







本文对TextCNN(原论文:Convolutional Neural Networks for Sentence Classification)做了大量调参实验,给出了很多使用TextCNN进行文本分类的具体建议。TextCNN的论文解析在网上有很多已有的博客可以参考,这里只是简述。
TextCNN结构如图:
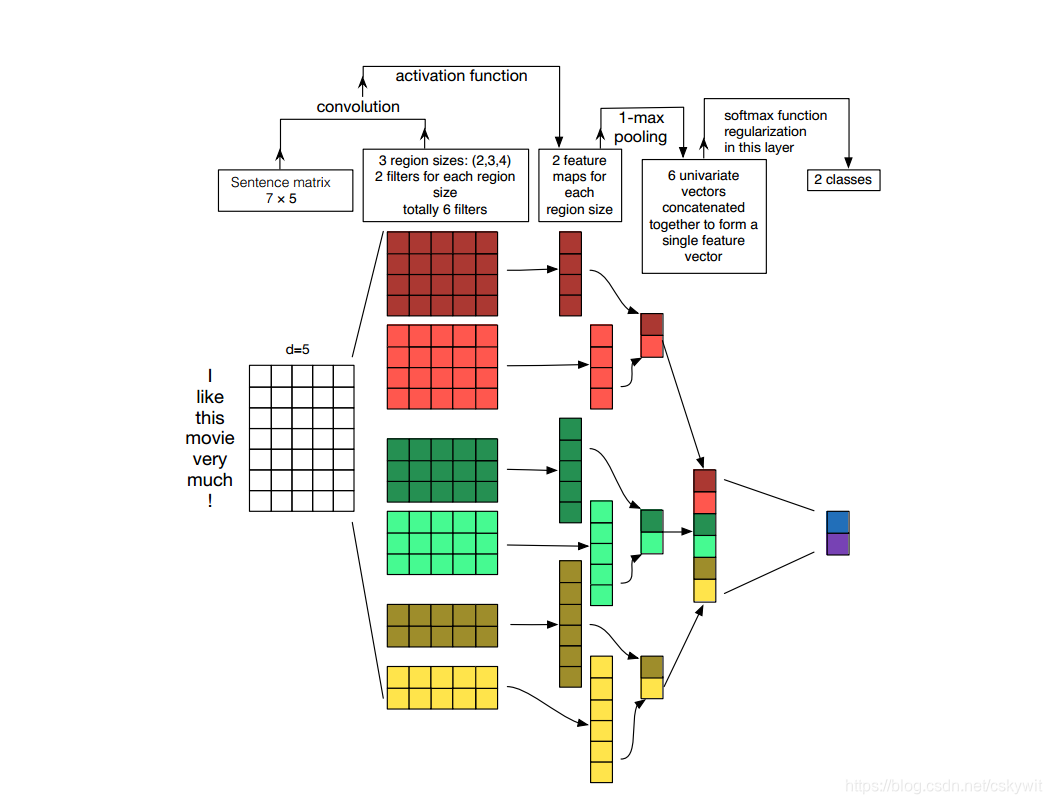
网络原理简述:网络输入是句子,其中的每个单词已经通过one-hot、word2Vec或gloVe映射为词向量,一个句子构成一个词数*词嵌入维度大小的矩阵,类似图片格式一样。然后经过不同大小的filter卷积,文中设置为(region_size*词嵌入维度),输出(句子长度- region_size+1)*1维的向量。经过max-pooling得到一个数值,将各个filier的输出值经过max-pooling后的值拼接起来进行最后的分类。
可调的网络参数:输入的词向量表示,filter region_size,特征图的数量,激活函数类型,池化策略,正则化方法。
实验结论:
1.使用预训练的词向量(word2Vec或gloVe)对分类性能提升明显,如果可训练数据多,针对任务从头开始训练效果更好。文中也尝试使用word2Vec+gloVe的词向量,效果不明显。
2. filier region_size对效果有很大影响,需要重点调参。文中给出的建议是,先使用单个filter线性搜索最佳的region_size,通常使1~10。找到最小大小后,组合多个region_size与最佳大小相同的filter,或多个region_size与最佳大小相近的filter可以实现很明显的想过提升。注意组合时候region_size不要偏离最佳大小太多。
3.针对每种region_size,filter map的数量可以探索,但超过600以后提升不明显甚至性能下降。
4.相比global/local average pooling,k-max pooling,local max-pooling,gobal max-pooling效果最好。
5.正则化对性能的提升影响不大,文中猜想由于词向量本身就有缓解过拟合的作用。
6.Relu和tanh激活效果比其他方式好。
7.尽量使用cross-fold应对单词训练的variance。

















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









