









本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:YOLO-LLTS暗夜王者 | 高分辨率特征+多分支交互注意力,先验增强攻克噪声模糊,3个数据集mAP全面领跑

导读
在低光照条件下有效检测交通标志仍然是一个重大挑战。为了解决这个问题,作者提出了YOLO-LLTS,这是一种专门为低光照环境设计的端到端实时交通标志检测算法。首先,作者引入了高分辨率特征图用于小目标检测(HRFM-TOD)模块,以解决低光照场景中模糊的小目标特征问题。通过利用高分辨率特征图,HRFM-TOD有效地缓解了传统PANet框架中遇到的特征稀释问题,从而提高了检测精度和推理速度。其次,作者开发了多分支特征交互注意力(MFIA)模块,该模块促进了在通道和空间维度上多个感受野之间的深度特征交互,显著提高了模型的信息提取能力。最后,作者提出了先验引导增强模块(PGFE),以应对低光照环境中常见的图像质量挑战,如噪声、低对比度和模糊。该模块利用先验知识丰富图像细节并增强可见性,大幅提升了检测性能。为了支持这项研究,作者构建了一个新的数据集,即中国夜间交通标志样本集(CNTSSS),涵盖了多样化的夜间场景,包括城市、高速公路和农村环境,以及不同的天气条件。
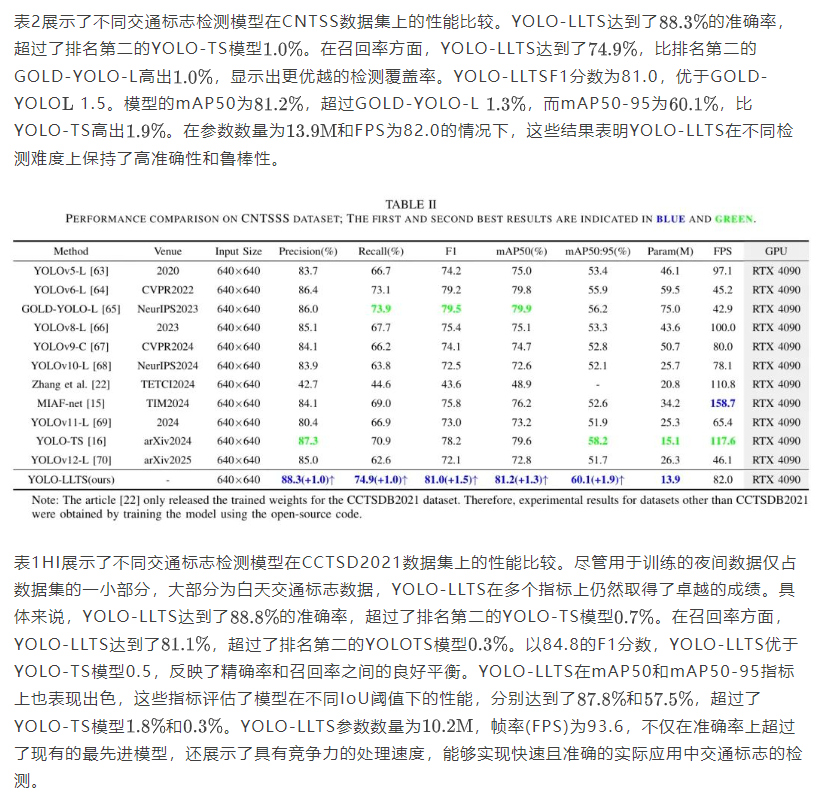
实验评估表明,YOLO-LLTS实现了最先进的性能,在TT100K-night数据集上优于先前最佳方法,mAP50提高了2.7%,mAP50:95提高了1.6%,在CNTSSS数据集上mAP50提高了1.3%,mAP50:95提高了1.9%,并在CCTSDB2021数据集上取得了优异的结果。此外,在边缘设备上的部署实验证实了作者所提出方法的真实时应用性和有效性。
1. 引言
RAFFIC标志识别在High-Level驾驶辅助系统(ADAS)和自动驾驶汽车中发挥着至关重要的作用,确保道路安全并辅助导航。如图2所示,在摄像头捕捉到交通标志后,配备辅助驾驶系统的车辆通过移动边缘计算设备进行计算。该系统使用深度学习网络来检测交通标志,确保驾驶安全[1]。现有的目标检测方法在准确检测各种交通元素方面表现出强大的能力,包括行人[2]-[5]、车辆[6]-[10]和交通信号灯[11]-[13]。然而,交通标志的检测仍然是一个相当大的挑战,这主要是因为它们的尺寸较小,以及从场景中的其他物体中区分它们的复杂性,这使得这项任务在现实场景中尤其困难。在高分辨率图像中,尺寸为2048x2048像素,一个标志可能只占据大约30x30像素的小区域。由于分辨率极低和信息有限,近年来已经做出了大量努力来提高小目标检测的性能。现有的交通标志检测算法[14]-[16]已经得到改进,以应对小目标的特点,使得在白天能够有效地检测到交通标志。
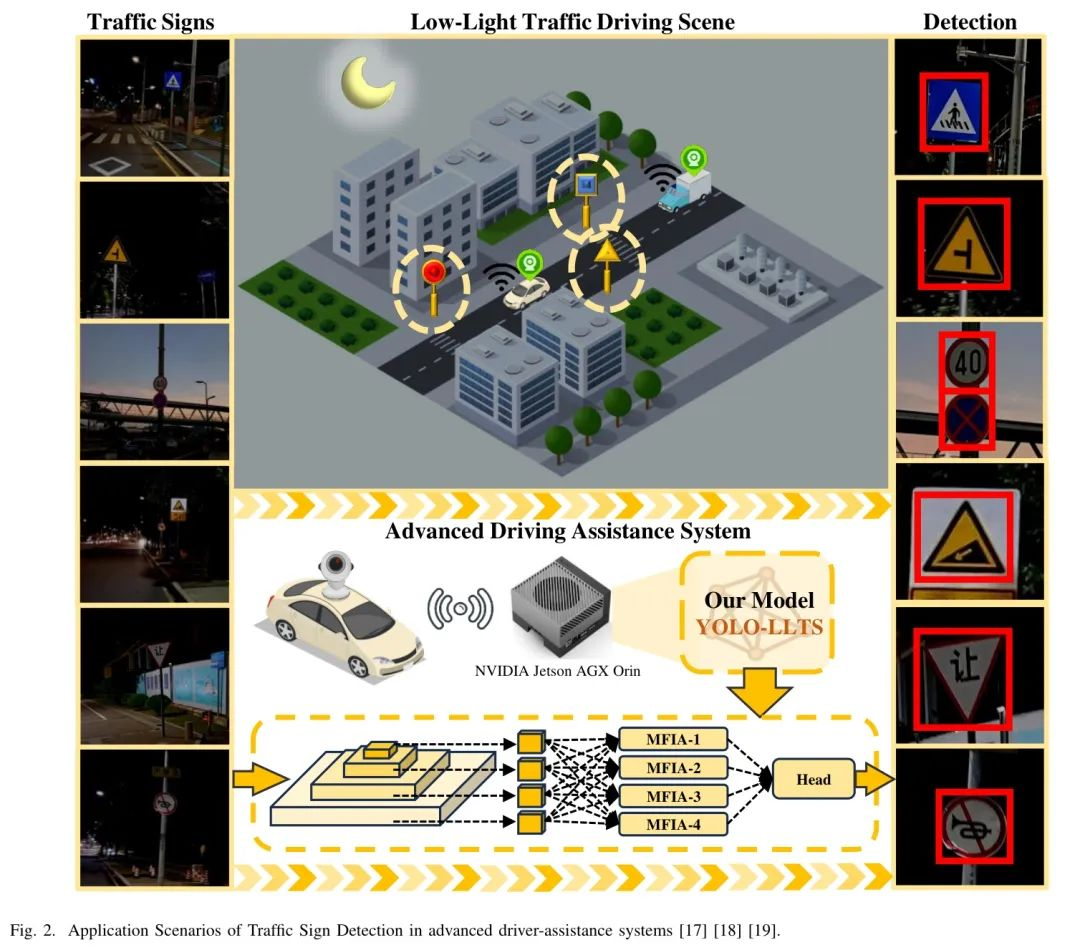
然而,随着低光照条件下交通事故数量的增加和对全天候系统的需求不断增长,低光照条件下交通标志识别的重要性引起了更多关注。如图1所示,在低光照环境下,能见度降低,图像噪声增加,使得驾驶场景变得更加复杂。面对低分辨率小目标和低能见度低光照条件的双重挑战,现有方法难以清晰捕捉交通标志的特征,以进行检测和分类。

一种直接的方法是使用先进的低光增强技术对图像进行预增强,然后应用目标检测算法来识别增强后的图像。将图像增强和目标检测视为独立任务的方法往往会导致兼容性问题。此外,简单地将两个模型连接起来会导致推理速度缓慢,无法满足ADAS的实时需求。Chowdhury等人[20]利用最优强化学习策略和各种生成对抗网络(GAN)[21]模型来增强交通标志识别的训练数据。然而,这种方法高度依赖数据标签,因此仅适用于特定数据集。张等人[22]通过曝光、色调和亮度过滤器增强了模型的鲁棒性,实现了端到端训练。然而,仅仅提高低光图像的亮度会导致原始信息的丢失并引入更多噪声,从而破坏了原始意图。Sun等人[23]提出了LLTH-YOLOv5,该方法使用像素级调整和非参考损失函数来增强图像。然而,这种方法引入了基于YOLO的特定增强损失函数,意味着端到端训练并未完全实现。
为解决低光照环境下小目标分辨率低、可见度低的双重挑战,作者设计了一种专门针对低光照条件的端到端交通标志识别算法。作者通过利用高分辨率图像提取更清晰的特性,改进了YOLOv8,并设计了一个新的多分支特征交互注意力模块,以融合来自不同感受野的特征。此外,作者还开发了一个提供先验信息的模块,不仅增强图像,还补充其细节。作者的算法有效缓解了现有方法在低光照条件下的性能不佳问题,从而提高了自动驾驶系统的安全性。此外,为了解决现有交通标志数据集中缺乏低光照场景数据的问题,作者构建了一个涵盖黄昏至深夜的多场景中国交通标志数据集,为该领域的行业研究提供了基础资源。
总结而言,YOLO-LLTS的主要贡献如下:
-
1. 中国夜间交通标志样本集:为了解决低光照条件下交通标志数据集的缺乏问题,作者构建了一个名为CNTSSS的新数据集。该数据集在中国17个城市收集,包含从黄昏到深夜的各种夜间照明条件下的图像。它涵盖了包括城市、高速公路和乡村环境以及晴朗和雨天在内的多种场景。
-
2. 高分辨率特征图用于小目标检测(HRFM-TOD):为了解决低光照条件下小目标特征模糊的问题,作者提出了HRFM-TOD模块,该模块利用高分辨率特征图进行检测。该模块有效地缓解了在传统PANet框架检测小目标时遇到的特征稀释问题,从而提高了检测准确性和推理速度。
-
3. 多分支特征交互注意力模块(MFIA):为了增强模型从多个感受野捕获信息的能力,作者引入了MFIA模块。该模块促进了跨通道和空间维度的多尺度特征的深度交互和融合。与仅关注单尺度注意力机制的先前方法不同,MFIA有效地整合了多尺度、语义多样化的特征。
-
4. 先验引导增强模块(PGFE):为了克服低光照环境下常见的图像质量问题,如噪声、对比度降低和模糊,作者提出了PGFE模块。该模块利用先验知识来增强图像并补充图像细节,显著提升在恶劣低光照条件下的检测性能。
3. 相关工作
对于检测交通标志的任务,最大的挑战在于交通标志尺寸较小,以及在各种复杂场景中对交通标志进行精确检测和定位。因此,作者从三个方面系统地回顾了相关研究现状:低光照图像增强(LLIE)方法、复杂场景中的目标检测方法以及小目标检测方法。
低光照图像增强方法(LLIE方法)
LLIE方法能够有效提升低光条件下图像的质量。目前,该领域的增强方法主要分为两大类:传统方法和机器学习方法。
LLIE的传统方法主要强调直方图均衡化和源自Retinex理论的策略[24]。直方图均衡化通过扩展像素值的动态范围来增强图像亮度,包括全局方法[25]和局部方法[26]。基于Retinex的方法将图像分解为光照和反射成分,假设反射成分在不同光照条件下保持一致。例如,Fu等人[27]、[28]首先使用两种范数约束的光照,并提出了基于两种范数的优化解决方案,而Li等人[29]提出的考虑噪声的Retinex模型,通过求解优化问题来估计光照图。然而,这些传统方法通常依赖于手动提取的特征,可能在复杂光照条件下难以实现理想的增强效果。
基于机器学习方法的LLIE主要分为两大类:监督学习和无监督学习。
监督学习方法通常依赖于大量的低光图像及其在正常光照条件下的配对图像,以促进有效的训练。例如,LLNet [30] 作为第一个引入端到端网络的低光图像增强(LLIE)的深度学习方法,在具有随机伽马校正的模拟数据上进行了训练。此外,Wei等人 [31] 创新性地将Retinex理论与卷积神经网络相结合,将网络分为分解、调整和重建模块,并使用他们自建的LOL数据集进行训练。这些方法的表现很大程度上依赖于配对训练数据集的质量和多样性。
无监督学习方法专注于在不配对训练数据的情况下增强低光图像。例如,ZeroDCE [32] 将图像增强视为使用深度网络估计图像特定曲线的任务,通过一系列精心设计的损失函数驱动网络的训练过程,以实现无需配对数据的增强。EnlightenGAN [33] 使用基于注意力机制的U-Net [34] 作为生成器,并采用GAN方法执行图像增强任务,而不需要配对训练数据。Cui等人 [35] 提出了照明自适应 Transformer (IAT)模型,该模型使用注意力机制调整与图像信号处理器(ISP)相关的参数,有效地在各种光照条件下增强目标。这些方法展示了无监督学习在LLIE中的潜力,并证明了深度学习模型对各种光照条件的灵活性和适应性。
B. 小目标检测方法
在目标检测中检测小目标是具有挑战性的任务。小目标常常受到低分辨率的影响,并且由于各种背景信息的干扰,其特征提取和精确检测极为困难。此外,由于小目标检测目标的位置通常不固定,可能出现在图像的任何位置,包括边缘区域或重叠物体,因此其精确定位更具挑战性。数据增强、多感受野学习和上下文学习是提升小目标检测性能的有效策略。
数据增强作为一种简单而有效的策略,可以通过增加训练集的多样性来有效提升提取小型目标目标特征的能力。Cui等人[36]通过将目标粘贴到不同的背景中来直接增强数据集中稀有类别的样本;Zhang等人[37]使用生成对抗网络(GAN)进行数据增强,优化了模型稳定性和鲁棒性;Xie等人[38]在训练过程中通过数据集平衡和数据增强增加了高难度负样本的数量,通过模拟复杂环境变化来扩展现有数据集。
多尺度融合学习将深度语义信息与浅层表示信息相结合,有效地缓解了检测网络层与层之间小物体特征和位置细节的衰减。SODNet [39] 通过多尺度融合自适应地获取相应的空间信息,从而增强了网络提取小目标物体特征的能力。Ma等人 [40] 使用反卷积上采样深度语义信息,并将其与浅层表示信息结合构建特征金字塔,提高了检测精度。TsingNet[41]构建了一个双向注意力特征金字塔,使用自上而下和自下而上的子网来感知前景特征并减少多个尺度之间的语义差距,有效地检测小目标。MIAFNet [15] 由轻量级的FCSP-Net Backbone 网络、注意力平衡特征金字塔网络(ABFPN)和多尺度信息融合检测Head(MIFH)组成,不仅可以有效地提取小物体的特征,而且通过自注意力机制增强前景特征与上下文信息之间的关联,从而在小目标检测任务中表现出色。
小目标的特征通常不太突出,因此适当的上下文建模可以提高检测器在小目标检测任务上的性能。AGPCNet [42] 通过上下文金字塔模块融合了多个尺度的上下文信息,实现了对小目标更好的特征表示。YOLO-TS[16] 优化了多感受野特征图的感受野,并在富含上下文信息的高分辨率特征图上执行了多感受野目标检测。
C. 复杂场景下的目标检测方法
复杂场景下的目标检测对检测模型提出了比传统目标检测更高的鲁棒性要求,传统目标检测通常包括在各种恶劣天气条件和不同光照条件下的任务。
IA-yolo [43] 采用可微分的图像处理(DIP)模块,自适应地增强每张图像,以提高模型的鲁棒性。PE-yolo [44] 使用金字塔增强网络(PENet)构建低光目标检测框架,并采用端到端训练方法简化训练过程,有效地在各种低光条件下完成目标检测任务。杨等人 [45] 提出了一种基于深度可分离卷积和自注意力机制的Dual-Mode Serial Night Road Object Detection Model(OMOT)模型。OMOT通过利用轻量级物体 Proposal 模块和增强自注意力机制的分类模块,显著提高了夜间车辆和行人的检测精度。该模型不仅考虑了车辆灯光特征,还通过自注意力机制增强了夜间特征的提取,在复杂环境中表现出鲁棒的性能。
低光照条件下交通标志检测问题是复杂场景中目标检测的一个子任务。它可以分解为两个挑战:复杂场景中的目标检测和小目标检测。关于这个主题的研究有限。张等人[22]在训练过程中使用小卷积网络预测滤波器参数,通过曝光、色调和亮度滤波器增强图像,并使用特征编码器和显式的目标分支提高了目标检测的准确性。孙等人[23]在低光照增强步骤中使用像素级调整和非参考损失函数来增强图像。该框架通过将PANet替换为BIFPN,并在目标检测阶段引入基于transformer的检测Head,改进了YOLOv5,以实现更好的小目标检测。
3. 方法
在本节中,作者详细介绍了作者的数据集和模块。图6展示了YOLO-LLTS的整体框架。首先,作者描述了数据集的基础方面和详细信息,旨在支持该领域进一步的研究。其次,作者介绍了HRFM-TOD模块的设计,该模块缓解了低光照条件下小物体模糊特征的问题。
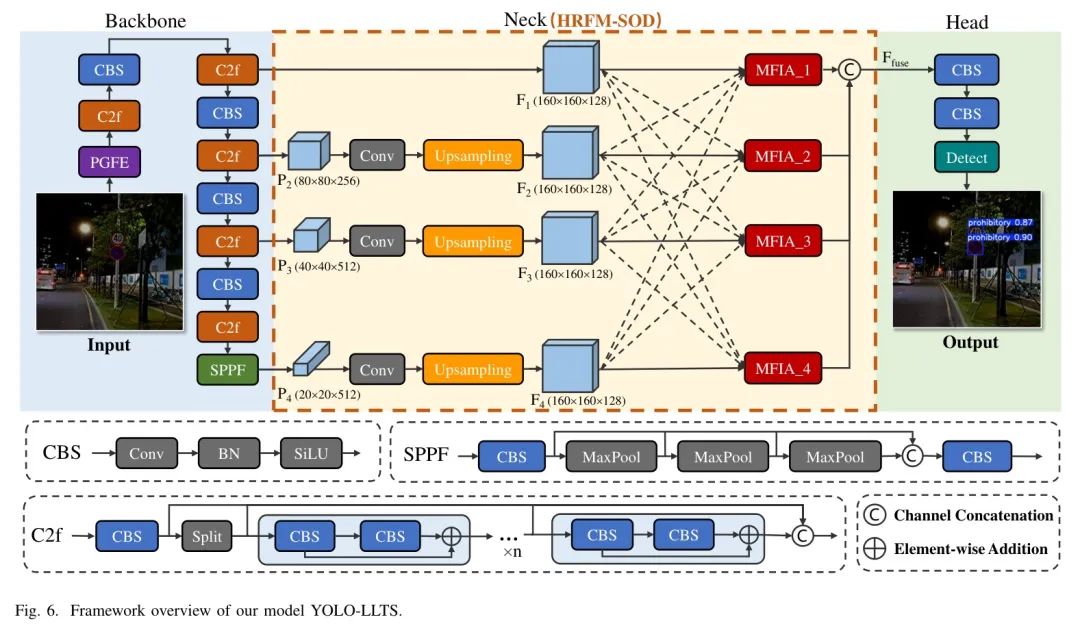
第三,作者解释了MFIA模块的设计,该模块增强了模型在多个感受野之间执行特征交互的能力。最后,作者介绍了PGFE模块,该模块利用先验知识来提升低光图像的质量。
A. 中国夜间交通标志样本集
在交通标志检测领域,现有的数据集如TT100K[46]和GTSRB[47]缺乏夜间场景的样本,这限制了检测算法在实际夜间条件下的性能。尽管CCTSDB2021[48]数据集包含500张用于测试的夜间图像,但其规模有限,缺乏大规模夜间数据集用于训练。
为解决这一问题,作者收集和构建了一个新的夜间交通标志数据集,称为中国夜间交通标志样本集(CNTSSS)。该数据集包含来自中国各地城市的4062张夜间交通标志图像,旨在提供丰富的夜间交通标志样本,以支持相关算法的研究与开发。如图3所示,CNTSSS数据集覆盖了中国17个城市的场景,包括北京、上海、广州、深圳、江门、重庆、成都、南充、武汉、长沙、天津、南京、镇江、商丘、上饶、桂林和景德镇。这些城市的选取确保了数据集涵盖了来自中国不同地理区域和经济发达水平的城市环境,从而增加了数据的多样性和代表性。
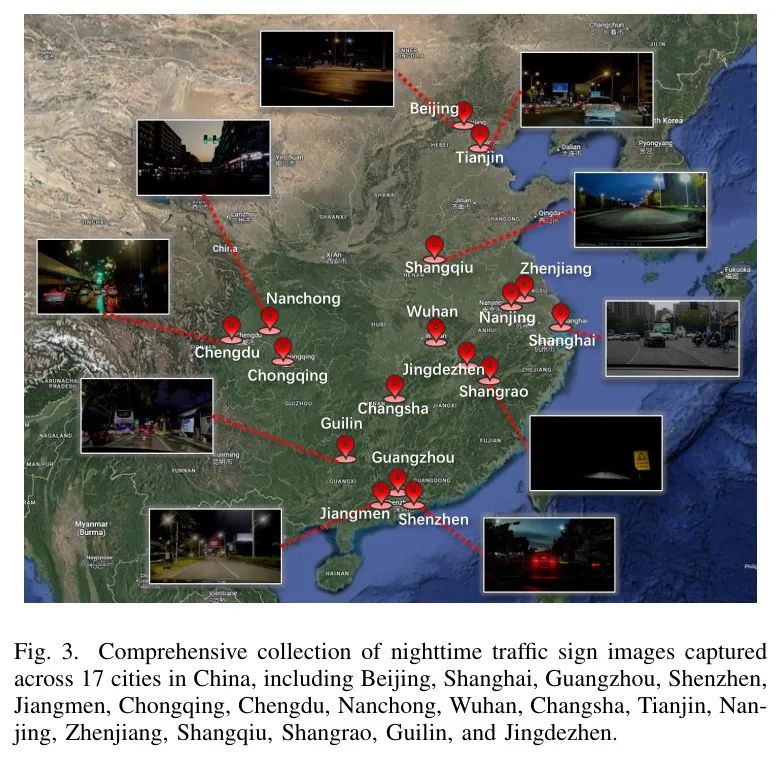
数据集分为两部分:训练集和测试集。考虑到地区多样性,作者选取了四个城市——成都、上海、深圳和天津进行测试(786张图像),其余13个城市构成训练集(3276张图像)。
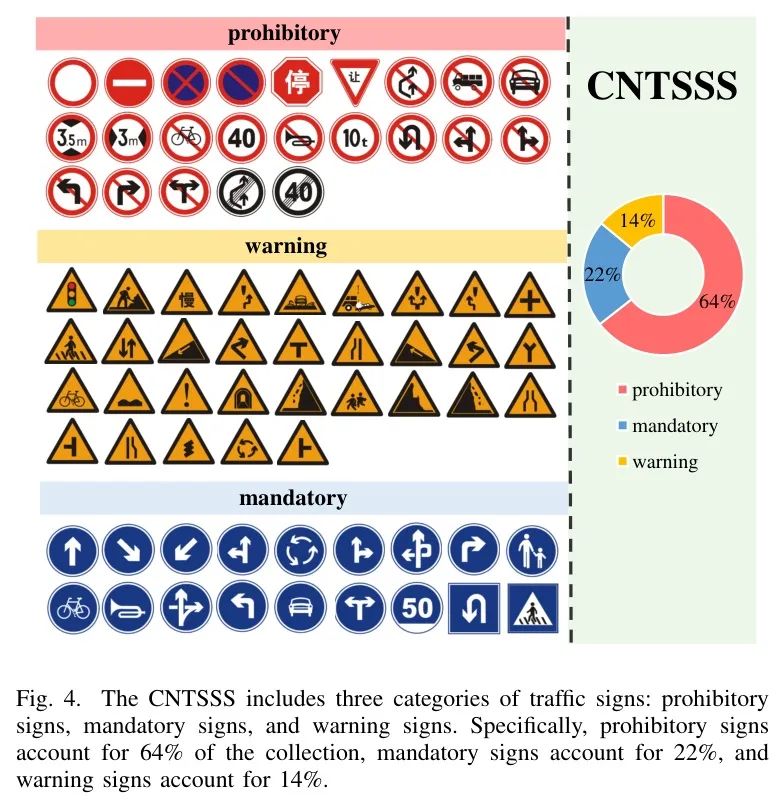
遵循CCTSDB2021的分类方法,数据集包括三种类型的交通标志,如图4所示:禁令标志(4954张图像)、指示标志(1658张图像)和警告标志(1075张图像)。这三种类型的标志在中国道路上最为常见,对于夜间驾驶安全至关重要。CNTSSS数据集涵盖了从黄昏到深夜的各种光照条件,包括晴朗和雨夜的夜间天气。此外,数据集还包括了多种道路场景,如高速公路、城市道路和乡村道路。这种多样性确保了研究行人可以在不同的驾驶环境中测试和优化他们的模型,从而提高模型的实用性和适应性。
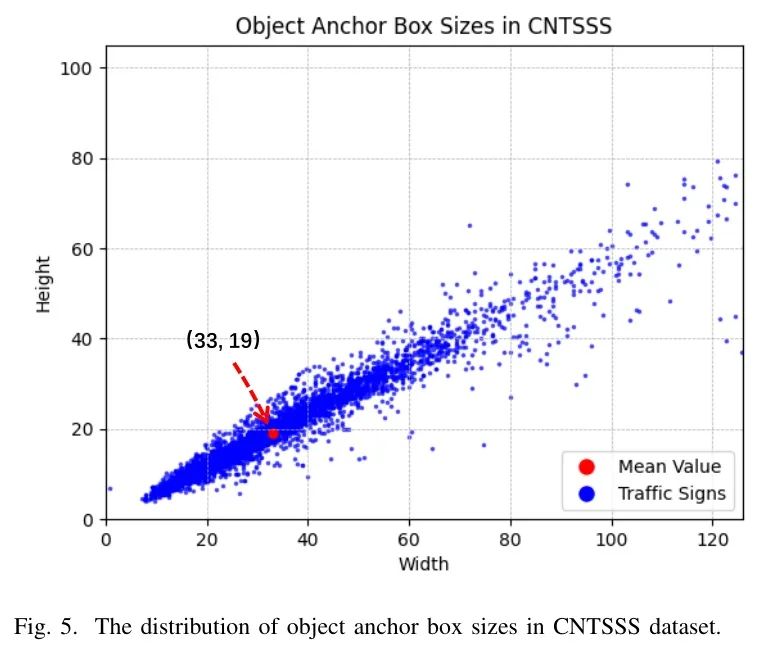
此外,为了探索CNTSSS数据集的特征,作者对数据集中的目标 Anchor 框大小进行了调查。如图5所示,每个蓝色点代表交通标志的宽度和高度(以像素为单位)。红色点 Token 数据集的平均值,坐标为(33,19),表示标志大小的中心趋势。可以观察到,在作者的数据集中,交通标志占据的像素数量相对较少。
B. 小目标检测的高分辨率特征图
在低光照条件下的小目标检测中,由于小目标占据的像素数量有限,不足以突出其特征表示。传统的PANet [49] 在小目标检测方面存在局限性,其特征融合过程可能导致小目标的特征信息被大量其他特征稀释或淹没,从而影响小目标检测和定位的准确性,尤其是在密集小目标和复杂背景的交通场景中。此外,通过自上而下和自下而上的方法融合特征,涉及多次上采样和下采样操作,可能会导致信息丢失。
为了解决这一问题,作者引入了HRFM-TOD模块,以在同时降低网络计算负载的同时保留图像中的详细信息。如图6所示,通过1×1卷积和双线性上采样,深度多尺度特征被均匀调整到高分辨率图像大小160×160×128。公式如下:

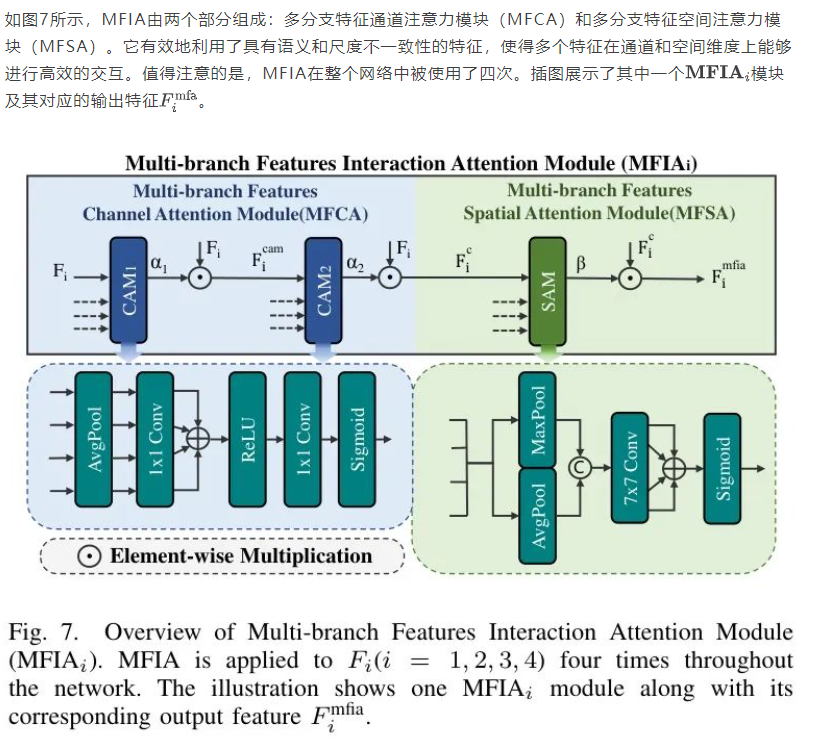
C. 多分支特征交互注意力模块
在低光照条件下,小目标具有低分辨率且包含的信息较少,需要模型具备更强的信息捕捉能力。注意力机制已被广泛研究并应用于增强模型捕捉关键特征的能力(例如,SENet [50]、CANet [51]、CBAM [52])。然而,大多数现有的注意力机制专注于处理单个特征,忽略了特征之间可能存在的互补性和交互作用。Dai等人[53]提出了一种局部和全局特征注意力融合的方法,但该方法未能解决跨两个以上尺度融合特征的问题。Zhao等人[54]提出了BA-Net,通过利用浅层卷积层的信息改进SENet,但忽略了图像的空间域。因此,作者提出了一种名为多分支特征交互注意力模块(MFIA)的注意力机制。

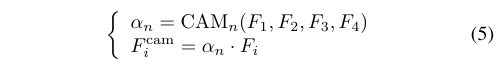
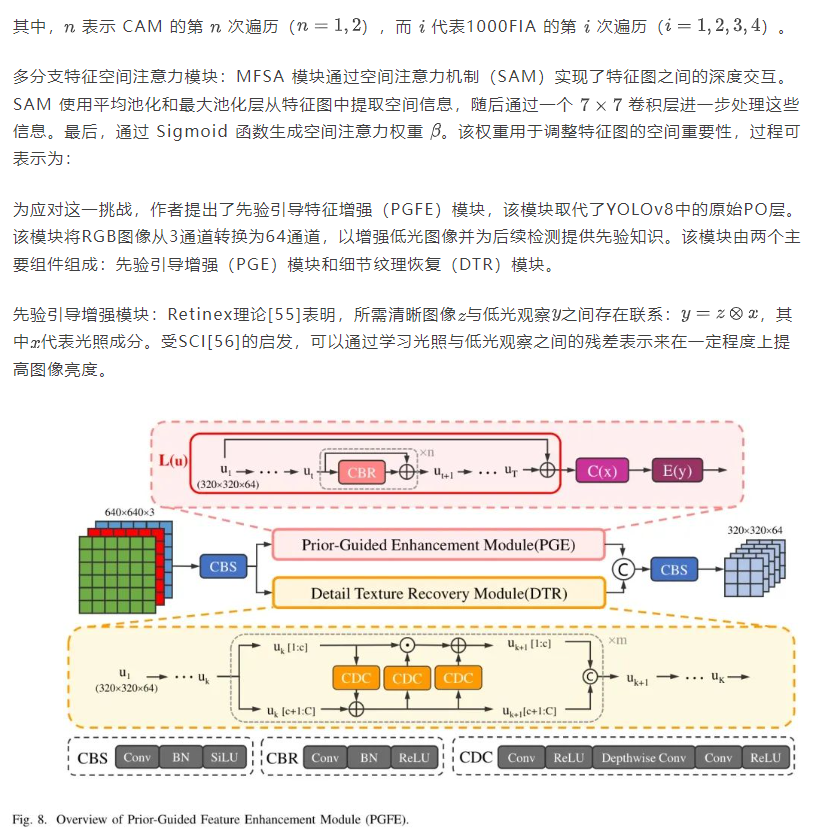
与直接将低光观察映射到光照相比,学习残差表示显著降低了计算复杂度,并有助于避免由于亮度增强不平衡而引起的曝光问题。这种设计使得作者的网络在夜间保持强大性能的同时,也能在白天保持其性能。如图8所示,对输入特征应用n个连续的残差操作,然后将最终输出添加到初始特征中以提高它们。公式如下:
![]()

D.基于先验的特征增强模块
在光照条件较差的情况下捕获的图像通常质量较差,这表现为噪声增加、对比度降低、边缘模糊以及暗区中的信息隐藏,严重影响了交通标志检测的准确性。然而,仅仅使用现有网络增加曝光度可能会放大图像噪声,使得原本低质量的图像仍然不清晰,这会对后续的目标检测任务产生负面影响。

4. 实验
在本节中,作者详细描述了实验中所使用的dataset、参数设置和评估指标。通过实验结果展示了算法的有效性和结构的合理性。最后,作者对实验结果进行了错误分析,并进行了实际应用测试。
A. 数据集

为了评估YOLO-LLTS在夜间识别交通标志的性能,作者使用公开数据集TT100K、CCTSDB2021以及作者自有的数据集CNTSSS进行全面的评估。
-
1. TT100K-night:清华大学和腾讯联合实验室组织并发布的TT100K数据集,根据Zhu等人[46]的方法进行了修改,排除了样本少于100个的类别,将焦点缩小到45个类别。训练集包含6,105张图像,测试集包含3,071张图像,每张图像的分辨率为2048x2048像素。如图9所示,作者使用了CycleGAN[61]来增强TT100K数据集,以确保对模型性能的更准确评估。
-
2. CNTSSS:将白天数据转换为夜间条件无法准确评估模型在夜间性能。因此,作者构建了自己的数据集,该数据集仅包含夜间捕获的交通标志图像。CNTSSS数据集包括训练集中的3,276张图像和测试集中的786张图像,交通标志被分类为强制、禁止或警告类型。更详细的信息已在上一节中概述。
-
3. CCTSDB2021数据集:CCTSDB2021数据集由长沙理工大学创建,包含训练集和测试集共17,856张图像,交通标志被分为强制、禁止或警告类型。训练集包含16,356张图像,其中大约700张是在夜间拍摄的,其余图像是在白天拍摄的。尽管训练集的夜间数据量不如CNTSSS数据集,但这种分布更能反映现实世界的驾驶条件,使其成为一个具有挑战性但又有价值的基准。为了评估模型在夜间的性能,作者从测试集中选取了500张夜间图像作为性能评估的基础。
B. 实验设置
-
1. 训练细节:作者的实验在一台配备四个NVIDIA GeForce RTX 4090 GPU的机器上进行。输入图像被调整至640x640像素的分辨率。对于CNTSSS数据集,训练的epoch数设置为200,对于TT100K和CCTSDB2021数据集,epoch数设置为300。批大小设置为48。作者使用学习率为0.01,动量为0.937的随机梯度下降(SGD)算法。
-
2. 评估指标:作者使用精确率、召回率、F1分数、平均精度均值(mAP)在50%交并比(IoU)下(mAP50)、平均精度均值从50%到95%交并比(mAP50:95)以及速度(FPS)来评估所提算法的性能。这些指标[62]的计算公式如下:

C. 与现有技术的比较
与现有最先进的技术相比,YOLO-LLTS在准确性和速度方面均表现出优异的性能。作者将YOLO-LLTS与包括YOLOv5 [63]、YOLOv6 [64]、GOLD-YOLO [65]、YOLOv8 [66]、YOLOv9 [67]、YOLOv10 [68]、张等人 [22]、MIAF-net [15]、YOLOv11 [69]、YOLO-TS [16]和YOLOv12 [70]在内的多个模型进行了比较。这些比较模型都是过去五年内开发的先进模型。
如表1所示,尽管YOLO-TS在TT100K-night数据集上表现出极高的性能,但YOLO-LLTS仍然优于YOLO-TS。具体来说,YOLO-LLTS达到了77.2%的准确率,比排名第二的YOLO-TS高出2.0%。在召回率方面,YOLO-LLTS达到了64.4%,比YOLO-TS高1.2%。此外,YOLO-LLTSF1分数为70.2,比YOLO-TS高出1.5。在mAP50和mAP50-95评估指标中,这些指标衡量了模型在不同IoU阈值下的检测性能,YOLO-LLTS也表现最佳,分别达到了71.4%和50.0%。YOLO-LLTS参数数量为9.9M,FPS为83.3,在处理速度上保持了高效。由于MIAF-net缺乏开源代码,实验结果基于作者自己的重现。张等人仅发布了CCTSDB2021数据集的训练权重。因此,除了CCTSDB2021以外的数据集的实验结果是通过使用开源代码训练模型获得的。YOLO-LLTS在TTiooK-night数据集上的表现不佳可能归因于TT100K-night是从白天图像生成的,而模型对这种生成数据泛化能力不佳。
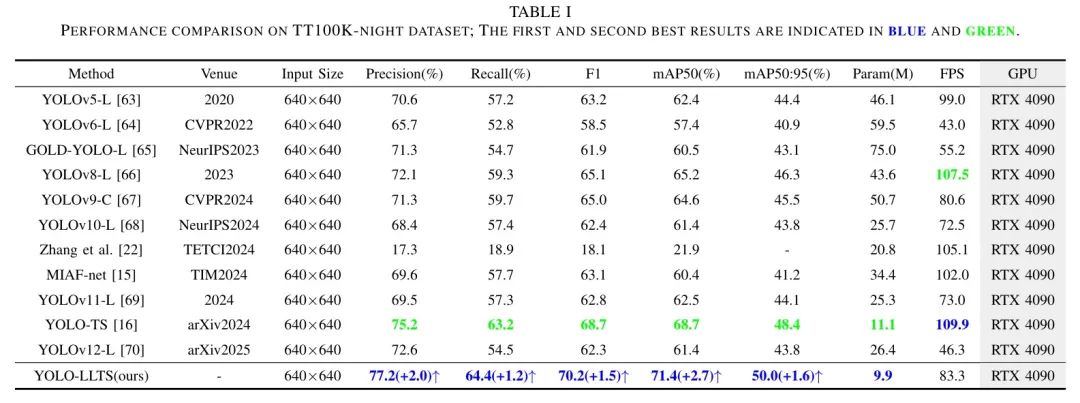
如图10所示,对CNTSSS数据集进行了与最新YOLO版本(包括YOLOv10 [68]、YOLOv11 [69]和YOLO-TS [16],均为2024年发布)的比较。第一行的图像显示,除了YOLO-LLTS外,其他所有模型都存在误检。从第二行到第五行,多个模型出现了漏检的实例。相比之下,YOLO-LLTS的结果与 GT 情况完全一致,能够准确识别交通标志。

D. 消融研究
在本节中,消融实验被设置以验证不同模块的合理性。为了全面评估在低光照条件下交通标志识别的有效性,作者在CNTSSS数据集上使用mAP50和mAP50:95指标进行对比实验。
-
1. HRFM-TOD的有效性:为了验证HRFM-TOD的有效性,作者在 Baseline 之上仅保留此模块。如表所示,HRFM-TOD模块将mAP50从75.1%提升至77.6%,提升了2.5%,同时将mAP50:95从53.3%提升至55.5%,提升了2.2%。FPS也从75.4提升至77.0。实验表明,HRFM-TOD模块不仅提升了检测性能,还加速了模型推理速度。
-
2. PGFE的有效性:为了验证PGFE的有效性,作者进行了相应的消融实验。如表所示,PGFE模块将mAP50从75.1%提升至78.3%,提高了3.2%,将mAP50:95从53.3%提升至55.5%,提高了2.2%。当PGFE与HRFM-TOD结合使用时,mAP50提高了4.4%,mAP50:95提高了5.8%。实验表明,HRFM-TOD模块显著提升了低质量图像,从而改善了检测性能。此外,作者还对公式中的不同参数设置进行了实验。如表所示,当γ和δ分别设置为2和2.5时,模型表现最佳。
-
3. DFEDR的有效性:由于DFEDR模块只能与HRFM-TOD模块结合使用,作者验证了这两个模块的联合效果。如表倒数第二行所示,与 Baseline 相比,mAP50和mAP50:95分别提高了4.5%和5.1%。与仅使用HRFM-TOD的配置相比,mAP50和mAP50:95分别提高了2.0%和2.9%。实验表明,DFEDR模块有效地整合了多感受野特征,提高了检测性能。
E. 错误分析与模型部署
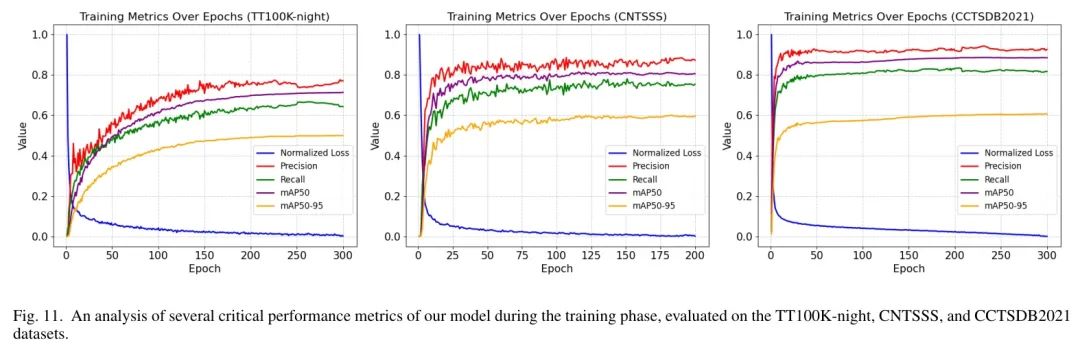
在本研究中,作者对交通标志检测模型的训练错误进行了详细分析,涉及三个不同的数据集[71]。图11展示了关键训练指标(包括归一化损失、精确度、召回率、mAP50和mAP50-95)随训练轮数增加的变化情况。归一化损失是框损失、分类损失和分布Focal Loss的加和,作者对其进行了归一化处理以便于展示。如图所示,在所有数据集中,随着训练轮数的增加,归一化损失迅速下降并最终稳定,表明模型在这些数据集上表现出良好的收敛性。这些关键性能指标在训练初期迅速增加,并最终稳定。
同时,作者在移动边缘设备NVIDIA Jetson AGX Orin上进行了推理速度测试。实验在Ubuntu 18.04操作系统环境下进行,使用PyTorch深度学习框架(版本2.1.0),并由Jetpack 5.1提供优化支持。作者选择了CCTSD2021数据集中的1,500张测试图像进行速度测试。未使用TensorRT加速时,YOLO-LLTS每张图像的推理时间为44.9毫秒,帧率为22.3。实验表明,YOLO-LLTS在边缘设备上表现出良好的实时性能。这表明YOLO-LLTS在High-Level驾驶辅助系统(ADAS)和自动驾驶系统中具有广阔的应用前景。此外,作者还使用移动边缘计算设备在现实世界的道路场景中评估了该模型。如图12所示场景中,交通标志被成功检测并准确分类。这证明了YOLO-LLTS在现实世界应用中的完全有效性。

5. 结论
本文提出了一种名为YOLO-LLTS的端到端实时交通标志检测算法,该算法专门针对低光环境设计。为了解决夜间特定交通标志数据集的缺乏,作者构建了一个名为中国夜间交通标志样本集(CNTSSS)的新数据集。该数据集包括从黄昏到午夜不同低光条件下拍摄的照片,涵盖了城市、高速公路和农村环境下的多种场景,以及不同的天气条件。作者引入了高分辨率特征图用于小目标检测(HRFM-TOD)模块,以有效解决低光条件下小目标特征不清晰的问题,显著提高了检测精度和推理速度。
此外,作者设计了多分支特征交互注意力(MFIA)模块,使多个感受野之间的特征能够进行深度交互和融合,从而增强了模型捕捉和利用关键信息的能力。进一步地,作者提出了先验引导增强模块(PGFE),以减轻低光环境下噪声增加、对比度降低和模糊等问题,显著提升了检测性能。实验结果表明,YOLO-LLTS在TT100Knight、CNTSSS和CCTSDB2021数据集上实现了最先进的性能。在边缘设备上的部署实验进一步验证了该方法的实际有效性和实时适用性。
在未来工作中,作者计划扩展CNTSSS数据集,增加更多样化的场景,并进一步优化算法,以增强其在现实世界自动驾驶应用中的鲁棒性和泛化能力。作者还将发布作者的源代码和数据集,以促进该领域的进一步研究。
参考
[1]. YOLO-LLTS: Real-Time Low-Light Traffic Sign Detection via Prior-Guided Enhancement and Multi-Branch Feature Interaction
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









