






在生成式AI应用百花齐放的当下,AI服务器的重要性可谓不言而喻,无论是对于大规模的训练、推理,亦或是RAG等任务,都对其提出了更高的要求。公开数据显示,AI服务器市场规模已经达到了211亿美元,预计2025年达到317.9亿美元,2023-2025年的CAGR为22.7%。
而AI服务器中GPU或AI加速器则扮演着引人注目的角色,其中CPU的作用却往往容易被忽视。那么,一个真正为AI服务器或AI数据中心基础设施设计的出色的CPU,应该是什么样的?
英特尔至强6 性能核处理器,可以说给出了一个正解。
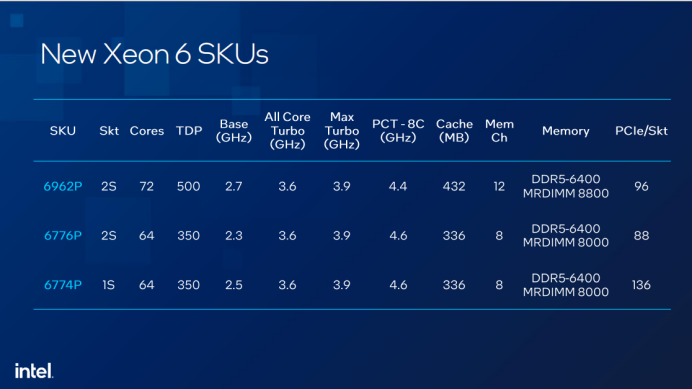
近期,英特尔再发布三款全新至强 6 处理器,其中 6776P 型号被英伟达选为新一代 AI 加速系统 DGX B300 的唯一主控 CPU,幷集成了英特尔创新的Priority Core Turbo(PCT)以及英特尔® Speed Select – 睿频频率(Intel® SST-TF)技术。
那么,作为主控CPU的至强6如何通过架构创新破解AI算力的协同难题的?至强 6 又有哪些技术突破和性能优势?近日,CSDN采访了英特尔技术专家,详细解读了至强6处理器的架构创新。
主控CPU:从算力孤岛到协同架构的必然选择
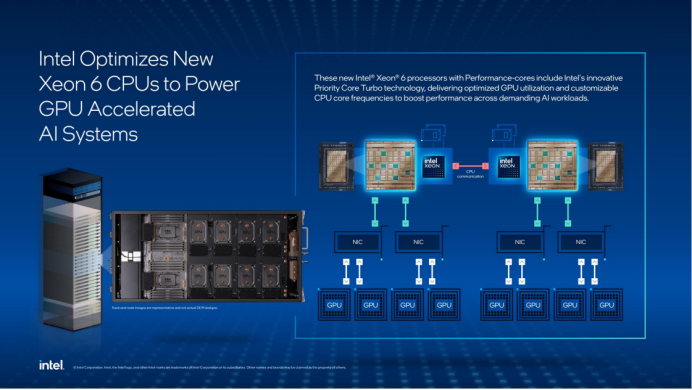
随着生成式AI工作负载复杂度激增,单一GPU架构已难以应对数据预处理、任务调度等多元需求。于是,为了在这些工作负载的性能和总体拥有成本(TCO)之间达到理想的平衡点,一个有效的策略是采用主控 CPU 和独立 AI 加速器来构建 AI 加速系统。
在 AI 加速系统中,主控 CPU 通过提供高效的任务管理和出色的预处理性能来优化处理性能和资源利用率。这两大要素对确保模型训练管线中数据高效供给以及维持独立 AI 处理器的理想运行状态至关重要。
因此,至强6处理器通过PCT技术动态调配核心频率,确保高优先级任务快速响应。其128个核心的性能核处理器设计,有效分担密集型AI任务,显著加速数据向GPU的传输,实现算力资源的优化配置,全面提升AI系统的运行效能。
MLPerf 2024 基准测试显示,至强 6 在 AI 加速系统中的综合性能表现领先业界,其 192 条 PCIe 5.0 通道(较上一代提升 20%)为 GPU 提供数据传输 "高速公路",而 MRDIMM 内存技术则带来了30%的带宽提升,可大幅加速数据从内存到处理单元的传输效率。

对此,英特尔技术专家表示:“至强6的架构创新不仅提升了单节点性能,还通过优化多节点协同,确保了高效的数据流通和任务调度,进而优化了整个AI系统的端到端性能。”而这也是英伟达选择至强6作为DGX B300主控CPU的原因所在。
据介绍,DGX B300 选择至强 6776P 作为主控 CPU,并非简单硬件集成,而是从架构层面对 AI 工作负载的深度优化。技术专家透露:"我们与英伟达联合验证了 UPI 互连、内存配置等关键环节,确保双路至强 6776P 与 8 个 GPU 的协同效率。" 该配置中,至强 6 的 Priority Core Turbo(PCT)技术允许 8 个核心动态超频至 4.6GHz,较传统 Max Turbo 提升 0.7GHz,使 GPU 数据供给速度提升 35%,完美适配 MoE 模型中专家层的数据交互需求。
当然,作为主控CPU的至强6并没有忘记自己的本份,把存力与算力的硬指标优势结合起来,转化成真正的优势,才是它被看好的底气。在算力方面,除了更多内核,它还有内置加速器与指令集更新带来的加成。
主攻AI加速的英特尔® 高级矩阵扩展(Intel® AMX)新增对FP16数据类型的支持,现已全面覆盖 int8、BF16和FP16数据类型。其在每个内核中的矩阵乘加(MAC)运算速度可达 2048 FLOPS(int8)和1024 FLOPS(BF16/FP16),能大幅提升 AI 推理和训练性能。
在安全方面,英特尔早期的方案为SGX,但从第五代至强开始新增了TDX方案,把CPU和GPU之间的通道也纳入了端到端的硬件加密保护范围,有效防止数据在传输过程中被窃取或篡改,确保AI训练过程的安全性。
如果用一句话总结主控CPU的至强6,那就是“更强通用计算,更优AI加速”。
那么,至强6何以实现如此卓越的性能?据技术专家介绍,核心在于5大技术能力的支撑。
五大技术支柱:至强 6 的 AI 主控实力解析
- PCT 技术:动态超频的精准算力释放
PCT 技术是至强 6 的核心创新点,其设计逻辑颠覆传统 CPU 超频理念。技术专家解释:"传统 Max Turbo 假设一半核心休眠,而 PCT 允许最多 8 个核心动态超频,且不依赖散热系统调整。" 在 DGX B300 中,这一技术使 CPU 能根据 GPU 需求动态分配算力 —— 当 GPU 需要数据时,8 个 PCT 核心以 4.6GHz 高频处理 I/O 任务,其他核心保持基础频率,实现性能与功耗的平衡。这种动态调度机制,打破了传统 CPU"全核同频" 的局限,为 AI 加速系统提供了更灵活的算力分配方案。
针对 PCT 技术与传统超频的差异,技术专家详解:"至强 6 通过 Speed Select 技术(SST)将核心分为高优组与低优组,高优组运行高频,低优组保持基频。" 这种设计不依赖硬件改造,仅通过 BIOS 配置或 SST-TF 工具即可动态调整,使客户能根据工作负载灵活分配算力。
- 内存架构创新:带宽与容量的双重突破
至强6首次引入Multiplexed Rank DIMM(MRDIMM)技术,同时支持每通道2条DIMM,最大内存容量达8TB。MRDIMM不仅提升带宽,还通过2 DPC架构降低单GB成本,这也是英伟达DGX B300选择该技术的重要原因。"此外,至强6支持CXL技术,实现CPU与GPU内存的一致性共享,进一步优化内存利用率。
当被问及 MRDIMM 与 CXL 的应用边界,技术专家指出:"MRDIMM 解决高频带宽需求,CXL 更适合容量扩展。" MRDIMM有更高的内存带宽,内存带宽对AI系统的影响也是取决于具体的工作负载类型。以MoE 模型卸载为例,如果能利用CPU里面的AMX矩阵运算能力,则此时对内存带宽的要求必然更高。因此,内存带宽的实际需求与工作负载密切相关。
- I/O性能跃升:数据流动的高速公路
I/O 性能方面,至强 6 的 192 条 PCIe 5.0 通道构建起高速数据链路。在 DGX B300 中,双路至强 6776P 通过 176 条 PCIe 通道连接 8 个 GPU,配合 AI 感知网络路由技术,大幅降低小包通信延迟,提升整网通信效率。
- RAS 特性:大规模集群的可靠性基石
对于动辄数千节点的 AI 集群,系统可靠性直接影响 TCO。至强 6 的 RAS(可靠性、可用性、可维护性)技术覆盖 CPU、内存、I/O 全子系统。RAS 技术的核心在于 "预防 + 修复" 双重机制:通过实时固件更新预防潜在故障,利用 EDPC 等特性快速修复 I/O 错误。大规模集群中,RAS技术的应用显著提升了系统的稳定性和可维护性,有效降低了宕机风险,确保了数据处理的连续性和高效性。
- 混合负载优化:从预处理到推理的全场景覆盖
至强 6 的 Advanced Matrix Extensions(AMX)新增 FP16 精度支持,可高效处理 MoE 模型的专家层卸载任务。技术专家透露:"这种混合负载能力,使至强 6 既能处理数据预处理,又能承担轻量级推理,为企业提供更灵活的算力分配方案。
简言之,至强 6 的架构设计,正是为了让 CPU 与 GPU 各司其职,共同提升端到端效率。
主控 CPU 定义 AI 加速新范式
综上可以看出,在当前AI应用加速落地、新推理计算范式和合成数据等趋势的推动下,AI算力需求越来越注重推理和复合工作负载。
在这之中GPU或专用加速器固然重要,但CPU作为整个系统的“指挥官”,绝不能成为短板。用户需要的是一个真正兼顾通用计算,以及AI服务器及AI数据中心场景的CPU产品。它不仅能支持广泛的第三方GPU及AI加速器,还能在其中补足GPU或专用加速器覆盖不到或不足的地方,为更多样和复杂的场景提供灵活的算力选择,并增强整个AI平台的稳定性、安全性和扩展性。
英特尔至强 6 处理器以 "AI 加速系统主控 CPU" 的定位,重新定义了算力协同的标准。从 PCT 技术的动态超频到 MRDIMM 的内存革命,从 RAS 特性的可靠性保障到开放生态的灵活适配,至强 6 不仅是一款处理器,更是 AI 基础设施的 "神经中枢"。
可以预测,随着 AI 应用向各行业渗透,至强 6 所代表的 "主控 CPU + 加速器" 架构,将成为企业级 AI 落地的主流范式,推动算力资源从 "粗放式堆砌" 向 "精细化协同" 演进。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











