







本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:高密度人群计数算法,苏大发布VMambaCC,既要全局感受野,也要推理速度!
以下文章来源于微信公众号:AI视界引擎
作者:AI引擎
链接:https://mp.weixin.qq.com/s/Ds1glOMW4szn-i6D6iljGQ
0 导读
人群计数是利用视觉模型对图像或视频中个体数量分析的关键任务,但是该任务往往具有高密度、遮挡和小目标等挑战。今天分享苏大发布的VMambaCC状态空间模型,兼顾全局感受野和推理速度!

论文链接:https://arxiv.org/abs/2405.03978
作为深度学习模型,Visual Mamba(VMamba)具有低计算复杂度和全局感受野,已成功应用于图像分类和检测。为了扩展其应用范围,作者将VMamba应用于人群计数,并提出了一种新型的VMambaCC(VMamba人群计数)模型。
自然地,VMambaCC 继承了 VMamba的优点,即对图像的全局建模和低计算成本。此外,作者为VMambaCC设计了一种多头高级特征(MHF)注意力机制。
MHF是一种新的注意力机制,它利用高级语义特征增强低级语义特征,从而以更高的精度增强空间特征表示。在MHF的基础上,作者进一步提出了一种高级语义监督特征金字塔网络(HS2PFN),该网络逐步整合并增强高级语义信息与低级语义信息。
在五个公共数据集上的大量实验结果验证了作者的方法的有效性。例如,在ShangHaiTech_PartA数据集上,作者的方法取得了平均绝对误差51.87和均方误差81.3的成绩。
1 引言
人群计数是指使用计算机视觉技术对图像或视频中的个体数量进行量化的任务。这项任务对于预测人群趋势和优化资源分配具有重要意义,并且可以为许多实际应用提供关键信息,例如城市规划、安全监控和零售分析。
对于人群计数任务,面临的挑战包括高密度、遮挡和小目标。为了应对这些挑战,当前的人群计数模型主要基于两种架构构建:卷积神经网络(CNNs)和 Transformer 。
CNN是一种专门用于处理图像等数据的深度学习模型。有许多经典的用于人群计数的CNN模型,例如多列CNN、拥堵场景识别网络(CSRNet)、上下文感知特征网络(CANNet)、基于浅层特征的密集注意力网络(SDANet)和精细特征提取网络(FGENet)。这些模型利用CNN提取特征并融合多尺度特征来计数个体。然而,这些方法对位置和尺度变化敏感。此外,正如Kolesnikov等人所指出的,基于CNN的模型难以获得全局感受野;因此,这些模型在处理多尺度个体时受到限制。
作者的方法能够更高效地处理过程,计算复杂度始终保持在较低水平。作者的主要贡献如下:
-
提出了一个新颖的VMambaCC模型,这是第一个用于高密度人群计数的视觉状态空间模型。VMambaCC不仅具有全局感受野,而且具有快速的学习和推理速度。
-
VMambaCC包含一种新型的多头高级特征(MHF)增强机制,该机制通过加强高级语义特征来增强低级语义信息。
-
在MHF注意力机制的基础上,本研究提出了一种特征融合网络,即高级语义监督特征金字塔网络(HS2FPN)。这个网络逐步融合了不同尺度的信息,并部分保留了高级语义特征。
本文后续部分的结构如下。
- 在第2节中,作者提供了与人群计数任务相关文献的简洁回顾。
- 第3节深入介绍了VMambaCC模型,包括其架构、设计理念以及创新组件,包括MHF注意力机制和HS2FPN特征融合网络。
- 第4节展示了作者关于计数、定位和消融研究的成果,为作者的模型提供了全面评估和分析。
- 最后,第5节总结了本文。
2 相关工作
人群计数在计算机视觉领域引起了广泛关注。几十年来,人群计数的方法包括基于检测的方法,保持了高级特征监督并捕捉不同分辨率下的个体信息。最后,在预测阶段之后,作者的模型输出图像X中个体的位置和置信度分数。

2.1 MHF attention mechanism
图3展示了MHF注意力的结构。大致上,MHF注意力可以划分为 三个部分:通道增强模块(CEM),多 Head 空间增强模块(MSEM),以及高级CEM(HCEM)。
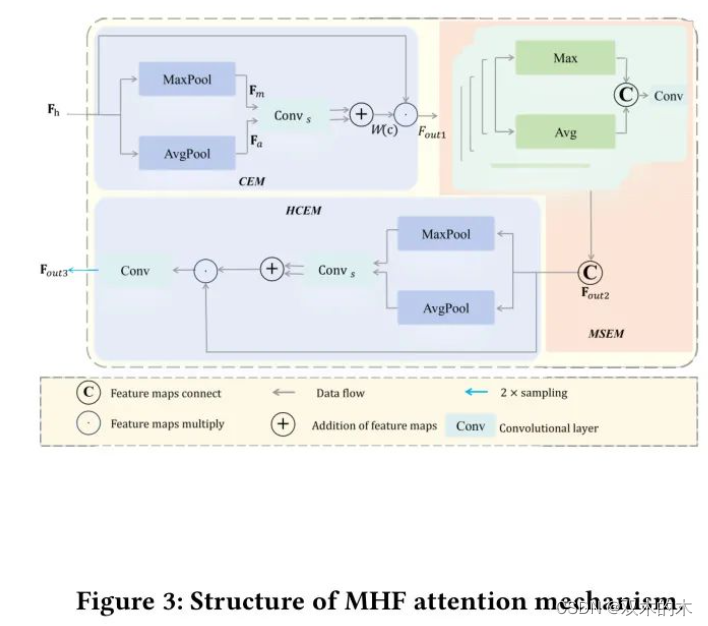
Cem
CEM的目的是为通道分配注意力权重,使模型能够更好地选择和强调重要特征。在这个模块中,高级特征图通过最大池化和平均池化层。

Msem
MSEM的作用是让模型关注有用的信息,这可以提高模型的鲁棒性。如果作者只在所有通道的特征图中提取最大值和平均值,那么很可能会丢失许多细粒度的信息。
因此,作者将特征图划分为多个组,并设计多头空间特征以关注不同组别的细粒度信息。

Hcem

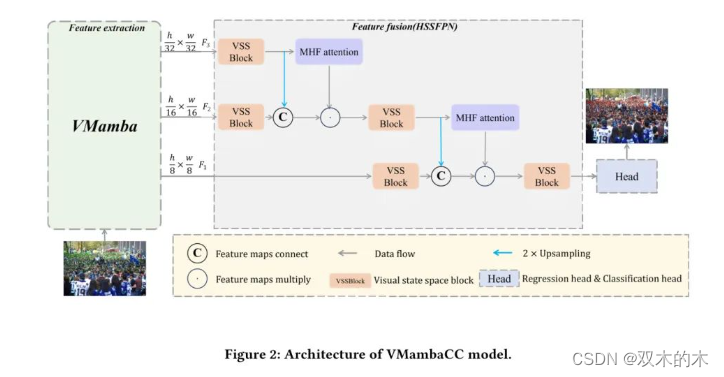
Hs2FPN
作者对现有的人群计数模型进行了彻底的分析,发现现有的特征融合网络在处理高密度和复杂场景时存在局限性。主要限制在于这些网络的全球感知能力不足,无法有效捕捉图像中的整体信息,以及对场景中关键特征提取和表示的不充分,特别是在处理遮挡和人群不同尺度变化时。
因此,HS2FPN旨在解决这些问题,从而提高人群计数的准确性和鲁棒性。
HS2FPN主要由多个视觉状态空间(VSS)和MHF注意力块组成。VSS是来自VMamba 的一个模块,可以通过四向扫描策略有效增强模型对图像全局信息的感知,使模型能够更全面地理解场景,并提高在复杂场景中捕捉人群分布特征的能力。
这种策略为模型提供了一个独特的视角来观察和处理图像数据,同时在保持全球感知能力的同时显著降低计算复杂性。
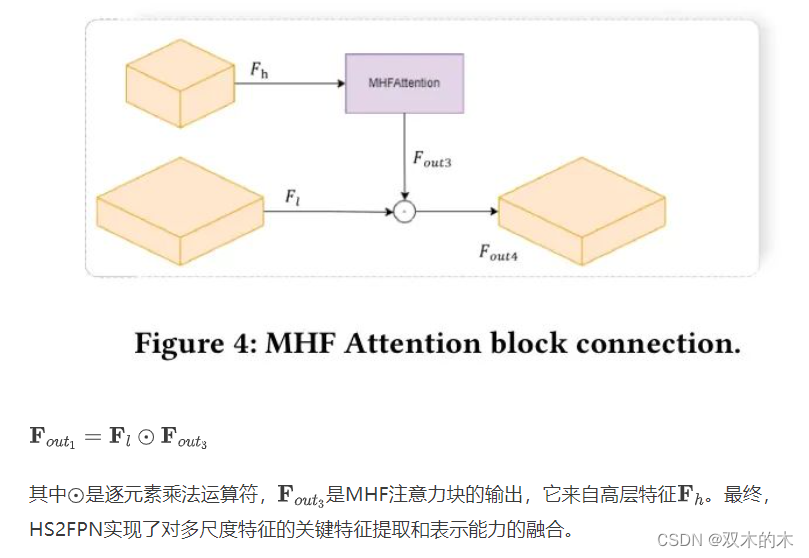
MHF注意力块通过在处理遮挡和多尺度人群时整合高层特征,增强了模型捕捉和表示重要特征的能力。此外,作者还设计了使用高层特征增强低层特征的增强方案,如图4所示。F_l设为低层特征。那么,作者的增强方案可以描述为:
3 实验
为了验证VMambaCC的有效性,作者在四个公开的人群数据集上进行了实验,并将其与最先进的模型进行了比较。
3.1 Experimental Setups
数据集。
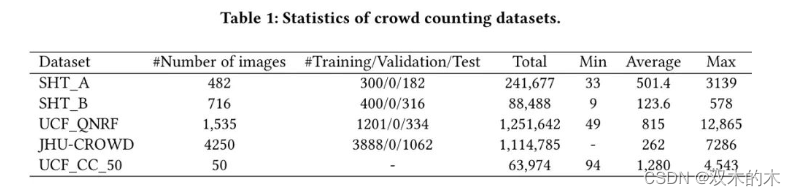
本研究使用了四个具有挑战性的数据集:
上海科技大学、UCF_QNRF 、JHU-Crowd 和 UCF_CC_50 。这些数据集的详细信息如表1所示,其中 SHT_A 和SHT_B 都属于上海科技大学数据集。
-
上海科技大学是一个大规模的人群计数数据集,包含1198张图像和330,165个标注。该数据集涵盖了各种场景类型和密度。不同密度图像的数量存在一些不平衡。SHT_A和SHT_B是其两个子集,其中SHT_A的密度显著高于SHT_B。
-
UCF-QNRF是一个包含1535张具有挑战性的图像和1,251,642个标注的数据集,图像场景多样,角度、密度和光照变化丰富。
-
JHU-Crowd是一个大规模的数据集,包含4250张图像和1,114,785个标注,平均每张图像262个人。此外,该数据集提供了丰富的标注,包括点 Level 、图像 Level 和 Head Level 的标注。
-
UCF_CC_50是一个具有挑战性的数据集,包含50张图像,平均每张图像有1280个标注。该数据集包含各种场景和视角,如音乐会、抗议、体育场馆和马拉松。
数据增强。 本研究采用了以下数据增强策略,包括以0.5的概率进行随机缩放(缩放因子从0.7到1.3),以0.5的概率进行随机水平翻转,色彩调整,添加高斯噪声,以及随机裁剪到的大小。对于QNRF数据集,作者将最大尺寸限制在不超过1408,并保持了原始图像的宽高比。
超参数设置。 作者将Adam(Kingma和Ba, 2015)优化器应用于作者的模型,学习率为。除QNRF外的所有数据集中的每张图像,作者每隔两个像素设置一个参考点。对于QNRF数据集,作者每隔两个像素在垂直和水平方向生成一个参考点。
评估指标。 对于人群计数任务,平均绝对误差(MAE)和均方误差(MSE)是两个常见的评估指标。MAE表示预测值和真实值之间的绝对误差的平均值,而MSE是预测值和真实值之间平方误差的平均值。这两个指标帮助作者评估模型在人群计数任务中的准确性和精确性,定义如下:

3.2 Counting Experiments
对于人群计数任务,VMambaCC与11种主流方法进行了比较,包括9种基于CNN的模型(MCNN),CSRNet,CANNet,ASNet,SDANet,Spatial-Channel-wise Attention Regression (SCARNet),Gaussian kernels Network (GauNet)(陈等,2018),P2PNet(杨等,2018),以及FGENet)以及2种基于Transformer的模型和LoViTCrowd。
在上海科技大学、UCF_QNRF和JHU-Crowd数据集上的实验结果如表2所示,其中最佳值以粗体显示,次佳值以下划线标出。从表2中可以看出,在MSE方面,VMambaCC在SHT_A上取得了次佳结果,比最佳方法LoViTCrowd低0.4分。
在MAE方面,作者的方法与FGENet相差0.21分。作者认为SHT_A中存在一些标注不准确的情况。
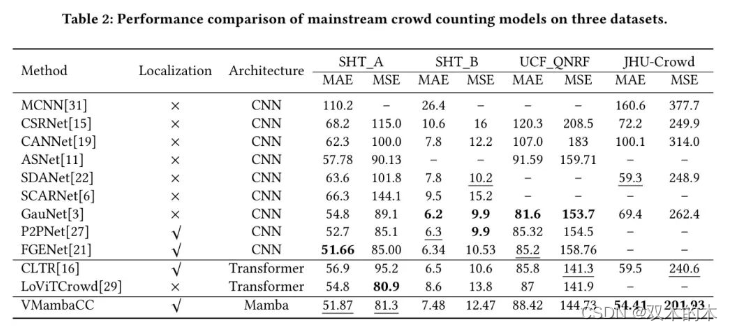
此外,基于CNN的模型GauNet在SHT_B上表现最佳,而作者基于VMamba的模型表现不佳,这可能是因为SHT_B中的样本不足和标注点较少。在这种情况下,VMambaCC与现有方法之间存在一定差距。
在UCF_QNRF数据集上,VMambaCC与当前最佳方法之间也存在一定差距。UCF_QNRF中的一些样本有数万个标注,这增加了匈牙利匹配算法的计算工作量。由于实验设备限制,作者的方法在训练过程中无法使用适当的batch_size;因此,VMambaCC无法达到最佳性能。
VMambaCC在JHU-Crowd数据集上取得了最佳结果,与排名第二的SDANet方法相比,MAE提高了4.89,与排名第二的CLTR方法相比,MSE提高了38.67。
在UCF_CC_50数据集上,采用了五折交叉验证。
结果如表3所示。与其他方法的比较列于表4中。
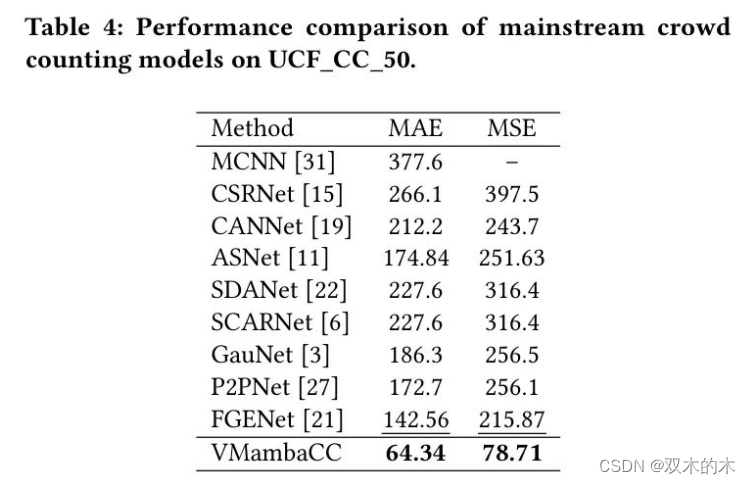
观察表4可知,作者的方法在UCF_CC_50数据集上比其他方法取得了显著改进。与排名第二的FGENet相比,VMambaCC在MAE上提高了78.22分,在MSE上提高了137.16分。显然,作者的方法已经达到了这个数据集上的最先进水平。
3.3 Localization Experiments

为了进一步验证VMambaCC的定位性能,作者还对SHT_B、JHU-Crowd和UCF_QNRF数据集进行了实验。结果展示在表6中。
很明显,作者的方法在这三个数据集上都取得了令人满意的表现。此外,这些结果为后续研究工作提供了比较的基准。

3.4 Ablation experiments
MHF. 在SHT_A数据集上对MHF注意力机制进行了简单的消融实验。可能的消融组件包括CEM、MSEM、HLCEM、头的数量以及连接位置。因此,作者分别对它们进行了消融,如表7所示。
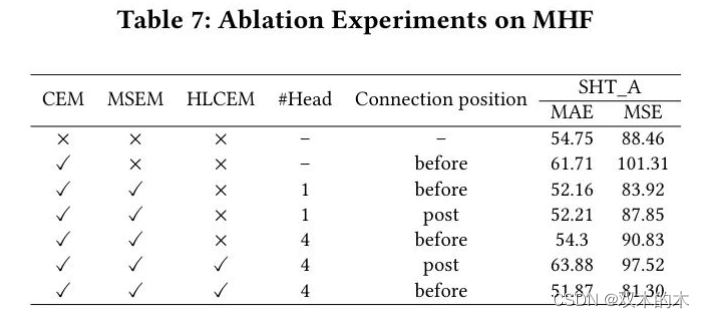
从表7可以看出,在没有MHF的 Baseline 模型(表中第一行)在SHT_A数据集上获得了54.75的MAE和88.46的MSE。当仅添加CEM(表7的第二行)时,与 Baseline 相比,模型性能下降,因为直接将高级特征与低级特征通道相乘可能会引入一些噪声。然而,当同时添加CEM和带有一个头的MSEM(表7的第三行)时,该模型的MAE和MSE都有所提高,因为此操作保留了高级特征中的空间信息。此外,当设置头数为4时,由MSEM提取的多组权重的融合效果不佳,导致与没有多 Head 操作相比,结果更差。为了确定逐元素乘法正确的位置,作者比较了特征融合前后特征增强的效果。结果表明,在特征融合后进行逐元素乘法会导致交叉效应,可能引入噪声。因此,在特征融合之前进行逐元素乘法操作更好。
特征融合 在特征融合部分也进行了比较实验。作者的特征融合网络可以被其他网络替换,如FPN(Wang等人,2017)和FGFP(Wang等人,2018)。此外,作者的HS2FPN可以删除MHF注意力机制。因此,如表8所示,比较了四种特征融合网络。
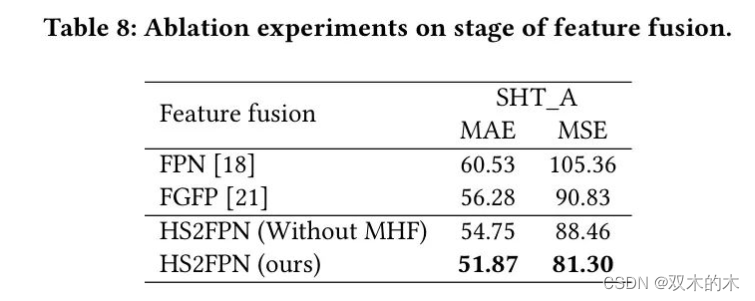
当在特征融合阶段使用FPN时,作者的模型获得了60.53的MAE和105.36的MSE。作者认为FPN简单地添加不同的特征可能会导致许多重要语义信息的丢失。使用FGFP的VMambaCC获得了56.28的MAE和90.83的MSE,这比使用FPN的VMambaCC要好。改进的原因在于FGFP对空间和通道维度进行加权,使模型能够更多地关注重要信息。在MAE和MSE方面,使用HS2FPN的VMambaCC具有最佳结果。与FGFP相比,HS2FPN在MAE上提高了4.41,在MSE上提高了9.53。这一优势主要得益于作者合理利用高级语义特征来监督低级语义特征。
3.5 Visualization
综合的实验验证了作者的方法在计数和定位领域的有效性。这些验证不仅证实了作者的方法的可靠性,还为未来模型的改进和进步奠定了坚实的理论基础。作者的预测结果展示在图5中。作者相信这些成果将显著推动该领域的研究,并为后续的技术创新奠定基础。

4 总结
在本研究中,作者引入了VMamba并提出了一个创新的人群计数模型VMambaCC。这个计数模型在人群计数背景下具有全局感受野和线性增长的计算复杂性。本研究设计了一种新的注意力机制MHF。MHF利用高级语义来指导低级语义细节的细化,因此它可以在特征融合过程中避免高级语义信息的丢失。通过将MHF机制作为基础,作者进一步开发了特征融合网络HS2FPN。广泛的实验验证确认了作者的模型在面对当前人群计数和定位挑战时的显著优势。因此,VMambaCC为人群计数领域进一步的研究和实际应用提供了重要的见解和参考框架。
5 参考
[1].VMambaCC: A Visual State Space Model for Crowd Counting.
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









