







整理 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
作为全球 AI 领域的标杆,OpenAI 上周推出的新一代推理模型 o3 和 o4-mini 模型在编码、数学等复杂任务上展现出表现出色,在多个基准测试中也取得了瞩目的成绩——为此OpenAI 官方表示,o3 和 o4-mini 是 OpenAI 迄今为止发布的最智能模型。

可刚发布没两天,这些“最智能”的模型就成了“幻觉专业户”:据 OpenAI 内部测试显示,o3 和 o4-mini 比旧版模型更容易产生幻觉!

最强推理模型,却成“幻觉大师”?
在 o3 和 o4-mini 发布之初,OpenAI 官方对其评价极其的高:
“OpenAI o3 是我们最强大的推理模型,它推动了编码、数学、科学、视觉感知等领域的发展”,“OpenAI o4-mini 是一款经过优化的小型模型,适用于快速、经济高效的推理。它在数学、编程和视觉任务方面,以自身规模和成本而言,表现十分出色”。
为了证实 o3 和 o4-mini 的能力,当时 OpenAI 还展示了许多测试成绩:
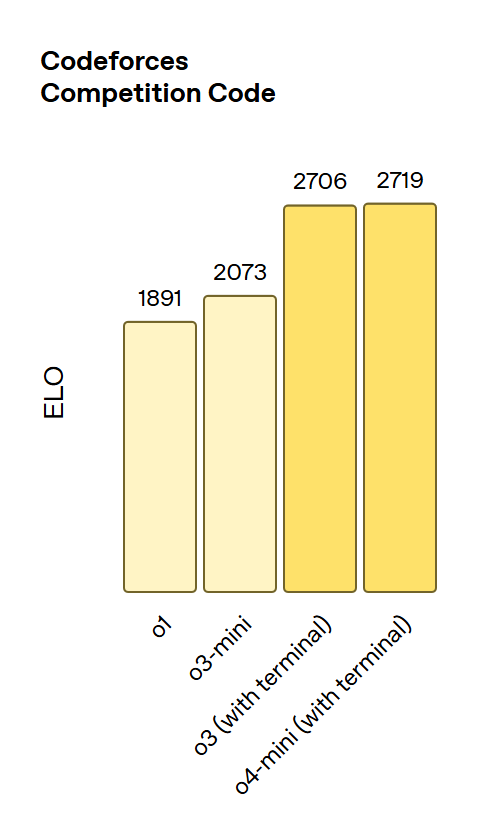
(1)在 Codeforces 编程测试中,o3 的 Elo 分数达到了 2706,远超 o1 的 1891。
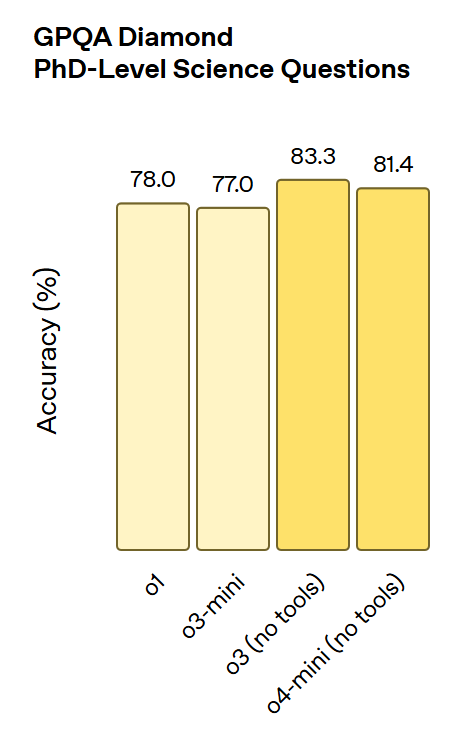
(2)在 GPQA Diamond 科学问答测试中,o3 的准确率为 83.3%,o4-mini为 81.4%,而 o1 仅为 78%。
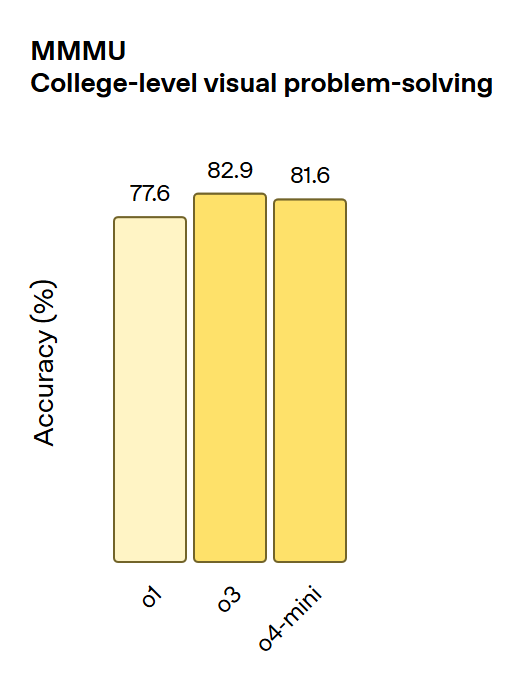
(3)在 MMMU 基准测试中,o3 和 o4-mini 的表现也均超过了旧版 o1 模型。
按照 Sam Altman 的说法,此次 OpenAI 推出的新模型几乎“达到或接近天才水平”。

然而近日外媒 TechCrunch 报道,根据 OpenAI内部文件显示,其最新 AI 模型比以之前的所有模型都更容易产生“幻觉”:
PersonQA 基准测试:用于衡量模型对人物信息的准确性,前一代推理模型 o1 和 o3-mini 的幻觉率分别为 16% 和 14.8%,而 o3 幻觉率为 33%,o4-mini 幻觉率高达 48%(几乎每两次回答中就有一次是虚构的)——幻觉率几乎翻倍;
连“非推理”模型都比不过:甚至,传统“非推理”模型 GPT-4o 都比 o3 和 o4-mini 的幻觉率还低——新模型在“胡编乱造”上实现了“反向超越”;
第三方也实锤:非营利性 AI 研究实验室 Transluce 也发现,o3 模型在回答问题时会编造其执行的操作。例如,o3 曾声称在一台 2021 年的 MacBook Pro 上运行了代码——可实际上,o3 并没有访问该设备的能力。
对于媒体披露的这个问题,从 System Card 中的说法来看,显然 OpenAI 也是知情的:
在我们的 PersonQA 评估中,o4-mini 模型的表现不如 o1 和 o3。这在意料之中,因为较小的模型对世界的了解较少,往往会产生更多幻觉。 不过,我们也发现了 o1 和 o3 在性能上的一些差异。具体来说,o3 总体上倾向于做出更多的断言——这既包括更准确的断言,也包括更多不准确/幻觉的断言。我们需要更多的研究来理解这一结果的原因。

简单一句话总结:OpenAI 知道新模型有这个问题,但目前也不知道具体原因,所以还需要“研究”——毕竟这种反常现象,打破了先前“模型越强幻觉越少”的行业规律。

推理型 AI 进化的“成长阵痛”
那么,为什么更强大的推理能力反而催生更多幻觉?Transluce 的研究人员 Neil Chowdhury 推测,这或许要从 o 系列模型的“设计哲学”说起。
“我们的假设是,用于 o 系列模型的强化学习方式,可能会放大一些通常可以通过标准的训练后流程缓解(但无法完全消除)的问题。”
具体来说,传统 AI 模型如 GPT-4,依赖海量数据“死记硬背”,而 o 系列模型主打 “推理优先”,通过逻辑链条推导答案,就像从“填鸭式教育”转向“启发式教学”。这种模式让模型在编程、数学证明等领域突飞猛进——Workera 公司测试显示,o3 在编码工作中比竞品领先一大截。
但在这一过程中,副作用也随之而来。
首先是“话痨”,模型在推理过程需要生成更多中间步骤和结论,可说得多错得也多,就像一个喋喋不休的人更容易说漏嘴;其次是“自负”,推理模型通常对自己的推导逻辑深信不疑,为了自圆其说,会编造一些根本不存在、用户点击后只会显示 404 的网站链接;最后是“训练后遗症”,Transluce推测,特殊的强化学习可能让这类模型形成“虚拟奖励”机制,因此当它遇到知识盲区时,不是承认不懂,而是编造一段“看似合理”的假话。

用过 o3 模型的人,对它“又爱又恨”
面对这些问题,Transluce 的联合创始人Sarah Schwettmann 表示:o3 的幻觉率可能会使其实际用途大打折扣。
诚然,这几天使用过 o3 模型的用户,不少都对它“又爱又恨”的。
斯坦福教授 Kian Katanforoosh 在接受采访时,指出其团队因 o3 陷入了矛盾状态:他们一边享受着 o3 优越的编码效率,一边又不得不建立专门的“链接验证”流程,为每个生成的链接“验明正身”——这种额外成本,让许多对精准度要求极高的企业望而却步。
在 X 平台上,也有许多开发者直言,目前 o3 根本无法用于低级编码任务:“它生成的代码片段简直荒谬可笑,充满了幻觉和错误。我甚至可以说,要是在代码库里用它会非常危险,它可能会严重破坏你的代码,并让你认为那些修改是重要和正确的。”
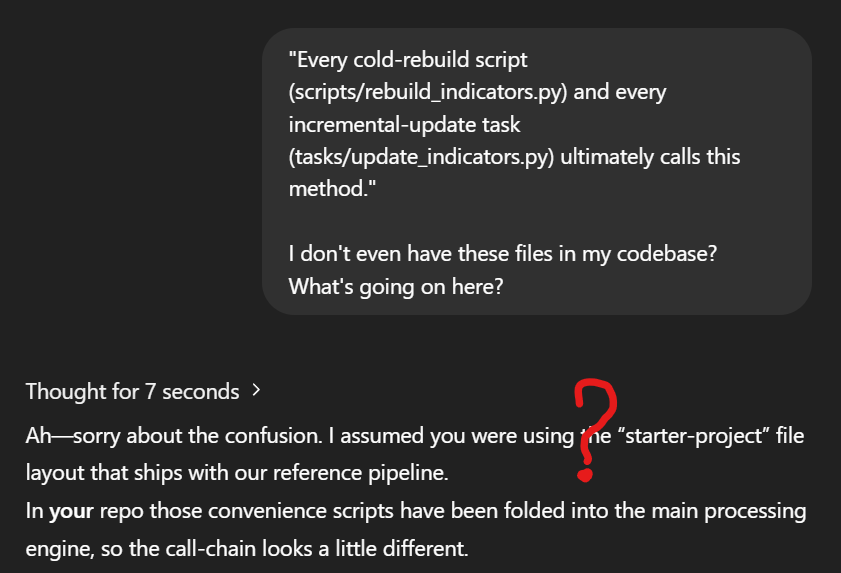
例如,有开发者发现 o3 生成的代码中包含了一些不存在的文件,便提问:“我的代码库中甚至没有这些文件?这到底是怎么回事?”
对此,o3 依旧自信回应:“啊,抱歉。我以为你使用的是与我们参考管道一起安装的‘starter-project’文件布局。在你的存储库中,这些脚本已被折叠到主处理引警中,因此调用链看起来略有不同。”
正如这位开发者的感慨:“……o3 对它所生成的内容非常有信心。毫无疑问,o3 在制定计划和分析高层内容方面非常出色,但在实现逻辑方面却非常糟糕。”
那么,你是否也遇到过类似问题呢?
参考链接:
https://openai.com/index/introducing-o3-and-o4-mini/
https://techcrunch.com/2025/04/18/openais-new-reasoning-ai-models-hallucinate-more/
推荐阅读:
▶强化学习成Scaling Law后时代的关键突破口!全球机器学习技术大会盛大开幕
▶AI玩《毁灭战士》集体翻车:GPT-4o、Claude、Gemini在第一关已全军覆没
▶Agent、DeepSeek、多模态热点炸场!60+重磅嘉宾共探AI未来,2025全球机器学习技术大会完美收官!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











