







浅谈这篇论文
Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning —2020CVPR
视频文本检索可以作为知识图谱中的多模态语义对齐,因为要做多模态知识图谱,所以先学习一些视频语义对齐,也就是视频文本检索相关文章。简单浅谈一下。
这个任务的公共点,首先将视频和文本查询进行编码,然后将他们映射到一个公共空间,在这里视频文本的相似度可以直接计算出来。这个过程重要的是视频编码、文本编码和公共空间学习的形式。论文提出的模型叫HGR,主要思想是对视频和句子进行三个层次的编码,每个层次求个相似度,整合三个相似度匹配的结果。第一是全局层次,也就是整个句子和整个视频匹配,第二个层次是提取了句子中动词部分,对应相应的视频片段,第三个是句子中实体单词部分。论文中分词和词性标注是直接用现有工具提取的。具体处理如下。
一、句子的处理
图1是论文中处理句子描述的框架图,对句子生成一个角色图,其中句子成分使用现成的工具来解析获取动词、名词短语以及每个名词短语对对应动词的语义角色(现在工具多的很,什么哈工大的LTP,斯坦福的也有等等等等)。
 图1
图1
HGR0层句子编码取的BiLSTM的两个方向处理结果的平均。对结果乘以了一个注意力系数α。具体含义论文讲很清楚,这里也很简单。
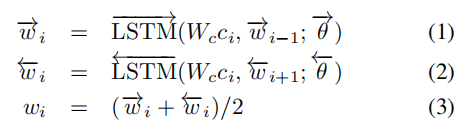
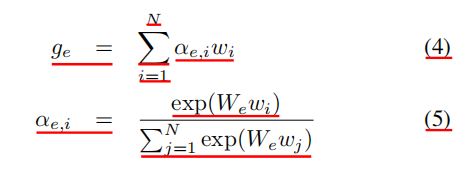
文中提出了一种基于注意力的图推理。对图中的交互进行推理,以获得分层的文本表示。利用关系GCN对图中的交互进行建模是一种直接的方法,该方法需要为每个语义角色学习单独的转换权矩阵。为了解决这个问题,将GCN中的多关联权值分解为两部分:对于所有关系类型,共有的公共转换矩阵Wt∈RD×D,以及针对不同语义角色的角色嵌入矩阵Wr∈RD×K,其中D为节点表示的维数,K为语义角色的个数。对于第一个GCN层的输入,将初始化的节点嵌入gi∈{ge, ga, go}与它们对应的语义角色相乘:
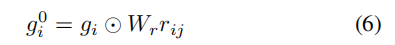
其中,rij是一个one-hot编码的向量,表示节点i到j的边缘类型。假设gli是节点i在第lGCN层的输出表示,采用图注意网络从相邻节点中选择相关上下文来增强每个节点的表示:
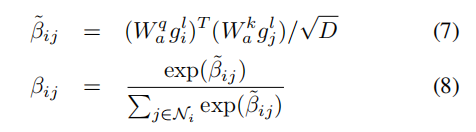
其中Ni是节点i的邻域节点,Wak和Wqa是计算图注意的参数。然后共享利用Wt,将上下文从有关注的节点转换到具有残差连接的节点i:
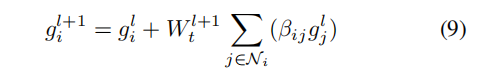
以GCN第一层为例,计算如下
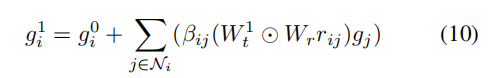
作者这样处理这样,就将参数的大小从L × K × D × D显著减小到L × D × D + K × D,其中L是GCN的层数。gcn第L层的输出是最终的层次文本表示,Ce表示全局事件节点,Ca表示动作节点,Co表示实体节点。
二、视频的处理
构建了三个独立的视频嵌入。利用帧的特征序列,乘上三个参数(对应文本的三个层次e,a,o),其中全局层面乘了一个类似于文本那的注意力系数。其他的就是乘完系数矩阵就完事了。
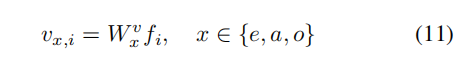
匹配问题:在三个层次分别匹配,最后融合
全局匹配用余弦相似度,动作和实体级别,需要学习局部分量之间的对其方法来计算总体匹配分数。对于每个cx,i∈cx其中x∈{a, o},首先计算每对交叉模态局部分量sx ij = cos(vxj,cxi)之间的局部相似度。计算了一个注意力权值,作为文本节点在跟视频帧匹配的时候的权值(用这个系数乘局部余弦相似度的结果),使用c动态地对准视频帧(可能是用某个单词编码对找最匹配的帧)。每种结果为Sx=sum(Sx,i) x属于(a,e,o)
总结
这篇文章的两点就在于结合了图结构,对句子分成了全局、动作和实体三个层次,总体思想还是对视频和句子分层编码然后匹配,实验对比部分其中有一个是跟Dual Encoding2019初版的做了对比,效果可以,后续2021年Dual Encoding又有了改进,又把HGR比下去了,挺有意思的。















 4363
4363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









