









本文来源公众号“码科智能”,仅用于学术分享,侵权删,干货满满。
原文链接:苹果开源AIMv2通用视觉模型:性能碾压CLIP和DINOv2,视觉与文本的完美融合
用iPhone拍摄早餐,生成热量分析+营养报告;对文物照片提问,获得考古学家级解答;对图像进行指代提问,获得元素级别的理解;输入「帮我找上周会议白板」,精准定位手写笔记; 输入一段视频,通过指令即可配诗意字幕——这就是苹果AIMv2带来的真实未来!
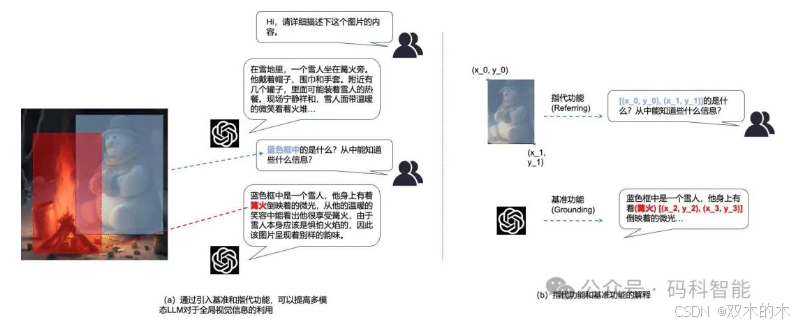
当传统视觉模型还在单模态里打转时,苹果用「图像+文本」自回归预训练杀出重围:
🔥 视觉与文本信息深度融合,看图说话精准度SOTA
🔥 手机端可部署的300M至2.7B参数模型
🔥 训练数据量仅CLIP的1/4,性能却碾压
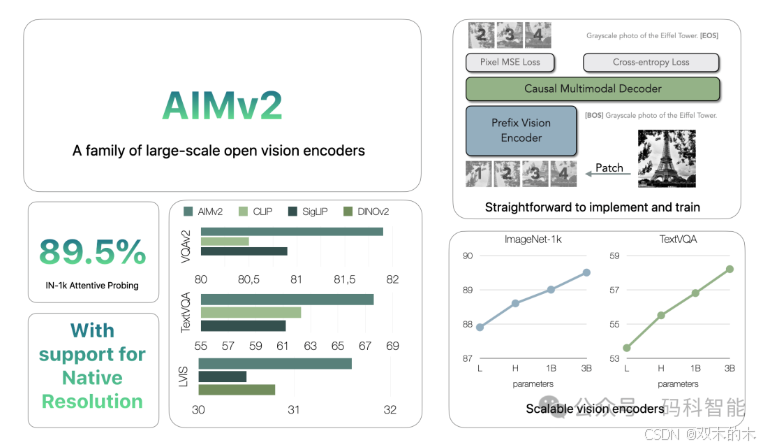
AIMV2 不再局限于仅处理视觉信息的传统模式,而是将图像和文本整合为统一的序列进行预训练。论文及开源代码如下:
Paper:https://arxiv.org/abs/2411.14402
Code:https://github.com/apple/ml-aim再来系统的介绍一下苹果的这个模型:
AIMv2是苹果公司推出的开源多模态自回归预训练视觉模型,通过深度融合图像和文本信息,提高视觉模型的性能。它采用了一种创新的预训练框架,将图像切分为非重叠的图像块,并将文本拆分为子词令牌,随后将这两种信息合并为一个统一的序列进行自回归预训练。这一方法简化了训练过程,并显著增强了模型对多模态数据的理解能力。AIMv2提供多种参数规模的版本(如300M、600M、1.2B和2.7B),能够适应从手机到PC的不同设备。

该模型的性能测试如何?
在ImageNet-1k测试中,冻结参数的AIMv2准确率89.5%,把需要全量微调的CLIP(88.3%)按在地上摩擦。并在iNaturalist、DTD和 Infographic 等关键基准测试中超越了DFN-CLIP 和 SigLIP。
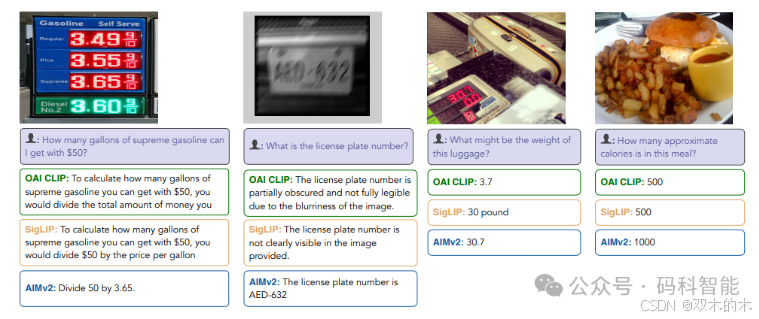
更恐怖的是:AIMV2 在训练数据量仅为 DFN-CLIP 和 SigLIP 的四分之一(12B vs. 40B)的情况下,仍能取得如此优异的成绩,且训练过程更加简便、易于扩展。
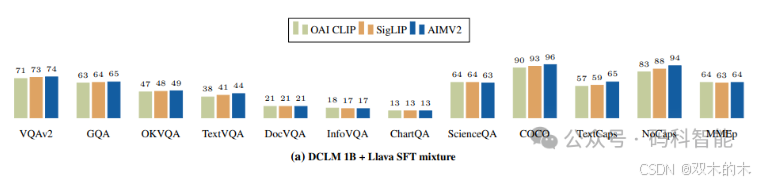
该模型的技术架构简介:
- 多模态自回归预训练框架:AIMv2 将图像分割为不重叠的小块(Patch),同时将文本分解为子词标记(Token),然后将两者拼接成一个统一的多模态序列。在预训练阶段,模型通过自回归的方式预测序列中的下一个元素,无论是图像块还是文本标记。这种设计让模型能够同时学习视觉和语言模态之间的关联,从而实现跨模态的理解与生成。
- 视觉编码器与多模态解码器:编码器基于视觉 Transformer(ViT)架构,负责处理图像 Patch,提取高质量的视觉特征。解码器采用因果自注意力机制,根据前文内容预测下一个元素,确保生成结果的连贯性与准确性。
- 损失函数设计:图像损失使用像素级回归损失,比较预测的图像块与真实图像块,提升视觉重建的精度。整体目标是最小化文本损失和图像损失的加权和,从而平衡模型在双模态上的性能表现。。
- 训练数据与扩展性:
使用了大规模图像-文本配对数据集进行预训练,包括 DFN-2B 和 COYO 等公开数据集。其训练过程高效简洁,无需过大的批量大小或复杂的跨批次通信方法。随着数据量和模型规模的增加,AIMv2 的性能持续提升,展现出优异的扩展性。
当AIMv2遇上Apple Vision Pro,元宇宙的入口正在打开。或许不久的将来,你的手机相册会主动提醒:「检测到女友新发型,推荐3款约会穿搭」——这样的世界,你敢想象吗?
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









