









本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:45倍加速+最新SOTA!VAE与扩散模型迎来端到端联合训练:REPA-E让VAE自我进化!

文章链接: https://arxiv.org/pdf/2504.10483
项目链接:https://end2end-diffusion.github.io/
Git链接:https://github.com/End2End-Diffusion/REPA-E
模型链接:https://huggingface.co/REPA-E
亮点直击
端到端联合优化的突破 首次实现VAE与扩散模型的端到端联合训练,通过REPA Loss替代传统扩散损失,解决两阶段训练目标不一致问题,使隐空间与生成任务高度适配。
训练效率革命性提升 REPA-E仅需传统方法1/45的训练步数即可收敛,且生成质量显著超越现有方法(如FID从5.9降至4.07),大幅降低计算成本。
双向性能增益 不仅提升扩散模型性能,还通过反向传播优化VAE的隐空间结构,使其成为通用型模块,可迁移至其他任务(如替换SD-VAE后下游任务性能提升)。
总结速览
解决的问题
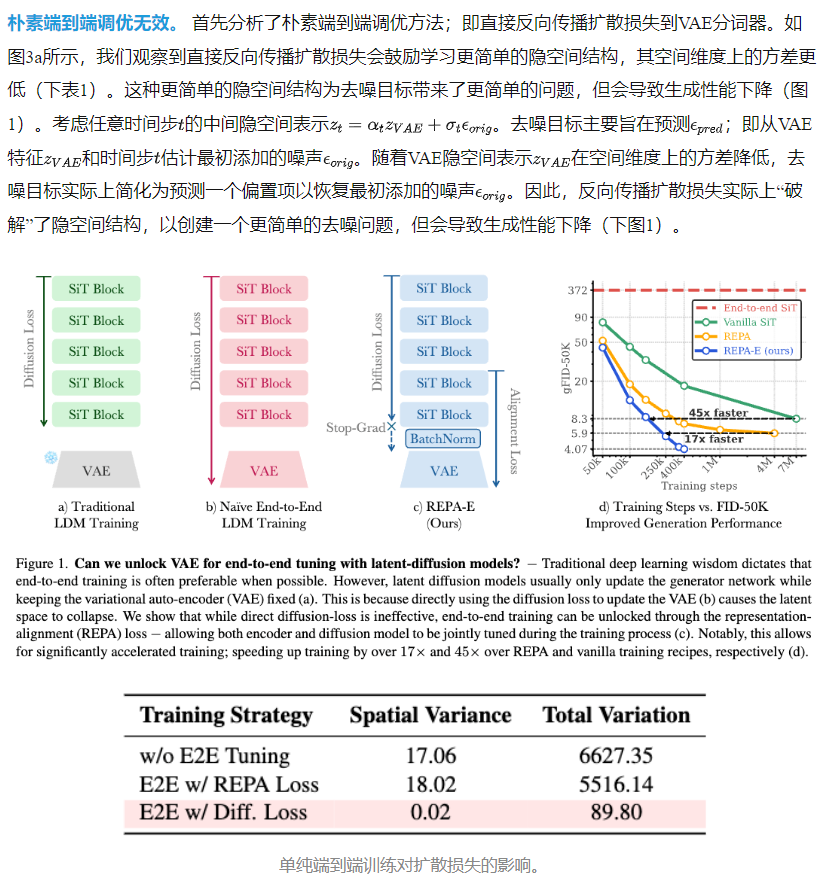
现有隐空间扩散模型(LDM)采用两阶段训练(先训练VAE,再固定VAE训练扩散模型),导致两个阶段的优化目标不一致,限制了生成性能。直接端到端联合训练VAE和扩散模型时,传统扩散损失(Diffusion Loss)失效,甚至导致性能下降。
提出的方案
提出REPA-E训练框架,通过表示对齐损失(REPA Loss)实现VAE与扩散模型的端到端联合优化。REPA Loss通过对齐隐空间表示的结构,协调两者的训练目标,替代传统扩散损失的直接优化。
应用的技术
-
表示对齐损失(REPA Loss):在扩散模型的去噪过程中,对齐隐空间表示的分布,确保VAE生成的隐空间编码更适配扩散模型的训练目标。
-
端到端梯度传播:通过联合优化框架,将扩散模型的梯度反向传播至VAE,动态调整其隐空间结构。
-
自适应隐空间优化:根据扩散模型的训练需求,自动平衡VAE的重建能力与隐空间的可学习性。
达到的效果
-
训练加速:相比传统两阶段训练(4M步),REPA-E仅需400K步即达到更优性能,训练速度提升45倍;相比单阶段REPA优化(17倍加速)。
-
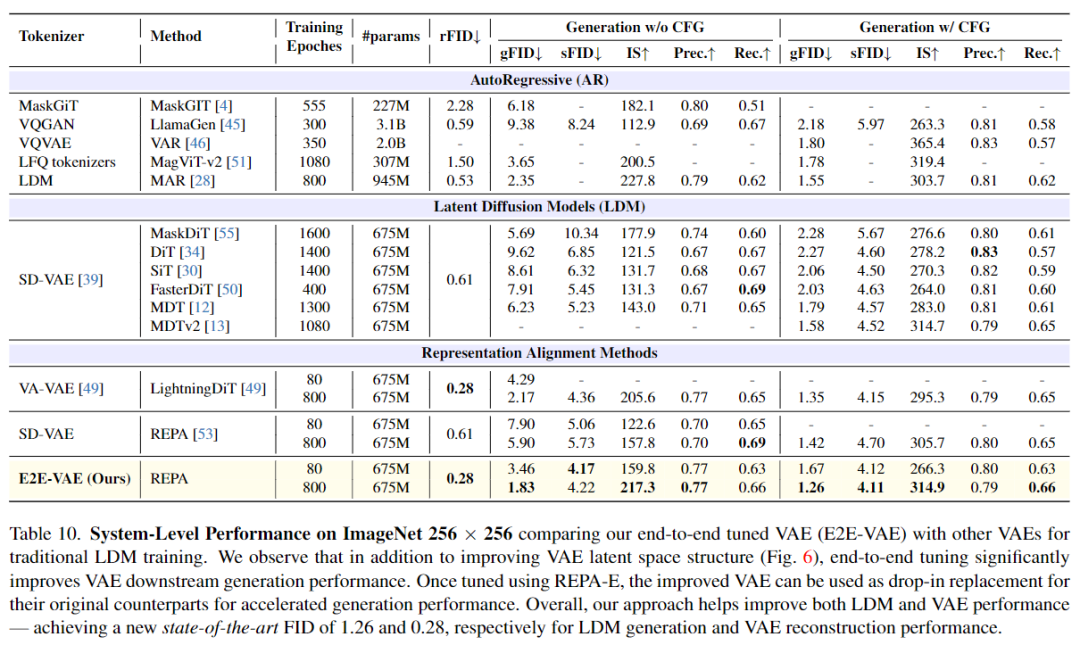
生成质量SOTA:在ImageNet 256×256上,FID达到1.26(使用分类器引导)和1.83(无引导),刷新当前最佳记录。
-
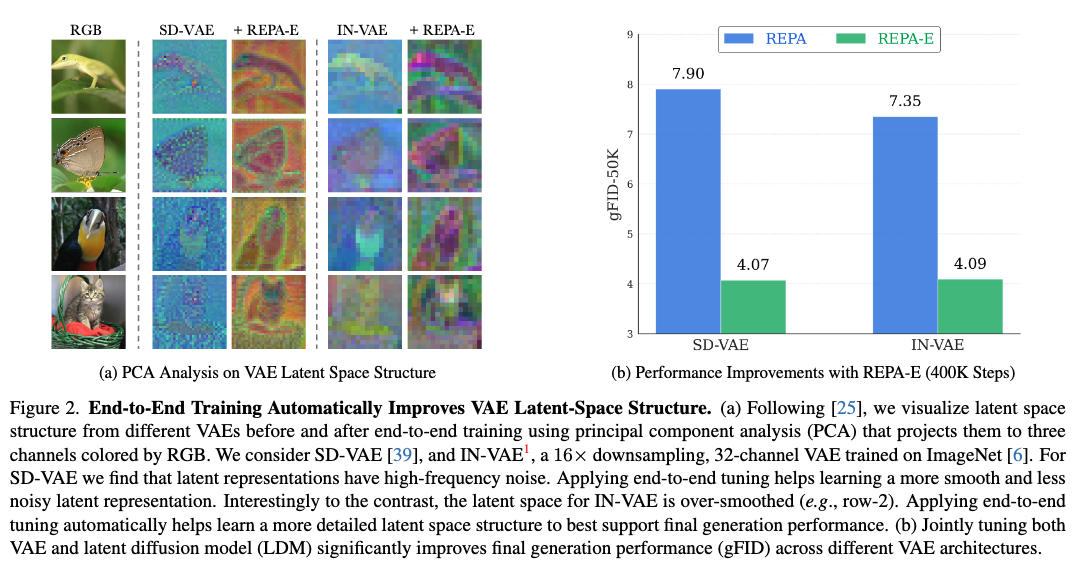
隐空间改善:对不同初始结构的VAE(如高频噪声的SD-VAE、过平滑的IN-VAE),端到端训练自动优化其隐空间,提升生成细节
REPA-E:解锁VAE的联合训练
概述。 给定一个变分自编码器(VAE)和隐空间diffusion transformer (例如SiT),本文希望以端到端的方式联合优化VAE的隐空间表示和扩散模型的特征,以实现最佳的最终生成性能。首先提出三个关键见解:1)朴素的端到端调优——直接反向传播扩散损失到VAE是无效的。扩散损失鼓励学习更简单的隐空间结构(下图3a),这虽然更容易最小化去噪目标,但会降低最终生成性能。接着分析了最近提出的表示对齐损失,发现:2)更高的表示对齐分数与改进的生成性能相关(图3b)。这为使用表示对齐分数作为代理来提升最终生成性能提供了另一种途径。3)使用朴素REPA方法可达到的最大对齐分数受限于VAE隐空间特征的瓶颈。进一步表明,在训练过程中将REPA损失反向传播到VAE有助于解决这一限制,显著提高最终的表示对齐分数(图3c)。
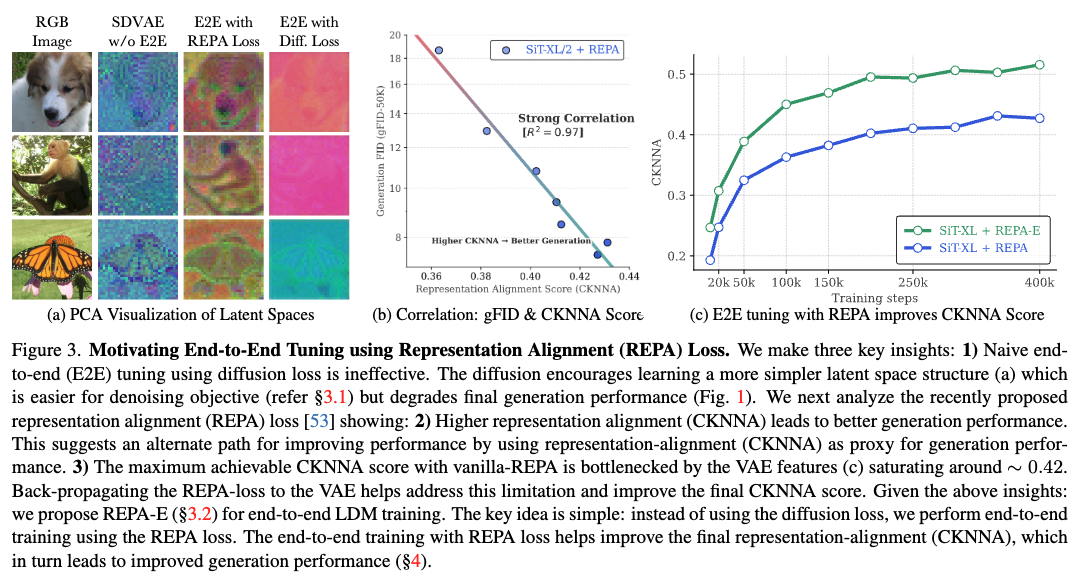
基于上述见解本文提出了REPA-E;一种用于联合优化VAE和LDM特征的端到端调优方法。我们的核心思想很简单:不直接使用扩散损失进行端到端调优,而是使用表示对齐分数作为最终生成性能的代理。这促使本文提出最终方法,即不使用扩散损失,而是使用表示对齐损失进行端到端训练。通过REPA损失的端到端训练有助于更好地提高最终的表示对齐分数(图3b),从而提升最终生成性能。
用REPA推动端到端训练的动机
更高的表示对齐分数与更好的生成性能相关。 本文还使用CKNNA分数在不同模型规模和训练迭代中测量表示对齐。如前图3b所示,训练过程中更高的表示对齐分数会带来更好的生成性能。这表明可以通过使用表示对齐目标(而非扩散损失)进行端到端训练来提升生成性能。
表示对齐受限于VAE特征。 图3c显示,虽然朴素应用REPA损失可以提高表示对齐(CKNNA)分数,但可达到的最大对齐分数仍受限于VAE特征,饱和值约为0.4(最大值为1)。此外,我们发现将表示对齐损失反向传播到VAE有助于解决这一限制;允许端到端优化VAE特征以最好地支持表示对齐目标。
基于REPA的端到端训练
REPA-E——一种用于联合训练VAE和LDM特征的端到端调优方案。建议使用表示对齐损失而非直接使用扩散损失来进行端到端训练。通过REPA损失实现的端到端训练能够更好地提升最终表示对齐分数(图3c),从而改善最终生成性能。
VAE隐空间归一化的批归一化层为了实现端到端训练,我们首先在VAE和隐空间扩散模型之间引入批归一化层。典型的LDM训练需要使用预计算的隐空间统计量(例如SD-VAE的std=1/0.1825)对VAE特征进行归一化。这有助于将VAE隐空间输出归一化为零均值和单位方差,从而提高扩散模型的训练效率。然而,在端到端训练中,每当VAE模型更新时都需要重新计算统计量——这代价高昂。为解决这个问题,我们提出使用批归一化层,该层使用指数移动平均(EMA)均值和方差作为数据集级统计量的替代。因此,批归一化层充当了可微分归一化算子,无需在每次优化步骤后重新计算数据集级统计量。

实验
本文通过广泛实验验证REPA-E的性能及所提组件的影响,主要探究三个关键问题:
-
REPA-E能否显著提升生成性能与训练速度?(下表2、前图1、下图4)
-
REPA-E是否适用于不同训练设置(模型规模、架构、REPA编码器等)?(下表3-8)
-
分析端到端调优(REPA-E)对VAE隐空间结构及下游生成性能的影响。(图6、表9-10)
实验设置

训练性能与速度的影响
首先分析REPA-E对隐空间diffusion transformer 训练性能与速度的提升。
定量评估
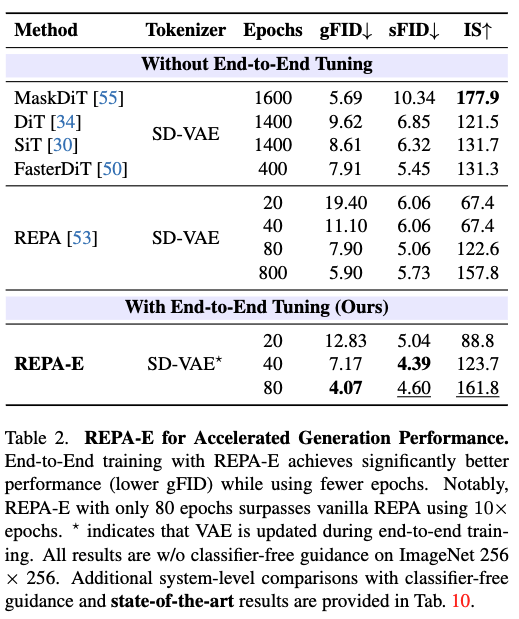
下表2比较了不同隐空间扩散模型(LDM)基线。在ImageNet 256×256生成任务中评估相似参数量(∼675M)的模型,结果均未使用分类器无关引导。关键发现:
-
端到端调优加速训练:相比REPA,gFID从19.40→12.83(20轮)、11.10→7.17(40轮)、7.90→4.07(80轮)持续提升;
-
端到端训练提升最终性能:REPA-E在80轮时gFID=4.07,优于FasterDiT(400轮,gFID=7.91)、MaskDiT、DiT和SiT(均训练1400轮以上)。REPA-E仅需40万步即超越REPA 400万步的结果(gFID=5.9。
定性评估
下图4对比REPA 与REPA-E在5万、10万、40万步的生成效果。REPA-E在训练早期即生成结构更合理的图像,且整体质量更优。


REPA-E的泛化性与可扩展性
进一步分析REPA-E在不同训练设置下的适应性(模型规模、分词器架构、表示编码器、对齐深度等)。默认使用SiT-L 为生成模型,SD-VAE为VAE,DINOv2-B为REPA损失的预训练视觉模型,对齐深度为8。各变体训练10万步,结果均未使用分类器无关引导。
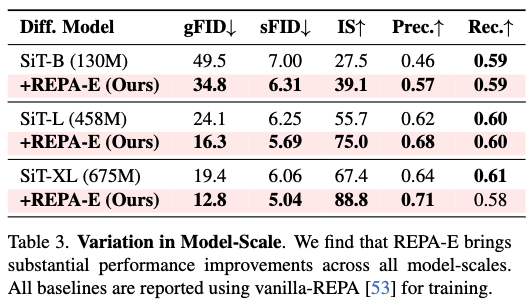
模型规模的影响
下表3比较SiT-B、SiT-L和SiT-XL:
-
REPA-E在所有配置下均优于REPA基线,gFID从49.5→34.8(SiT-B)、24.1→16.3(SiT-L)、19.4→12.8(SiT-XL);
-
增益随模型规模增大:SiT-B提升29.6%,SiT-L提升32.3%,SiT-XL提升34.0%,表明REPA-E对大模型更具扩展性。
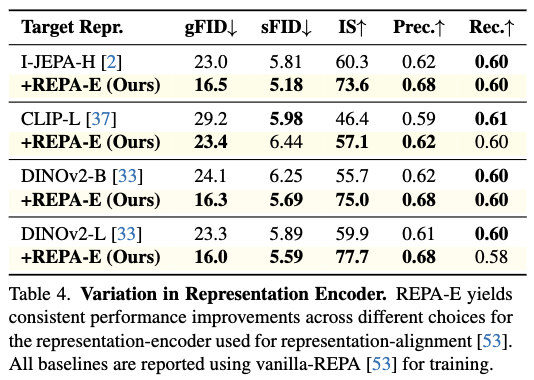
表示编码器的选择
表4显示不同感知编码器(CLIP-L、I-JEPA-H、DINOv2-B/DINOv2-L)下REPA-E均一致提升性能。例如DINOv2-B下gFID从24.1→16.3,DINOv2-L下从23.3→16.0。
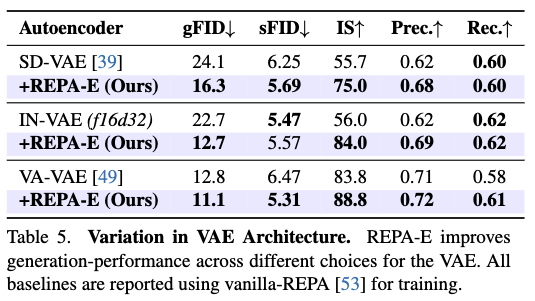
VAE的变体。 下表5评估了不同VAE对REPA-E性能的影响。我们报告了使用三种不同VAE的结果:1)SD-VAE,2)VA-VAE,以及3)IN-VAE(一个在ImageNet上训练的16倍下采样、32通道的VAE,使用[39]中的官方训练代码)。在所有变体中,REPA-E始终在性能上优于REPA基线。REPA-E将gFID从24.1降至16.3(SD-VAE),从22.7降至12.7(IN-VAE),从12.8降至11.1(VA-VAE)。结果表明,REPA-E在VAE的架构、预训练数据集和训练设置多样性的情况下,始终能稳健提升生成质量。
对齐深度的变体。 下表6研究了在扩散模型不同层应用对齐损失的效果。观察到REPA-E在不同对齐深度选择下均能持续提升生成质量,相较REPA基线,gFID分别从23.0降至16.4(第6层)、24.1降至16.3(第8层)、23.7降至16.2(第10层)。
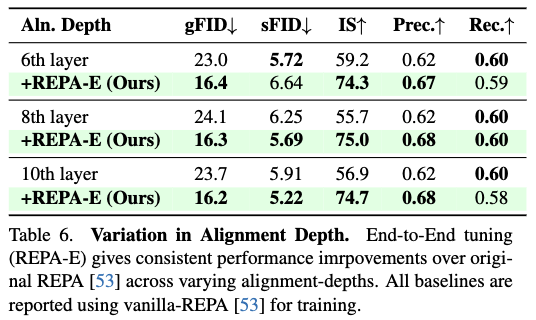
组件设计的消融实验。 本文还进行了消融研究,分析各组件的重要性,结果如表7所示。观察到每个组件对REPA-E的最终性能都起到了关键作用。特别地,观察到对扩散损失应用stop-grad操作有助于防止隐空间结构的退化。同样地,批归一化(batch norm)通过自适应地规范化潜变量统计信息,提升了gFID从18.09至16.3。同样地,正则化损失对保持微调后VAE的重建性能起到了关键作用,从而将gFID从19.07提升至16.3。
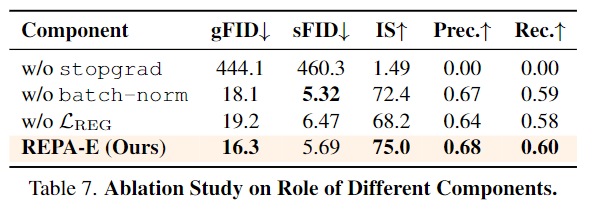
端到端从头训练。 分析了VAE初始化对端到端训练的影响。如表8所示,我们发现虽然使用预训练权重初始化VAE能略微提升性能,但REPA-E也可以在从头训练VAE和LDM的情况下使用,并仍然在性能上优于REPA,后者在技术上需要一个VAE训练阶段以及LDM训练阶段。例如,REPA在400万次迭代后达到FID 5.90,而REPA-E在完全从头训练的情况下(同时训练VAE和LDM)在仅40万次迭代内就达到了更快更优的生成FID 4.34。
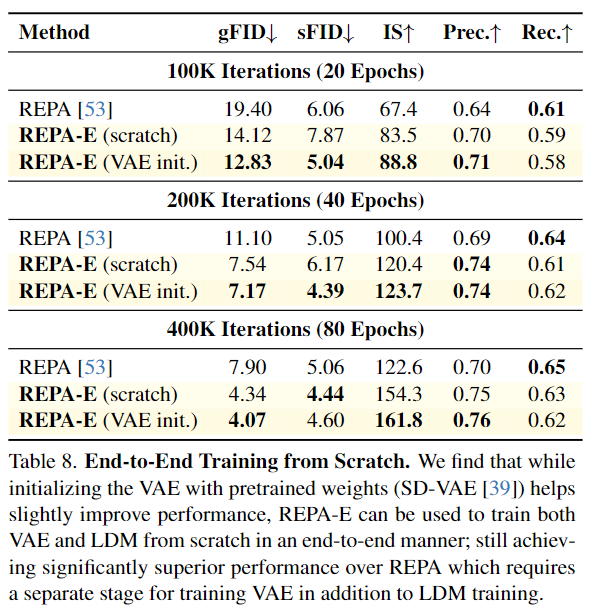
端到端微调对VAE的影响
接下来分析了端到端微调对VAE的影响。首先展示端到端微调能改善隐空间结构(下图6)。然后展示一旦使用REPA-E进行微调,微调后的VAE可以作为原始VAE的直接替代品,显著提升生成性能。

端到端训练提升隐空间结构。 结果如图6所示。本文使用主成分分析(PCA)将隐空间结构可视化为RGB着色的三个通道。我们考虑三种不同的VAE:1)SD-VAE,2)IN-VAE(一个在ImageNet上训练的16倍下采样、32通道的VAE),3)最新VA-VAE。观察到使用REPA-E进行端到端微调自动改善了原始VAE的隐空间结构。例如,与同时期工作的发现一致,我们观察到SD-VAE的隐空间存在高噪声成分。应用端到端训练后可自动帮助调整隐空间以减少噪声。相比之下,其他VAE如最新提出的VA-VAE的隐空间则表现为过度平滑。使用REPA-E进行端到端微调可自动学习更具细节的隐空间结构,以更好地支持生成性能。
端到端训练提升VAE性能。 接下来评估端到端微调对VAE下游生成性能的影响。首先对最近提出的VA-VAE进行端到端微调。然后我们使用该微调后的VAE(命名为E2E-VAE),将其下游生成性能与当前最先进的VAE进行比较,包括SD-VAE和VA-VAE。本文进行了传统的潜扩散模型训练(不使用REPA-E),即仅更新生成器网络,同时保持VAE冻结。表9展示了在不同训练设置下的VAE下游生成性能比较。端到端微调后的VAE在各种LDM架构和训练设置下的下游生成任务中始终优于其原始版本。有趣的是,观察到使用SiT-XL进行微调的VAE即使在使用不同LDM架构(如DiT-XL)时仍能带来性能提升,进一步展示了本文方法的稳健性。
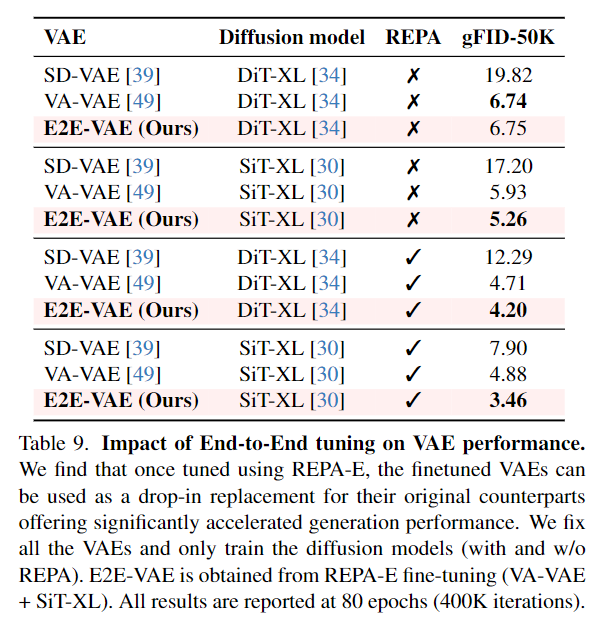
结论
本文探讨了一个基本问题:“我们是否能够实现基于隐空间扩散 Transformer 的端到端训练,从而释放 VAE 的潜力?”具体来说,观察到,直接将扩散损失反向传播到 VAE 是无效的,甚至会降低最终的生成性能。尽管扩散损失无效,但可以使用最近提出的表示对齐损失进行端到端训练。所提出的端到端训练方案(REPA-E)显著改善了隐空间结构,并展现出卓越的性能:相较于 REPA 和传统训练方案,扩散模型训练速度分别提升了超过 17× 和 45×。
REPA-E 不仅在不同训练设置下表现出一致的改进,还改善了多种 VAE 架构下原始的隐空间结构。总体而言,本文的方法达到了新的SOTA水平,在使用和不使用 classifier-free guidance 的情况下,分别取得了 1.26 和 1.83 的生成 FID 分数。希望本工作能够推动进一步的研究,推动隐空间扩散 Transformer 的端到端训练发展。
参考文献
[1] REPA-E: Unlocking VAE for End-to-End Tuning of Latent Diffusion Transformers

THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









