







《Cross-Modal and Hierarchical Modeling of Video and Text》(2018 ECCV)
这篇文章主要介绍了一个叫做分层序列嵌入(Hierarchical Sequence Embedding, HSE)的通用模型,其作用是对不同模态的数据进行分层建模并利用模态间的对应关系来学习模型参数。文章以文本和视频之间的检索为例进行介绍,并在大型数据集上做了实验。
HSE是在已有的FSE(Flat Sequence Embedding)的基础上改进后的模型。FSE的模型如下:

FSE是一种原始的seq2seq方法,它不考虑视频或文本中的层次结构,因此称为平面序列嵌入。如下式所示。
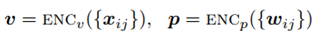
然后得到相似度:

但是FSE的一个明显的缺陷在于其LSTM层需要大量的单元才能很好地对视频帧或者单词进行建模,因此优化和学习都会比较困难。而HSE在FSE的基础上添加了一些组件,从而可以从多个粒度来考虑视频和文本之间的对应关系,较好地利用数据中的层次结构来减少计算单元。HSE的框架如下图所示(红色部分是增加的组件):

在HSE中,使用前向路径来计算嵌入:
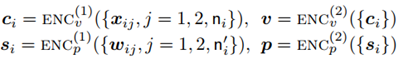
在构造损失函数时,考虑到以下几个损失。
判别性损失:
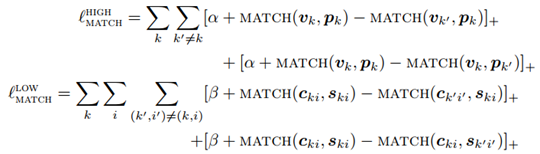
对比损失:
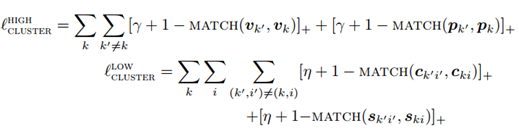
重构损失:

最后,总体的损失函数就是把以上三种函数相加:
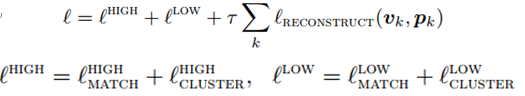
在实验部分,作者在三个大型数据集上进行了实验:ActivityNet Dense Caption,DiDeMo和ActivityNet Action Recognition数据集。这三个数据集都包含大量的视频和对应的文本,采用的评估指标有R@K和MR(中位数)。实验结果如下:

表格的前四行是已有的最新方法,C3D和Inception-V3是不同的特征表示。从表格中可以看出,和FSE相比,HSE(τ=0)和HSE(τ=5e-4)都大大提高了检索中所有指标的性能,这也就意味着分层建模能够很有效地捕获视频与段落、片段与句子之间的结构信息和对应关系。此外,在实验中,HSE(τ=0)始终优于HSE(τ=5e-4)的性能,表明通过改变τ的取值可以调节模型的性能,从而说明模型具有一定的泛化性。
总结
这篇文章将HSE和FSE进行了对比,从实验结果可以看出,从多个粒度出发来考虑不同模态数据之间的对应关系是可以在一定程度上提高模型的检索性能的,甚至可以达到降低计算复杂度的效果。















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









