






训练神经网络基本采用反向传播+梯度下降来进行,具体过程如下:
全连接层神经元之间互相连接,假设第一层有三个节点,第二层有个节点,如下图所示:

我们通过w11,w12,w21,w22,w31,w32来分别表示神经网络中节点到节点的权重,实际上,这可以被表示为矩阵的形式:

因此,神经网络层与层之间的权重矩阵W在程序中就是通过这一个个矩阵表示出来的。而刚好每一层的神经元又可以采用向量的形式表示出来,故要求得第二层神经元的各个值,我们只需要将向量与矩阵相乘就行了。(上图中向量为1*3向量,而矩阵是3*2矩阵,两个相乘得到1*2向量,这个向量刚好对应第二层的两个神经元节点)
在训练开始时,W矩阵中的所有元素被设为随机初始值(一般为-0.5--0.5,因为全连接神经网络一般用sigmoid激活函数激活,选择-0.5--0.5的值有利于反向传播顺利进行)
首先由数据进入一个随机生成参数的网络,数据不断通过神经元及激活函数向前传播,直至到达输出层,在训练过程中,我们会有监督值t来监督这次前向传播的值是否正确,如果不正确,则监督值会传出一个误差值,告诉这个网络你的计算和我想要的差了多少。这个过程有点像猜数字游戏,A心里想好一个数,B来猜,B先猜是5,A说小了,那B就会说一个比5大的数。
神经网络的更新与此相似,但是输出层告诉整个神经网络的是一个精准的误差值,而整个神经网络要调整的是整个权重矩阵的参数,而不是像猜数字那样,只用对一个数字进行增大或减小,具体就是告诉整个矩阵中的每一个数是该变大还是变小,而且由于矩阵是一个整体,你必须要考虑矩阵中的所有数变大变小的程度,而不是说矩阵中的每一个数都增加或减少一个定值。那怎么确定一个矩阵中的每个权重值变大还是变小,又各自改变多少呢?这就是梯度下降要做的事。
梯度是多元函数微分中的概念,相当于分别求得矩阵中各个变量下降最快的方向,那么,用这个方向乘以一定的步长就可以粗略的作为该次反向传播w权值的更新结果。
原理如下:我们通过监督值t减去网络给出的输出值得到误差,但我们一般采用均方误差:
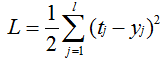
我们改变W矩阵的各个值,目的是为了使损失L最小。
即我们求得W对L的梯度表达式:
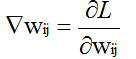
通过一次误差反向传播,原理与正向传播一致,拿上图的例子说明即:一个1*2误差向量乘上2*3(W的转置)得到1*3向量,按照这样的做法,我们可得到各个层的误差值。(详细的数学推导我另发帖子阐明,对于编程来讲,了解是如何操作的就够了)
而刚好L可以被y表达出来(第一个式子),且y又可以被如下式子表示,其中f()表示激活函数
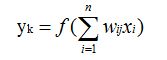
那么由多元微分的传递性可得:
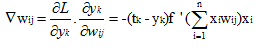
f '()中的值实际上就是该层节点没有经过激活函数而只有线性求和的值。而t-y表示误差,xi是上一层的输入。有了梯度,这样我们就知道W矩阵中的每个值该如何修改了。















 7378
7378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









