







论文:Two-Stream Convolutional Networks for Action Recognition in Videos
这篇文章是NIPS 2014年牛津大学提出的一个双流网络来做视频行为识别,比较经典。论文的三个贡献:(1)提出了two-stream结构的CNN,由空间和时间两个维度的网络组成;(2)使用多帧的稠密光流场作为训练输入,可以提取动作的信息;(3)利用了多任务学习的方法把两个数据集联合起来。
1. Q:双流网络的具体结构是什么?
A:

该网络有两个独立的识别流——空间和时间,在网络尾部再融合在一起。空间流从静态的视频单帧中识别动作,而时间流以稠密光流的形式从运动中识别动作。这两个流均为ConvNets。由于空间卷积神经网络本质上是一种图像分类体系结构,所以可以使用图像识别的方法,在大型图像分类数据集(如ImageNet challenge数据集)上对网络进行预训练。时间流的输入是通过在几个连续帧之间叠加光流位移场来实现的。
2. Q:双流网络尾部如何将空间和时间两个维度信息进行融合?
A: 文章考虑了两种融合方法,空间流和时间流分别经过softmax后做class score fusion:(1)求平均;(2)以L2正则化的softmax输出作为特征,训练多分类线性SVM。
【PS】《Convolutional Two-Stream Network Fusion for Video Action Recognition》详细讨论了不同的fusion方法。
3. Q:光流optical flow是什么?如何计算?
A: 稠密光流(dense optical flow)可以看作是连续帧
t
t
t 和
t
+
1
t+1
t+1 之间的位移向量场的集合。用
d
t
(
u
,
v
)
d_t(u,v)
dt(u,v) 表示第
t
t
t 帧中点
(
u
,
v
)
(u,v)
(u,v) 移动到下一帧
t
+
1
t+1
t+1 中相应的点的位移向量。向量场
d
t
d_t
dt 包含两部分(因为每个像素点有x和y方向的移动):水平分量
d
t
x
d_t^x
dtx 和垂直分量
d
t
y
d_t^y
dty,可以看作是图像通道(如图2所示)。L表示堆叠的帧数,那么一共可以得到2L个通道的光流,然后才能作为Figure1中Temporal stream ConvNet的输入。

假设一个视频的宽和高分别是 w 和 h,那么Figure1中Temporal stream ConvNet的输入维度
I
τ
I_τ
Iτ 应该是下式 ,其中
τ
τ
τ 表示任意的一帧。
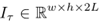
那么怎么得到
I
τ
I_τ
Iτ 呢?文章介绍了两种计算
I
τ
I_τ
Iτ 的方式,分别为optical flow stacking和trajectory stacking,这二者都可以作为前面Temporal stream ConvNet网络的输入,接下来依次介绍。
Optical flow stacking(光流的简单叠加):
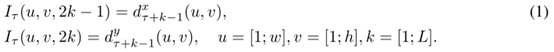
公式(1)给出了水平和垂直方向的
I
τ
I_τ
Iτ 的计算公式,其中
(
u
,
v
)
(u,v)
(u,v) 表示任意一个点的坐标,
c
c
c 是通道,
c
=
[
1
;
2
L
]
c=[1;2L]
c=[1;2L] ,因此
I
τ
(
u
,
v
,
c
)
I_τ(u,v,c)
Iτ(u,v,c) 存的就是
(
u
,
v
)
(u,v)
(u,v) 这个位置的位移向量。简单的光流场叠加并没有追踪,每个都是计算的某帧
t
+
1
t+1
t+1 中某个像素点
(
u
,
v
)
(u,v)
(u,v) 相对于
t
t
t 帧中对应像素点
(
u
,
v
)
(u,v)
(u,v) 的位移,光流场叠加最终得到的是每个像素点的两帧之间的光流图。(如Fig. 3-left)
Trajectory stacking (轨迹叠加):
轨迹叠加就是假设第一帧的某个像素点,我们可以通过光流来追踪它在视频中的轨迹。在几个帧的相同位置采样,沿着运动轨迹采样。帧
τ
τ
τ 对应的输入
I
τ
I_τ
Iτ 为
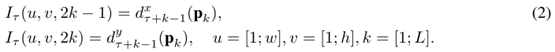
P
k
P_k
Pk是轨迹上的第 k 个点,在帧
τ
τ
τ 的开始位置为
(
u
,
v
)
(u,v)
(u,v),且定义以下递推关系:
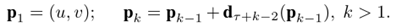
公式(1)中
I
τ
(
u
,
v
,
c
)
I_τ(u,v,c)
Iτ(u,v,c) 存的是位置
(
u
,
v
)
(u,v)
(u,v) 处的位移向量(displacement vectors),而公式(2)中
I
τ
(
u
,
v
,
c
)
I_τ(u,v,c)
Iτ(u,v,c) 存的是沿着轨迹
P
k
P_k
Pk 采样的向量。(如Fig. 3-right)

4. Q:多任务学习(Multi-task learning)怎么做?
A: Spatial stream ConvNet输入的是静态的图像,所以其预训练模型较容易得到(一般采用在ImageNet数据集上的预训练模型),但是Temporal stream ConvNet的预训练模型需要在视频数据集上训练得到,目前可供训练的视频数据集很少,所以作者提出能不能把多个数据集(这里就是UCF101和HMDB-51,训练集数量分别是9500和3700个视频)联合起来,这样还能避免过拟合的现象。由此文章采用multi-task的方式来解决。怎么做的呢?
首先原来的网络(Temporal stream ConvNet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算UCF-101数据集的分类输出,另一个用来计算HDMB-51数据集的分类输出,这就是两个task。这两条支路有各自的loss,最终的loss就是两个loss的和,然后回传更新参数。所以这里的重点就是:网络全卷积层是不变的,或者说对于两个数据集是共享参数的。只是改变了最终的loss。
5. Q:实验结果及评价?
A: 数据集:

评价标准:
作者提供了三组训练和测试数据,并通过平均分类精度(mean classification accuracy)来衡量模型性能。每次分割UCF-101包含9500个训练视频,每个HMDB-51分割包含3700个训练视频。
实验一:

Table1是两个网络的实验结果,数据集都是UCF-101(split 1)。对Spatial ConvNet测试其性能,考虑三个因素: (i) 从头训练UCF-101;(ii) 在ILSVRC -2012预训练模型基础上,用UCF-101进行微调;(iii) 保持预训练网络固定,只对最后一层(分类)微调。pre-trained+fine tuning表示用预训练网络的参数初始化所有层,然后对所有层fine tune;pre-trained+last layer同样是用预训练网络的参数初始化所有层,但是只对最后一层fine tune,也就是前面那些层的参数在初始化后固定不变从实验结果可以看出直接在UCF-101数据集上从头开始训练容易过拟合。在后面的实验中作者采用第三种做法,也就是在预训练模型的基础上只fine tune最后一层的参数。
(b)表示Temporal stream ConvNet的几种不同类型输入的差别,训练都是从头开始(from scratch)。其中Optical flow stacking和Trajectory stacking在前面介绍过了。注意参数L对结果的影响,第一行中L=1相当于只给了一帧图像,另外在后面的实验中作者采用L=10。可以看出Optical flow stacking的效果要优于Trajectory stacking。最后一行的bi-dir表示bi-directional optical flow(双向光流),而采用双向光流叠加的效果仅略好于单向正向光流叠加。通过对比(a)和(b)可以看出Temporal stream ConvNet的效果要优于Spatial stream ConvNet,这证明了动作识别中运动信息的重要性。
实验二:

Table2是multi task的实验结果。为了有效增加HMDB-51训练集的大小,作者评估了不同的选项:(i) 微调在UCF-101上预训练的temporal network; (ii) 从UCF-101中添加了与HMDB-51没有交集的78个类,这些类是手动选择的; (iii) 采用多任务学习,在UCF-101和HMDB-51分类任务之间共享权值。从表中看出多任务学习表现最好,因为它允许训练过程利用所有可用的训练数据。
实验三:

Table3是双流网络的不同构建方式的实验结果对比,使用平均或线性SVM来融合softmax得分。由Table3可知:(i) 时间和空间识别流是互补的,因为它们的融合在这两方面都得到了显著的改善;(ii) 基于SVM的softmax融合性能优于平均融合;(iii) 双向光流的效果没有其他好;(iv) 使用多任务学习进行训练的temporal ConvNet,无论是单独使用还是与空间网络融合使用都表现得最好。
实验四:
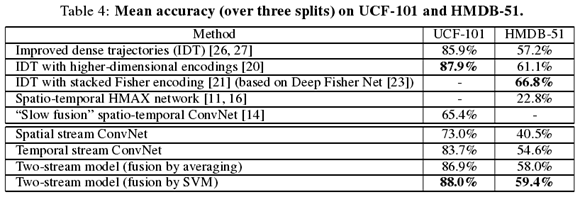
Table 4是two stream convnet和其他算法的对比。从Table 4可以看出,本文的双流网络在很大程度上都优于[14,16]的deep architecture,并可与state-of-the-art hand-crafted models相比较[20,21,26]。
其他细节
6. Q:Bi-directional optical flow(双向光流)是什么?
A: 光流的简单叠加和轨迹叠加两个方法其实考虑的都是前馈光流,都是依靠后一帧计算相对于前一帧的光流。当我们考虑 T 帧时,我们不再一直往后堆 L 帧,而是计算 T 帧之前 L/2 和 T 帧之后的 L/2 帧。
7. Q:Mean flow subtraction(减去平均光流)是什么?
A: 这主要是为了消去摄像头运动引起的相对运动。给定一对帧,它们之间的光流可以由特定的位移控制,例如通过摄像机的移动。所以需要从稠密光流中估计并减去全局运动分量。在论文中,作者考虑一个更简单的方法:在每一个位移场d中都减去它的平均向量。
总结:
优点:(1)提出了two-stream(spatial stream convnet获取图像目标和场景的appearance,temporal stream convnet获取时序motion信息),开创了two-stream视频分析时代;(2)2014年取得了state-of-the-art效果。
不足:(1)不是完全end-to-end的视频分析,需要离线计算光流,计算光流比较耗时,没法达到实时;(2)解决的是short-term video分析,没法有效的解决long-term video分析。















 6109
6109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









