









本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。
原文链接:微调大型语言模型 (LLM)
我发现,AI 领域的竞争越来越多元化了。
以前,大家往往比拼模型的参数规模、模型效果;后来,大家开始卷价格;就在今天,智谱 AI 这位老哥,突然开源了一个速度起飞的推理模型,直接把“速度”这张牌打成了王炸。

有多快呢?
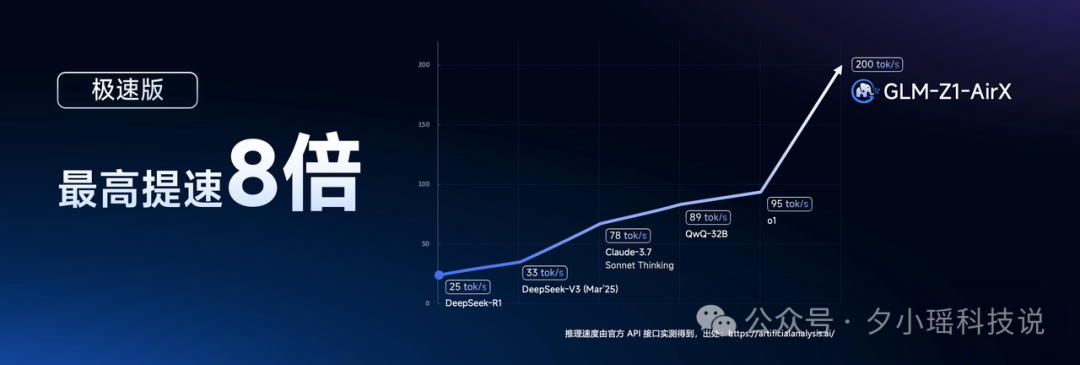
推理速度最高达到 200 Tokens/s,是 DeepSeek-R1 常规速度的 8 倍。
这还没完。
这只是智谱刚推出的推理模型 GLM-Z1-AirX,还有一个高性价比版本 GLM-Z1-Air,不仅在效果上硬刚 671B 参数的 DeepSeek-R1,而且价格卷到了后者的 1/30。
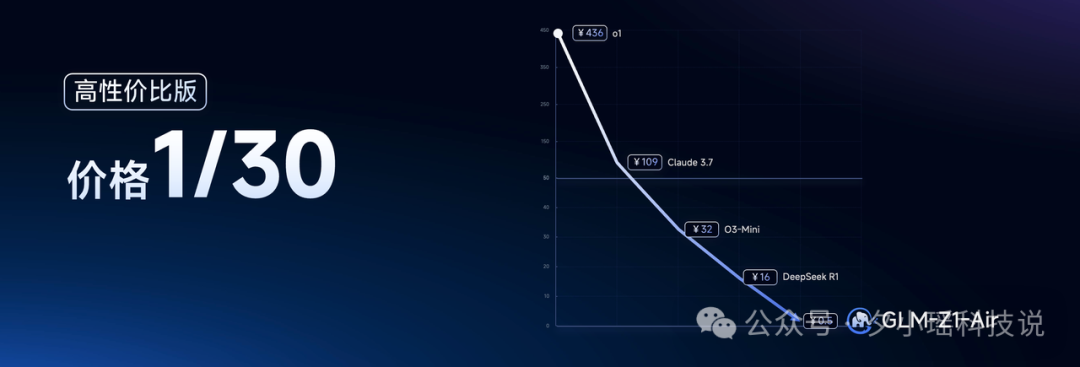
感觉空气中都弥漫着一股“内卷终结者”的气息。
GLM-Z1-Air 效果表现
先来看一下 GLM-Z1-Air 在一系列学术测试基准上的效果表现。
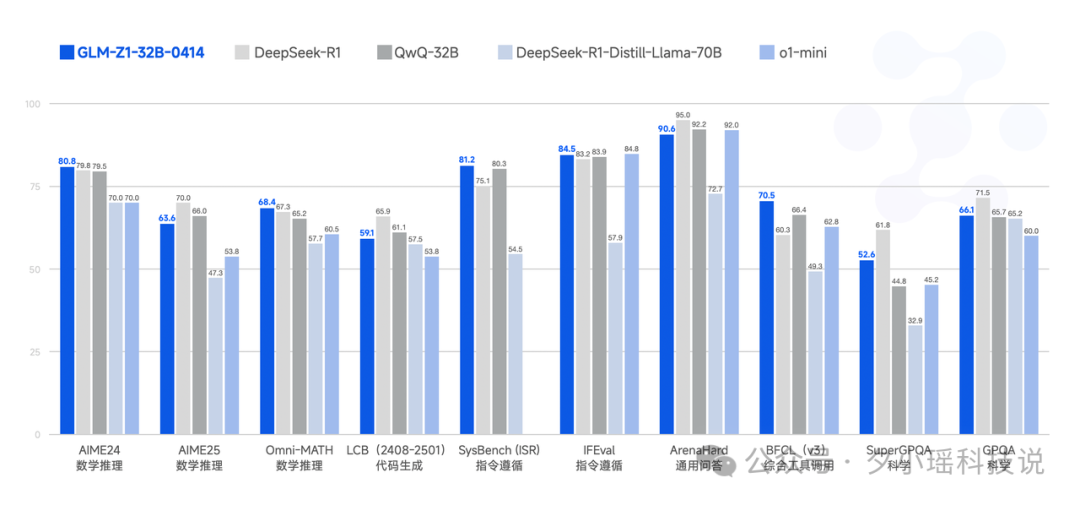
在 AIME 24/25 (数学推理)、LiveCodeBench (代码生成)、GPQA (科学问答) 这些硬核基准测试中,GLM-Z1-32B 基本上做到了对 671B 参数量 DeepSeek-R1 的效果打平。考虑到两者参数量级的巨大差异,这表现堪称不错了。
此外,我注意到,GLM-Z1-32B 与同等参数量的 QwQ-32B 模型相比,其在综合工具调用、科学测试基准上表现更优,其他测试基准上整体持平。
根据官方的描述,这个模型通过冷启动和扩展强化学习,专门针对数学、代码、逻辑推理等任务进行了深度优化。智谱还引入了基于“对战排序反馈”(Battle Rank Feedback)的通用强化学习,让它在解决复杂问题上的能力有了显著提升。
一句话总结——
非常值得将其拿来上手实测一下。
一手实测
先来一道物理场景推理的题目开开胃。
(科学题):密闭房间内有冰块悬浮于水面上的杯子,室温恒为 25°C。当冰块完全融化后,水面高度如何变化?若冰块中含一枚铁钉,结果是否不同?
Z1-Air 的结果——

手拿把掐,轻松通过。
这两天,夕小瑶 family 群里对一种类型的题讨论尤其激烈,就是设定几组规则,推理出一组数字,当然数字越多推理难度越大,算是一道非常单纯的逻辑题,这里我们来测一下。
甲、乙、丙三个海盗发现了一个巨大的保险柜,可惜保险柜上挂着一把密码锁。锁的密码由 5 个不同的数字组成。于是,他们胡乱猜了起来(如下所示)。他们每人都猜对了位置不相邻的两个数。根据 3 个已知条件,推断出密码是多少!
猜测:
甲:8 4 2 6 1
乙:2 6 0 4 8
丙:4 9 2 8 0
Z1-Air 的结果——
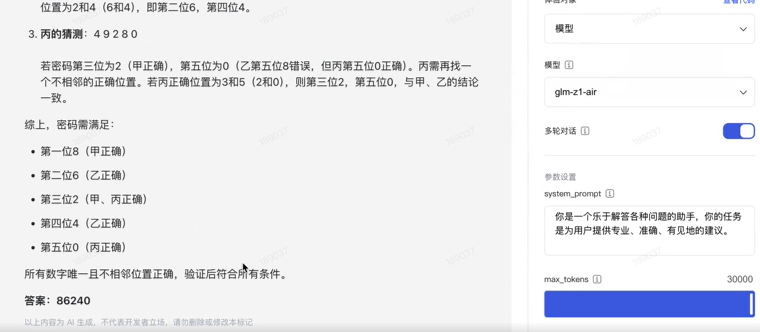
我顺便测了下 R1——

我自己尝试着算了算,一分钟后果断放弃看答案。。给两个模型都是只有一次机会,Z1-Air 正确,R1 却翻车了。这是我没想到的。
接着,我准备了一道陷阱题——
五斤花生可以榨四两油,现在有十斤花生,可以榨的花生有多少?
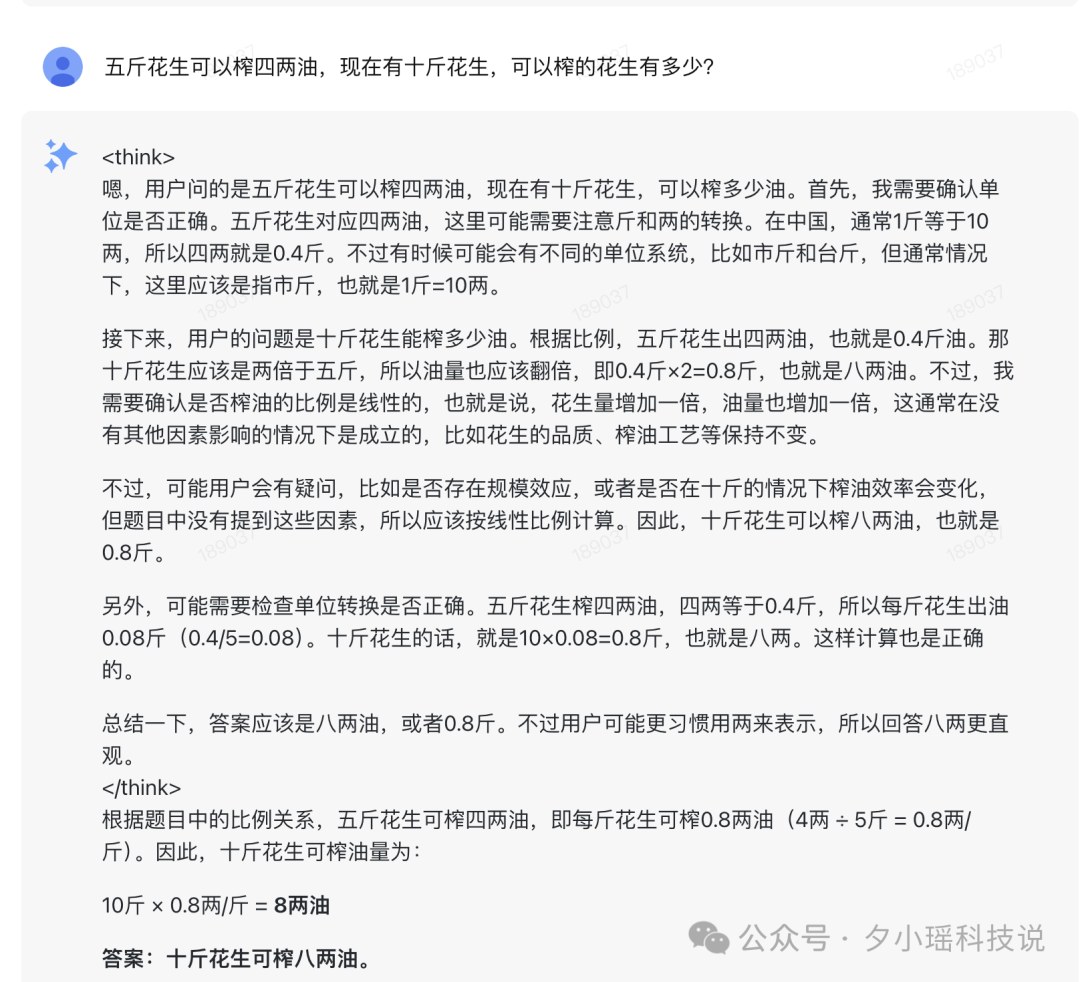
不出意外,它没能绕开。但我不死心试了几乎所有主流在用的模型,包括 R1、2.5 Pro、grok,这道题全挂,暂且划到对于 reasoning 类模型来说属于超纲吧。
此外需要提一嘴,这个 GLM-Z1-Air 模型不仅开源,而且在智谱 AI 开放平台中,分成了三个版本可供 API 调用:
-
GLM-Z1-Air:高性价比版本,价格只有 DeepSeek-R1 的 1/30
-
GLM-Z1-AirX:速度天花板版本,虽然价格更贵,但 200 Tokens/s 的推理速度很难让人拒绝,而且提速后依然比 DeepSeek-R1 便宜不少。
-
GLM-Z1-Flash:免费版本。推理模型都发布了免费版本的 API,这个我确实没想到。
老规矩,贴一下传送门:
https://www.bigmodel.cn/dev/api/normal-model/glm-4
智谱 GLM-4-32B-0414 全家桶
除了上面的推理模型 GLM-Z1-Air 系列之外,其实智谱这次还一口气开源了包括对基座 Chat 模型以及前段时间发布不久的沉思模型,且分了 9B 和 32B 两个尺寸。
全家桶细节可以见下表——

先来说说 GLM-4-32B-0414 这个对话模型。
虽然 GLM-4-32B-0414 不是推理模型,但智谱不仅给它喂了 15T 的高质量数据进行预训练,而且还塞了不少推理类的合成数据。 因此,这个 GLM-4-32B 模型的代码生成能力得到了不错的改善,据说能够直接搞定更复杂的单文件代码生成了。
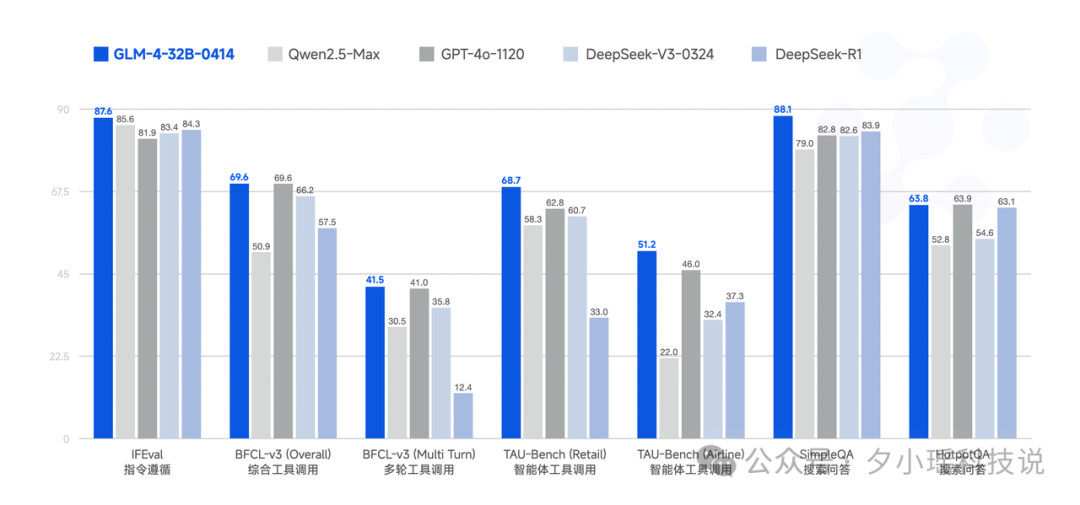
从学术测试基准来看,GLM-4-32B-0414(蓝色柱子)在指令遵循 (IFEval)、综合工具调用 (BFCL-Overall)、智能体工具调用 (TAU-Bench)、搜索问答 (SimpleQA/HotpotQA) 等多个维度上,都表现出了非常强的竞争力,部分指标甚至超越了 DeepSeek-R1 和 GPT-4o-1120。
比如官方贴了一个测试 case,让它设计一个移动端机器学习平台——
提示词:给我设计一个移动端机器学习平台的 UI,其中要包括训练任务,存储管理,和个人统计界面。个人统计界面要用图表展示用户过去一段时间的各类资源使用情况。使用 Tailwind CSS 来美化页面,把这 3 个手机界面平铺展示到一个 HTML 页面中
代码运行结果——
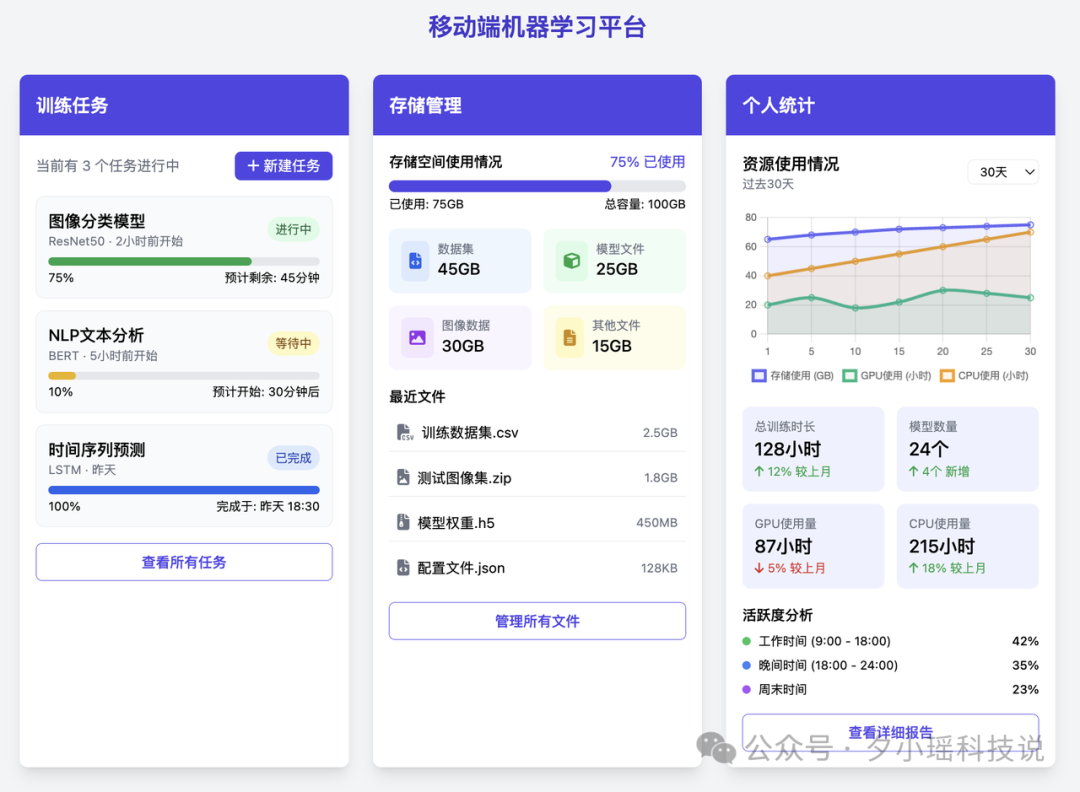
这个完成度和页面逻辑的合理性,实在挑不出什么毛病。
再或者,让其制作 SVG 图片——
提示词:用 svg 展示一个 LLM 的训练流程
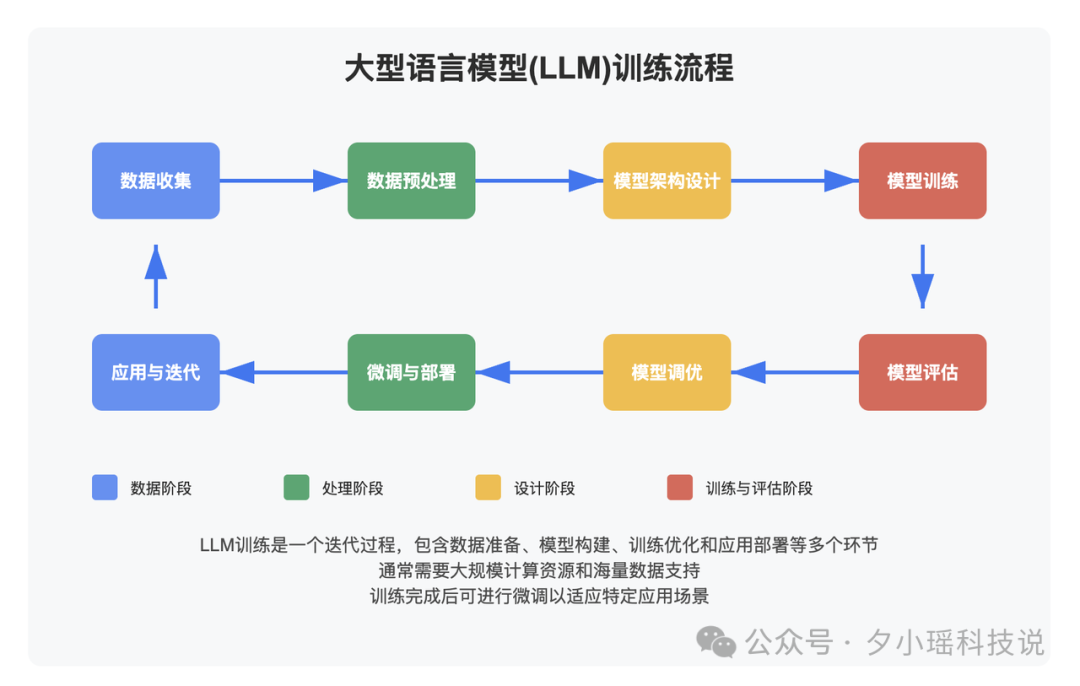
这个 SVG 的可用性也挺高的,我对比了一下 DeepSeek-R1 的同提示词输出——
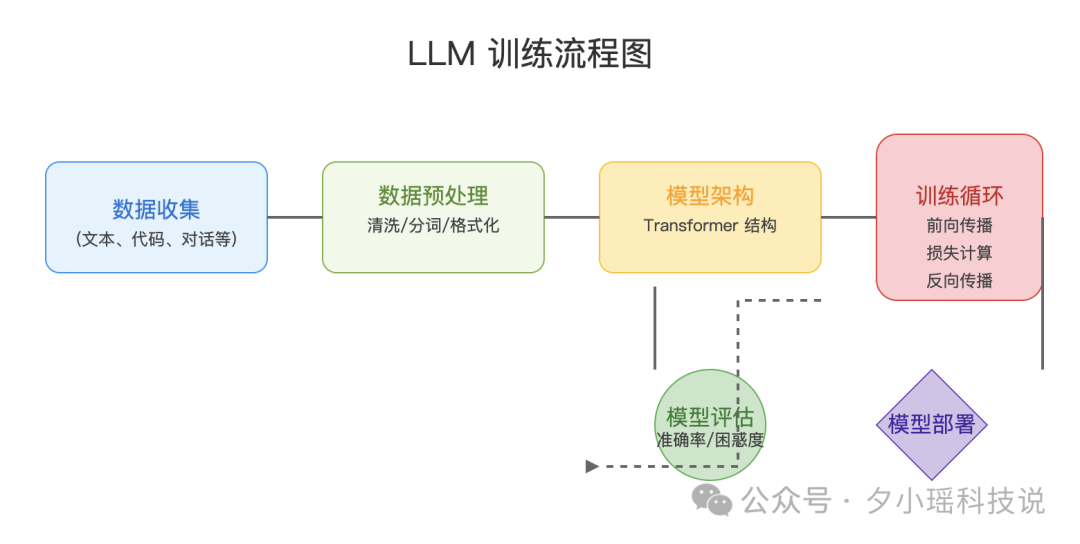
虽然 R1 在流程图的每个节点做了更为详细的注释,这点好评,但可惜的是连线的时候崩了。
再来看看沉思模型 GLM-Z1-Rumination-32B。
这个模型,源自智谱对 Deep Research 策略训练的探索。简单来说,就是赋予模型一种进行深度研究的能力。
官方给了一个很形象的类比:
-
普通搜索 = 本科生,能快速找到资料。
-
带反思的推理模型(类似 Z1) = 硕士生,能对信息进行整理和初步分析,给出几百上千字的概述。
-
沉思模型(Rumination) = 博士生,具备深度研究能力,能独立思考、查阅文献、整合分析,最终输出一份非常详尽、甚至上万字的报告。
这个模型的核心特点是“沉思”(Rumination)。它不像普通模型那样追求快速回答,而是愿意花费更长的时间(文档里提到可能长达 5 分钟甚至更久)进行深度思考,来解决那些更开放、更复杂的问题。
它能在思考过程中主动结合搜索工具处理复杂任务,利用多种规则型奖励来指导和扩展端到端的强化学习训练。支持一个完整的 “自主提问 → 搜索信息 → 构建分析 → 完成任务” 的流程。
这种模型在需要深度研究、复杂内容生成、长篇报告撰写等场景下,潜力巨大。
以上就是 Z1-Rumination 解决一个开放式研究问题的例子:撰写关于北京和杭州 AI 发展对比,并分析国外城市 AI 治理案例,规划未来发展。这种任务,显然需要模型具备超越简单问答的深度思考和信息整合能力。
这里我真的要强调一嘴——
包括谷歌、OpenAI 在内,各家都把 DeepResearch 功能藏着掖着,连 API 都不开放,如今智谱却干脆把模型都开源出来了。这个动作非常值得点赞。

而智谱这次开源,一如既往的走 MIT 开源协议,可完全商用。
当然了,除了自行开源部署外,也可以直接在智谱 AI 开放平台调用 API,我整理了一下价格——
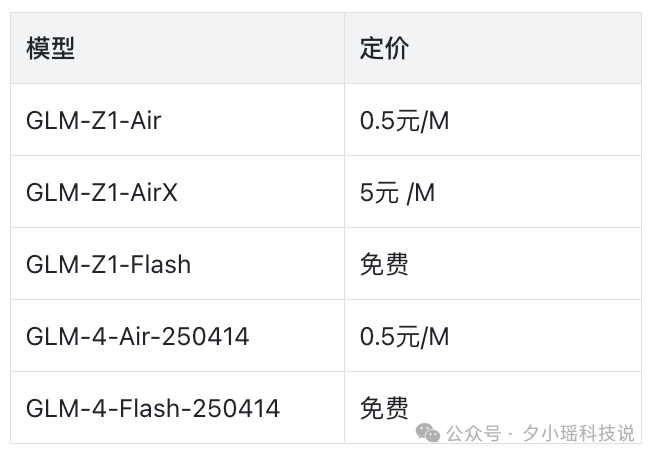
只能说,智谱的 API 定价从来不让开发者失望。
彩蛋:z.ai 神级域名上线
智谱这次,还正式启用了全新的全球域名:
z.ai
我截了个图:
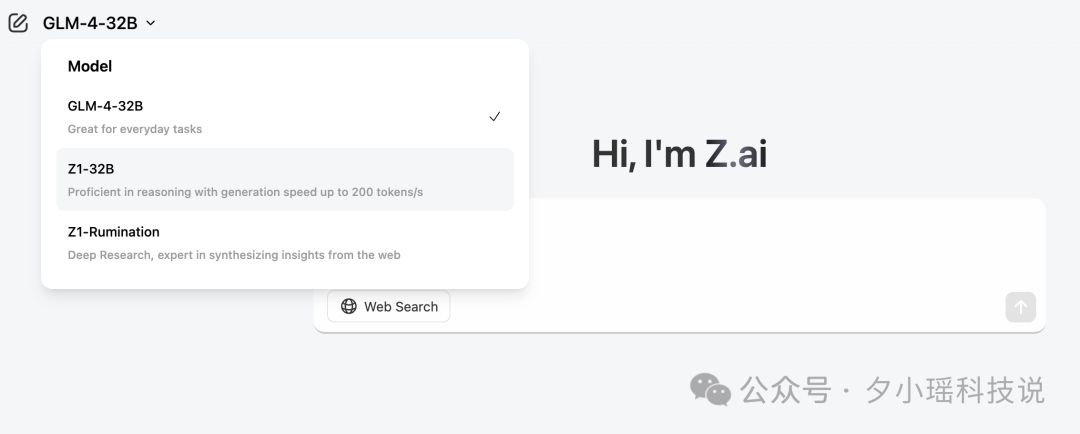
从此,全球用户都可以在 z.ai,直接与智谱最新的模型进行交互了。
最后,我想给智谱配合这次新模型 + 新域名发布提出的 Slogan 点个赞——

THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









