






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Attention-Guided Multi-scale Interaction Network for face Super-Resolution
Xujie Wan, Wenjie Li, Guangwei Gao, Senior Member, IEEE, Huimin Lu, Senior Member, IEEE, Jian
Yang, Member, IEEE, and Chia-Wen Lin, Fellow, IEEE
文章目录
摘要
由于混合网络中不同尺度的特征众多,如何融合这些多尺度特征并促进它们的互补性是提高人脸超分辨率的关键。现有的方法只是将CNN和Transformer结合,为此论文提出了注意力引导的多尺度交互网络AMINet,包括全局和局部的交互以及encode和decode的特征交互。具体包括LGFI(局部和全局交互模块);RDFF残差深度特征提取模块,主要用来提取局部特征;SKAF选择核心特征融合模块。
简介
基于cnn的方法通常不需要大量的计算消耗。尽管如此,他们专注于提取局部细节,比如面部的局部纹理、颜色等。但是缺乏长期特征的交互,比如人脸的全局轮廓。基于Transformer的FSR方法可以很好地模拟全局建模,但其计算消耗很大。基于混合的FSR方法利用了CNN和Transformer的优势,促进模型来完成局部和全局面部特征的提取,同时保持可管理的计算成本,它的优秀性能来自于不同尺度提取特征,如利用自注意力提取全局特征利用卷积提取局部特征。因而在编码解码阶段这种方式有助于模型精炼局部细节和全局轮廓特征。但是如何融合不同尺度的特征使其可以互补是一个关键问题。如Faceformer只是简单的将CNN和基于窗口的transformer进行并行化。SCTANET也只在设计的模块中并列了基于空间注意的残差块和多头自注意机制。CTCNet也只是将CNN和Transformer进行了串联。以上各种方法都没有有效融合不同尺度的特征,从而促使模块内不同尺度的特征自由流动,以便精炼面部细节。
为了解决这一问题,文章提出了一种Attention-Guided Multi-scale Interaction Network(AMINet)。提出了两种方式融合特征:从注意力和卷积中获得的特征融合以及编码器不同阶段的特征融合。具体包括LGFI自适应地将全局面部和局部特征与通过卷积获得的不同接受域进行融合,在提取局部特征部分提出了残余深度特征提取模块(RDFE)提取局部特征在使用不同卷积内核的大小提取特征,在特征融合部分提出选择性核注意融合模块(SKAF)负责加权融合的这两部分特征为模型在训练阶段自适应地执行选择性融合。另外SKAF还作为编码器和解码器特征融合模块(EDFF)中的一个关键融合模块,通过融合不同尺度的编解码器过程中的特征。
此种设计极大的增强了模型内不同尺度的交互,提升了模型的表示能力,从下图中可以看出我们的模型无论在模型大小和推理速度上都取得了最佳的性能。

文章的贡献如下:
(1)设计了一个不同于传统Transformer的LGFI,它允许模块内的自由流和自适应的局部和全局特征的选择性融合
(2)设计了一个RDFE,通过融合和细化由不同大小的卷积核提取的局部特征,可以更好地细化面部细节
(3)设计了SKAF,通过选择适当的卷积核来帮助LGFI和EDFF中不同尺度特征的选择性融合。

相关工作
1.人脸超分辨率
早期的深度学习方法侧重于利用面部先验作为指导来提高准确性,如利用面部地标和热图,人脸对齐网络,面部地标先验、三维形状先验等,这些方法具有一定的先进性但需要对训练集进行标注。
随后基于注意力机制的方法被提出,如有监督的对抗性网络逐像素生成方法;SPARNet,它可以利用残差块中的空间注意力来自适应地关注重要的面部结构特征。一种部分注意机制来提高面部细节和面部结构保真度的一致性。均衡化纹理增强模块,通过直方图均衡化来增强面部纹理细节。将傅里叶变换引入到FSR中,充分探讨了空间域特征与频域特征之间的相关性。双分支网络,它引入了基于局部变化的卷积,以提高卷积的能力。文献10通过设计混合注意模块,提高了区域特征和全球特征的交互能力。文献22设计了一种基于小波的网络来减少编解码器中的降采样损失。
2.基于注意力的超分辨率
文献24将通道注意插入到残差块中,以增强模型的表示,文献25利用通道注意和残余机制结合了一种多层次的信息融合策略。文献27构建了一个利用空间注意的简化前馈网络,以降低参数和计算复杂度。文献27构建了一个利用空间注意的简化前馈网络,以降低参数和计算复杂度。文献30通过利用自我注意的递归机制,降低了成本。文献33引入了一个自我关注网络,用来研究不同层次的特征之间的关系。文献21通过一 种平行的自我注意机制来减轻不准确的先验估计的不利影响 ,从而增强了FSR,有效地捕获了局部和非局部的依赖关系 。为了结合不同注意事项的优点,文献34将通道注意力和空间注意力相结合。本文利用注意力从不同的接受域学习特征映射,允许我们的网络自适应地选择适当的卷积核大小来匹配多尺度特征融合。这种设计使我们的网络能够有效地执行多尺度的特征提取。此外,它还改进了跨不同尺度的特性的集成。
提出的方法
1.AMINet
在编码阶段,我们的网络的目标是提取不同尺度的特征,并捕获输入图像的多尺度特征表示F3,bottleneck继续细化特征F3并提供了一个信息更丰富的表示来获得细化的特征F4。在解码过程中,该网络侧重于特征上采样和面部细节重建。在编码和解码阶段之间采用交互式连接,以确保功能在整个网络中完全集成。具体如下。
(1)编码阶段
本阶段旨在提取不同尺度的面部特征。首先,使用3×3卷积来提取面部浅层特征,然
后,通过三个编码器阶段进一步细化提取的面部特征。每个编码器包括我们设计的LGFI和
一个降采样操作。每个编码器完成后,输入人脸特征的通道计数将加倍,输入人脸特征的图像大小将减半。
(2)bottleneck
在这个阶段,我们继续使用两个LGFI来细化和增强编码特性,以确保它们在解码阶段得到更好的利
用。在这一阶段之后,我们的模型可以不断增强不同尺度上的面部结构信息,从而提高人们对面部细节的感知。
(3)解码阶段
有三个解码器。我们专注于多尺度的特征融合,旨在在这一阶段重建高质量的人脸图像。每个解码器包括上采样操作、EDFF和LGFI。每个上采样操作符将输入特征通道计数减半,同时将输入面部特征的宽度和权重增加一倍。同时解码阶段使用我们提出的SKAF来自适应地选择性地融合来自编码器和解码器阶段的不同尺度特征。
损失函数为
其中N表示成对的训练人脸图像计数,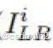
和
分别为第 i对的人脸LR图像和HR图像,FAMINet(·)和Θ分别表示AMINet和AMINet的参数个数。
2.LGFI
LGFI主要用于局部和全局的面部特征提取。由自注意(SA)、残差深度特征提取模块(RDFE)和选择性核注意融合组成模块(SKAF),分别用于局部和全局特征融合和交互。
(1)SA
SA提取全局面部特征,可以有效地建模远距离特征之间的关系。同时,通过SR中的多头机制,可以从不同的子空间中捕获特征,提高了模型的鲁棒性和泛化能力。具体结构和公式表示如下。



(2)RDFE

本文设计了RDFE来提取不同尺度下的局部面部特征。与传统的前馈网络(FFN)相比,RDFE有利于灵活地处理更复杂的特征和多尺度的特征。本文使用3×3、5×5和7×7的深度卷积并行提取三个尺度的人脸特征,深度卷积可以降低模型的计算复杂度,而不同核大小的卷积可以有效地提取丰富的人脸细节。同时使用了
计算了三个分支的融合特征的特征权重


其中Hcat是连接操作。最后用特征细化模块(FRM)来细化特征,首先应用归一化和多个3×3卷积层来细化局部面部上下文。之后,沙漏块Hourglass进一步集成了多尺度信息,以捕获全局和局部关系,其表示为
(3)SKAF
我们设计了一个SKAF模块,使我们的模型能够选择重建融合交互所需的局部和全局特征。对于全局特

征X1和局部特征X2首先将5×5卷积和7×7卷积提取的局部和全局特征融合,得到混合特征X。
然后,我们实施池化
学习获得的混合特征的权重,其中权重反映了不同接受方式下特征的重要性领域。获取选择权重的过程
所需的面部特征如下。
里Havp(·)表示平均池化操作,Hmap(·)表示最大池化操作。最后,我们将上述计算得到的权重分别与局部特征和全局特征相乘。
获取重要的局部和全局特征X的过程X’ , X’'通过自适应权重选择,可以表示为
这里Hcs(·)表示沿通道尺寸的特征分离操作。通过上述算子,我们可以得到自适应选择的局部特征和全局特征。
3.EDFF
为了充分利用从编码和解码阶段提取的多尺度特征,我们引入了一个EDFF来融合不同的特征,使我们的AMINet具有更好的特征传播和表示能力。EDFF主要利用我们提出的SKAF来融合和选择重建所需的不同尺度特征。然后,使用1×1的卷积来减少信道计数并降低了该过程的计算成本,得到了两个通过我们的SKAF权重。这些操作都可以表示为
接下来,我们输入得到的两个权重分成两个分支来进行乘法。通过这个操作符, 我们从混合特征中获得了所选择的面部特征
通过融合编码和解码特征而获得的。最终我们添加了这两个分支的特性。流程为

4.模型扩展
由于基于对抗gan的方法可以获得更好感知,我们将我们的AMINet扩展到AMIGAN生成更多高质量的SR结果。损失包括三部分。
(1)像素损失。用于减少像素 SR和HR图像之间的差异。
 2)知觉损失。
2)知觉损失。
利用预训练好的VGG19模型来提取面部特征从HR图像和我们生成的FSR图像中获得。
然后,我们比较了所获得的HR的感知特征和FSR图像来约束FSR特征的生成。因此,知觉损失可以描述

其中flVgg表示来自VGG网络的第1层的特征图,LVGG是VGG和 M的层数l Vgg指示该要素贴图中的元素的数量。
(3)对抗损失
GANs已被证明能有效地重建逼真的图像。GAN通过生成器生成FSR结果,同时使用鉴别器
来区分地面真实值和FSR结果,最终使生成器能够在持续对抗的过程中生成真实的FSR结果。此过程为。

生成器试图最小化
AMINet网络的损失函数为
5.实验
(1)数据集和评估指标
在我们的研究中,我们利用CelebA数据集分别对CelebA、Helen和SCface数据集进行训练和
评估。将对齐后的人脸图像进行中心裁剪,并将其大小调整为128×128像素,以获得高分辨率(HR)版本。然后将这些HR图像降采样到16×16像素使用双边插值,产生相应的低分辨率(LR)图像。随机选择了18000张CelebA图像进行训练,1000张进行测试。
为了衡量FSR结果的质量我们使用了五个指标: PSNR 、SSIM 、LPIPS 、VIF 和FID。
(2)实施细节
在NVIDIA GeForce RTX 3090上使用PyTorch框架实现了我们的模型。使用Adam优化器优化网络,参数设置为β1= 0.9和β2= 0.99.初始学习率为2×10−4,将生成器和鉴别器的单独学习率设置为1×10−4和4×10−4各自地损失函数的权值被配置为λpix= 1, λpcp= 0.01和λadv= 0.01。
(3)消融实验

设计了4种消融实验,第一个模型删除了SA,标记为“LGFI w/oSA”。第二个模型删除了RDFE,标记为“LGFI w/o RDFE”。第三个模型删除了SKAF,标记为“LGFI w/o SKAF“。
得到如下结论,(a)引入SA,RDFE单独可以提高模型性能。这是因为上述两个模块可以捕获局部和全局特征,促进面部特征重建,包括面部细节和整体轮廓;通过引入SKAF来捕捉局部和全局面部特征之间的关系,(b)模型的性能显著提高。这是因为我们的SKAF可以促进我们的SA和RDFE之间的交互 ,整合更丰富的信息,并为最终的FSR图像重建提供补充信息。
LGFI和Transformer比较。LGFI使用双分支结构与表示局部和全局特征进行交互。相比之下,传统的
Transformer在修复器中使用一个串行结构来连接局部和全局 特征。为了验证LGFI的有效性,我们将网络中的所有LGFI替换为Transformer,并对两种模型之间相似的参数进行了比较实验 。从表二可以看出,当两个网络保持相似的参数时,使用 LGFI的网络性能更好。 这是因为LGFI同时利用了本地功能和其他特性
全球互动分支,促进多尺度面部信息的交流。

RDFE和FFN的比较。前馈网络(FFN)对每个位置的输入进行独立的非线性变换,以帮助变压器捕获局部特征,但它缺乏提取多尺度特征的能力,这不利于精确的FSR。相比之下,我们的RDFE可以很好地提取多尺度的局部特征。为了比较RDFE和FFN,我们用FFN将RDFE替换为FFN,同时保持两种模型的参数相似。如表3所示,由于与我们的RDFE利用多个分支捕获不同的感受野面部特征相比,FFN捕获特征交互的
能力有限,因此我们的RDFE在类似计算消耗的情况下比FFN表现得好得多。
RDFE的有效性。采用注意机制引导的三分支网络进行深度特征提取,利用特征细化模块丰富特征表示。为了验证RDFE的有效性,我们进行了多次消融实验。我们设计了五个改进的模型。第一个模型采用3×3深度卷积的单分支结构,标记为“单路径(3×3dw)”。第二种模型采用5×5深度卷积的单分支结构,标记为“单路径(5×5dw)”。第三种模型采用7×7深度卷积的单分支结构,标记为“单路径(7×7dw)”。第四种模型去掉了注意力单位标签为“没有AU”。第五个模型删除了该特性细化模块,标记为“w/o FRM”。从表四中,我们有以下观察结果: (a)通过比较表的前三行和最后一行,可以看到,多尺度分支能够提取不同层次的人脸特征,有利于模型的性能;从表的第二行和最后行与最后一行的比较可以看出 ,使用注意单元(AU)指导三分支特征提取可以使模型自适应分配权重,增强重要面部信息的表示,从而提高模型性能 ;©从表的最后两行中,我们可以得出结论,特征细化模块(FRM)模块可以进一步集成多尺度信息,细化多尺度融合特征,从而提高性能。

SKAF的有效性: SKAF是LGFI的重要组成部分,促进本地和全局分支之间的信息交换。我们进行了一系列的消融实验 来验证我们的SKAF模块的影响,并评估联合方法的实用性。
由于SKAF由双分支卷积层、最大池化层和平均池化层组成, 因此我们验证了SKAF中模块组件的有效性。从表中,我们 有以下观察: (a)从表的最后三行,我们发现使用单一池分支导致性能降低,而单独使用平均池结果比使用最大池化的性能更低 这是因为面部的显著特征是面部恢复的关键,最大限度地集中关注
显著的面部特征信息。相比之下,平均集中化关注的是面部的整体信息。(b)与第三行和第五行相比,可以得出结论, 同时使用5×5和7×7可以提高不同感受域下的表现,充分利用关键面部信息。

EDFF的研究:本节介绍了一组实验来验证我们的EDFF的有效性,这是一个为融合多尺度特性而量身定制的模块。我 们将EDFF添加到SPARNet 中,它使用EDFF来连接SPARNet中的编码和解码阶段,并将它们发送到下一个解码阶段。此外,我们将EDFF添加到SFMNet [20]中,具体操作与SPARNet中相同。从表六的结果中可以看出,虽然两种模型的参数都略有提高,但模型的性能却有所提高,这准确地证明了EDFF在编码和解码阶段的特征融合有一定的帮助。
(4)与其他方法的比较
本节将我们的AMINet及其基于GAN的变体与目前可用的领先FSR方法进行了比较,包括
SAN,RCAN,HAN,SwinIR,FSRNet,DICNet、FACN、SPARNet、SISN、AD GNN、Restormer-M、LAAT、ELSFace,SFMNet和SPADNet。
a.在CelebA数据集上的比较。我们在CelebA测试集上对 AMINet与现有的FSR方法进行了定量比较,详见表7。

我们的 AMINet优于所有其他评估指标,包括PSNR、SSIM、LPIPS和VIF,这充分证明了它的效率。这个强烈地验证了AMINet的有效性。此外,图中的视觉比较。揭示了,以前的FSR方法难以准确地复制眼睛和嘴巴等面部特征。相比之下,AMINet擅长保存对面部结构和产生更精确的结果,证明了其有效性。
b.在Helen数据集上的比较。我们在测试集上评估我们的 方法,以进一步评估AMINet的多功能性。表7提供了×8 FSR 结果的定量比较,其中AMINet取得了更好的性能。图中的视 觉比较。表明现有的FSR方法难以保持准确性,导致形状模糊和面部细节的丢失。相比之下,AMINet成功地保留了面部轮廓和细节,增强了其在不同数据集上的有效性和适应性。
c.与基于Gan方法的比较。我们提出了AMIGAN作为一种创新的方法来提高图像恢复任务的视觉保真度。为了证实其优越性,我们将AMIGAN与最先进的基于gan的方法进行了严格的比较,即FSRGAN ,DICGAN ,SPARGAN 和 SFMGAN 。作为一个补充的评估指标,我们引入了FID 来定量评估GANs的性能。表八中的数据来自对Helen数据集的测试,显示AMIGAN远远超过其竞争对手。

此外,目视检查如图所示。强调了AMIGAN的卓越能力。不像现有的FSR方法,它们显示出可见的在生成的面部图像中,AMIGAN精心地恢复了关键的面部特征和口鼻周围复杂的纹理细节,这强调了AMIGAN在面部纹理修复方面的威力。
d.与真实面孔的比较。为了进一步评估我们的模型在现实世界条件下的性能,我们还使用来自SCface数据集的低质量人脸图像进行了实验。

我们直观地比较重建结果。从图中,我们发现基于人脸先验方法的重建结果并不令人满意。挑战在于从真实世界的LR面部图像中准确地估计先验。不正确的先验信息会导致重建过程中的误导性指导。相比之下,我们的AMINet可以恢复更清晰的面部细节和忠实的面部结构。该结果充分证明了我们的方法在实际场景中的有效性。
(5)模型的复杂性分析
除了前面提到的性能指标外,模型参数的数量和推断时间是评价绩效的关键因素。
如图所示。1、我们在参数、PSNR值和推理速度方面与现有模型进行比较。我们可以看到,AMINet在保持快速推理时间和小参数计数的情况下仍然表现良好。
结论
文章提出了一种注意力引导的人脸超分辨率多尺度交互网络。具体来说,我们设计了一个LGFI,它允许从自注意中获得的全局特征和从我们设计的RDFE中获得的局部特征的可访问性通信。为了增强RDFE中局部特征的杂色性,我们采用多尺度深度可分离卷积核结合注意机制来提取和细化局部特征。此外,为了在不同尺度上自适应地融合特征,我们提出了一种RDFE,利用注意机制来选择适当大小的卷积核来促进特
征融合。在合成和真实测试集上的大量实验表明,我们设计的模块显著改善了不同尺度上的特征与模块的通信,使得我们提出的方法在FSR性能、模型大小和推理速度方面优于现有的方法。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









