







【CSDN 编者按】在 AI 技术快速发展的今天,计算硬件的进步正成为推动 AI 应用落地的关键力量之一。英特尔最新芯片搭载的神经处理单元(NPU),以其高效的 AI 任务处理能力,为开发者带来了全新的性能体验。相较于传统CPU,NPU 可以显著提升 AI 模型的运行速度,但具体能提升到什么程度呢?为了解答这个问题,本文作者通过实际测试和深入解析,最终确认:NPU 大概能带来 15 倍的性能提升。
作者 | Sebastian Montabone 翻译 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
目前,英特尔最新的芯片配备了一个神经处理单元(NPU),其设计目标是比普通 CPU 更高效地处理 AI 和机器学习任务。理论上来说,NPU 可以更快地运行 AI 工作负载,并且功耗更低——这非常好,因为你可以将 CPU 释放出来执行其他通用任务。
但我想知道,与 CPU 相比,NPU 在运行模型时到底能快多少。根据我的测试结果:NPU 大概能带来 15 倍的性能提升,这实在是令人惊讶。
如果你正在考虑购买一款带有 NPU 的边缘设备,我可以推荐 Khadas Mind 2 迷你 PC。它非常小巧,但性能强大,还配备了一个小型电池作为 UPS(不间断电源),你可以随意更换 USB 电源而不会断电。好的,现在让我们看看我是如何得出标题中提到的那个数字的。
在实时计算机视觉中,吞吐量和延迟是影响系统效率和响应速度的两个基本性能指标。吞吐量指的是每秒处理的帧数(FPS),决定了系统在一段时间内能处理多少数据,这基本上就是你问“处理这段视频需要多长时间”时所指的内容。另一方面,延迟是指从输入到输出处理单帧所需的时间,它会影响系统对新数据的响应速度。在增强现实和自动驾驶等实时应用中,低延迟至关重要。当你操作一个系统时,如果感觉它“卡顿”,那就是因为它的延迟很高。通常来说,一般人都希望保持低延迟和高吞吐量。
接下来,假设你已经在系统上安装了 OpenVINO,且设备中有一个带有 NPU 的英特尔芯片。如果你自己也不太确定,可以通过运行以下命令快速检查这两点是否属实:
import openvino as ov
core = ov.Core()
core.available_devices你应该会看到类似 ['CPU', 'GPU', 'NPU'] 的回复,这些是 OpenVINO 中可用的设备。如果你没有看到你的设备,请确保你正确安装了驱动程序,并在继续之前进行故障排除。
接下来,我们需要一个模型。我将使用 ResNet-50,这是最著名的卷积神经网络架构之一,由微软在 2015 年的论文《Deep Residual Learning for Image Recognition》中首次被提出。该模型在 ImageNet-1K 数据集上以 224×224 的分辨率进行了训练,这意味着你可以输入一张该尺寸的图像,模型将预测 1000 个不同物体类别的概率。
经过 OpenVINO 优化的 ResNet-50,可以前往这个地址下载:https://huggingface.co/katuni4ka/resnet50_fp16/tree/main。只需下载这两个文件:resnet50_fp16.xml 和 resnet50_fp16.bin,并将它们放在你的工作文件夹中。如果你想尝试其他模型,也可以这样做。请确保对你的模型运行 OpenVINO 优化器以获得最佳性能。我还将用 OpenCV 来加载和调整图像大小,因此我们先安装它,并确保 numpy 也已安装:
pip install opencv-python numpy现在,让我们用这个模型对图像进行分类。将以下代码写入一个文件并保存为 classify.py:
import openvino as ov
import numpy as np
import cv2
def classify_image():
# Step 1: Load OpenVINO model
core = ov.Core()
model = core.read_model("resnet50_fp16.xml")
compiled_model = core.compile_model(model, "CPU") # Use "NPU" if available
# Step 2: Get input tensor details
input_layer = compiled_model.input(0)
input_shape = input_layer.shape # Should be (1, 3, 224, 224)
# Step 3: Load and preprocess image
image = cv2.imread("input.jpg")
image = cv2.resize(image, (224, 224)) # Resize to match model input
image = image[:, :, ::-1] # Convert BGR to RGB (OpenCV loads as BGR)
image = image.astype(np.float32) / 255.0 # Normalise to [0,1]
image = np.transpose(image, (2, 0, 1)) # HWC to CHW
image = np.expand_dims(image, axis=0) # Add batch dimension
# Step 4: Run the inference
output = compiled_model(image)[compiled_model.output(0)]
# Step 5: Process the results
top_class = np.argmax(output) # Get class index
# Load ImageNet labels (remember to download the file)
imagenet_labels = np.array([line.strip() for line in open("imagenet_classes.txt").readlines()])
# Display result
print(f"Predicted Class: {imagenet_labels[top_class]}")
if __name__ == "__main__":
classify_image()确保在同一文件夹中有以下文件:classify.py、imagenet_classes.txt、resnet50_fp16.xml 和 resnet50_fp16.bin。然后添加任何图像并将其重命名为 input.jpg,之后只需调用脚本:
python classify.py你应该能得到正确的预测类别,就像这样:

现在我们已经确认模型在 OpenVINO 上可以正常工作,接下来我们可以使用一个方便的工具——benchmark_app,来对不同设备上的模型性能进行基准测试。这个工具可以帮助你快速检查不同设备在运行不同模型时的性能表现。你可以通过以下命令调用它:
benchmark_app -m MODEL -d DEVICE -hint HINT为了进行全面的性能对比,我运行了以下四条命令:
benchmark_app -m "resnet50_fp16.xml" -d CPU -hint latency
benchmark_app -m "resnet50_fp16.xml" -d CPU -hint throughput
benchmark_app -m "resnet50_fp16.xml" -d NPU -hint latency
benchmark_app -m "resnet50_fp16.xml" -d NPU -hint throughput以下是测试结果:
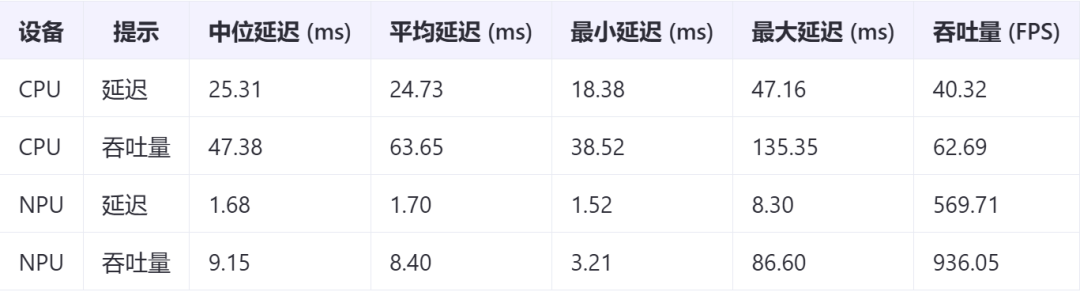
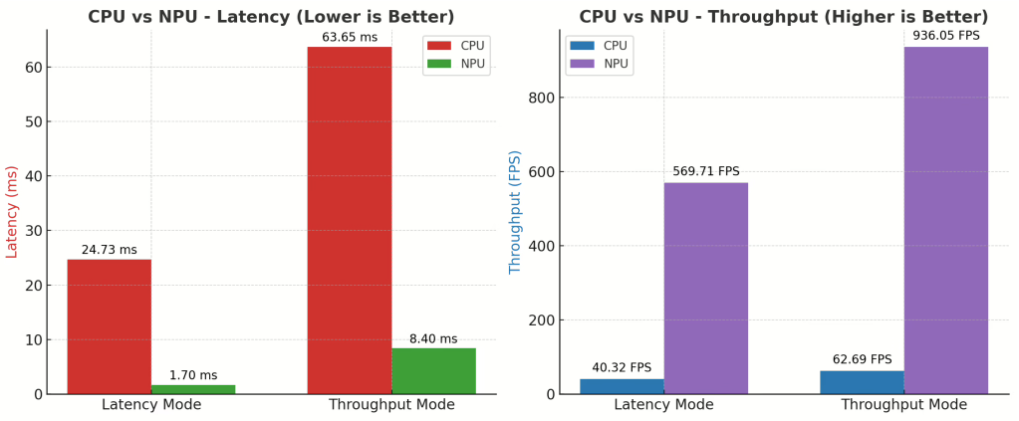
关键结论:
(1)在延迟模式下,NPU 的平均延迟为 1.70ms,相比 CPU 的 24.73ms,性能提升了约 15 倍。
(2)在吞吐量模式下,NPU达到了 936.05 FPS,相比 CPU 的 62.69 FPS,性能提升了约 15 倍。
这些结果清楚地表明,在延迟和吞吐量方面,英特尔的 NPU 相比 CPU 都有显著的性能提升,特别是在这个特定的 ResNet-50 模型中,性能提升了大约 15 倍。
原文链接:https://www.samontab.com/web/2025/02/from-cpu-to-npu-the-secret-to-15x-faster-ai-on-intels-latest-chips/
推荐阅读:
▶从 DeepSeek R1 看未来:揭秘爆火 AI 模型背后的技术原理,探索 AI 的下一大步
▶延续Win10三年需付超3000元!微软彻底封堵:删除绕过Win11系统要求教程、将第三方工具标记为恶意软件
▶ChatGPT搜索功能全面开放,无需账号即可体验;美媒称DeepSeek已无法被封杀;谷歌取消一系列多元化招聘目标 | 极客头条
DeepSeek 到底做了什么?所谓的“DeepSeek时刻”或者“国运级创新”到底意味着什么?今晚 8:00-9:30,CSDN 视频号推出“DeepSeek 暨 AI 进化论十日谈”系列第一讲精彩为您呈现,欢迎预约关注!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











