







 本文介绍了近年来视频文本检索领域的研究进展,涉及多个重要工作,如MMT、T2VLAD、CLIP4Clip、CLIP2Video、CAMoE、VALUE、HERO和HiT。这些工作通过多模态学习和时间序列对齐,提高视频和文本的匹配精度,解决检索挑战。文章讨论了各种模型的动机、方法和性能,揭示了预训练模型如CLIP在视频文本检索中的应用潜力。
本文介绍了近年来视频文本检索领域的研究进展,涉及多个重要工作,如MMT、T2VLAD、CLIP4Clip、CLIP2Video、CAMoE、VALUE、HERO和HiT。这些工作通过多模态学习和时间序列对齐,提高视频和文本的匹配精度,解决检索挑战。文章讨论了各种模型的动机、方法和性能,揭示了预训练模型如CLIP在视频文本检索中的应用潜力。

©PaperWeekly 原创 · 作者 | 小马
单位 | FightingCV公众号运营者
研究方向 | 计算机视觉

写在前面
近几年,随着抖音、快手等短视频平台,以及哔哩哔哩、优酷等视频平台的出现,网络中出现了大量的视频媒体。海量视频媒体给视频内容的准确检索带来了巨大挑战。在本文中,我们将介绍一些近几年视频文本检索的文章,让大家了解视频文本检索的最近工作进展。

工作介绍
2.1 MMT——ECCV 2020
2.1.1. 论文信息

论文标题:
Multi-modal Transformer for Video Retrieval
论文地址:
https://arxiv.org/abs/2007.10639
代码地址:
https://github.com/gabeur/mmt
2.1.2. 论文动机

进行视频文本检索的关键是学习精确的视频-文本表示,并建立相似度估计。目前的方法主要存在两个方面的缺陷:1)没有充分利用好视频中动作、音频、语音等各个模态,从上图中可以看出,从所有组成模态中联合提取的线索比单独处理每个模态更具信息性;2)没有充分考虑视频的时间性,由于数据集中的视频时长不一样,目前的方法通常是通过聚合视频中不同时刻提取的描述,从而丢弃长期时间信息。
在本文中,作者提出了一个多模态 Transformer(MMT)来解决上面的挑战,首先提取不同时刻和不同模态的特征,将他们聚集在一个紧凑的表示中,并用 Transformer 进行不同时间和模态信息的交互,最终基于聚合特征来评估视觉和文本之间的相似性。
2.1.3. 论文方法
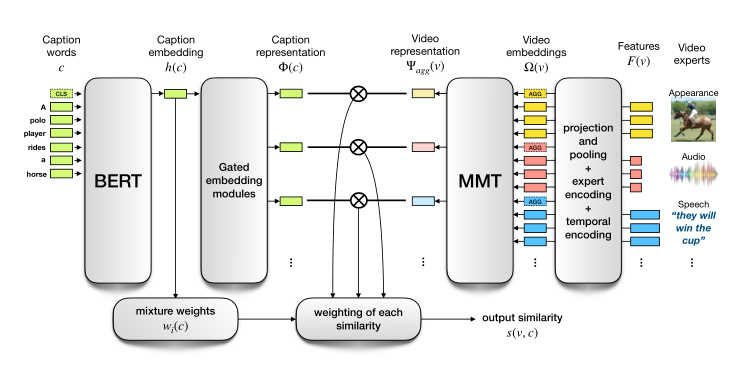
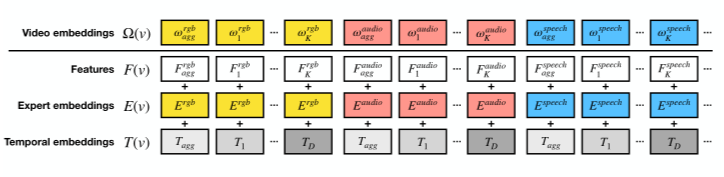
本文的结构如上图所示,本文的特征提取用的是预训练的 BERT,视频的特征用的是不同的预训练好的“专家”模型来提取不同模态的特征,每个模态采用 max-pooling获得一个聚合特征,然后将提取的特征和专家 embedding、时间 embedding 相加能到最终的视频特征(如下图所示)。
作者用一个多模态 Transformer(MMT)来建模这些特征的不同模态和时间的关系,最终获得具有代表性的聚合特征,然后用不同聚合特征和文本特征求相似度,并对其进行加权求和,得到最终的视频本文相似度。
2.2 T2VLAD——CVPR 2021
2.2.1. 论文信息

论文标题:
T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
论文地址:
https://arxiv.org/abs/2104.10054
代码地址:
未开源
2.2.2. 论文动机
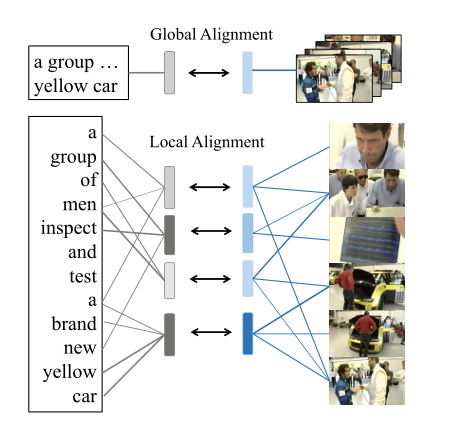
目前进行多模态匹配的方式有两种,一种是全局的粗粒度匹配,这种方式简单,但是忽略了细粒度的语义对齐;另一种是细粒度的语义对齐,目前通常是设置三个语义级别(事件、动作和实体),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2975
2975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









