







问题描述
在使用bert-base-uncased时,只需要下载四个文件链接下载就可以正常使用。但是当我用roberta时下载相同的四个文件会报错TypeError
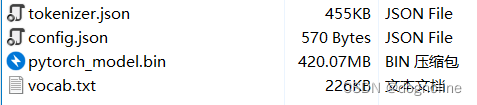
运行以下代码不报错,报错的话检查一下文件目录有没有出错
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(your_file_path)
使用roberta-large时,执行运行以下代码会报错
from transformers import RobertaTokenizer
tokenizer = RobertaTokenizer.from_pretrained(your_file_path)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1742, in from_pretrained
resolved_vocab_files, pretrained_model_name_or_path, init_configuration, *init_inputs, **kwargs
File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 1858, in _from_pretrained
tokenizer = cls(*init_inputs, **init_kwargs)
File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/models/roberta/tokenization_roberta.py", line 171, in __init__
**kwargs,
File "/home/user001/anaconda3/envs/pyg37/lib/python3.7/site-packages/transformers/models/gpt2/tokenization_gpt2.py", line 185, in __init__
with open(merges_file, encoding="utf-8") as merges_handle:
TypeError: expected str, bytes or os.PathLike object, not NoneType
解决
一般出现这个错误就是在路径下没有需要的文件,经过检查发现Roberta比Bert要多一个文件,我之前没有下载,现在重新下载放到目录中去。
注意: 路径是包含这五个文件的文件夹目录
下载官方文档中的merges.txt文件
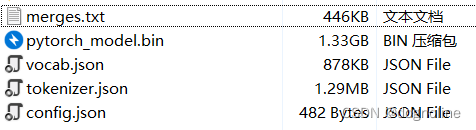
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(your_file_path)

















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









