







前言
SIMD(Single Instruction Multiple Data)是CPU硬件层面支持的用于对数据进行并行操作。
原理:采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术
它的指令集存在如下:
-
X86下的实现为MMX、SSE、AVX指令集
-
ARM下的实现为NEON指令集
MMX
1996年Intel推出了X86的MMX(MultiMedia eXtension)指令集
- MMX定义了8个64位寄存器(MM0-MM7),以及相应的操作指令
- 可用于以“压缩”格式保存64位整数或多个较小整数,并没有浮点数的支持!
注意:上面说的是x86的指令扩展,可以看到有点类似于64兼容32操作系统架构"rdi->edi"。
2003年才以 x86-64 和 64 位 PowerPC 处理器架构的形式引入到(在此之前是 32 位)个人计算机领域的主流。
SSE
1999年推出了全面覆盖MMX的SSE(Streaming SIMD Extensions)流式SIMD扩展指令集
- 添加了8个新的128位寄存器(XMM0-XMM7)
- 开始支持单个寄存器存储4个32位单精度浮点数
X86-64架构世界的到来:
- 在原来的基础上添加了8个寄存器(XMM8至XMM15)
- 支持单个寄存器存储2个64位双精度浮点数
AVX
2011年推出了延伸SSE的AVX(Advanced Vector Extensions)高级向量扩展指令集
- 引入了16个256位寄存器(YMM0-YMM15)
- AVX的256位寄存器和SSE的128位寄存器存在着相互重叠的关系(XMM寄存器为YMM寄存器的低位)
最好不要混用AVX与SSE指令集,否在会导致transition penalty(过渡处罚)
目前Apple OS X 10.6.8、Linux 2.6.30、Windows 7,可见现在AVX指令集是一个主流指令集
总结:
使用
实现SIMD的方法如下:
- 使用Intel开发的跨平台函数库(Intel IPP库)
- 借助于Auto-vectorization(自动矢量化),即借助编译器将标量操作转化为矢量操作
- 使用编译器指示符,如Cilk里的#pragma simd和OpenMP里的#pragma omp simd
- 使用内置函数,高级语言中类似调用普通函数一样使用simd,函数的具体实现定义在编译器中
- 使用汇编直接操作SIMD指令和寄存器,高级语言中嵌入汇编代码,极致的性能优化
FFmpeg对simd的使用就是“内置函数”形式
如:4.2.2中 的libavutil/x86/intmath.h:#include<immintrin.h>4.2.2中没找到向量寄存器的使用
内置函数使用
SSE/AVX指令主要定义于以下一些头文件中:
- <xmmintrin.h> : SSE, 支持同时对4个32位单精度浮点数的操作。
- <emmintrin.h> : SSE 2, 支持同时对2个64位双精度浮点数的操作。
- <pmmintrin.h> : SSE 3, 支持对SIMD寄存器的水平操作(horizontal operation),如hadd, hsub等…。
- <tmmintrin.h> : SSSE 3, 增加了额外的instructions。
- <smmintrin.h> : SSE 4.1, 支持点乘以及更多的整形操作。
- <nmmintrin.h> : SSE 4.2, 增加了额外的instructions。
- <immintrin.h> : AVX, 支持同时操作8个单精度浮点数或4个双精度浮点数。
每一个头文件都包含了之前的所有头文件,所以引用immintrin.h即可使用SSE、AVX的内在函数
SSE/AVX命名规则
数据类型通常以_mxxx(T)的方式进行命名
xxx代表数据的位数:
- SSE提供的__m128为128位
- AVX提供的__m256为256位
T为类型:
- 若为单精度浮点型则省略
- 若为整形则为i,如__m128i
- 若为双精度浮点型则为d,如__m256d。
操作浮点数的内置函数命名方式为_mm(xxx)_name_PT
name为函数执行的操作的名字:
- _mm_add_ps ,加法
- _mm_sub_ps ,减法
P代表的是对矢量或者标量进行操作:
- _mm_add_ss ,只对最低位的32位浮点数执行加法
- _mm_add_ps ,对4个32位浮点数执行加法操作
T代表浮点数的类型:
- _mm_add_pd, d则为双精度浮点
- _mm_add_ps, s则为单精度浮点型
操作整形的内置函数命名方式为:_mm(xxx)_name_epUY
U为整数的类型:
- _mm_adds_epu16 , u为无符号类型
- _mm_adds_epi16 , i为有符号类型
Y为操作的数据类型的位数:
- _mm_cvtpd_pi32
SSE/AVX操作类别
存取操作(load/store/set)
- load系列可以用来从内存中载入数据到SSE/AVX提供的类型中
- store系列可以将SSE/AVX提供的类型中的数据存储到内存中
- set系列可以直接设置SSE/AVX提供的类型中的数据
算术运算(常用部分)
- _mm_add_ps,_mm_add_ss等加法系列
- _mm_sub_ps,_mm_sub_pd等减法系列
- _mm_mul_ps,_mm_mul_epi32等乘法系列
- _mm_div_ps,_mm_div_ss等除法系列
- _mm_sqrt_pd,_mm_rsqrt_ps等开平方系列
- _mm_rcp_ps,_mm_rcp_ss等求倒数系列
- _mm_dp_pd,_mm_dp_ps计算点乘
比较运算(常用部分)
- _mm_max_ps逐分量对比两个数据,并将较大的分量存储到返回类型的对应位置中。
- _mm_min_ps逐分量对比两个数据,并将较小的分量存储到返回类型的对应位置中。
- _mm_cmpeq_ps逐分量对比两个数据是否相等。
- _mm_cmpge_ps逐分量对比一个数据是否大于等于另一个是否相等。
- _mm_cmpgt_ps逐分量对比一个数据是否大于另一个是否相等。
- _mm_cmple_ps逐分量对比一个数据是否小于等于另一个是否相等。
- _mm_cmplt_ps逐分量对比一个数据是否小于另一个是否相等。
- _mm_cmpneq_ps逐分量对比一个数据是否不等于另一个是否相等。
- _mm_cmpnge_ps逐分量对比一个数据是否不大于等于另一个是否相等。
- _mm_cmpngt_ps逐分量对比一个数据是否不大于另一个是否相等。
- _mm_cmpnle_ps逐分量对比一个数据是否不小于等于另一个是否相等。
- _mm_cmpnlt_ps逐分量对比一个数据是否不小于另一个是否相等。
逻辑运算(常用部分)
- _mm_and_pd对两个数据逐分量and
- _mm_andnot_ps先对第一个数进行not,然后再对两个数据进行逐分量and
- _mm_or_pd对两个数据逐分量or
- _mm_xor_ps对两个数据逐分量xor
实战
以下使用宏定义方式分别运行AVX、SSE指令集:
//Building :
//- AVX Pattern "clang demo.c -D AVX -mavx && ./a.out"
//- SSE Pattern "clang demo.c && ./a.out"
#include <stdio.h>
#include <immintrin.h>
#include <sys/time.h>
#define N 170 * 1024 * 1024
#define SEED 0x100
int main(){
#if defined(AVX)
//AVX
float* a = (float*) _mm_malloc(N * sizeof(float), 32);
float* b = (float*) _mm_malloc(N * sizeof(float), 32);
float* c = (float*) _mm_malloc(N * sizeof(float), 32);
#else
//SSE
float* a = (float*) _mm_malloc(N * sizeof(float), 16);
float* b = (float*) _mm_malloc(N * sizeof(float), 16);
float* c = (float*) _mm_malloc(N * sizeof(float), 16);
#endif
srand(SEED);
for (int i = 0; i < N; i++) {
a[i] = b[i] = (float)(rand() % N);
}
struct timeval before, after;
gettimeofday(&before, NULL);
//====================begin times====================
int i = 0;
#if defined(AVX)
//AVX
__m256 A,B,C; // 向量类型 __m256 = 8xfloat
for (; i < (N & (~(unsigned)7)); i+=8) {
A = _mm256_load_ps(&a[i]); //256bit = 32byte 表示并行操作32byte数据
B = _mm256_load_ps(&b[i]);
//将压缩的单精度浮点值从对齐的内存位置移动到目标向量。对应的英特尔®avx指令为 VMOVAPS
C = _mm256_mul_ps(A,B);
//将浮点数与32个向量相乘。对应的英特尔®avx指令为 VMULPS
_mm256_store_ps(&c[i],C);
//将打包的单精度浮点值从float32向量移动到对齐的内存位置。相应的英特尔®AVX指令是VMOVAPS。 即__m256 C 移动到 c指针的位置
}
#else
//SSE
__m128 A,B,C; // 向量类型 __m128 = 4xfloat
for (; i < (N & (~(unsigned)3)); i+=4) {
A = _mm_load_ps(&a[i]);
B = _mm_load_ps(&b[i]);
C = _mm_mul_ps(A,B);
_mm_store_ps(&c[i],C);
}
#endif
//====================end times====================
gettimeofday(&after, NULL);
printf("%f, %f, %f, %f\n", c[0], c[1], c[N-2], c[N-1]);
double msecs = 0.0;
msecs = (after.tv_sec - before.tv_sec)*1000.0 + (after.tv_usec - before.tv_usec)/1000.0;
#if defined(AVX)
printf("AVX pattern execution time = %2.3lf ms\n", msecs);
#else
printf("SSE pattern execution time = %2.3lf ms\n", msecs);
#endif
_mm_free(c);
_mm_free(b);
_mm_free(a);
return 0;
}
运行结果:
$ clang demo.c && ./a.out
SSE pattern execution time = 512.333 ms
$ clang demo.c -D AVX -mavx && ./a.out
AVX pattern execution time = 417.597 ms
汇编使用
go的数据操作模块
var a []byte
var b []byte
for i,_ := range a{
if a[i] != b[i]
return false;
}
下图是使用 SIMD 技术优化汇编代码前后的对比图:
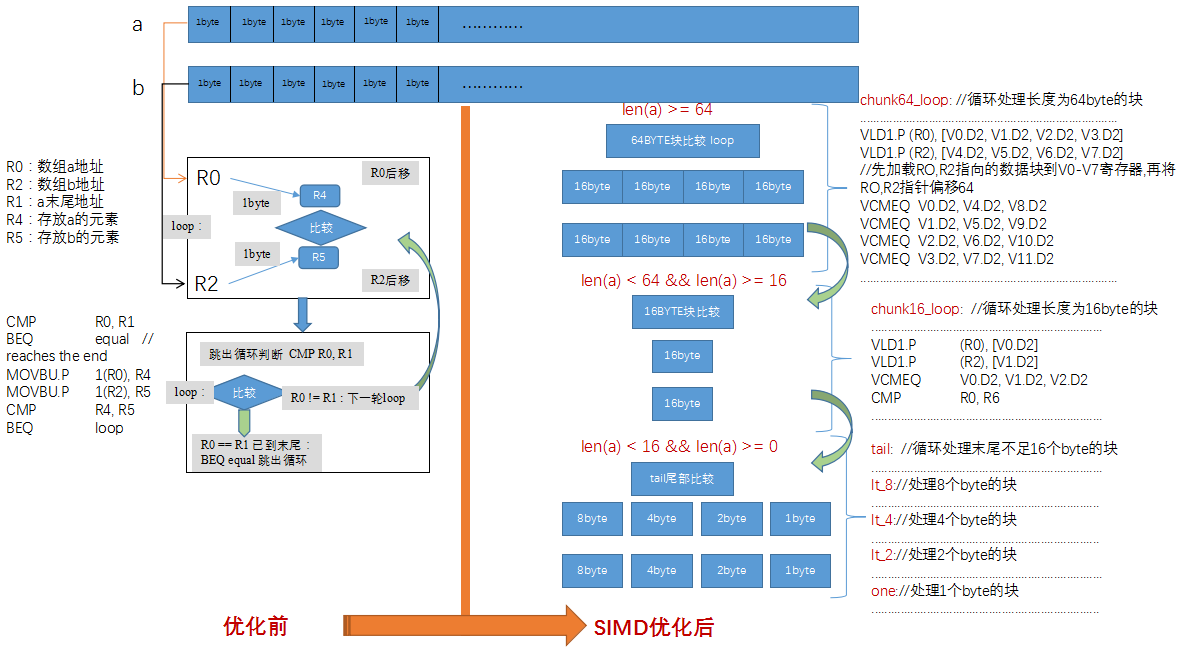
优化前代码详解
//func Equal(a, b []byte) bool
TEXT bytes·Equal(SB),NOSPLIT,$0-49
//---------数据加载------------
// 将栈上数据取到寄存器中
// 对数组长度进行比较,如果不相等直接返回0
MOVD a_len+8(FP), R1 // 取数组a的长度
MOVD b_len+32(FP), R3 // 取数组b的长度
CMP R1, R3 // 数组长度比较
BNE notequal // 数组长度不同,跳到notequal
MOVD a+0(FP), R0 // 将数组a的地址加载到通用寄存器R0中
MOVD b+24(FP), R2 // 将数组b的地址加载到通用寄存器R2中
ADD R0, R1 // R1保存数组a末尾的地址
//-----------------------------
//--------数组循环比较操作-------
loop:
CMP R0, R1 // 判断是否到了数组a末尾
BEQ equal // 如果已经到了末尾,说明之前都是相等的,跳转到标签equal
MOVBU.P 1(R0), R4 // 从数组a中取一个byte加载到通用寄存器R4中
MOVBU.P 1(R2), R5 // 从数组b中取一个byte加载到通用寄存器R5中
CMP R4, R5 // 比较寄存器R4、R5中的值
BEQ loop // 相等则继续下一轮循环操作
//-----------------------------
//-------------不相等-----------
notequal:
MOVB ZR, ret+48(FP) // 数组不相等,返回0
RET
//-----------------------------
//-------------相等-------------
equal:
MOVD $1, R0 // 数组相等,返回1
MOVB R0, ret+48(FP)
RET
//-----------------------------
优化后代码详解
// 函数的参数,此处是通过寄存器传递参数的
// 调用memeqbody的父函数已经将参数放入了如下寄存器中
// R0: 寄存器R0保存数组a的地址
// R1: 寄存器R1数组a的末尾地址
// R2: 寄存器R2保存数组b的地址
// R8: 寄存器R8存放比较的结果
TEXT runtime·memeqbody<>(SB),NOSPLIT,$0
//---------------数组长度判断-----------------
// 根据数组长度判断按照何种分块开始处理
CMP $1, R1
BEQ one
CMP $16, R1
BLO tail
BIC $0x3f, R1, R3
CBZ R3, chunk16
ADD R3, R0, R6
//------------处理长度为64 bytes的块-----------
// 按64 bytes为块循环处理
chunk64_loop:
// 加载RO,R2指向的数据块到SIMD向量寄存器中,并将RO,R2指针偏移64位
VLD1.P (R0), [V0.D2, V1.D2, V2.D2, V3.D2]
VLD1.P (R2), [V4.D2, V5.D2, V6.D2, V7.D2]
// 使用SIMD比较指令,一条指令比较128位,即16个bytes,结果存入V8-v11寄存器
VCMEQ V0.D2, V4.D2, V8.D2
VCMEQ V1.D2, V5.D2, V9.D2
VCMEQ V2.D2, V6.D2, V10.D2
VCMEQ V3.D2, V7.D2, V11.D2
// 通过SIMD与运算指令,合并比较结果,最终保存在寄存器V8中
VAND V8.B16, V9.B16, V8.B16
VAND V8.B16, V10.B16, V8.B16
VAND V8.B16, V11.B16, V8.B16
// 下面指令判断是否末尾还有64bytes大小的块可继续64bytes的循环处理
// 判断是否相等,不相等则直接跳到not_equal返回
CMP R0, R6 // 比较指令,比较RO和R6的值,修改寄存器标志位,对应下面的BNE指令
VMOV V8.D[0], R4
VMOV V8.D[1], R5 // 转移V8寄存器保存的结果数据到R4,R5寄存器
CBZ R4, not_equal
CBZ R5, not_equal // 跳转指令,若R4,R5寄存器的bit位出现0,表示不相等,跳转not_equal
BNE chunk64_loop // 标志位不等于0,对应上面RO!=R6则跳转chunk64_loop
AND $0x3f, R1, R1 // 仅保存R1末尾的后6位,这里保存的是末尾不足64bytes块的大小
CBZ R1, equal // R1为0,跳转equal,否则向下顺序执行
...............................................
...............................................
//-----------循环处理长度为16 bytes的块------------
chunk16_loop:
VLD1.P (R0), [V0.D2]
VLD1.P (R2), [V1.D2]
VCMEQ V0.D2, V1.D2, V2.D2
CMP R0, R6
VMOV V2.D[0], R4
VMOV V2.D[1], R5
CBZ R4, not_equal
CBZ R5, not_equal
BNE chunk16_loop
AND $0xf, R1, R1
CBZ R1, equal
//-----处理数组末尾长度小于16、8、4、2 bytes的块-----
tail:
TBZ $3, R1, lt_8
MOVD.P 8(R0), R4
MOVD.P 8(R2), R5
CMP R4, R5
BNE not_equal
lt_8:
TBZ $2, R1, lt_4
MOVWU.P 4(R0), R4
MOVWU.P 4(R2), R5
CMP R4, R5
BNE not_equal
lt_4:
TBZ $1, R1, lt_2
MOVHU.P 2(R0), R4
MOVHU.P 2(R2), R5
CMP R4, R5
BNE not_equal
lt_2:
TBZ $0, R1, equal
one:
MOVBU (R0), R4
MOVBU (R2), R5
CMP R4, R5
BNE not_equal
//-----------------判断相等返回1----------------
equal:
MOVD $1, R0
MOVB R0, (R8)
RET
//----------------判断不相等返回0----------------
not_equal:
MOVB ZR, (R8)
RET
上述优化代码中:
- 使用 VLD1(数据加载指令)一次加载 64bytes 数据到 SIMD 寄存器
- 再使用 VCMEQ(相等比较指令)比较 SIMD 寄存器保存的数据内容得到结果
大于 16byte 小于 64byte 块数据,使用一个 SIMD 寄存器一次处理 16byte 块的数据
小于 16byte 数据块使用通用寄存器保存数据,一次比较 8\4\2\1byte 的数据块
引用文章
- https://juejin.cn/post/7091571543239000078
- https://xie.infoq.cn/article/9354c2496e3652fd6560aa074
- https://zhuanlan.zhihu.com/p/55327037
- https://www.eet-china.com/mp/a71752.html














 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









