










DeepSeek 推出的 R1 模型热度持续高企,在春节第一波引发股市震荡、登顶全球 App Store 免费下载榜之后,DeepSeek 在继续引发连锁反应:美国 AI 搜索公司 Perplexity 宣布支持 R1 模型,亚马逊、微软、谷歌等科技巨头亦将其纳入云平台。热潮从中国蔓延至美国,再反向影响国内市场。现在,全民都在关注并尝试使用,字节和阿里云大模型大幅降价,百度两款主力大模型宣布免费,各家大厂纷纷接入 DeepSeek 服务。这一现象标志着 AI 大模型竞争进入新阶段:低价化、开源化与工程化成为关键词。
Gartner 高级研究总监 Mike Fang 对媒体分享了 DeepSeek 的核心,核心优势在于:
- 研究导向模式:不追求短期盈利,专注算法优化与工程效率;
- 技术突破:在硬件受限环境下,通过混合精度计算、模型蒸馏等技术提升性能;
- 开源策略:以低成本推理模型降低企业应用门槛,推动生态适配。
DeepSeek 引爆热潮的背后:低价、开源
Gartner 高级研究总监 Mike Fang 梳理总结了 DeepSeek 从成立到火爆的一系列重要的节点。DeepSeek 自 2023 年成立以来,以“低价+高性能”策略迅速抢占市场。其 V2 模型定价仅为 GPT-4 Turbo 的 1/75,直接引发行业价格战。Gartner 预测,到 2027 年,生成式 AI 的 API 调用成本或降至当前的 1%,年均降幅达 90%。
尽管 R1 尚未超越 OpenAI 等顶尖闭源模型,但其在 Lymsys 全球性能榜单中已跻身前三,且凭借开源属性独树一帜。其“思维链”能力与 APP 端创新(结合搜索与深度推理)进一步拓展应用场景。R1 带动国内芯片厂商、开发平台加速适配,推动自主研发生态。开源策略亦为中小企业提供试错机会,催生“AI 路由”“模型可组装”等新架构需求。
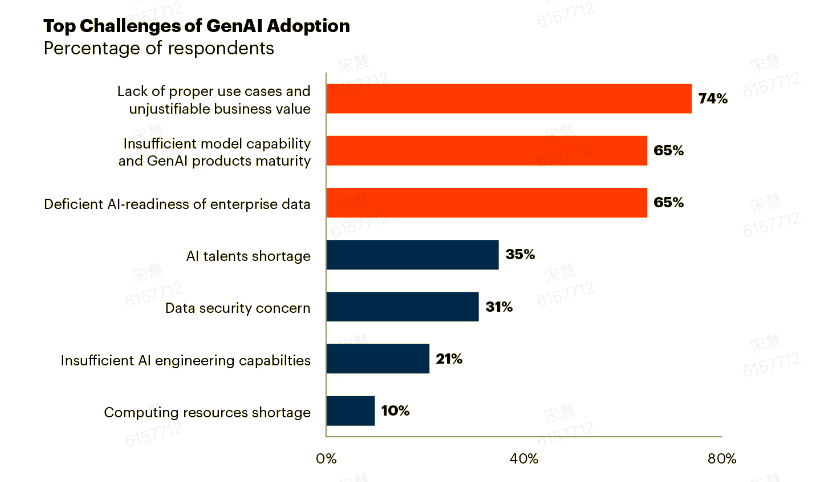
不过,Gartner 调研显示,中国企业生成式 AI 生产落地率不足 10%,主要受限于场景缺失,缺乏明确业务用例;AI 系统存在数据瓶颈,企业的非结构化数据治理困难;大模型仍存在工程化门槛,模型部署与运维成本高。因此,Gartner 建议企业现阶段可以多模型协同,结合大模型与小模型,通过 AI 网关动态适配场景。同时,强化数据标注与元数据管理,以及建立伦理审查与风险管控体系,平衡效率与责任。
大模型开源闭源之争,更需要关注商业化和数据
DeepSeek 的爆火再次印证了业界对模型开源的期望。不过,目前 DeepSeek 并未有具体商业落地计划,而是以研究驱动。DeepSeek 的开源路径将如何演进,值得关注。另外,开源模型的商业化探索,还有非常大的尝试空间。大模型的开源与传统软件开源不同,例如 DeepSeek 仅开源其模型权重,并没有开源数据,因此对于数据的技术发展还有更大的想象空间。
对于 DeepSeek 给全球科技格局带来的影响和变化,Mike Fang 表示,全球科技厂商正积极拥抱以成本优化为核心的 AI 技术策略。对依赖顶尖模型的厂商而言,DeepSeek R1 等低成本方案的普及显著降低了算力与模型调用成本,驱动其加速技术迁移与场景落地。与此同时,开源社区迎来新一轮繁荣期,技术创新与协作生态的扩展催生出新趋势,例如多模型动态适配架构(AI 路由)的兴起,进一步推动技术普惠化。更为关键的是,中国 AI 产业的快速崛起正在打破“美国单极主导”的固有认知——从算法突破到硬件适配,从自主生态构建到全球化布局,中国已成为全球AI研发与创新的核心参与者。这一趋势不仅重塑了技术竞争格局,更预示着未来全球AI发展将呈现多元化、多极化的新图景。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











