关数据使用的许可信息,可以在nyc.gov网站上查询。
1.2 基准测试目标
基准测试的目标是使用Pandas和DuckDB两个工具加载Parquet格式的数据文件,进一步计算月度统计信息,包括行程总数、平均持续时间、行驶距离、总车费以及小费金额。
为此,需要生成几个日期时间字段,依据特定时间段对数据进行筛选,并在Pandas中有效管理多级索引。
数据加载完成后,会发现要处理的数据超过1.11亿条:

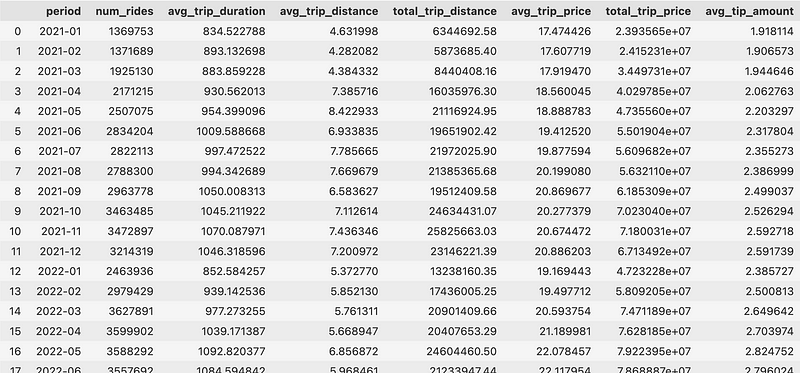
对于结果,希望得到以下 DataFrame:
1.3 Pandas设置
Pandas是一个为简便数据处理而设计的单线程库,并不擅长快速处理大量数据。
Pandas首先需要将全部数据一次性加载入内存,在处理Parquet文件时,还得依次单独读取每个文件,这一过程并不高效。
此外,使用Pandas时还需应对多级索引重置的繁琐工作,这一步骤是为了使各个列的数据更易于访问:
import os
import pandas as pd
# 加载数据
base_path = "path/to/the/folder"
parquet_files = [os.path.join(base_path, file) for file in os.listdir(base_path) if file.endswith('.parquet')]
dfs = [pd.read_parquet(file) for file in parquet_files]
df_pd = pd.concat(dfs, ignore_index=True)
# 基准测试函数
def calculate_monthly_taxi_stats_pandas(df: pd.DataFrame) -> pd.DataFrame:
# ...(此处省略函数实现细节)
return df
# 运行
res_pandas = calculate_monthly_taxi_stats_pandas(df=df_pd)
2.DuckDB设置
通过Python与DuckDB进行交互有多种方法,但最直接简便的方式是使用类似SQL的命令。实际上,仅需两条SELECT语句,即可实现之前用Pandas编写的代码功能。
DuckDB还内置了一个高效的parquet_scan()函数,能够同时读取指定路径下的所有Parquet文件,大大提高了数据处理的效率:
import duckdb
# 数据库连接
conn = duckdb.connect()
# 基准测试函数
def calculate_monthly_taxi_stats_duckdb(conn: duckdb.DuckDBPyConnection, path: str) -> pd.DataFrame:
# ...(此处省略函数实现细节)
return df
# 运行
res_duckdb = calculate_monthly_taxi_stats_duckdb(conn=conn, path="path/to/the/folder/*parquet")
3.基准测试结果
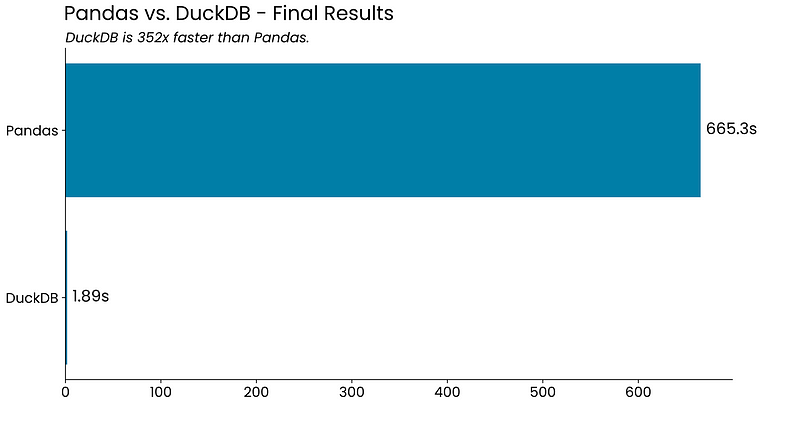
DuckDB能在两秒之内处理超过1亿条记录的庞大数据集,其速度之快令人难以置信,处理速度比Pandas快352倍。如果能接受DuckDB的某些局限,它肯定是一个可行的Pandas替代品。
4.总结
总的来说,DuckDB能够使用大家熟悉的SQL语言来快速编写并执行数据聚合查询,速度提升了几个数量级。
DuckDB还支持多种文件格式,包括JSON、CSV和Excel,并且能够与多家数据库厂商的产品兼容。如果你打算在更专业的环境下使用DuckDB,你将有很多灵活的选择。
















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











