






某三甲医院信息中心最近接到一项特殊任务——部署DeepSeek大模型用于智能诊疗系统。当工程师们打算按惯例选择英伟达H20加速卡时,测试结果却让所有人惊愕:在长文本医疗报告处理场景下,系统吞吐量在达到某个临界点后竟不再增长。更令人困惑的是,增加集群规模后性能提升微乎其微,这就像给汽车加油却不见速度提升。
这个真实的“急诊病例”,揭开了大模型技术变革浪潮下硬件适配的深层矛盾。
DeepSeek引发的范式革命:从“全科医生”到“专家会诊”
推理模型的技术代际跃迁
GPT-4.5又贵又蠢的笑柄证实了大模型的未来必属推理,DeepSeek省卡好用的实践则开启了推理模型的范式革命。
如果说传统稠密模型是“全科医生”,MoE架构的DeepSeek则实现了“专家会诊”的质变。MoE核心创新在于动态专家路由机制——每个输入输入的“小片段”(token),都能聪明地找到最合适的专家网络处理。这种架构革新使得模型在保持参数规模可控的同时,推理质量实现指数级提升。DeepSeek V3仅用1/8的激活参数就达到GPT-4o的智能水平,就像用一把小巧的瑞士军刀,完成原本需要重型机械才能干的活儿。
开源生态的格局重构
DeepSeek的开源策略如同在AI领域投下“技术民主化”的核弹。当Llama 3.1等传统架构还在比拼参数规模时,DeepSeek-R1已实现6710亿级参数的MoE架构开源,这直接导致行业技术路线发生根本性转向。而后与之配套的AI Infra全面开源,更是起到了“车门焊死”的效果。不论国内外知名的公有云平台,还是已经自研大模型的大厂,都已经把自家应用接入DeepSeek-R1当作默认选项。
MoE架构的算力新范式:当“专家会诊”遇见硬件现实
动态路由的蝴蝶效应
MoE的动态专家选择机制就像随时重组的手术团队:每个token处理都需要实时调度不同专家网络。这种动态性对硬件提出三重挑战:
- 计算波动性:专家激活模式的不确定性导致算力需求剧烈波动(波动幅度可达300%);
- 通信风暴:专家分布在多卡时,每层网络都需要跨卡通信(128卡集群单次前向传播产生超过5TB数据交换);
- 显存过山车:不同专家组合的显存占用差异显著(实测波动范围在32GB-72GB之间)。
长序列推理的显存困局
医疗文本、法律文书等场景的序列长度普遍超过8K,这对显存带宽提出极限挑战。以处理16K序列为例:
- 传统稠密模型需要连续显存访问带宽4TB/s;
- MoE架构因动态路由引入的随机访问模式,等效带宽需求暴增至6.8TB/s;
- H20的4.0TB/s带宽此时就像四车道高速突遇八车道车流,必然引发严重拥堵。
H20的“中年危机”:架构性缺陷深度剖析
算力密度的先天不足
H20的FP8算力(296 TFLOPS)仅为H100的15%,这个设计在稠密模型时代尚可应对,但在MoE场景下犹如用家用轿车跑F1赛道。关键瓶颈在于:
- 计算单元利用率:动态路由导致SM单元平均利用率不足40%;
- 指令流水线阻塞:条件分支预测错误率高达32%(H100仅为8%);
- 张量核心闲置:稀疏计算模式下,Tensor Core有效使用率仅55%。
集群部署的“伪高吞吐”陷阱
当EP(专家并行)规模超过32时,H20集群出现明显的性能塌缩:
- 通信墙:每增加1倍EP规模,有效算力仅提升18%(理想应为线性增长);
- 显存墙:16K序列处理时,显存带宽利用率达98%,成为绝对瓶颈;
- 扩展悖论:128卡集群在16K/32BS场景下,吞吐量反而比64卡下降7%。
如图是采用128卡、EP规模128时,在序列长度分别为2k/4k/8k/12k/16k的场景下,DeepSeek V3吞吐和Batch Size关系的实测结果。
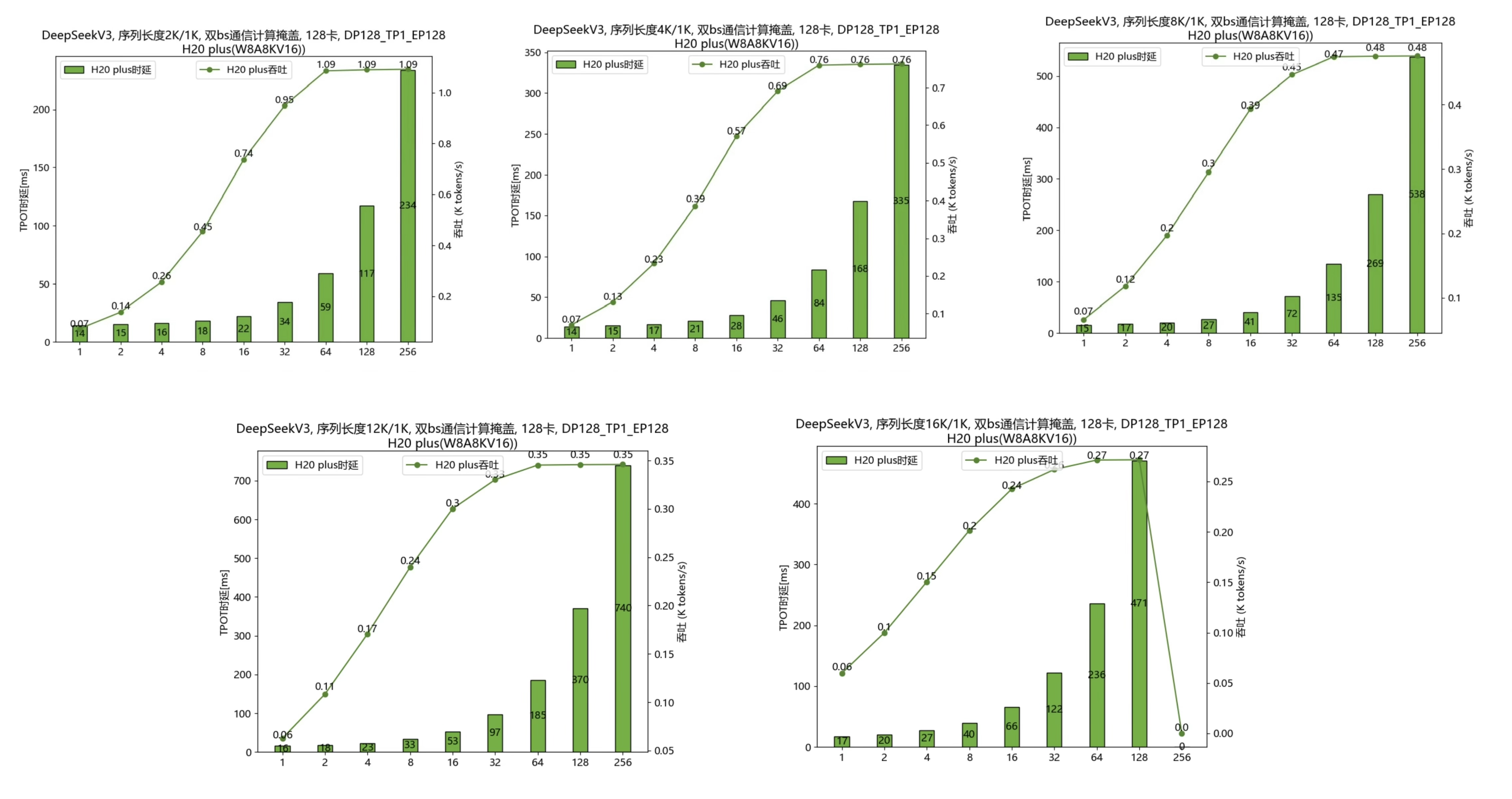
可以看到,大EP场景下,随着Batch Size增加会达到H20的算力bound,增大batch,时延呈等比例增长,然而吞吐无法继续提升(2k,64bs;16k,32bs)。
更令人无奈的是,随着序列长度增大,算力bound的拐点会提前,由2k的64bs,提前到16k的32bs。
动态负载的“资源黑洞”
MoE的动态特性导致显存管理面临“三难困境”:
- 预分配浪费:按峰值需求预留显存,利用率不足50%;
- 动态分配延迟:实时分配引入高达30%的时间开销;
- 碎片化损耗:专家网络交替加载产生显存碎片,可用空间减少25%。
因此,我们可以明确,H20在稠密模型推理场景表现突出有其历史原因,但在大EP场景下,固有架构的算力瓶颈已经暴露无遗,自然无法胜任DeepSeek推理的最佳拍档。
破局之道:推理系统的进化之路
技术管理者需要建立“模型驱动”的硬件选型框架,从算力密度评估、通信拓扑适配、显存架构创新三个方面来考量,刷新推理系统硬件选型的方法论。
结合DeepSeek开源分享,MoE专属优化三原则如下:
- 通信计算流水线化:将All-to-All通信与专家计算深度交织,实测可提升23%吞吐;
- 稀疏计算硬件加速:采用结构化稀疏编码,使计算效率提升至稠密模式的82%;
- 动态负载预测:基于LSTM构建专家激活预测模型,预加载准确率达89%。
同时,模型-硬件协同设计范式也是必然的选择,仍然是DeepSeek官方适配方案给出的启示:
- 专家分组策略:将相关性强的专家部署在同卡,减少63%跨卡通信;
- 混合精度路由:用FP16计算路由决策,FP8执行专家网络;
- 序列分块调度:将长序列拆分为4K块进行流水处理,时延降低41%。
终章:推理芯片的“新王登基”
在这场由DeepSeek引发的技术革命中,H20的退场不是终点而是新起点。智能算力市场正在经历从“通用计算”到“架构专用”的深刻变革。技术管理者需要认识到:当EP规模越来越大时,H20代表的旧秩序已经崩塌,可重构计算架构将成为MoE场景的必备选项,而开源模型与硬件协同优化已成必然趋势。
在这场算力范式迁移中,唯有深刻理解“模型定义硬件”的新规则,才能在AI竞赛的下半场赢得先机。H20的谢幕,恰是新一代推理架构登场的序曲。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











