






点击上方“程序人生”,选择“置顶公众号”
第一时间关注程序猿(媛)身边的故事

作者
苏克1900
已获原作者授权,如需转载,请联系原作者。
之前,我们用Selenium成功爬取了东方财富网的财务报表数据,但是速度非常慢,爬取70页需要好几十分钟。为了加快速度,本文分析网页JavaScript请求,找到数据接口然后快速爬取财务报表数据。
1. JavaScript请求分析
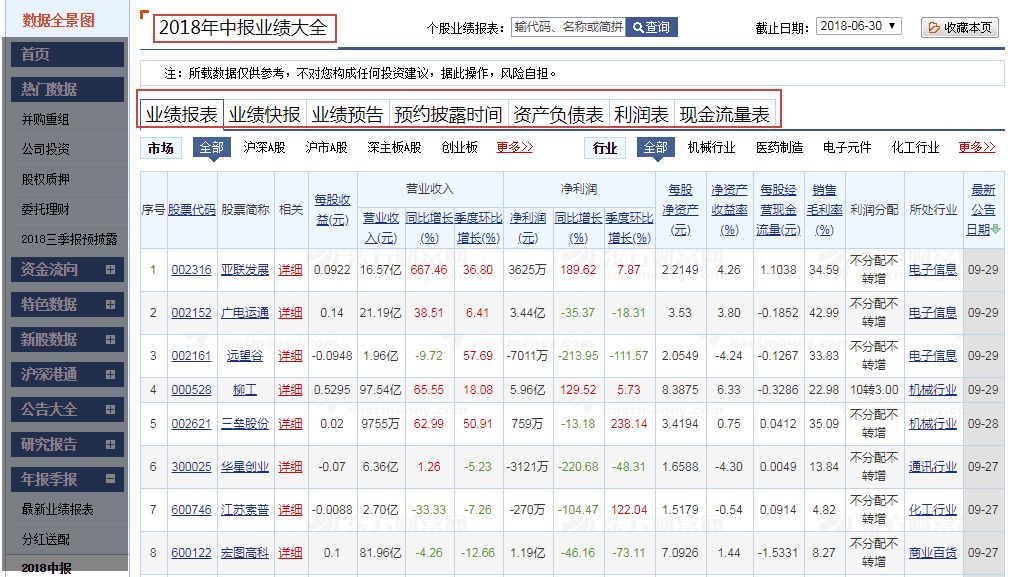
接下来,我们深入分析。首先,点击报表底部的下一页,然后观察左侧Name列,看会弹出什么新的请求来:
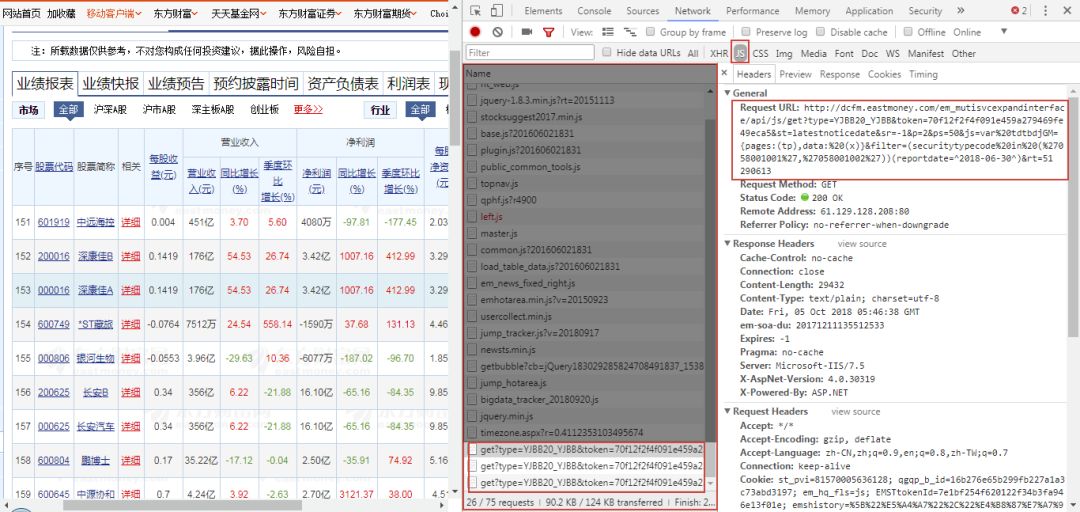
可以看到,当不断点击下一页时,会相应弹出以get?type开头的请求。点击右边Headers选项卡,可以看到请求的URL,网址非常长,先不管它,后续我们会分析各项参数。接着,点击右侧的Preview和Response,可以看到里面有很多整齐的数据,尝试猜测这可能是财务报表中的数据,经过和表格进行对比,发现这正是我们所需的数据,太好了。
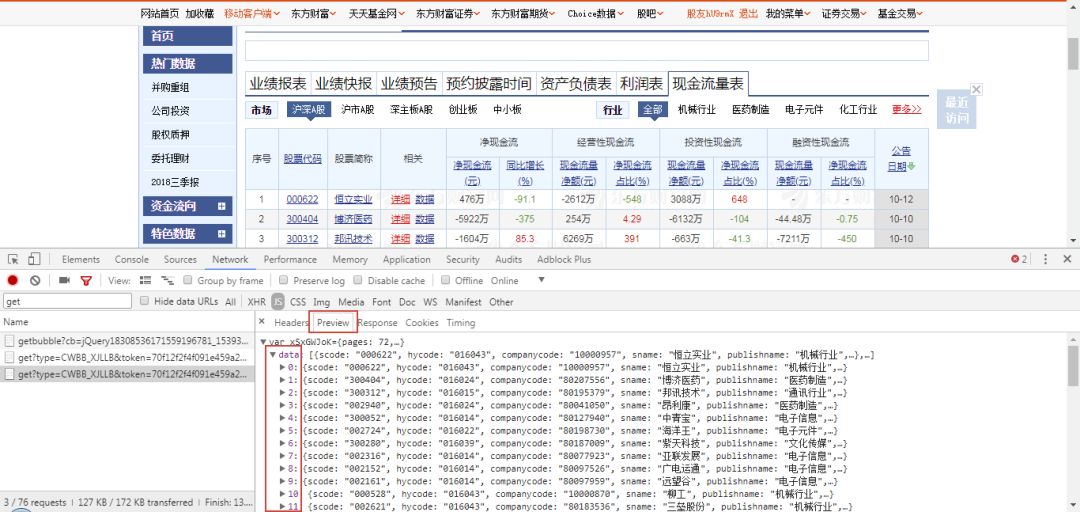
然后将URL复制到新链接中打开看看,可以看到表格中的数据完美地显示出来了。竟然不用添加Headers、UA去请求就能获取到,看来东方财富网很大方啊。

到这里,爬取思路已经很清晰了。首先,用Request请求该URL,将获取到的数据进行正则匹配,将数据转变为json格式,然后写入本地文件,最后再加一个分页循环爬取就OK了。这比之前的Selenium要简单很多,而且速度应该会快很多倍。下面我们就先来尝试爬一页数据看看。
2. 爬取单页
2.1. 抓取分析
这里仍然以2018年中报的利润表为例,抓取该网页的第一页表格数据,网页url为:http://data.eastmoney.com/bbsj/201806/lrb.html
表格第一页的js请求的url为:http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js/get?type=CWBB_LRB&token=70f12f2f4f091e459a279469fe49eca5&st=noticedate&sr=-1&p=2&ps=50&js=var%20spmVUpAF={pages:(tp),data:%20(x)}&filter=(reportdate=^2018-06-30^)&rt=51312886}&filter=(reportdate=^2018-06-30^)&rt=51312886)
下面,我们通过分析该url,来抓取表格内容。
1import requests
2def get_table():
3 params = {
4 'type': 'CWBB_LRB', # 表格类型,LRB为利润表缩写,必须
5 'token': '70f12f2f4f091e459a279469fe49eca5', # 访问令牌,必须
6 'st': 'noticedate', # 公告日期
7 'sr': -1, # 保持-1不用改动即可
8 'p': 1, # 表格页数
9 'ps': 50, # 每页显示多少条信息
10 'js': 'var LFtlXDqn={pages:(tp),data: (x)}', # js函数,必须
11 'filter': '(reportdate=^2018-06-30^)', # 筛选条件
12 # 'rt': 51294261 可不用
13 }
14 url = 'http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js/get?'
15 response = requests.get(url, params=params).text
16 print(response)
17get_table()
这里我们定义了一个get_table()方法,来输出抓取的第一页表格内容。params为url请求中所包含的参数。
这里对重要参数进行简单说明:type为7个表格的类型说明,将type拆成两部分:'CWBB_' 和'LRB',资产负债表等后3个表是以'CWBB_' 开头,业绩报表至预约披露时间表等前4个表是以'YJBB20_'开头的;'LRB'为利润表的首字母缩写,同理业绩报表则为'YJBB'。所以,如果要爬取不同的表格,就需要更改type参数。'filter'为表格筛选参数,这里筛选出年中报的数据。不同的表格筛选条件会不一样,所以当type类型更改的时候,也要相应修改filter类型。
params参数设置好之后,将url和params参数一起传进requests.get()方法中,这样就构造好了请求连接。几行代码就可以成功获取网页第一页的表格数据了:
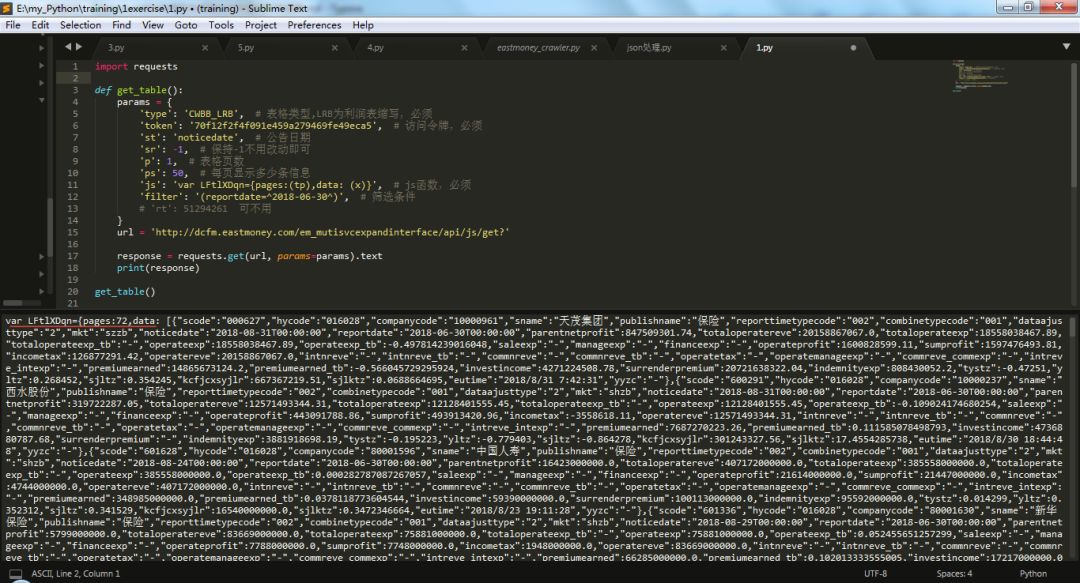
可以看到,表格信息存储在LFtlXDqn变量中,pages表示表格有72页。data为表格数据,是一个由多个字典构成的列表,每个字典是表格的一行数据。我们可以通过正则表达式分别提取出pages和data数据。
2.2. 正则表达式提取表格
1# 确定页数
2import re
3pat = re.compile('var.*?{pages:(\d+),data:.*?')
4page_all = re.search(pat, response)
5print(page_all.group(1))
6结果:
772
这里用\d+匹配页数中的数值,然后用re.search()方法提取出来。group(1)表示输出第一个结果,这里就是()中的页数。
1# 提取出list,可以使用json.dumps和json.loads
2import json
3pattern = re.compile('var.*?data: (.*)}', re.S)
4items = re.search(pattern, response)
5data = items.group(1)
6print(data)
7print(type(data))
8结果如下:
9[{'scode': '600478', 'hycode': '016040', 'companycode': '10001305', 'sname': '科力远', 'publishname': '材料行业'...
10'sjltz': 10.466665, 'kcfjcxsyjlr': 46691230.93, 'sjlktz': 10.4666649042, 'eutime': '2018/9/6 20:18:42', 'yyzc': 14238766.31}]
11<class 'str'>
12
这里在匹配表格数据用了(.*)表示贪婪匹配,因为data中有很多个字典,每个字典都是以'}'结尾,所以我们利用贪婪匹配到最后一个'}',这样才能获取data所有数据。多数情况下,我们可能会用到(.*?),这表示非贪婪匹配,意味着之多匹配一个'}',这样的话,我们只能匹配到第一行数据,显然是不对的。
2.3. json.loads()输出表格
这里提取出来的list是str字符型的,我们需要转换为list列表类型。为什么要转换为list类型呢,因为无法用操作list的方法去操作str,比如list切片。转换为list后,我们可以对list进行切片,比如data[0]可以获取第一个{}中的数据,也就是表格第一行,这样方便后续构造循环从而逐行输出表格数据。这里采用json.loads()方法将str转换为list。
1data = json.loads(data)
2# print(data) 和上面的一样
3print(type(data))
4print(data[0])
5结果如下:
6<class 'list'>
7{'scode': '600478', 'hycode': '016040', 'companycode': '10001305', 'sname': '科力远', 'publishname': '材料行业', 'reporttimetypecode': '002', 'combinetypecode': '001', 'dataajusttype': '2', 'mkt': 'shzb', 'noticedate': '2018-10-13T00:00:00', 'reportdate': '2018-06-30T00:00:00', 'parentnetprofit': -46515200.15, 'totaloperatereve': 683459458.22, 'totaloperateexp': 824933386.17, 'totaloperateexp_tb': -0.0597570689015973, 'operateexp': 601335611.67, 'operateexp_tb': -0.105421872593886, 'saleexp': 27004422.05, 'manageexp': 141680603.83, 'financeexp': 33258589.95, 'operateprofit': -94535963.65, 'sumprofit': -92632216.61, 'incometax': -8809471.54, 'operatereve': '-', 'intnreve': '-', 'intnreve_tb': '-', 'commnreve': '-', 'commnreve_tb': '-', 'operatetax': 7777267.21, 'operatemanageexp': '-', 'commreve_commexp': '-', 'intreve_intexp': '-', 'premiumearned': '-', 'premiumearned_tb': '-', 'investincome': '-', 'surrenderpremium': '-', 'indemnityexp': '-', 'tystz': -0.092852, 'yltz': 0.178351, 'sjltz': 0.399524, 'kcfjcxsyjlr': -58082725.17, 'sjlktz': 0.2475682609, 'eutime': '2018/10/12 21:01:36', 'yyzc': 601335611.67}
接下来我们就将表格内容输入到csv文件中。
1# 写入csv文件
2import csv
3for d in data:
4 with open('eastmoney.csv', 'a', encoding='utf_8_sig', newline='') as f:
5 w = csv.writer(f)
6 w.writerow(d.values())
通过for循环,依次取出表格中的每一行字典数据{},然后用with…open的方法写入'eastmoney.csv'文件中。
tips:'a'表示可重复写入;encoding='utf_8_sig' 能保持csv文件的汉字不会乱码;newline为空能避免每行数据中产生空行。
这样,第一页50行的表格数据就成功输出到csv文件中去了:
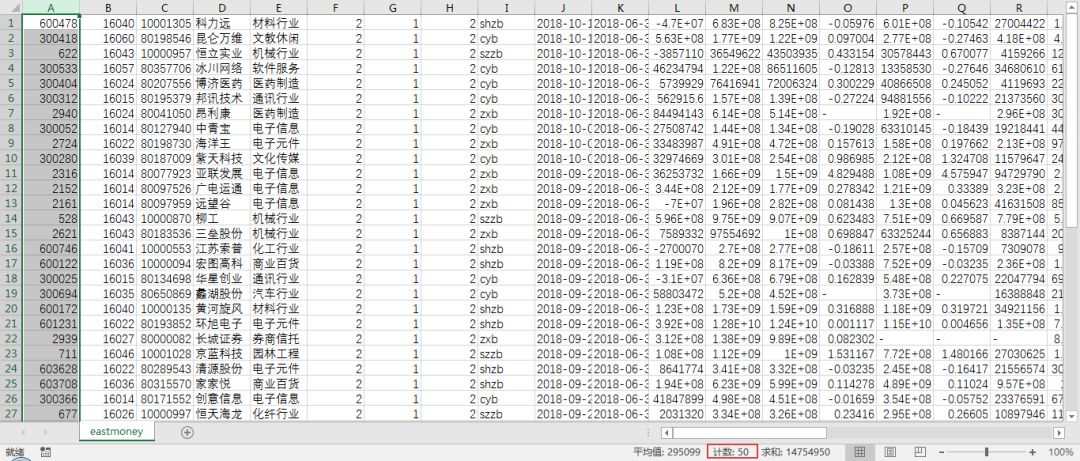
这里,我们还可以在输出表格之前添加上表头:
1# 添加列标题
2def write_header(data):
3 with open('eastmoney.csv', 'a', encoding='utf_8_sig', newline='') as f:
4 headers = list(data[0].keys())
5 print(headers)
6 print(len(headers)) # 输出list长度,也就是有多少列
7 writer = csv.writer(f)
8 writer.writerow(headers)
这里,data[0]表示list的一个字典中的数据,data[0].keys()表示获取字典中的key键值,也就是列标题。外面再加一个list序列化(结果如下),然后将该list输出到'eastmoney.csv'中作为表格的列标题即可。
1['scode', 'hycode', 'companycode', 'sname', 'publishname', 'reporttimetypecode', 'combinetypecode', 'dataajusttype', 'mkt', 'noticedate', 'reportdate', 'parentnetprofit', 'totaloperatereve', 'totaloperateexp', 'totaloperateexp_tb', 'operateexp', 'operateexp_tb', 'saleexp', 'manageexp', 'financeexp', 'operateprofit', 'sumprofit', 'incometax', 'operatereve', 'intnreve', 'intnreve_tb', 'commnreve', 'commnreve_tb', 'operatetax', 'operatemanageexp', 'commreve_commexp', 'intreve_intexp', 'premiumearned', 'premiumearned_tb', 'investincome', 'surrenderpremium', 'indemnityexp', 'tystz', 'yltz', 'sjltz', 'kcfjcxsyjlr', 'sjlktz', 'eutime', 'yyzc']
244 # 一共有44个字段,也就是说表格有44列。
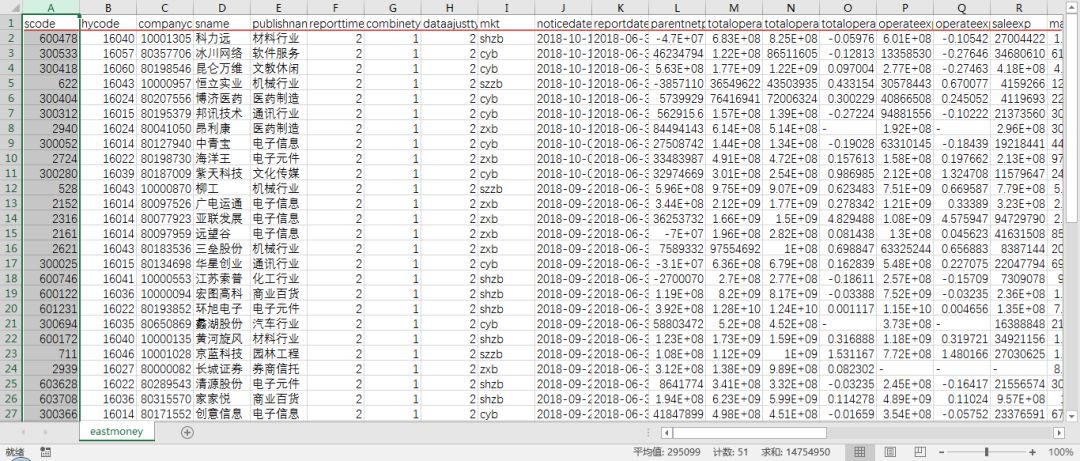
以上,就完成了单页表格的爬取和下载到本地的过程。
3. 多页表格爬取
将上述代码整理为相应的函数,再添加for循环,仅50行代码就可以爬取72页的利润报表数据:
1import requests
2import re
3import json
4import csv
5import time
6def get_table(page):
7 params = {
8 'type': 'CWBB_LRB', # 表格类型,LRB为利润表缩写,必须
9 'token': '70f12f2f4f091e459a279469fe49eca5', # 访问令牌,必须
10 'st': 'noticedate', # 公告日期
11 'sr': -1, # 保持-1不用改动即可
12 'p': page, # 表格页数
13 'ps': 50, # 每页显示多少条信息
14 'js': 'var LFtlXDqn={pages:(tp),data: (x)}', # js函数,必须
15 'filter': '(reportdate=^2018-06-30^)', # 筛选条件,如果不选则默认下载全部时期的数据
16 # 'rt': 51294261 可不用
17 }
18 url = 'http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js/get?'
19 response = requests.get(url, params=params).text
20 # 确定页数
21 pat = re.compile('var.*?{pages:(\d+),data:.*?')
22 page_all = re.search(pat, response) # 总页数
23 pattern = re.compile('var.*?data: (.*)}', re.S)
24 items = re.search(pattern, response)
25 data = items.group(1)
26 data = json.loads(data)
27 print('\n正在下载第 %s 页表格' % page)
28 return page_all,data
29def write_header(data):
30 with open('eastmoney.csv', 'a', encoding='utf_8_sig', newline='') as f:
31 headers = list(data[0].keys())
32 writer = csv.writer(f)
33 writer.writerow(headers)
34def write_table(data):
35 for d in data:
36 with open('eastmoney.csv', 'a', encoding='utf_8_sig', newline='') as f:
37 w = csv.writer(f)
38 w.writerow(d.values())
39
40def main(page):
41 data = get_table(page)
42 write_table(data)
43
44if __name__ == '__main__':
45 start_time = time.time() # 下载开始时间
46 # 写入表头
47 write_header(get_table(1))
48 page_all = get_table(1)[0]
49 page_all = int(page_all.group(1))
50 for page in range(1, page_all):
51 main(page)
52 end_time = time.time() - start_time # 结束时间
53 print('下载用时: {:.1f} s' .format(end_time))
整个下载只用了20多秒,而之前用selenium花了几十分钟,这效率提升了足有100倍!
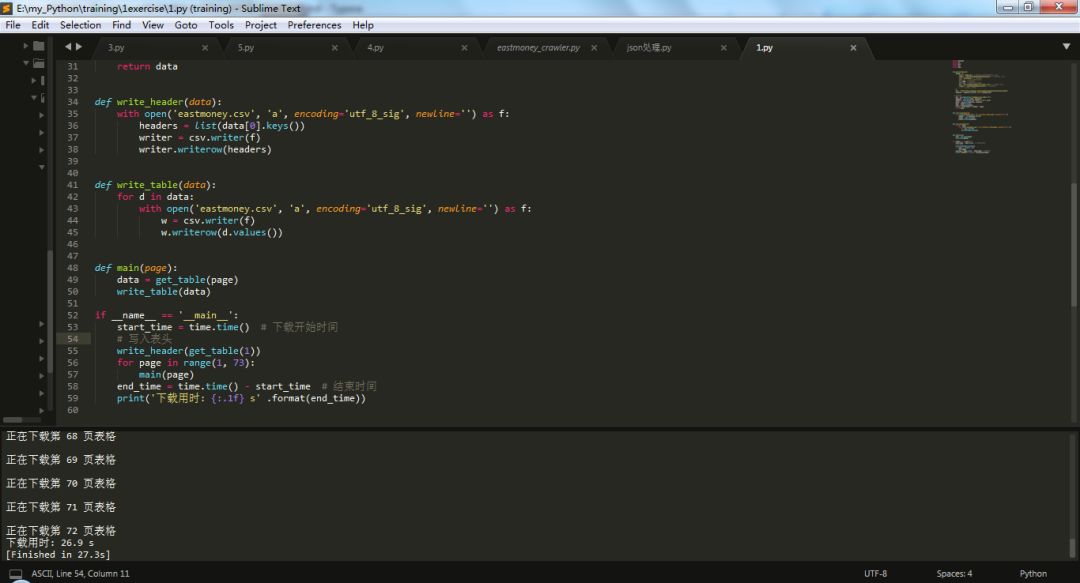
这里,如果我们想下载全部时期(从2007年-2018年)利润报表数据,也很简单。只要将type中的filter参数注释掉,意味着也就是不筛选日期,那么就可以下载全部时期的数据。这里当我们取消注释filter列,将会发现总页数page_all会从2018年中报的72页增加到2528页,全部下载完成后,表格有超过12万行的数据。基于这些数据,可以尝试从中进行一些有价值的数据分析。
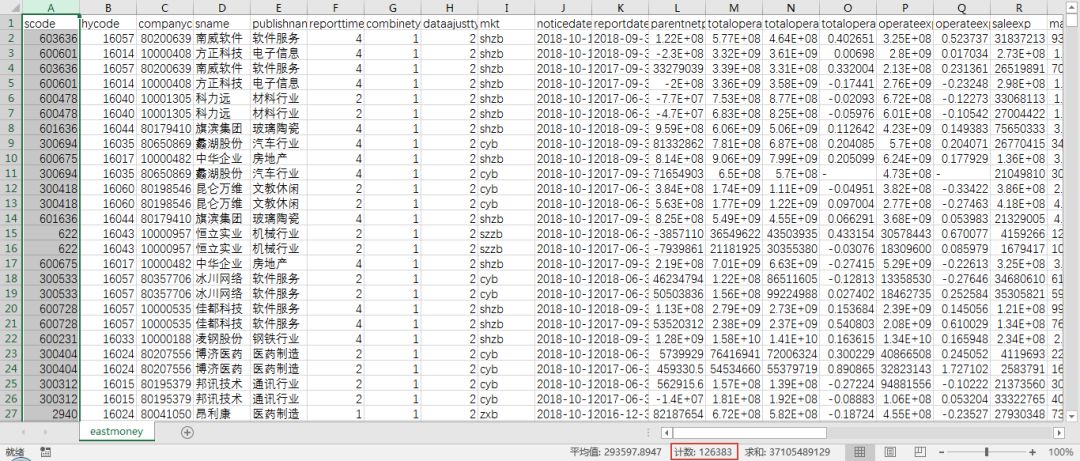
4. 通用代码构造
以上代码实现了2018年中报利润报表的爬取,但如果不想局限于该报表,还想爬取其他报表或者其他任意时期的数据,那么就需要手动地去修改代码中相应的字段,很不方便。所以上面的代码可以说是简短但不够强大。
为了能够灵活实现爬取任意类别和任意时期的报表数据,需要对代码再进行一些加工,就可以构造出通用强大的爬虫程序了。
1"""
2e.g: http://data.eastmoney.com/bbsj/201806/lrb.html
3"""
4import requests
5import re
6from multiprocessing import Pool
7import json
8import csv
9import pandas as pd
10import os
11import time
12
13# 设置文件保存在D盘eastmoney文件夹下
14file_path = 'D:\\eastmoney'
15if not os.path.exists(file_path):
16 os.mkdir(file_path)
17os.chdir(file_path)
18
19# 1 设置表格爬取时期、类别
20def set_table():
21 print('*' * 80)
22 print('\t\t\t\t东方财富网报表下载')
23 print('作者:高级农民工 2018.10.10')
24 print('--------------')
25 year = int(float(input('请输入要查询的年份(四位数2007-2018):\n')))
26 # int表示取整,里面加float是因为输入的是str,直接int会报错,float则不会
27 # https://stackoverflow.com/questions/1841565/valueerror-invalid-literal-for-int-with-base-10
28 while (year < 2007 or year > 2018):
29 year = int(float(input('年份数值输入错误,请重新输入:\n')))
30
31 quarter = int(float(input('请输入小写数字季度(1:1季报,2-年中报,3:3季报,4-年报):\n')))
32 while (quarter < 1 or quarter > 4):
33 quarter = int(float(input('季度数值输入错误,请重新输入:\n')))
34
35 # 转换为所需的quarter 两种方法,2表示两位数,0表示不满2位用0补充,
36 # http://www.runoob.com/python/att-string-format.html
37 quarter = '{:02d}'.format(quarter * 3)
38 # quarter = '%02d' %(int(month)*3)
39
40 # 确定季度所对应的最后一天是30还是31号
41 if (quarter == '06') or (quarter == '09'):
42 day = 30
43 else:
44 day = 31
45 date = '{}-{}-{}' .format(year, quarter, day)
46 # print('date:', date) # 测试日期 ok
47
48 # 2 设置财务报表种类
49 tables = int(
50 input('请输入查询的报表种类对应的数字(1-业绩报表;2-业绩快报表:3-业绩预告表;4-预约披露时间表;5-资产负债表;6-利润表;7-现金流量表): \n'))
51
52 dict_tables = {1: '业绩报表', 2: '业绩快报表', 3: '业绩预告表',
53 4: '预约披露时间表', 5: '资产负债表', 6: '利润表', 7: '现金流量表'}
54
55 dict = {1: 'YJBB', 2: 'YJKB', 3: 'YJYG',
56 4: 'YYPL', 5: 'ZCFZB', 6: 'LRB', 7: 'XJLLB'}
57 category = dict[tables]
58
59 # js请求参数里的type,第1-4个表的前缀是'YJBB20_',后3个表是'CWBB_'
60 # 设置set_table()中的type、st、sr、filter参数
61 if tables == 1:
62 category_type = 'YJBB20_'
63 st = 'latestnoticedate'
64 sr = -1
65 filter = "(securitytypecode in ('058001001','058001002'))(reportdate=^%s^)" %(date)
66 elif tables == 2:
67 category_type = 'YJBB20_'
68 st = 'ldate'
69 sr = -1
70 filter = "(securitytypecode in ('058001001','058001002'))(rdate=^%s^)" %(date)
71 elif tables == 3:
72 category_type = 'YJBB20_'
73 st = 'ndate'
74 sr = -1
75 filter=" (IsLatest='T')(enddate=^2018-06-30^)"
76 elif tables == 4:
77 category_type = 'YJBB20_'
78 st = 'frdate'
79 sr = 1
80 filter = "(securitytypecode ='058001001')(reportdate=^%s^)" %(date)
81 else:
82 category_type = 'CWBB_'
83 st = 'noticedate'
84 sr = -1
85 filter = '(reportdate=^%s^)' % (date)
86
87 category_type = category_type + category
88 # print(category_type)
89 # 设置set_table()中的filter参数
90
91 yield{
92 'date':date,
93 'category':dict_tables[tables],
94 'category_type':category_type,
95 'st':st,
96 'sr':sr,
97 'filter':filter
98 }
99
100# 2 设置表格爬取起始页数
101def page_choose(page_all):
102 # 选择爬取页数范围
103 start_page = int(input('请输入下载起始页数:\n'))
104 nums = input('请输入要下载的页数,(若需下载全部则按回车):\n')
105 print('*' * 80)
106
107 # 判断输入的是数值还是回车空格
108 if nums.isdigit():
109 end_page = start_page + int(nums)
110 elif nums == '':
111 end_page = int(page_all.group(1))
112 else:
113 print('页数输入错误')
114
115 # 返回所需的起始页数,供后续程序调用
116 yield{
117 'start_page': start_page,
118 'end_page': end_page
119 }
120
121# 3 表格正式爬取
122def get_table(date, category_type,st,sr,filter,page):
123 # 参数设置
124 params = {
125 # 'type': 'CWBB_LRB',
126 'type': category_type, # 表格类型
127 'token': '70f12f2f4f091e459a279469fe49eca5',
128 'st': st,
129 'sr': sr,
130 'p': page,
131 'ps': 50, # 每页显示多少条信息
132 'js': 'var LFtlXDqn={pages:(tp),data: (x)}',
133 'filter': filter,
134 # 'rt': 51294261 可不用
135 }
136 url = 'http://dcfm.eastmoney.com/em_mutisvcexpandinterface/api/js/get?'
137 response = requests.get(url, params=params).text
138 # 确定页数
139 pat = re.compile('var.*?{pages:(\d+),data:.*?')
140 page_all = re.search(pat, response)
141 # print(page_all.group(1)) # ok
142 # 提取出list,可以使用json.dumps和json.loads
143 pattern = re.compile('var.*?data: (.*)}', re.S)
144 items = re.search(pattern, response)
145 # 等价于
146 # items = re.findall(pattern,response)
147 # print(items[0])
148 data = items.group(1)
149 data = json.loads(data)
150 return page_all, data,page
151
152# 4 写入表头
153# 方法1 借助csv包,最常用
154def write_header(data,category):
155 with open('{}.csv' .format(category), 'a', encoding='utf_8_sig', newline='') as f:
156 headers = list(data[0].keys())
157 # print(headers) # 测试 ok
158 writer = csv.writer(f)
159 writer.writerow(headers)
160# 5 写入表格
161def write_table(data,page,category):
162 print('\n正在下载第 %s 页表格' % page)
163 # 写入文件方法1
164 for d in data:
165 with open('{}.csv' .format(category), 'a', encoding='utf_8_sig', newline='') as f:
166 w = csv.writer(f)
167 w.writerow(d.values())
168
169def main(date, category_type,st,sr,filter,page):
170 func = get_table(date, category_type,st,sr,filter,page)
171 data = func[1]
172 page = func[2]
173 write_table(data,page,category)
174if __name__ == '__main__':
175 # 获取总页数,确定起始爬取页数
176 for i in set_table():
177 date = i.get('date')
178 category = i.get('category')
179 category_type = i.get('category_type')
180 st = i.get('st')
181 sr = i.get('sr')
182 filter = i.get('filter')
183 constant = get_table(date,category_type,st,sr,filter, 1)
184 page_all = constant[0]
185
186 for i in page_choose(page_all):
187 start_page = i.get('start_page')
188 end_page = i.get('end_page')
189
190 # 先写入表头
191 write_header(constant[1],category)
192 start_time = time.time() # 下载开始时间
193 # 爬取表格主程序
194 for page in range(start_page, end_page):
195 main(date,category_type,st,sr,filter, page)
196 end_time = time.time() - start_time # 结束时间
197 print('下载完成')
198 print('下载用时: {:.1f} s' .format(end_time))
以爬取2018年中业绩报表为例,感受一下比selenium快得多的爬取效果:
利用上面的程序,我们可以下载任意时期和任意报表的数据。这里,我下载完成了2018年中报所有7个报表的数据。
文中代码和素材资源可以在下面的链接中获取:https://github.com/makcyun/eastmoney_spider
本文完。
- The End -
「若你有原创文章想与大家分享,欢迎投稿。」
加编辑微信ID,备注#投稿#:
程序 丨 druidlost
小七 丨 duoshangshuang
点文末阅读全文,看『程序人生』其他精彩文章推荐。
免费公开课|扫码即可报名
想学习超级账本的同学千万不要错过!开课前报名可免费观看直播和回放,课程结束后只有会员才可免费观看回放哦!

推荐阅读:

print_r('点个赞吧');
var_dump('点个赞吧');
NSLog(@"点个赞吧!")
System.out.println("点个赞吧!");
console.log("点个赞吧!");
print("点个赞吧!");
printf("点个赞吧!\n");
cout << "点个赞吧!" << endl;
Console.WriteLine("点个赞吧!");
fmt.Println("点个赞吧!")
Response.Write("点个赞吧");
alert(’点个赞吧’)













 9693
9693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









