






 面壁智能在北京发布了2亿参数的MiniCPM,一款云端协同且性能强劲的端侧大模型,相比大厂的千亿参数模型,MiniCPM通过高效的算法和数据优化,实现小尺寸的卓越性能,尤其是在多模态能力和成本效益上表现出色。
面壁智能在北京发布了2亿参数的MiniCPM,一款云端协同且性能强劲的端侧大模型,相比大厂的千亿参数模型,MiniCPM通过高效的算法和数据优化,实现小尺寸的卓越性能,尤其是在多模态能力和成本效益上表现出色。

降本增效,让大家迈向 AGI 的速度快一些。
作者 | 王启隆
责编 | 唐小引
出品 | CSDN(ID:CSDNnews)
当各大厂商都在积极地“卷”大模型参数规模的时候,微软在去年开始宣传起小型语言模型(Small Language Model,简称 SLM)的概念,并放出了一个 2.7B 的 Phi-2 模型。“小模型”+“高性能”,究竟可以为 AI 界带来哪些改变呢?

北京时间 2 月 1 日,面壁智能联合清华 NLP 实验室在北京清华科技园科建大厦举行了「旗舰端侧大模型技术沟通会」,发布 2B(2 亿参数)旗舰端侧大模型「面壁 MiniCPM」。这个模型主打云端协同,还被称为“性能小钢炮”,呼吁终端拥抱大模型,并具有“同量级最强多模态能力”。

同量级最强多模态能力
MiniCPM 在技术特性上实现了极致的性能优化与成本控制。面壁智能联合创始人 & CEO 李大海用 MiniCPM 对标来自法国的开源大模型 Mistral-7B,后者曾在去年“以小博大”战胜了 LLaMA-2 13B,甚至被称为「欧洲的 OpenAI」。
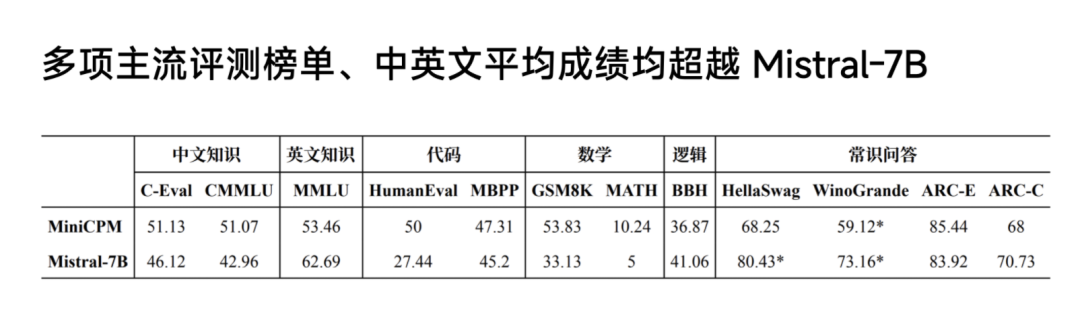
“螳螂捕蝉,黄雀在后”,2B 规模的 MiniCPM 只用 1T 的精选数据,就在多项主流评测榜单上的平均成绩超越了使用 8T 数据的 Mistral-7B。
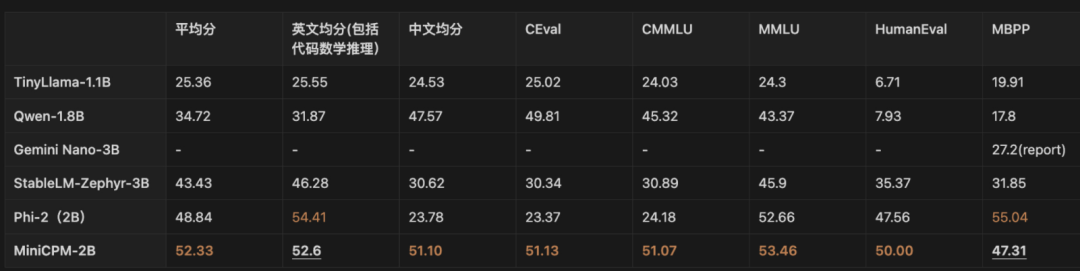
 此外,对阵文首提到的 Phi-2,自然也是不在下风。MiniCPM 甚至还能与更大规模的模型掰手腕,越级比肩 13B、30B 乃至 40B 参数规模的模型。在最接近用户体验的评测榜单「MT-Bench」上面,MiniCPM 取得了 7 分的成绩,用“小身材”逼近了 ChatGPT-4-turbo 的 9 分。
此外,对阵文首提到的 Phi-2,自然也是不在下风。MiniCPM 甚至还能与更大规模的模型掰手腕,越级比肩 13B、30B 乃至 40B 参数规模的模型。在最接近用户体验的评测榜单「MT-Bench」上面,MiniCPM 取得了 7 分的成绩,用“小身材”逼近了 ChatGPT-4-turbo 的 9 分。

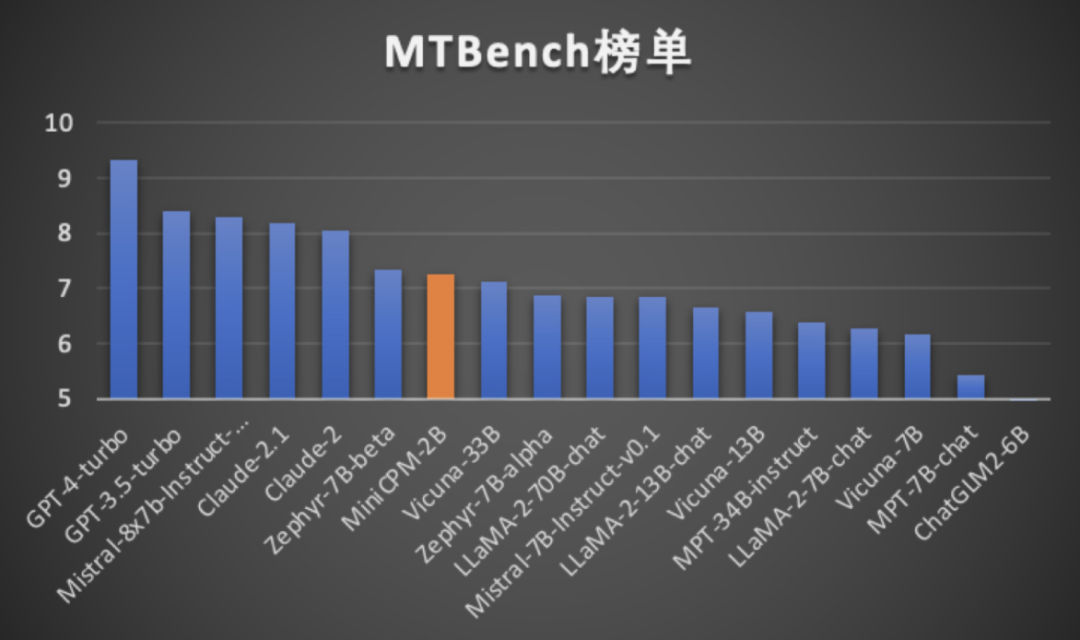

以小博大!
李大海将五道口比喻为“大模型的 Valley(硅谷)”,这个道口曾经修建了中国的第一条铁路——京张铁路,后来又变成了高校林立、名企坐落的“宇宙中心”。如今的五道口是全中国大模型公司最密集的地区:面壁、智源、智谱、百川、深言、硅基流动、无问芯穹、月之暗面……这些在国产大模型圈耳熟能详的名字,已经是五道口文化烙印的一部分。
源于清华 NLP 实验室,面壁智能是在中国率先开展大模型研究的团队,于 2018 年就发布了全球首个基于知识指导的预训练模型 ERNIE。2020 年至 2023 年间,面壁智能在大模型领域取得了一系列重要进展,包括悟道大模型首发、OpenBMB 开源社区建立、公司化运作、两轮融资、发布系列 Agent 研究框架如 AgentVerse、ChatDev、XAgent 等。
舞台已经布置完毕。为了实现 Agent,面壁选择了终端大模型这条路。

端侧大模型是指那些经过训练能够在用户设备终端(如智能手机、平板电脑、物联网设备等)本地运行的人工智能模型,尤其是指那些参数规模较大、具备复杂任务处理能力的模型。2023 年,华为、小米、vivo、苹果和三星等主流手机厂商纷纷入场端侧大模型,在如此庞大竞争压力下,面壁智能 CTO 曾国洋说:“这证明了面壁智能的方向是正确的。”
不同于大厂们砸钱卷的千亿参数模型,“小尺寸”是模型技术的“极限竞技场”。随着深度学习和大模型技术的发展,模型的参数量通常与其性能和泛化能力直接相关。大型语言模型如 GPT 等,凭借数百亿甚至数千亿级别的参数规模,在许多自然语言处理任务上表现出优越的性能。
然而,将如此庞大的模型应用于移动设备、嵌入式系统以及其他资源受限的端侧设备上,则面临巨大的挑战,如内存占用过高、计算需求过大、功耗过高等问题。怎么把这么厉害的模型装在我们的手机上?李大海给出了答案:依托面壁智能追求的「高效」技术路线,打通算力、算法、数据。
算力:全流程高效 infra,10 倍推理加速,90% 成本降低。
基础设施(infra)是大模型创业的“护城河”。面壁的全流程优化加速工具套件平台「面壁 ModelForce」,通过构建全流程高效的 infra,针对大模型训练和推理过程中的计算瓶颈进行深度优化,包括但不限于分布式计算架构的设计、通信优化、硬件适配与调度策略的改进等措施。

算法:「模型风洞」以小见大,寻找高效模型训练配置,实现模型能力快速形成。
算法论是面壁智能在过去三年实践中总结出来的训练方法论,把大模型变成了实验科学,并目标变为理论科学。经过上千次的模型沙盒实验,面壁探索出了最优的配制,所有尺寸的模型可以通过最优的超参数的配制,保证训练任意大小的模型取得最好的效果。
最终总结出一种模拟和优化模型训练过程的方法,在小模型上预测较大模型的性能表现,并设计出大小模型之间可以共享参数的方案。这样既能维持模型性能的持续最优状态,又能高效扩展模型训练策略,适合不同规模模型的快速迭代。

数据:现代化数据工厂,形成从数据治理到多维评测的闭环牵引模型版本快速迭代。
围绕大模型能力建设的算力、算法、数据三大要素,形成训练高效、推理高效、成长高效的技术方案,在有限资源下实现「变道超车」。

小钢炮都能做些啥?
面壁智能在发布会上的一项重大宣布便是首次在端侧部署多模态,具有强大的跨模态理解和处理能力,“能说会道,还可以写代码”。
MiniCPM 还被训练成首个能在终端设备(端侧)上运行的版本 MiniCPM-V,提高了在信号较差环境下的实用性,并保证了快速的响应速度和流畅的用户体验。

其关键特点是成本效益极高,面壁智能通过技术创新显著降低了端侧模型的推理成本,使其能在 CPU 上实现低成本、低延迟的推理。在降低成本的同时,MiniCPM 仍然保持着出色的推理速度和准确性,成为端侧模型能效比的典范,尤其适用于需要全天候响应、网络条件不佳的应用场景。
李大海举了一个极端的例子,那就是拍摄爆款纪录片《荒野求生》的“贝爷”贝尔·格里尔斯(Bear Grylls)。试想一下,我们如果和贝爷一样去野外露营,遇到紧急情况该怎么办?李大海做了一个现场演示:
在端侧应用中,MiniCPM 可以用于解决各种紧急或复杂场景的问题,例如识别野外蘑菇是否有毒,指导应对帐篷附近的蛇等。模型在移动端实现了高效的推理速度,每秒大约处理 7 个Tokens,并且注重推理成本的降低,力求在保持高性能的同时实现经济效益,比如通过 CPU 推理降低成本至云端模型的 1%,大大降低了大规模部署时的经济门槛。
成本到底有多低?在端上模型中,面壁智能让推理成本实现断崖式下跌,甚至可以实现 CPU 推理,成本更低。李大海给出了一个简单的算术题为例:

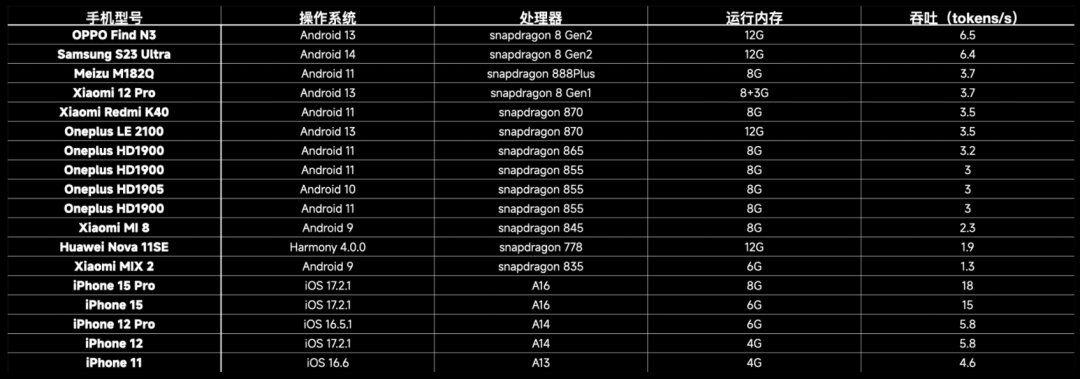
目前,面壁智能已经把模型在以下机型上进行了真实的落地,如果有混“机圈”的朋友,应该会很熟悉表中的“一代神 U”骁龙 835。虽然吞吐量不太行,但看样子 835 还能战到 AI 时代。
面壁团队也在发布日官宣将 MiniCPM 的“全家桶”——MiniCPM-SFT / DPOMiniCPM-V & MiniCPM-SFT / DPO-int4 进行开源,分享其技术和训练经验,以推动整个行业的共同发展,拯救算力焦虑,让「消费级显卡也能流畅玩转大模型,压缩 75% 性能基本无损耗,跑通国际主流手机品牌与终端 CPU 芯片,发布两年以上也无压力」。

开源地址(内含技术报告):
MiniCPM GitHub:https://github.com/OpenBMB/MiniCPM
OmniLMM GitHub:https://github.com/OpenBMB/OmniLMM

问答
CSDN:智能手机搭载的终端大模型是否具备自我学习与更新的能力?如果不具备这种自我迭代的能力,那么这类模型如何保持其知识库的时效性和准确性,是否需要定期通过云端或者其他方式获取并同步最新的数据和信息?
胡声鼎(清华大学计算机系博士,面壁智能科研团队成员):模型更新的技术是非常复杂的技术,和训练模型的情况不一样。当我们使用特别小的模型训练时,还存在不稳定的问题,所以这确实是待研究的话题。
现在有知识编辑或参数高效微调等方案可以解决这个问题。而目前可以应用的方法是参数高效微调,例如,在白天使用手机端侧大模型进行交互,那晚上休息给手机充电的时候就可以进行高效微调,实现后台自我更新。
但是,现在高效微调的效果可能不是那么令人满意。这方面遇到的问题在于要不要让端侧模型和云端协同,而我认为是需要的。所以我们也可以接上一些外部知识,让它具备更强大的能力。
CSDN:本次发布会的关键词之一是「云端协同」,MiniCPM 是如何根据任务需求以及不同终端设备的资源来分配云端之间的技术任务的?
韩旭(清华大学计算机系博士后,面壁智能首席研究员):云端协同的意思是在端侧部署小规模的模型,在云上部署大规模的模型,端侧算力少,云侧算力大。云端协同是一个工作模式,有很多实现方法,比如能本地接近的就本地接近,不能端侧本地解决的就传到云上用大算力接近。
MiniCPM 是一个能在端侧部署使用的小尺寸的大模型,这并不是说 MiniCPM 本身是一套云端协同技术,只是 MiniCPM 能在云端协同的框架内胜任端侧模型。
CSDN:MiniCPM 的多模态能力是如何实现的?
韩旭:我们现在的多模态模型采用了类似 GPT-4V 的技术,有语言模块和视觉模块,两个模块协同处理图文数据。关于这个技术,我们已经发了今年 ICLR 的论文,被收录为 spotlight 了。
CSDN:看完“荒野求生”的例子,我感觉对于程序员而言,联网还是比较重要的,哪怕只是挂个 GitHub 也需要实时联网。那么终端大模型相比较传统大模型,对程序员而言最重要的提升或者说功能会是什么呢?终端大模型能为程序员带来哪些帮助?
韩旭:终端大模型并不是说不联网,而是用每个人手头上有的资源就能计算部署。加入云服务器,一次性只能服务 10 个人,假设有 100 个人请求服务的话,就必须要排队。而如果一名用户手头资源就够用的话,用终端大模型部署肯定会更便利。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











