







本文来源公众号“GiantPandaCV”,仅用于学术分享,侵权删,干货满满。
原文链接:浅谈分辨率对模型影响以及训练方法
一、前言
最近几个人在讨论模型训练的时候,提到了一个尺度对于模型的影响以及训练方法的收益,因此花了点时间,简单做了几组实验,整理一下结论。
二、基础配置
本文的实验均是采用固定的配置结构以及同一套code实现,每次实验只改变分辨率等变量因素,保证实验合理性。
代码实现可以参考我的这个git repo https://github.com/FlyEgle/imageclassification
模型:ResNet50
数据集:ImageNet1k-128w
数据增强:RandomResizeCrop+RandomFlip
优化器:SGD+momentum
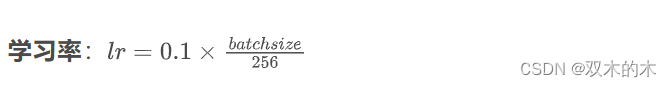
学习率衰减:cosineLr
混合精度:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









