









本文来源公众号“数据派THU”,仅用于学术分享,侵权删,干货满满。
原文链接:用PyTorch从零构建 DeepSeek R1:模型架构和分步训练详解
全文篇幅很长,几万字,分为(上)和(下),这两篇文章建议阅读15+分钟
本文深入剖析了 DeepSeek R1 模型的构建过程。
DeepSeek R1 的完整训练流程核心在于,在其基础模型 DeepSeek V3 之上,运用了多种强化学习策略。
本文将从一个可本地运行的基础模型起步,并参照其技术报告,完全从零开始构建 DeepSeek R1,理论结合实践,逐步深入每个训练环节。通过可视化方式,由浅入深地解析 DeepSeek R1 的工作机制。
本文的代码可在github上获得,并且我将英文的注释翻译成了中文,项目文件结构:
train-deepseek-r1/├── code.ipynb # Jupyter Notebook 代码实现├── requirements.txt # 依赖库列表└── r1_for_dummies.md # 面向非技术受众的 DeepSeek R1 解释
环境配置
首先,克隆代码仓库并执行以下命令安装必要的库:
git clone https://github.com/FareedKhan-dev/train-deepseek-r1.gitcd train-deepseek-r1pip install -r requirements.txt
接下来,导入所需的 Python 库:
# 导入必要的库import loggingimport osimport sysimport reimport mathfrom dataclasses import dataclass, fieldfrom typing import List, Optional# 导入 PyTorch 与deep hub Hugging Face Transformersimport torchimport transformersfrom transformers import (AutoModelForCausalLM,AutoTokenizer,HfArgumentParser,TrainingArguments,set_seed,TrainerCallback,TrainerControl,TrainerState,)from transformers.trainer_utils import get_last_checkpoint# 导入数据集工具库import datasetsfrom datasets import load_dataset# 导入 TRL (Transformers Reinforcement Learning deep—hub) 库from trl import (AutoModelForCausalLMWithValueHead,PPOConfig,PPOTrainer,GRPOTrainer,GRPOConfig,SFTTrainer)# 导入数学相关工具库from latex2sympy2_extended import NormalizationConfigfrom math_verify import LatexExtractionConfig, parse, verify
训练数据集
尽管 DeepSeek R1 的技术报告未明确指定强化学习预训练的初始数据集,但根据其目标,我们推断数据集应侧重于推理能力。
为尽可能贴近 DeepSeek R1 的复现,本文采用以下两个开源的 Hugging Face 推理数据集:
-
NuminaMath-TIR:用于 R1 Zero 阶段的训练。
-
Bespoke-Stratos-17k:用于 R1 阶段的训练。
NuminaMath-TIR 数据集由 DigitalLearningGmbH 发布,包含 7 万个数学问题,messages 列详细记录了解题过程的思维链 (Chain-of-Thought, COT) 推理。
以下是该数据集的样本示例:
# 从 DigitalLearningGmbH 加载 "AI-MO/NuminaMath-TIR" 数据集MATH_le = load_dataset("AI-MO/NuminaMath-TIR", "default")# 访问训练集首个样本MATH_le['train'][0]
输出:
#### 输出 ####{'problem': 'What is the degree of the polynomial 4 +5x^3 ... ','solution': 'This polynomial is not written in ...','messages': [{'from': 'user', 'value': 'The problem ...'}]}#### 输出 ####
Bespoke-Stratos 数据集由 bespokelabs 提供,包含 1.7 万个问题,专注于数学和代码相关的推理任务。
以下是 Bespoke-Stratos 数据集的样本示例:
# 从 bespokelabs 加载 "Bespoke-Stratos-17k" 数据集bespoke_rl = load_dataset("bespokelabs/Bespoke-Stratos-17k", "default")# 访问训练集首个样本bespoke_rl['train'][0]
输出:
#### 输出 ####{'system': 'Your role as an assistant involves ... ','conversations': [{'from': 'user', 'value': 'Return your ... deep hub'}]}##### 输出 ####
数据集的选择并非局限于上述两个,您可以根据需求选用其他数据集,但需确保数据集侧重于推理能力,即包含问题及其详细的逐步解答。
DeepSeek R1 训练流程概览
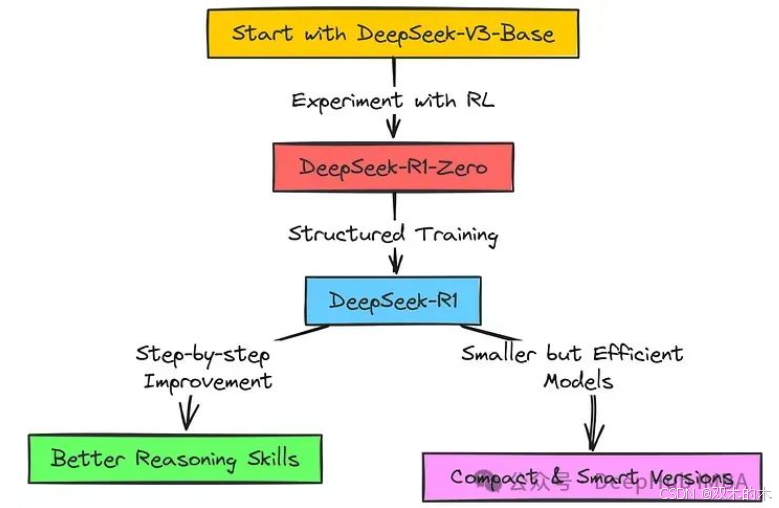
在深入技术细节之前,先对 DeepSeek R1 的训练流程进行简要概述。DeepSeek R1 并非从零开始训练,而是基于 DeepSeek 团队已有的强大语言模型 DeepSeek-V3。为了进一步提升模型的推理能力,DeepSeek 团队采用了强化学习方法。
强化学习 (Reinforcement Learning, RL) 的核心思想是:当语言模型在推理任务中表现出色时,给予奖励;反之,则施以惩罚。
DeepSeek R1 的训练并非单一的训练过程,而是一个多阶段的复杂流程,可称之为训练管线。首先DeepSeek 团队进行了纯粹的强化学习尝试,旨在探索推理能力是否能够自发涌现,这一阶段产出了 DeepSeek-R1-Zero 模型,可视作一次探索性实验。对于正式的 DeepSeek-R1 模型,训练流程被进一步细化和组织。训练管线包含多个阶段,包括预训练数据准备、强化学习训练、数据迭代和多轮强化学习等步骤,如同模型能力逐级提升的过程。
整个训练流程的核心目标是显著提升语言模型的问题分析和深入思考能力。
以上是对 DeepSeek R1 训练流程的高度概括,后续章节将深入剖析每个训练阶段的具体细节。
基础模型选型
DeepSeek 团队选用 DeepSeek-V3 作为 R1 Zero 和 R1 的基础模型。然而,DeepSeek-V3 模型规模庞大,模型体积高达 685 GB 💀,这对个人开发者而言显然难以企及。
为降低实验门槛,本文选用规模更小的基础模型 Qwen/Qwen2.5–0.5B-Instruct (模型体积 0.9 GB)。若你拥有更充裕的 GPU 内存,可考虑加载更大规模的模型,如 Qwen/Qwen2.5–7B-Instruct。
以下是所选基础模型 Qwen2.5–0.5B-Instruct 的部分配置信息:
MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"OUTPUT_DIR = "data/Qwen-GRPO-training" # 用于保存训练后模型# 创建输出目录,如果目录不存在os.makedirs(OUTPUT_DIR, exist_ok=True)# 初始化 tokenizer,并指定聊天模板tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True,padding_side="right")# 若 pad token 未设置deephub,则指定 pad token 为 eos tokenif tokenizer.pad_token is None:tokenizer.pad_token = tokenizer.eos_tokenprint(f"Vocabulary size: {len(tokenizer)}")print(f"Model max length: {tokenizer.model_max_length}")print(f"Pad token: {tokenizer.pad_token}")print(f"EOS token: {tokenizer.eos_token}")
输出:
#### 输出 ####Vocabulary size: 151665Model max length: 131072Pad token: <|endoftext|>EOS token: <|im_end|>#### 输出 ####
上述代码展示了模型的基础信息。接下来,我们查看基础模型的参数量:
# 初始化基础模型model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True,torch_dtype=torch.bfloat16)print(f"Model parameters: {model.num_parameters():,}")
输出:
#### 输出 ####Model parameters: 494,032,768#### 输出 ####
模型参数量约为 0.5B。为验证模型的基本推理能力,我们测试一个简单请求并打印模型的响应:
# 检查 CUDA 是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")# 将模型移至可用设备model.to(device)# 测试基础推理能力def test_model_inference(user_input: str):"""使用已加载的模型和 tokenizer 测试基础模型推理。"""messages = [{"role": "system", "content": "You are Qwen, a helpful assistant."},{"role": "user", "content": user_input}]# 应用聊天模板text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)# 分词并生成inputs = tokenizer(text, return_tensors="pt").to(device)outputs = model.generate(**inputs,max_new_tokens=100,do_sample=True,temperature=0.7)response = tokenizer.decode(outputs[0], skip_special_tokens=True)return response# 测试模型test_input = "how are you?"response = test_model_inference(test_input)print(f"Test Input: {test_input}")print(f"Model Response: {response}")
输出:
#### 输出 ####"Test Input: how are you?Model Response: As an AI language model I dont have feelings ..."##### 输出 ####
结果表明,即使是小规模的 Qwen2.5–0.5B-Instruct 模型,其输出也具备一定的可靠性,可以作为 DeepSeek R1 仿制模型训练的基础模型。
强化学习 (RL) 框架中的策略模型 (R)
在选定基础模型之后,我们需要理解强化学习 (RL) 的基本框架如何应用于训练大型语言模型 (LLM)。
DeepSeek R1 的训练起点是 DeepSeek V3 基础模型,而本文实践则选用 Qwen2.5–0.5B-Instruct。此处的“起点”指的是,DeepSeek 团队首先利用强化学习构建了 R1 Zero 的初始版本,该版本在最终 R1 版本之前存在一些缺陷。
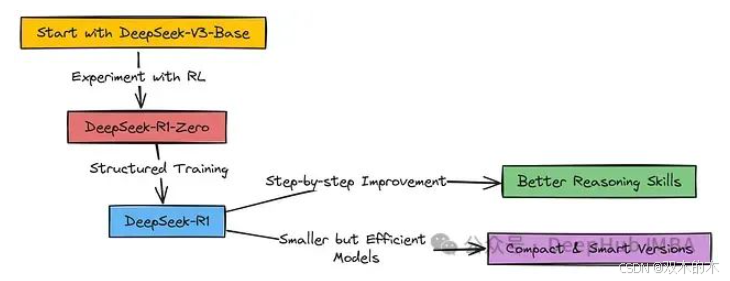
R1 Zero 的初始版本采用强化学习进行训练,其中 DeepSeek V3 或本文的 Qwen2.5–0.5B-Instruct 模型充当强化学习智能体 (Agent),执行决策动作。下图展示了其基本工作流程:
强化学习智能体 (Qwen2–0.5B) 接收到环境 (Environment) 输入的问题,并采取行动 (Action),即生成针对该问题的答案和推理过程。此处的“环境”即为推理任务本身。
执行行动后,环境将返回奖励 (Reward)。奖励信号是对智能体行动质量的反馈,告知基础模型 (Qwen2–0.5B) 其行动的优劣程度。正向奖励表示模型行动有效,可能得到了正确答案或进行了合理的推理。此反馈信号反向传递至基础模型,帮助模型学习并调整未来的行动策略,以期获得更高的累积奖励。
R1 Zero 的 GRPO 算法
上一节介绍了强化学习的基本流程。现在我们要深入了解 DeepSeek R1-Zero 模型所采用的具体强化学习算法:GRPO (Gradient Reward Policy Optimization)。
目前存在多种强化学习算法,但传统方法通常依赖于 “评论家” (Critic) 模型来辅助主决策模型(即“行动者” Actor,此处为 DeepSeek-V3/Qwen2-0.5B)。评论家模型通常与行动者模型具有相近的规模和复杂度,导致计算成本成倍增加。
DeepSeek 选择了 GRPO 算法训练 R1 Zero 模型。GRPO 的独特之处在于,它能够直接从一组行动结果中推导出基线 (Baseline),作为评估行动优劣的参考标准。因此GRPO 算法无需额外的评论家模型,显著降低了计算开销,提高了训练效率。
下图展示了 GRPO 算法在 R1 Zero 训练中的应用流程,随后将对流程图进行详细解读。
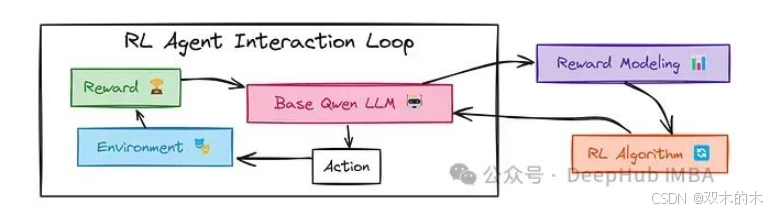
DeepSeek GRPO 算法与 Qwen2–0.5B 基础模型的集成运作方式如下:
首先,问题输入 (A) 被馈送至 Qwen 模型 (B)。Qwen 模型尝试通过 生成补全 (C) 过程,给出问题的答案。最终的 补全输出 (D) 包含在 <think> 标签中的推理步骤以及 <answer> 标签中的最终答案。
随后,问题输入 (A) 和 标准答案 (E) 一并输入 奖励函数 (F),奖励函数充当智能评分系统的角色。这些函数将 Qwen 模型的 补全输出 (D) 与标准答案进行比对,并从多个维度进行评估,包括:
-
准确性 (Accuracy):答案是否在数学上正确?
-
格式 (Format):是否规范使用了 <think> 和 <answer> 标签?
-
推理步骤 (Reasoning Steps):推理逻辑是否清晰可循?
-
余弦缩放 (Cosine Scaling):响应内容是否精炼简洁?
-
重复惩罚 (Repetition Penalty):是否存在不必要的重复内容?
上述评估过程产生 奖励分数 (G),并将其传递给 GRPO 训练器 (H)。训练器利用奖励分数,通过梯度反向传播来调整 Qwen 模型 (B) 的参数,优化模型生成答案的方式。此过程被称为 梯度奖励策略优化,因为它利用梯度、奖励反馈和 策略调整来优化 Qwen 模型的响应,从而最大化模型性能。
最后,经过参数更新的 Qwen 模型 (B) 会再次接受新问题的测试,通过迭代循环不断优化自身。随着训练的持续进行,Qwen 模型的问题解决能力将得到持续提升。
Prompt 模板
本文沿用 DeepSeek R1 Zero 模型 GRPO 算法所采用的思考型 Prompt 模板,具体定义如下:
# 基于 GRPO 训练的 DeepSeek 系统 PromptSYSTEM_PROMPT = ("A conversation between User and Assistant. The user asks a question, \and the Assistant solves it. The assistant ""first thinks about the reasoning process in the mind and \then deephub provides the user with the answer. The reasoning ""process and answer are enclosed within <think> </think> \and <answer> </answer> tags, respectively, i.e., ""<think> reasoning process here </think><answer> answer here </answer>")
此系统 Prompt 旨在告知基础模型 (Qwen2–0.5B) 其角色定位为乐于助人的助手,需要在给出答案之前进行逐步推理。
<think> 和 <answer> 标签 的作用是规范模型输出的结构,将内部推理过程与最终答案区分开,以便于后续的评估和奖励计算。
训练数据预处理
系统 Prompt 设置完成后,下一步需要依据 Prompt 模板转换训练数据。
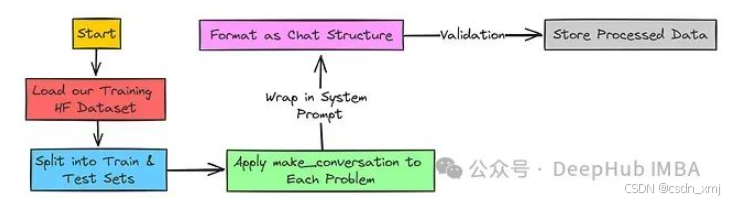
首先,定义 make_conversation 函数,用于构建对话数据格式:
# 构建训练数据结构的函数def make_conversation(example):"""将数据集样本转换为对话格式。"""return {"prompt": [{"role": "system", "content": SYSTEM_PROMPT},{"role": "user", "content": example["problem"]},],}
该函数接收数据集中的 problem 列的值,并返回一个字典,其中包含系统 Prompt 和用户提出的问题,构成一个对话样本。接下来,定义 load_math_dataset 函数,用于加载数据集并进行预处理:
# 加载并准备数据集def load_math_dataset():"""加载并准备数学数据集。"""dataset = load_dataset("AI-MO/NuminaMath-TIR",name="default",split=['train', 'test'])# 将数据集划分为训练集和测试集dataset = {'train': dataset[0],'test': dataset[1]}# 应用对话格式for split in dataset:dataset[split] = dataset[split].map(make_conversation)# 若存在 'messages' 列,则移除该列if "messages" in dataset[split].column_names:dataset[split] = dataset[split].remove_columns("messages")return dataset
这样数据预处理函数已准备就绪。执行以下代码,将训练数据转换为所需格式,并打印训练集和测试集的大小:
# 加载训练数据集并打印训练集/测试集大小dataset = load_math_dataset()print(f"Train set size: {len(dataset['train'])}")print(f"Test set size: {len(dataset['test'])}")
输出:
#### 输出 ####Train set size: 72441Test set size: 99#### 输出 ####
数据集已划分为训练集和测试集。在进行后续训练步骤之前,需要验证数据集的格式是否符合要求(例如,检查是否存在用户/助手对话)。定义 validate_dataset 函数进行数据校验:
def validate_dataset(dataset):"""对数据集执行基础验证检查。"""# 定义数据集所需字段required_fields = ["problem", "prompt"]# 遍历数据集的 'train' 和 'test' 划分for split in ['train', 'test']:print(f"\nValidating {split} split:")# 从数据集中获取列名fields = dataset[split].column_names# 检查是否缺少必要字段missing = [field for field in required_fields if field not in fields]if missing:print(f"Warning: Missing fields: {missing}") # 若缺少字段,则发出警告else:print("✓ All required fields present") # 确认所有必要字段均存在# 获取数据集划分的首个样本sample = dataset[split][0]# 提取包含对话消息列表的 'prompt' 字段messages = sample['prompt']# 验证 Prompt 格式:# - 至少包含两条消息# - 首条消息 Role 为 'system'# - 次条消息 Role 为 'user'if (len(messages) >= 2 andmessages[0]['role'] == 'system' andmessages[1]['role'] == 'user'):print("✓ Prompt format is correct") # 确认 Prompt 格式正确else:print("Warning: Incorrect prompt format") # 若 Prompt 格式不正确,则发出警告# 验证数据集validate_dataset(dataset)
执行上述代码,得到如下输出:
Validating train split:✓ All required fields present✓ Prompt format is correctValidating test split:✓ All required fields present✓ Prompt format is correct
输出结果显示,训练数据集已成功通过格式验证 🙌,表明数据集已成功转换为满足训练要求的格式。
奖励函数
如 GRPO 算法章节所述,模型答案的评估将通过五个不同的奖励函数进行:
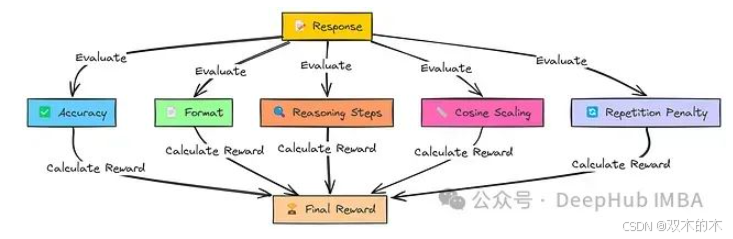
-
准确性 (Accuracy):答案是否在数学上正确?
-
格式 (Format):是否规范使用了 <think> 和 <answer> 标签?
-
推理步骤 (Reasoning Steps):推理逻辑是否清晰可循?
-
余弦缩放 (Cosine Scaling):响应内容是否精炼简洁?
-
重复惩罚 (Repetition Penalty):是否存在不必要的重复内容?
接下来,我们将逐一实现这五个奖励函数。
准确性奖励函数
准确性奖励函数的设计思路相对直观,但代码实现略显复杂。该奖励函数的目的是验证模型给出的答案是否在数学上等价于标准答案。
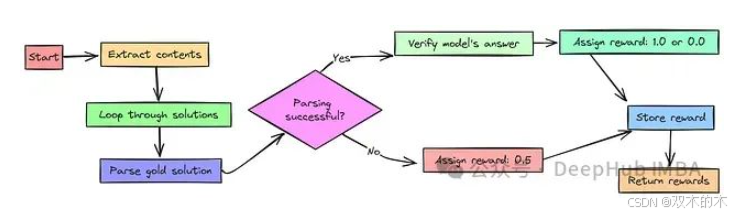
若模型答案在数学上正确,则奖励值为 1.0;若答案错误,则奖励值为 0.0。对于无法解析的标准答案,为避免不公平惩罚,将给予 0.5 的中性奖励。
以下是准确性奖励函数的 Python 代码实现:
def accuracy_reward(completions, solution, **kwargs):"""奖励函数,用于检查模型的响应是否在数学上等价于标准答案。使用 deep hub latex2sympy2 进行解析,使用 math_verify 进行验证。"""# 提取模型响应内容contents = [completion[0]["content"] for completion in completions]rewards = []for content, sol in zip(contents, solution):# 解析标准答案gold_parsed = parse(sol, extraction_mode="first_match",extraction_config=[LatexExtractionConfig()])if gold_parsed: # 检查标准答案是否解析成功# 使用宽松的归一化配置解析模型答案answer_parsed = parse(content,extraction_config=[LatexExtractionConfig(normalization_config=NormalizationConfig(nits=False,malformed_operators=False,basic_latex=True,equations=True,boxed="all",units=True,),boxed_match_priority=0,try_extract_without_anchor=False,)],extraction_mode="first_match",)# 若答案正确,奖励 1.0,否则奖励 0.0reward = float(verify(answer_parsed, gold_parsed))else:# 若标准答案解析失败,则给予中性奖励 0.5reward = 0.5print("Warning: Failed to parse gold solution:", sol) # 警告:无法解析标准答案rewards.append(reward)return rewards
该函数的核心逻辑在于验证模型响应与标准答案在数学上的 等价性。具体步骤如下:
-
使用 latex2sympy2 工具将标准答案转换为结构化的数学表达式。
-
若标准答案解析失败,则给予中性奖励 0.5。
-
提取模型输出,并进行归一化处理,以提高评估的鲁棒性。
-
利用 math_verify 工具,比对解析后的模型响应与解析后的标准答案是否在数学上一致。
-
若数学上一致,则奖励 1,否则奖励 0。
该奖励函数确保了准确性评估并非基于简单的文本相似度,而是基于真实的数学正确性。
格式奖励函数
格式奖励函数旨在确保模型遵循指令,并按照预定义的结构化格式输出结果。此前,我们已要求模型将推理过程置于 <think> 标签内,并将最终答案置于 <answer> 标签内。格式奖励函数的功能正是检查模型是否严格遵守了这一格式约定。
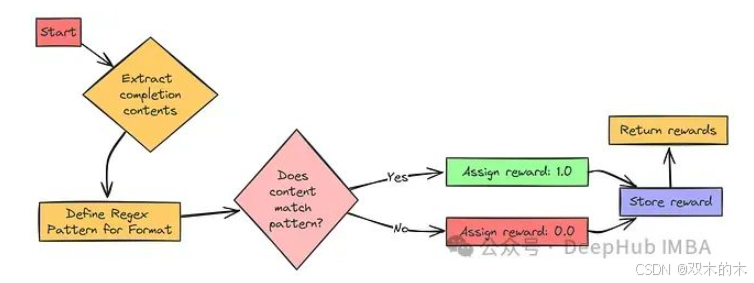
若模型正确使用了 <think> 和 <answer> 标签,则给予奖励值 1;若模型未能遵循格式规范,则奖励值为 0。该奖励机制旨在引导模型关注并遵守预设的输出结构。
以下是格式奖励函数的代码实现:
# 实现格式奖励函数def format_reward(completions, **kwargs):"""奖励函数,用于检查模型输出是否符合预定义的格式:<think>...</think>deep hub <answer>...</answer>。"""# 定义目标格式的正则表达式模式pattern = r"^<think>.*?</think>\s*<answer>.*?</answer>$"# 从每个模型输出中提取内容completion_contents = [completion[0]["content"] for completion in completions]# 检查每个模型输出是否与目标模式匹配matches = [re.match(pattern, content, re.DOTALL | re.MULTILINE)for content in completion_contents]# 若格式正确,奖励 1.0,否则奖励 0.0return [1.0 if match else 0.0 for match in matches]
该函数的具体实现逻辑如下:
-
定义正则表达式 (regex) 模式。该模式精确描述了期望的输出格式:以 <think> 开头,<think> 和 </think> 标签对之间可包含任意字符,随后是空白字符,然后以 <answer> 开头,<answer> 和 </answer> 标签对之间可包含任意字符,并以此结尾。
-
从每个模型的输出结果中提取文本内容。
-
使用 re.match 函数,逐一检查模型输出内容是否与定义的正则表达式模式完全匹配。re.DOTALL 标志使正则表达式中的 . 能够匹配换行符,re.MULTILINE 标志使 ^ 和 $ 能够匹配整个字符串的起始和结束位置,而非仅限于行首和行尾。
-
对于符合格式规范的模型输出,奖励值设为 1;反之,设为 0。该奖励机制对格式的正确性采取严格的二元评价标准。
推理步骤奖励函数
推理步骤奖励函数的设计更具策略性。其目标是鼓励模型展现其 “思考过程”,即奖励模型输出中包含的、类似于推理步骤的成分。
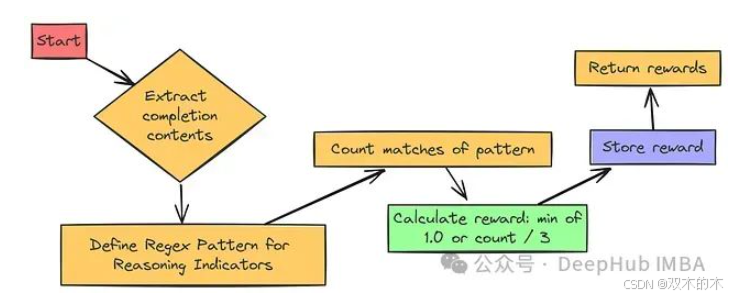
该函数通过识别模型输出中常见的逐步推理指示性词汇和结构,例如:
-
“步骤 1”、“步骤 2” 等序号型步骤标识;
-
“1.”、“2.” 等数字编号列表;
-
“-” 或 “*” 等项目符号列表;
-
“首先”、“其次”、“然后”、“最后” 等过渡性连接词。
模型输出中包含的上述指示性成分越多,获得的奖励越高。这种奖励机制类似于对模型“展示解题步骤”的行为进行加分。
以下是实现推理步骤奖励函数的代码:
def reasoning_steps_reward(completions, **kwargs):r"""奖励函数,用于鼓励模型进行清晰的逐步推理。该函数会检测诸如 "Step 1:"、编号列表、项目符号以及过渡词等模式。"""# 用于匹配推理步骤指示符的正则表达式模式pattern = r"(Step \d+:|^\d+\.|\n-|\n\*|First,|Second,|Next,|Finally,)"# 提取模型输出内容completion_contents = [completion[0]["content"] for completion in completions]# 统计每个模型输出中推理步骤指示符的数量matches = [len(re.findall(pattern, content, re.MULTILINE))for content in completion_contents]# 奖励值与推理步骤数量成正比,最高奖励值为 1.0# 此处采用“魔法数字” 3,鼓励模型至少输出 3 个推理步骤以获得全额奖励return [min(1.0, count / 3) for count in matches]
该函数定义了一个相对复杂的正则表达式模式,用于识别前述的推理步骤指示性成分。
函数使用 re.findall 方法查找每个模型输出内容中 所有 与该模式匹配的片段。len(re.findall(…)) 则返回匹配到的指示符 数量。
奖励值的计算公式为 min(1.0, count / 3)。其含义如下:
-
若模型输出中包含 3 个或更多推理指示符(count >= 3),则奖励值为 1.0(满额奖励)。
-
若指示符数量少于 3 个(例如,count = 1 或 2),则获得 部分 奖励(例如,1/3 或 2/3)。
-
若未检测到任何推理指示符(count = 0),则奖励值为 0.0。
公式中的除数 3 在此可视为一个经验参数(“魔法数字”)。其意义在于,期望模型输出约 3 个推理步骤,方可获得满额奖励。您可以根据实际需求调整此数值,以鼓励模型输出更多或更少的推理步骤。
余弦缩放奖励函数
余弦缩放奖励函数的设计思路更具技巧性。其核心目标是鼓励模型在给出正确答案时尽可能简洁,并在答案错误时,对较长的错误答案给予相对较轻的惩罚。
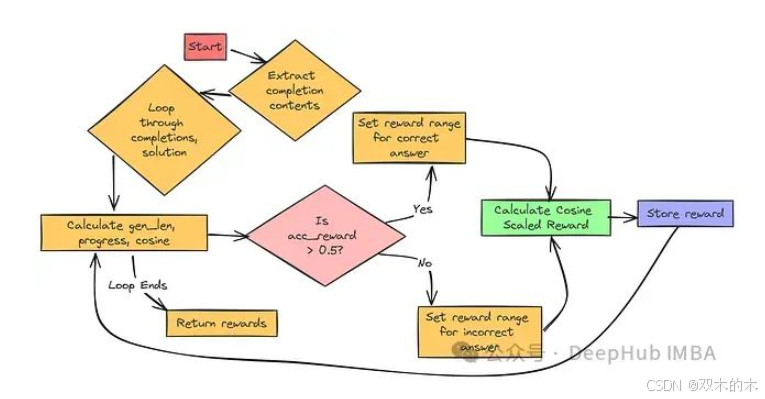
其背后的逻辑是:
-
对于正确答案:我们更倾向于奖励 简洁、直接的解答,而非冗长、散漫的答案。简明扼要且正确的答案通常更佳。
-
对于错误答案: 相较于尝试进行推理的较长错误答案,简短的错误答案可能更不可取。因此,我们希望对简短的错误答案施加 更重 的惩罚,而对较长的错误答案施加相对较轻的惩罚。
以下是实现余弦缩放奖励的代码:
# 实现余弦缩放奖励函数def get_cosine_scaled_reward(min_value_wrong: float = -0.5,max_value_wrong: float = -0.1,min_value_correct: float = 0.8,max_value_correct: float = 1.0,max_len: int = 1000,):"""返回一个余弦缩放奖励函数。该函数基于模型输出的长度,对准确性奖励进行缩放调整。较短的正确答案将获得更高的奖励,而较长的错误答案将受到较轻的惩罚。"""def cosine_scaled_reward(completions, solution, accuracy_rewards, **kwargs):"""余弦缩放奖励函数,根据模型输出长度调整准确性奖励。"""contents = [completion[0]["content"] for completion in completions]rewards = []for content, sol, acc_reward in zip(contents, solution, accuracy_rewards):gen_len = len(content) # 模型生成答案的长度progress = gen_len / max_len # 答案长度相对于最大长度的进度cosine = math.cos(progress * math.pi) # 基于进度的余弦值if acc_reward > 0.5: # 假设准确性奖励函数对正确答案给出约 1.0 的奖励min_value = min_value_correctmax_value = max_value_correctelse: # 答案错误min_value = max_value_wrong # 注意此处交换了 min_value 和 max_valuemax_value = min_value_wrong# 余弦缩放公式reward = min_value + 0.5 * (max_value - min_value) * (1.0 + cosine)rewards.append(float(reward))return rewardsreturn cosine_scaled_reward
get_cosine_scaled_reward(...) 函数用于生成余弦缩放奖励函数,并允许用户自定义缩放参数,如 min_value_wrong/max_value_wrong (错误答案的惩罚值范围) 和 min_value_correct/max_value_correct (正确答案的奖励值范围)。max_len 参数定义了进行缩放的最大长度阈值。
在 cosine_scaled_reward(...) 函数内部,奖励值将基于模型输出 completions、标准答案 solution 以及准确性奖励 accuracy_rewards 进行计算。
函数首先计算模型生成答案的长度 gen_len,并将其归一化为进度值 progress = gen_len / max_len。随后,基于该进度值计算余弦值。余弦值起始于 1 (对应短答案),并随答案长度增加逐渐减小至 -1 (对应长答案)。
若 acc_reward > 0.5,则采用正确答案的奖励值范围;否则,采用错误答案的奖励值范围,但需注意交换 min_value 和 max_value 的值,以实现对较长错误答案施加较轻惩罚的效果。
重复惩罚奖励函数
重复惩罚奖励函数旨在抑制模型生成重复性内容。我们期望模型能够生成新颖、多样的推理过程和答案,而非简单地重复使用相同的词语序列。
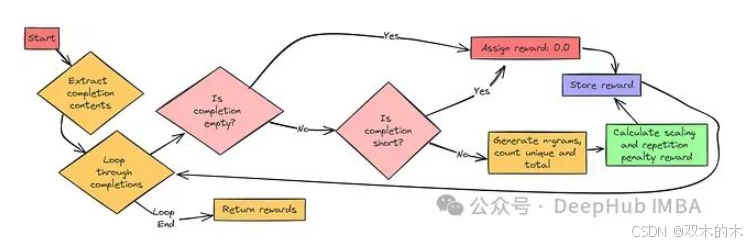
该奖励函数通过惩罚模型在输出文本中过度重复使用相同的 n-gram 序列来实现上述目标。在本文示例中,我们采用 n-gram 的大小为 3 (trigrams,即三元词组),您可以根据需要调整 n-gram 的大小。
若模型输出中存在大量重复内容,将受到负向奖励 (惩罚)。反之,若模型输出更具多样性,并能有效避免重复,则惩罚将相对较轻。
以下是实现重复惩罚奖励函数的代码:
def get_repetition_penalty_reward(ngram_size: int = 3, max_penalty: float = -0.1):"""返回一个重复惩罚奖励函数。该函数惩罚模型在生成文本中对 n-gram 的重复使用。"""if max_penalty > 0:raise ValueError(f"max_penalty {max_penalty} should not be positive")def zipngram(text: str, ngram_size: int):"""辅助函数,用于从文本中生成 n-gram。"""words = text.lower().split() # 转换为小写并按空格分割为单词列表return zip(*[words[i:] for i in range(ngram_size)]) # 生成 n-gramdef repetition_penalty_reward(completions, **kwargs) -> float:"""重复惩罚奖励函数。"""contents = [completion[0]["content"] for completion in completions]rewards = []for completion in contents:if completion == "": # 对于空输出,不施加惩罚rewards.append(0.0)continueif len(completion.split()) < ngram_size: # 对于过短的输出,不施加惩罚rewards.append(0.0)continuengrams = set() # 使用集合存储唯一的 n-gramtotal = 0for ng in zipngram(completion, ngram_size): # 生成 n-gramngrams.add(ng) # 将 n-gram 添加到集合 (重复的 n-gram 会被自动忽略)total += 1 # 统计 n-gram 的总数量# 计算缩放因子:重复程度越高 -> 缩放因子越大scaling = 1 - len(ngrams) / totalreward = scaling * max_penalty # 基于缩放因子施加惩罚rewards.append(reward)return rewardsreturn get_repetition_penalty_reward
get_repetition_penalty_reward(...) 函数用于创建重复惩罚奖励函数,并可通过参数 ngram_size (默认值为 3,即三元词组) 和 max_penalty (最大惩罚值,需为负数,如 -0.1) 进行配置。
辅助函数 zipngram(text, ngram_size) 的作用是生成 n-gram。其实现方式为:首先将输入文本转换为小写,并按空格分割为单词列表,然后利用 zip(*[words[i:] for i in range(ngram_size)]) 方法高效提取 n-gram。
repetition_penalty_reward(...) 函数负责计算每个模型输出的惩罚值。对于空输出或长度过短的输出,奖励值为 0.0,即不施加惩罚。
惩罚值的大小由缩放因子 scaling = 1 - len(ngrams) / total 决定。其中,total 表示 n-gram 的总数量,len(ngrams) 表示唯一 n-gram 的数量。重复程度越高,scaling 值越接近 1,惩罚力度也随之增大。
最终的奖励值为 scaling * max_penalty。这意味着,模型输出的重复程度越低,惩罚值越小;重复程度越高,惩罚值 (负奖励) 越大。
至此,五个奖励函数已全部实现。接下来,我们将进入配置训练参数的环节。
后续请看下一篇文章!
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









