




编译 | 苏宓
出品 | CSDN(ID:CSDNnews)
三天前,Python 软件基金会(PSF)正式发布了 Python 3.14.0。这是一次里程碑式的更新,带来了多个开发者期待已久的新特性,包括自由线程(支持、子解释器(Subinterpreters)引入、结构化模式匹配增强,以及对异步编程机制的深度优化等。
从功能上看,3.14 的变化可谓诚意十足。但许多开发者最关心的,依然是那句老问题——“它到底有多快?”
为此,软件工程师 Miguel 对新版 Python 进行了一轮非官方性能测试,希望看看这次升级在速度上究竟能带来多大提升。
不过,他也在测试开头就打了“预防针”:
“在我展示结果之前,必须提醒大家,这类基准测试(benchmark)其实很容易产生误导。运行这些测试当然很有趣,但要想仅靠几个简单脚本就准确描绘出像 Python 解释器这样复杂系统的性能全貌,几乎是不可能的。”
Miguel 表示,他设计的测试全部运行纯 Python 代码,刻意避免任何第三方依赖,尤其排除了所有用 C 编写的函数或扩展模块。
这样做的原因很简单:原生 C 代码在不同 Python 版本间的性能变化通常不大,因此加入它们反而会模糊结果。
当然,这样的测试也有明显局限。
现实中的 Python 应用往往是混合体——既包含大量纯 Python 逻辑,也调用 C、C++ 或 Rust 编写的底层模块。
因此,这种“纯 Python 环境”下的基准结果,更像是对解释器性能的“显微镜观察”,并不完全等同于真实场景下的运行表现。
Miguel 也再次强调:
“你可以把这份测试当作一个参考点,但千万别把它当作 Python 性能的最终结论。”
接下来,我们将看看完整的测试。

测试矩阵
这次的基准测试涵盖了一个五维度的测试矩阵,具体如下:
1. 6 个 Python 版本,以及 Pypy、Node.js 和 Rust 的最新版本:
CPython 3.9、3.10、3.11、3.12、3.13、3.14
Pypy 3.11
Node.js 24
Rust 1.90
2. Python 解释器模式(共 3 种):
Standard(标准模式)
JIT(即时编译模式):仅适用于 CPython 3.13 及以上版本
Free-threading(自由线程模式):同样仅适用于 CPython 3.13+
3. 测试脚本(共 2 个):
fibo.py:用于计算斐波那契数列,重点考察递归性能。
bubble.py:使用冒泡排序算法对随机生成的数字列表进行排序,强调迭代操作但不涉及递归。
4. 线程模式(共 2 种):
单线程(Single-threaded)
多线程(4 个独立线程同时运行计算任务)
5. 测试设备(共 2 台):
一台运行 Ubuntu Linux 24.04 的 Framework 笔记本(Intel Core i5 CPU)
一台运行 macOS Sequoia 的 Mac 笔记本(Apple M2 CPU)
你可能会觉得在测试里加入 Node.js 和 Rust 看起来有点奇怪。Miguel 也承认这可能确实有点“跨界”,但他表示,自己将两个 Python 测试脚本应用程序分别移植成了 JavaScript 和 Rust 版本,目的是为了在 Python 生态之外也能得到一组性能参考值,帮助更直观地看清 Python 的表现处于什么水平。

测试脚本
下面是 fibo.py 的主要逻辑:
def fibo(n): if n <= 1: return n else: return fibo(n-1) + fibo(n-2)经过多次实验,Miguel 发现使用这段函数计算第 40 个斐波那契数,在他的两台笔记本上大约需要几秒钟。
因此,后续所有测试结果都基于这个参数设置。
接下来是 bubble.py 中的排序函数:
def bubble(arr): n = len(arr) for i in range(n): for j in range(0, n-i-1): if arr[j] > arr[j+1]: arr[j], arr[j+1] = arr[j+1], arr[j] return arr在这个测试脚本中,Miguel 同样通过多次尝试来确定合适的数组大小,使得整个排序过程能在几秒钟内完成。最终,其选择使用一个包含 1 万个随机生成数字的列表作为测试数据。
需要说明的是,这两个例子并不是高性能代码的示范。如果目标是追求运行速度,还有许多更高效的实现方式。但这次基准测试的目的并非要写出最快的算法,而是要比较不同 Python 解释器执行相同代码的表现差异。
Miguel 解释道,他之所以选用这两个函数,是因为它们在编码风格上形成对比:一个是递归实现(fibo),另一个是迭代实现(bubble),这样能更全面地反映解释器在不同类型代码下的运行特性。
整个基准测试框架会让每个测试函数重复运行三次,并取三次结果的平均值作为最终成绩。
完整的测试脚本及基准测试框架代码已公开在 GitHub 仓库中,感兴趣的小伙伴也可自行查阅:https://github.com/miguelgrinberg/pyspeed。

基准测试 #1:单线程 Fibonacci
接下来来看第一个测试。在这个测试中,Miguel 首先测量了运行 fibo(40) 所需的时间(以秒为单位)。如前所述,每个数据点都是运行三次取平均值。
以下是表格形式的结果数据:
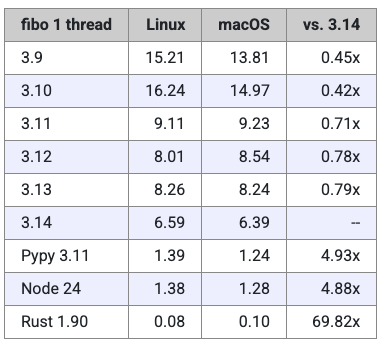
最右侧一列显示的是相对于 Python 3.14 的速度比。如果该列的数值小于 1,说明对应版本的运行速度比 3.14 慢;如果大于 1,则表示它比 3.14 更快。
在计算这些比值时,Miguel 取了 Linux 和 macOS 两个平台结果的平均值,以便得到一个更均衡的参考数据。
有时候,把数据可视化能更直观地看出差异,所以下面是一张图表,用图形方式展示了上面那组数字的对比情况:
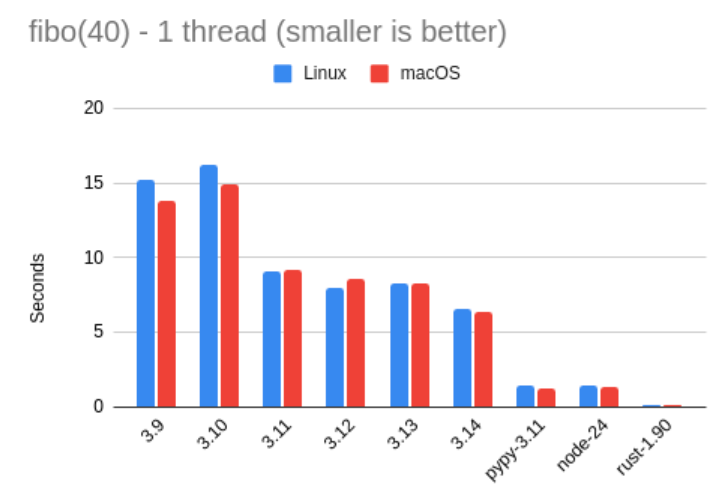
从这些结果中,我们能看到什么?
可以很明显地看出,Python 3.14 的性能相比 3.13 有了显著提升——大约提升了 27%。换句话说,3.13 的运行速度大约只有 3.14 的 79%。
此外,结果还显示,Python 3.11 是一个重要的分水岭——从那一版本开始,Python 终于从“非常慢”迈进到“没那么慢”的阶段。
还有一个与 3.14 无关但非常有趣的发现:Pypy 依然让人惊叹。在这次测试中,它的表现略快于 Node.js,而且速度几乎是 Python 3.14 的 5 倍。
非常令人印象深刻——虽然依然比不上 Rust,后者的运行速度果然如预期般,“把所有人都甩在身后”。
JIT 与 Free-Threading 变体
从 Python 3.13 开始,CPython 解释器提供了三种模式:
标准版(Standard)
自由线程版(Free-threading,FT)
即时编译版(Just-In-Time,JIT)
其中,自由线程解释器(FT) 取消了著名的 全局解释器锁(GIL),理论上这能显著提升多线程程序的执行效率。而 JIT 解释器则引入了动态编译机制,可在运行时将部分频繁执行的 Python 代码编译为原生机器码。按理说,这能让重复执行的代码段越跑越快。
上文展示的 3.13 和 3.14 数据,都是基于标准解释器的结果。
那么,在另外两种模式下同样的测试会得出什么呢?在接下来的表格和图表中,可以看到 3.13 与 3.14 在三种解释器模式下的性能对比。
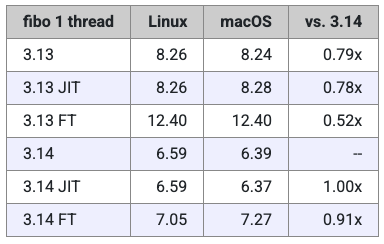
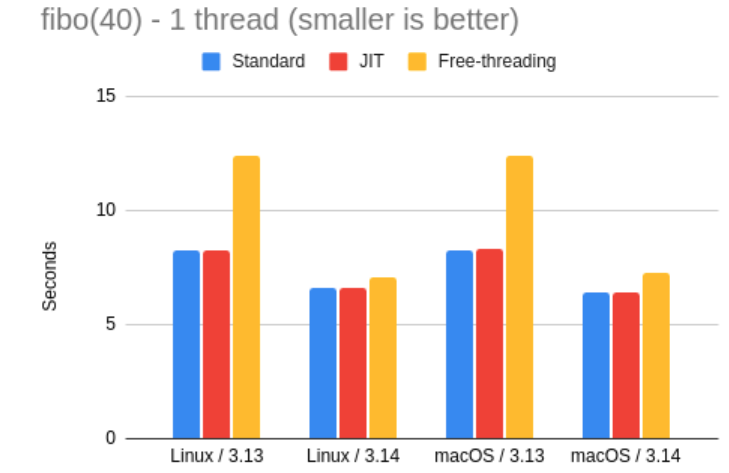
有一点令人失望的是,至少在这个测试中,JIT 解释器并没有带来显著的性能提升。对此,Miguel 不得不反复确认自己是否使用了正确构建、并启用了 JIT 功能的解释器。Miguel 坦言,自己对新 JIT 编译器的内部实现了解不多,但我怀疑它可能无法很好地处理这种高度递归的函数。
至于自由线程(Free-threading),Miguel 称,他早在去年就发现,这种解释器在运行单线程代码时表现偏慢。在 3.14 中,这种模式依然比标准解释器略慢,但差距明显缩小——自由线程的运行速度约为标准解释器的 91%。

基准测试 #2:单线程冒泡排序
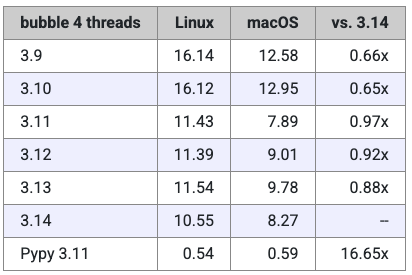
接下来是冒泡排序的测试结果,本次排序的对象是包含 1 万个随机数字的数组。
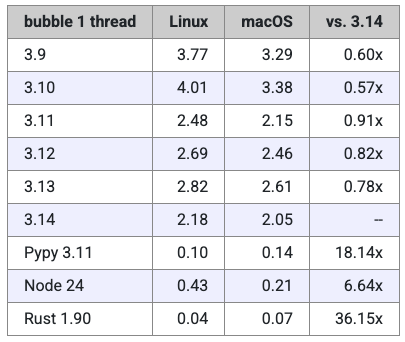
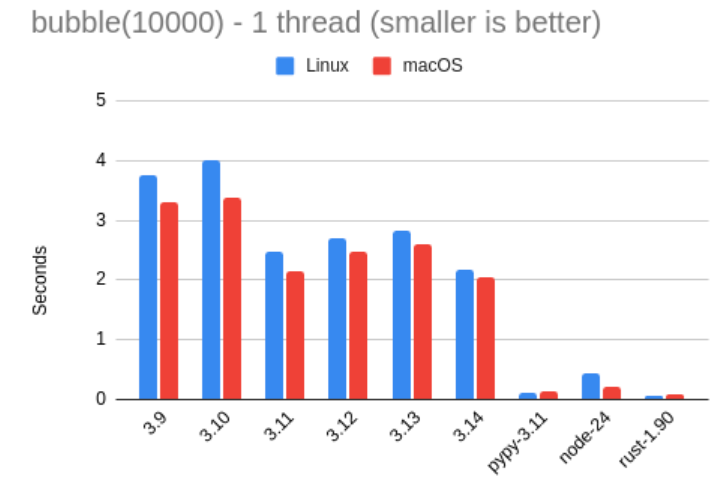
这项测试显示出 Miguel 所使用的 Linux 与 macOS 笔记本之间存在较大差异,不过在每台设备上,各版本之间的性能比例大致一致。这种差别表明,Python 在 Mac 上运行此测试时略快一些。
与斐波那契测试类似,Python 3.14 仍然是所有 CPython 版本中速度最快的,不过两者之间的差距比前一个基准测试要小一些。具体而言,Python 3.11 的运行速度约为 3.14 的 91%。有趣的是,3.12 与 3.13 的表现反而比 3.11 更慢——这一现象在 Miguel 称其去年进行的测试中也曾出现过。
在这次测试中,Pypy 的速度是 3.14 的 18 倍,甚至比 Node.js 还要快上 3 倍。Miguel 也表示,自己确实应该花些时间深入研究 Pypy,因为它的表现“令人惊艳”。
JIT 与自由线程变体
接下来,Miguel 还测试了 Python 3.13 与 3.14 的特制解释器在冒泡排序任务中的表现。
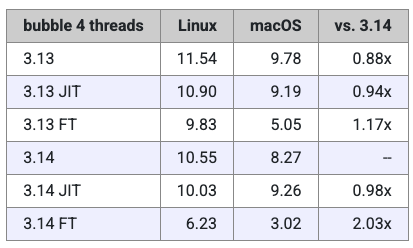
下表与图表展示了具体结果:
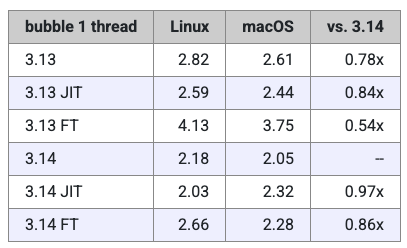
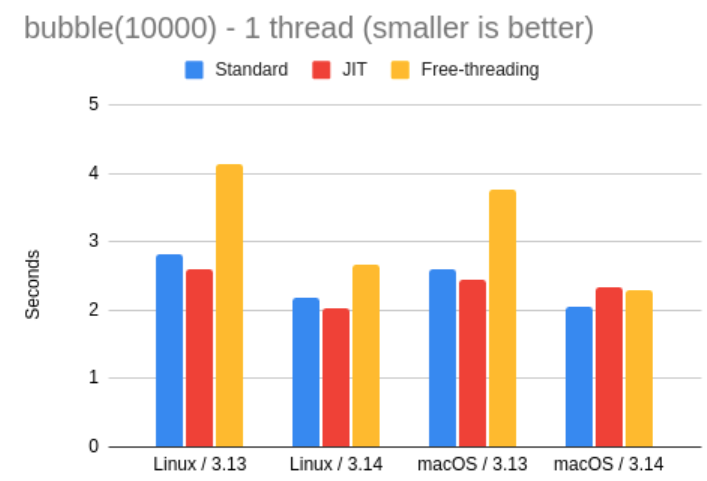
在这项测试中,JIT 解释器的表现略有提升,但仅限于 Linux 版本的 Python。在 Mac 上,JIT 在 3.13 时稍快一些,但到了 3.14 反而略慢。总体而言,这些速度差异都非常小,因此可以看出 JIT 解释器仍处在早期阶段,需要更多时间打磨。从结果来看,Miguel 所使用的测试代码似乎并不能很好地从 JIT 编译中受益。
至于自由线程解释器,其性能依然略逊一筹,不过差距在 3.14 中已经比 3.13 小得多,这与前面的测试结果一致。目前看来,自由线程模式还不适合用于常规任务,但如果遇到 GIL 成为性能瓶颈的场景(例如 CPU 密集型多线程应用),它依然是值得尝试的选项。

基准测试 #3:多线程 Fibonacci
今年,Miguel 决定在测试集中加入两个脚本的多线程版本,主要是想给自由线程解释器一个“展示实力的机会”。
在多线程 Fibonacci 测试中,Miguel 的做法是先启动了 4 个线程,每个线程都独立计算第 40 个 Fibonacci 数。由于所使用的两台笔记本都拥有超过 4 个 CPU 核心,理论上可以很好地并行运行这些任务。测试时间的计算方式是:从启动第一个线程开始计时,到所有 4 个线程结束为止。
下面是 fibo.py 在标准解释器下使用 4 个线程运行的测试结果。
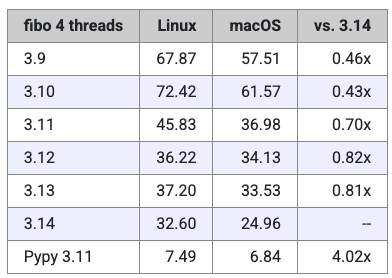
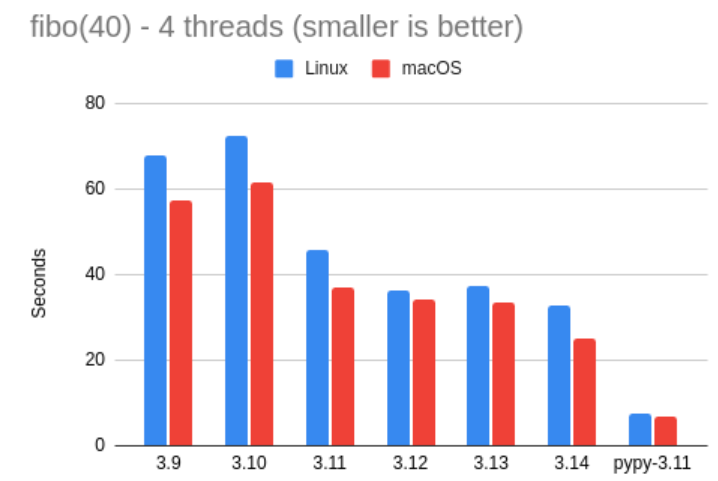
请注意,Miguel 表示,这里他并没有运行 Node 或 Rust 版本的测试,因为这类测试只适用于 Python 的 GIL(全局解释器锁)。
当然,这些结果本身说明不了太多问题。我们可以再次看到,Miguel 的 Mac 似乎比 Linux 机器稍微快一点,但除此之外,整体表现基本是线性扩展的。举个例子:单线程版本的斐波那契测试耗时 7 秒,而在这里(多线程测试中),Mac 上耗时 25 秒,Linux 上耗时 32 秒,大致是 4 倍左右的比例。这也符合预期——毕竟 GIL 会阻止 Python 代码实现真正的并行。
接下来,再来看看 Python 3.13 和 3.14 解释器的详细结果。
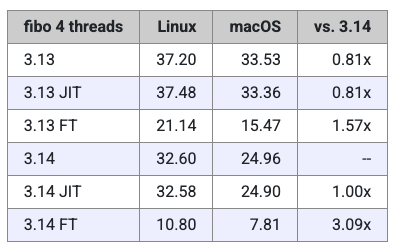
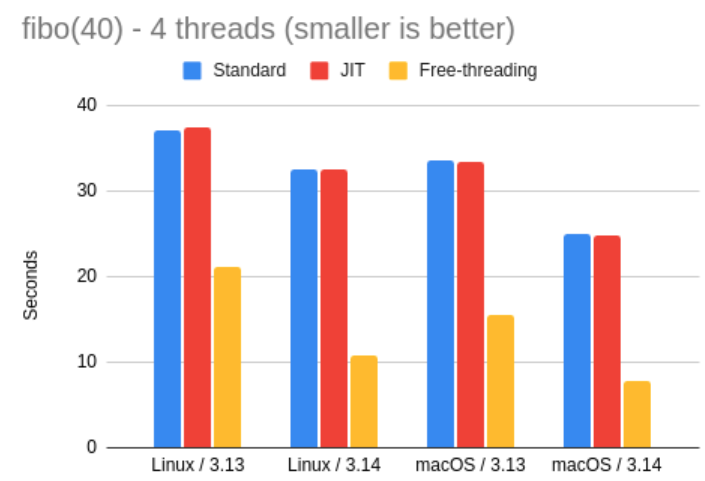
这结果相当不错!
由于在这个测试中,Miguel 透露,他本来也没指望 JIT 解释器能带来什么显著变化,所以可以忽略那部分结果。但无 GIL(free-threading)解释器的表现清楚地展示了——移除 GIL 后,Python 在处理多线程、CPU 密集型任务时能获得明显提升。
在 Python 3.13 中,无 GIL 解释器的运行速度大约比标准解释器快了 2.2 倍;而在 3.14 中,这一提升达到了约 3.1 倍。这个结果相当令人振奋!

基准测试 #4:多线程冒泡排序
为了完成这轮基准测试,接下来继续看看多线程冒泡排序的结果。
这个测试中,Miguel 让 4 个线程同时运行,每个线程都要对 10,000 个随机数进行排序。这四个线程收到的,是同一个随机生成数组的拷贝。
先从标准解释器的结果看起:
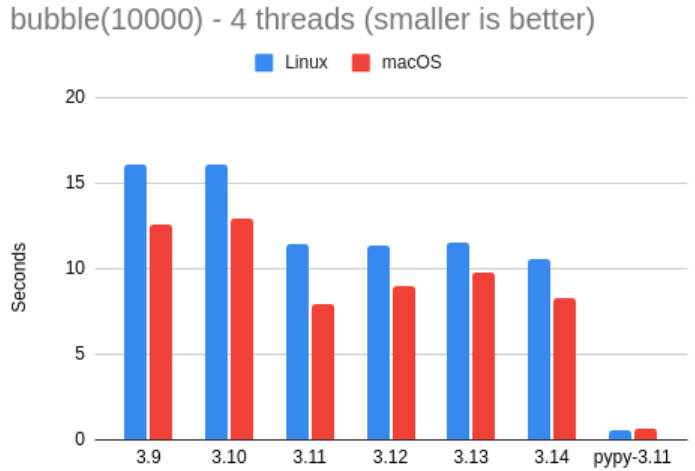
这部分测试结果同样没有带来太多意外。单线程版本在 Python 3.14 上的运行时间约为 2 秒,而在多线程情况下,Linux 上耗时约 10 秒,Mac 上约 8 秒。有趣的是,在 Linux 机器上,这个结果比单线程的 4 倍时间还要稍微多一点。
以下是 Python 3.13 和 3.14 的新解释器在该测试下的表现:
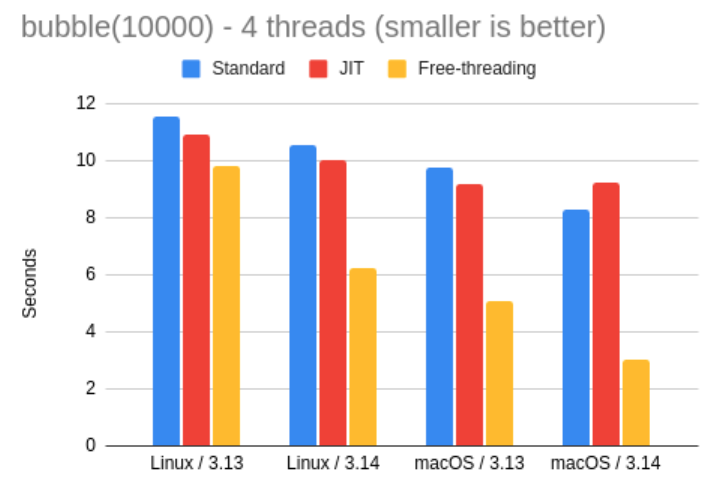
这里再次展示了自由线程解释器(Free-threading)的一个很好用例。
在这个测试中,Mac 上的自由线程表现甚至优于 Linux,但总体来看,Python 3.14 的 FT 模式比标准解释器大约快了 2 倍。如果你的应用是 CPU 密集型的多线程程序,切换到自由线程解释器可能是一个不错的选择。
至于 JIT 解释器,在 3.14 Mac 上单线程冒泡排序测试中出现的“反而更慢”的奇怪结果,在这里再次出现,因此 Miguel 猜这并非偶然。
不过,Miguel 称,这些差异并不大,不会影响实际使用。我们只能等待 JIT 解释器在未来版本中继续优化和发展。

结论
根据测试结果,Miguel 进一步总结出以下几点结论:
CPython 3.14 看起来是所有 CPython 版本中最快的。
如果你还无法升级到 3.14,可以考虑使用 3.11 及以上版本,这些版本相比 3.10 及更早版本有明显性能提升。
3.14 的 JIT 解释器在我的测试脚本下,并未带来显著速度提升。
3.14 的自由线程解释器在 CPU 密集型多线程应用中比标准解释器快,适合尝试此类场景。但对于其他类型的工作负载,不建议使用自由线程模式,因为对于不受 GIL 限制的代码,它的速度仍然略慢。
Pypy 的速度依然惊人!
来源:https://blog.miguelgrinberg.com/post/python-3-14-is-here-how-fast-is-it
推荐阅读:
地址栏也能打游戏!程序员用不到400行代码,在浏览器地址栏复活《贪吃蛇》,网友惊叹:怎么想出这个点子的?
用4.39亿方块在《我的世界》手搓一款ChatGPT?玩家又一次“整活”,还把游戏玩出了新高度!
“开发Linux是业余爱好”?内核开发者:这是Linus唯一的错话,曾被忽视、嘲笑的OS打破“未来全是Windows”的幻想!



















 1029
1029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











