






作者简介
Graviton,携程研发总监,专注数据思维驱动团队效能与技术发展。
本文旨在通过一个实际的例子,说明如何通过数据思维来解决研发工作中的一些棘手问题。通过此文,希望能够清楚地阐述我对下面几个问题的理解:
【What】什么是“数据思维”?
【Why】为什么要用“数据思维”去解决问题?
【Who】数据分析师、开发工程师、测试工程师、产品经理等各角色在这个领域内的定位?
【How】能否用一个清晰可复制的流程来描述“数据思维”的执行过程?
一、什么是“数据思维”?
我从Brian Godsey的著作《THINK LIKE A DATA SCIENTIST——Tackle the Data Science Process Step-by-Step》一书中,深受启发,书中提到:“数据科学的核心并不关注数据库的具体实现或者编程语言,即使这些内容对从业者而言是不可缺少的。其核心在于数据内容之间的相互作用,给定项目的目标以及用于实现这些目标的数据分析方法。”
数据科学是一门新兴学科,说白了就是一种方法论。结合书名所提,“数据思维”本质上就是应用这种方法论去思考 (Think) ,去分析、理解“数据内容之间的相互作用”,再结合“数据分析方法”,去实现“给定项目的目标”。
二、为什么要用“数据思维”?
数据的价值已是公认的共识。数据可以从理性客观的方式来表达方向、程度、结果等等。拿互联网行业的研发工作为例,我们经常面对“如何用有限的研发资源来解决更多的需求”这样的问题,相比靠经验决策,相对公平、有效的解决方案唯有通过数据去量化每个需求带来的收益,从而可以有一个评判标准决定优先级;再者,我们也通常会用“影响多少订单量”这样的数据来衡量一个故障的严重程度;同时,我们也会定义一些特征、主动标记和采集一些符合这些特征的数据,从而可以衡量某个特定问题的结果,比如通过某些数据说明系统的用户体验得到了提升。总之,建立在数据之上的思考和讨论,往往更清晰,更易理解,更具说服力。
三、角色与定位
一般成熟的团队都会有数据分析师,数据科学家这样的角色,从工作职能上来讲,分析类的工作应该归属于他们。他们可以利用统计学、算法模型、机器学习等专业手段,把混沌未知的问题转化成更易于决策的数据依据。比如,如何优化一个搜索功能,让用户更快地搜索到他们感兴趣的产品或内容。
但今天讨论的“数据思维”,我认为并不专属于他们,而理应所有的职能角色都应该具备。而且掌握数据科学相关的专业知识并不是“数据思维”得以实践的必要条件。比如研发需要记录标识用户行为、系统状态等数据的埋点,并能分析它们以用于技术排障;测试工程师需要记录bug产生的数量,给它们按照严重程度分类,并通过统计不同项目产生bug的变化来评价项目质量;产品经理需要通过AB实验对比转化率、点击率等等这些最基本的指标,以验证产品收益是否符合预期……
四、流程
接下来,我们就以一个实际的例子来说明:如何利用“数据思维”来解决一个棘手的问题——页面性能优化。我尽可能详细地把“数据思维”相关的全过程记录下来,包括基于数据的思考过程,脱敏后的技术实现方法等。
第一步:我们需要明确问题和目标
问题1:我们的预定页面一直被用户投诉,非常慢,体验很差!
问题2:现阶段,我们各组能用于专项提升用户体验的研发和测试资源都非常有限!
从上述两个问题,我们设定期望的目标:挤出少量的研发和测试资源,限定一个特定场景,看到用户体验上的正向变化。我们限定了如下场景:
商旅酒店频道
H5
列表页
第1页(首屏)
默认筛选条件
第二步:找到量化指标
明确问题和目标后,我们需要找到几个有效且容易采集的指标来评价我们的问题和目标。
指标1: 自采TTI
我们很容易想到,评价用户体验最直观的感受就是要“快”,从定义上来讲,就是从页面访问开始到看到列表卡片这段周期的耗时。这个数据很容易就可以被采集,开始和结束两个时间戳减一下,单位是毫秒。然后把一个时间片段内所有采集到的这种耗时从小到大排列,取第95%小那个位置的值,叫95分位(类似方法称percentile,也叫分位线,后续统一用95L表示),这个值的意义是代表95%的访问都小于这个耗时,可以代表绝大多数的用户。
这是个综合性指标,代表了几乎整个页面首屏加载的生命周期,既包含了客户端因素,也包含了服务端因素。为方便描述,我们计这个指标为“自采TTI(Time to Interactive)”。
这里假定:我们已经部署了基于Apache Hadoop生态下的存储系统(HDFS)、数仓(HIVE)和查询分析引擎(SPARK),以及至少一种可定期调度执行特定脚本的工具(比如crontab),具体的部署方案超出了本文的介绍范围,不再赘述。
我们在客户端开发过程中,有很重要的一个步骤就是埋点的设计和开发。客户端开发会把特定埋点的结构化信息上报到服务端(这个过程使用了Kafka),然后会以特定的结构放入HIVE数仓。
以“自采TTI”为例,转换成JSON格式后大概是这样:
{
"key": "o_corp_htl_performance",
"ts": 1630653123093,
"userId": "012345",
"pageId": "1234567890",
"sessionId": 2940023,
"data":"{\"name\":\"customTTI\",\"latency\":1729,\"startTime\":1630653123093 }\""
}这能映射到HIVE上的一张表,每个key对应表里的一个字段。这是比较通用的一张表,通过自定义data字段,客户端可以上报各种自定义类型的数据。
下面是对应的按天分区的建表语句。
CREATE TABLE `edw_corp_frontend_tracelog`(
`ts`: bigint COMMENT '访问时间戳',
`key`: string COMMENT '埋点Key',
`userId`: string COMMENT '用户ID',
`pageId`: string COMMENT '页面ID',
`sessionId`: string COMMENT 'Session ID',
`data` string COMMENT '自定义埋点内容')
COMMENT '客户端页面自定义埋点表'
PARTITIONED BY (`d` string COMMENT 'date')
STORED AS ORC;最后,有了这张表后,我们可以通过执行一句简单的SQL得到每一天的“自采TTI”的95L聚合数据。
SELECT d,
avg(latency) as avg_latency,
percentile(latency, 0.5) AS P50_latency,
percentile(latency, 0.95) AS P95_latency
FROM
(SELECT d,
userId,
pageId,
CAST(get_json_object(`data`, '$.latency') AS bigint) AS latency
FROM mytracedb.edw_corp_frontend_tracelog
WHERE d>'2021-01-01' AND get_json_object(`data`, '$.name)='customTTI') AS dx
GROUP BY d我们可以把这个结果集导到某个数据可视化工具(Tableau/Excel)上展示,这样可以更加直观,如下图:
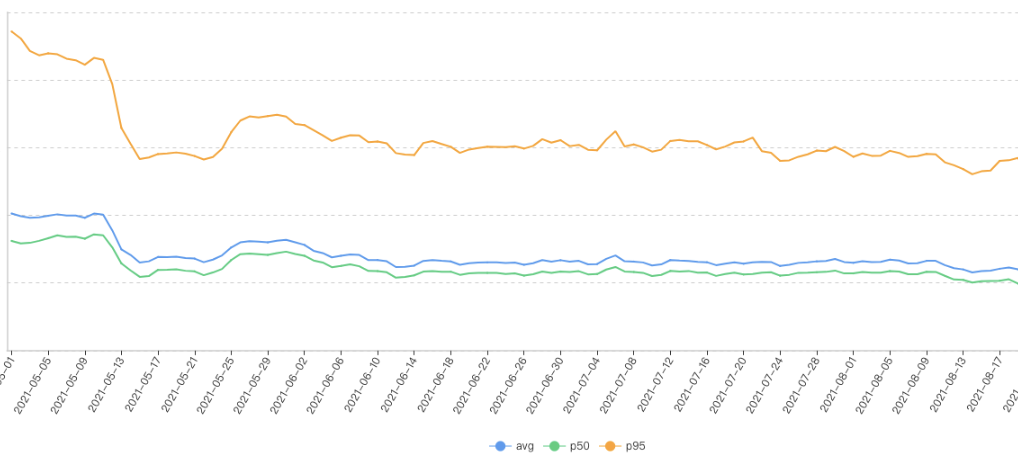
指标2: 自采FMP
按之前的解释,需要思考“数据内容之间的相互作用”。而单“自采TTI”只是一个综合性的数据内容,我们还需要一些数据能进一步定位哪些因素在对这个综合数据起主要作用。下图展示了整个页面加载的过程:前面三张图是纯客户端在运行,页面上没有展示内容;中间5张图看到头部加载了部分内容,列表还在加载中;最后2张图可以看到所有内容都已经展示出来。

简单来说,就是从浏览器(或者webview)发起请求到服务器下载页面数据和相关脚本,然后客户端渲染(render)出用户看得到且可交互的页面节点(DOM)。整个时间消耗也就分成服务端和客户端两部分(理论上还要考虑网络部分,但这块比较复杂,后续可以单独起一篇讨论)。
我们把前3张图的部分单独拉出来做一个指标,客户端在执行到第4张图的时候,上报一个埋点,只需要把data字段里的name值修改下即可:
{
"key": "o_corp_htl_performance",
"ts": 1630653123093,
"userId": "012345",
"pageId": "1234567890",
"sessionId": 2940023,
"data": "{\"name\":\"filterLoaded\",\"latency\":1729,\"startTime\":1630653123093 }\""
}指标3: 自采BFF延迟
接下来,中间5张图主要是在服务端处理,服务层面的耗时指标也需要考虑进来。这里客户端可以使用两种模式来请求API数据:一种是常规的CSR(Client Side Rendering),使用AJAX异步请求Restful API后在客户端渲染出DOM;另一种是SSR(Server Side Rendering),使用NodeJS调用内网SOA服务并直接生成好DOM下发到客户端。不论哪种模式,我们先只计API服务从接收到请求到输出报文,这个耗时为整个服务耗时,同样看95L。我们计这个指标为“自采BFF延迟”。实际上BFF(Backend for frontend)是对上游依赖服务的聚合,对BFF内部的耗时分布还可以进一步拆分,比如我们主要依赖Dx服务,那我们可以用类似方法,计“自采Dx延迟”,同样看95L,Dx<BFF。
服务端的日志相对比较丰富,但我们期望所有的数据内容都能归集到同一个数仓里,方便关联。于是通过ETL (Extract-Transfer-Load) 工具,把服务端存储的结构化埋点日志分发存储到HDFS,可以使用LinkedIn的Camus,很容易做到将kafka消息转存到HDFS上。
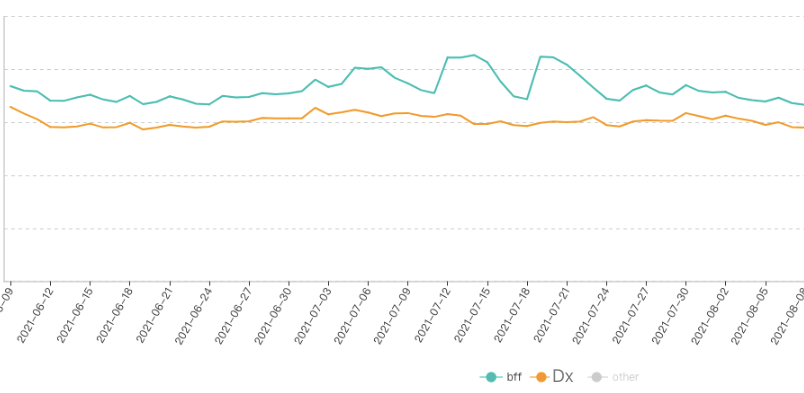
指标4: Google Lighthouse Score
到目前为止,我们已经有了自己定义的指标,而且很容易得到它们。但它们对用户体验的表达并不客观,因为我们基于一个假设,用户体验和某个页面执行周期的耗时有关。我们完全有理由可以质疑,假设这些自采指标优化得非常好看,真的就代表用户体验好了么?其实,这个问题的本质是如何定义用户体验?而“快”是我们通过共识和经验得出来的最容易的假设,但还是可能存在“幸存者偏差”的错误认知。
这确实是一个不太好准确回答的问题,因为体验问题本质是一种主观感性认知,没有一种绝对的标量定义。但我们可以想办法通过对比的方法:找到一个大多数用户都觉得体验好的页面,用一套相对全面并且通用的标尺来衡量它,再用同样的标尺来衡量我们自己的页面,从中找到差异,这样我们就能靠近我们想要的答案。很庆幸,我们要的这个通用标尺Google给我们提供了解决方案,那就是Lighthouse(https://developers.google.com/web/tools/lighthouse/)。
我们最常用的Chrome浏览器默认集成了Lighthouse,只需要打开“开发者工具”,就能看到它,并直接让它生成一份可视化结果。
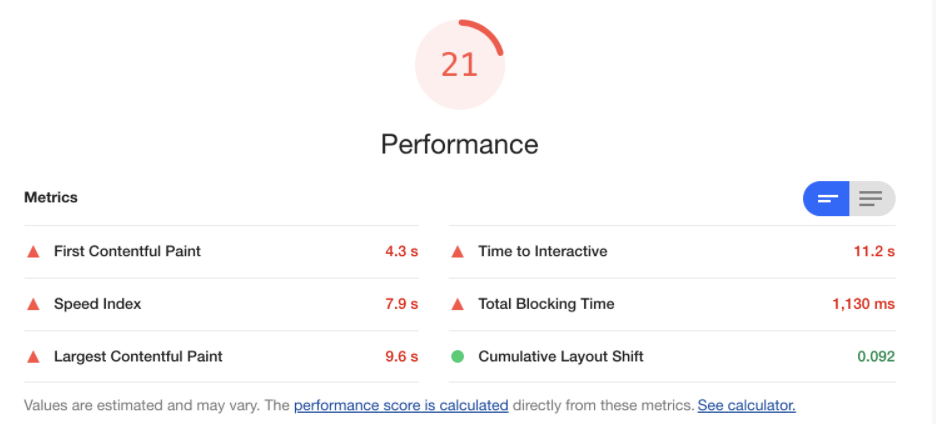
刚才有说到,要使用对比的方法,要找个大家公认的体验好的目标站点且业务性质相似,我们很快找到了携程大住宿业务的H5列表页。通过比对,很容易就能找到差距和入手点。
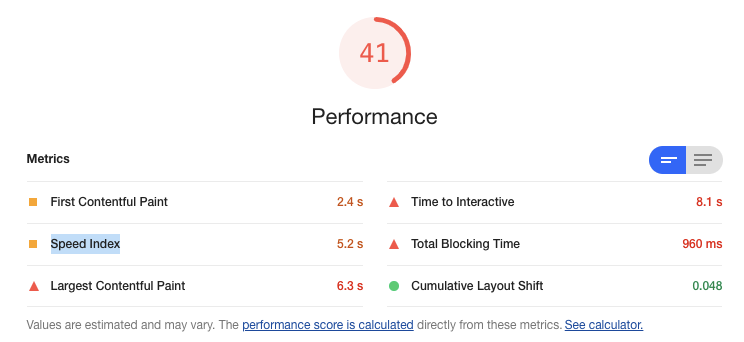
但我们每次都只能通过浏览器手动对两个页面采集评分(audit),那显然是非常低效且不可持续的。要想办法自动化持续采集这些lighthouse的评分数据,而lighthouse提供了Nodejs的npm包,可以通过Nodejs脚本来执行。
在我们尝试使用node脚本来生成lighthouse评分的时候,发现lighthouse只能基于单个页面执行。整个audit过程相当于在浏览器里打开指定URL,这对我们的目标页面并不友好,因为我们有登录态,还有部分数据依赖前置页面产生的cookie和localstorage。也就是说,直接打开目标页面会造成被迫自动跳转至登录页或产生报错,导致audit的结果不是我们想要的。
解决这个问题其实也不难,借用UI自动化测试的思路,引入了puppeteer来模拟前置流程,到达目标页面后,执行lighthouse。为了让整个过程更易维护和运行在我们的调度系统上(支持自定义docker镜像),我们直接打包了一个docker镜像。
先建一个dockerfile,把相关依赖包都写进来(至于如何知道要加哪些依赖,就先假设没有依赖,然后在本地环境加载运行这个镜像,通过报错信息收集缺失的依赖包,直到我们的脚本在本地能够成功运行)。
FROM centos
MAINTAINER by Graviton
RUN curl -sL https://rpm.nodesource.com/setup_12.x | bash -
RUN sudo yum -y install nodejs at-spi2-atk libdrm libxkbcommon libXcomposite libXdamage libXrandr libgbm pango alsa-lib-devel
RUN mkdir -p /home/lighthouse
RUN cd /home/lighthouse
RUN npm install --save puppeteer lighthouse
RUN npm install --save-dev esm
COPY lighthouse-util.js /home/lighthouse上面用到的 lighthouse-util.js 脚本如下:
import puppeteer from "puppeteer";
import lighthouse from "lighthouse";
// 使用puppeteer模拟一个Headless Chrome
export function initBrowser() {
return puppeteer.launch({
args: ["--no-sandbox"]
});
}
// 利用lighthouse包audit我们的目标页面
export function audit(browser, targetUrl, options = { output: "json" }) {
const endpoint = browser.wsEndpoint();
const url = new URL(endpoint);
return lighthouse(targetUrl,
Object.assign({},
{
port: url.port
},
options)
);
}为了能让这个镜像更通用,我们并没有把audit某个页面的逻辑打包进来镜像,而是直接通过构建灵活的bash脚本来运行。
cat > audit.js << _EOF_
import { initBrowser, audit } from "/home/lighthouse/lighthouse-util.js";
import fs from "fs";
import puppeteer from "puppeteer";
function sleep(ms){ return new Promise((r)=>{setTimeout(r, ms);})}
(async () => {
// 模拟手机
const iPhone = puppeteer.devices['iPhone X'];
const usr = '<username>'
const pwd = '<password>'
const browser = await initBrowser();
const page = await browser.newPage();
await page.emulate(iPhone);
// 模拟登录页面
await page.goto("https://mydomain.com/my_login_page");
await page.type('input.accout', usr);
await page.type('input.pwd', pwd);
await page.click('button.login');
await page.waitForNavigation();
// 模拟跳转到首页
await page.goto("https://mydomain.com/homepage");
await page.click('button.next');
await sleep(3000);
// 到达目标页面,获取目标页面的URL(动态获取,因为URL参数不确定)
const targetUrl = page.url();
console.log("ready to audit:", targetUrl);
// 开始生成report
const result = await audit(
browser,
targetUrl,
{
output: "json",
onlyCategories: ["performance"]
}
);
// 把结果存入磁盘
fs.writeFileSync("report.json", result.report, "utf-8");
await browser.close();
})()
.catch(console.error)
.then(() => {
console.log("done!");
process.exit(0);
});
_EOF_
# 本地执行audit.js
node -r esm audit.js
# 生成一个上传到hive的脚本
cat > hsql.sql << _EOF_
drop table tmp_mytracedb.tmp_lighthouse_audit;
create table tmp_mytracedb.tmp_lighthouse_audit(report string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
load data local inpath 'report.json' into table tmp_mytracedb.tmp_lighthouse_audit;
_EOF_
# 通过spark-sql执行
spark-sql -f hsql.sql这样我们就能灵活地模拟任何交互过程,达到目标页,定时且自动化获得我们想要的结果。
经过一番折腾,我们终于可以自动并正确采集lighthouse评分了。最终,我们把对比的结果展示出来,如下图,可以每天采集多次,并计各分值的中位数变化和趋势。
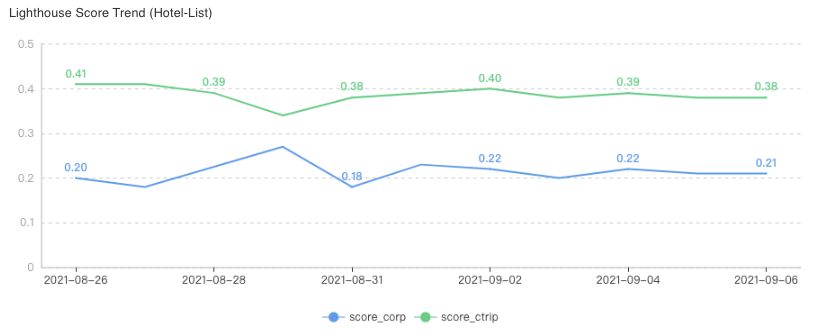
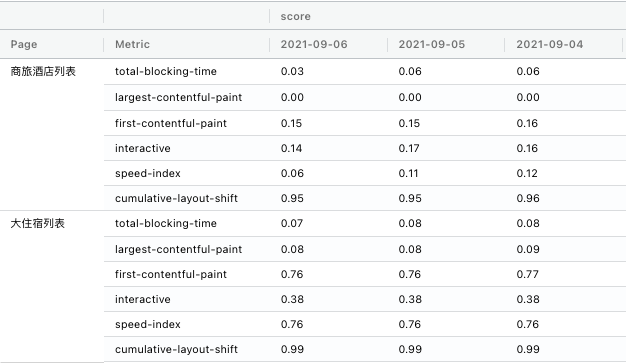
第三步:分析找到突破口
寻找主因
通过上述指标的报表,我们观察到自采TTI的95L在4.8s左右,自采FMP的95L在2.7s左右,自采BFF延迟的95L在1.8s左右。如下图,我们把几个自采指标示意放在一起看,很容易可以发现,客户端的FMP占了TTI近60%。

同时,我们在 lighthouse上找到类似指标FCP (First Contentful Paint: First Contentful Paint marks the time at which the first text or image is painted.) ,发现我们认为体验好的大住宿的列表页,这个FCP的评分是我们列表页的7倍之多。
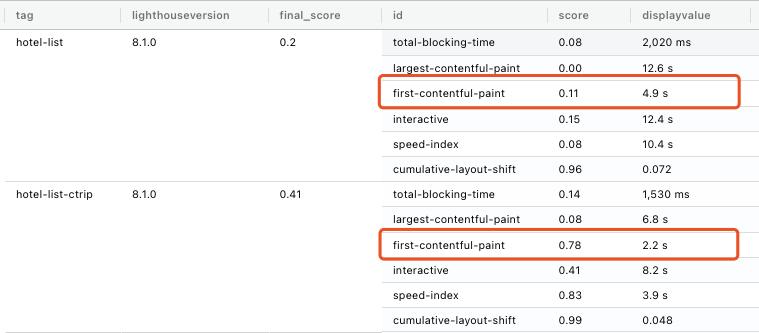
显然,这是我们要找的主因的线索,知道这些数据后,接下来就好办了,无非就是找bad case,从详细的上下文日志中定位出具体慢的原因。由于存储的限制,历史详细日志往往会被自动清除或者archieve到难以查询的地方,所以我们期望bad case越新鲜越好。
我们的解决方案是将用户行为数据实时同步进clickhouse中,借助clickhouse强大的查询效率,可以从海量用户访问的日志数据中,近乎实时地找到足够新鲜的bad case,关键我们还可以用SQL去查询。下面是我们从clickhouse中找bad case的一个查询语句示例:
SELECT toDateTime(ts, 'Asia/Shanghai') ts,
pageId,
userId,
JSONExtract(data, 'latency', 'Int32') AS latency
FROM myckdb.corp_frontend_tracelog
WHERE ts >= toDateTime('2021-09-01 12:00:00')
AND ts < toDateTime('2021-09-01 15:00:00')
AND key = 'o_corp_htl_performance'
AND pageId IN ('1234567890')
AND JSONExtract(data, 'name', 'String') = 'filterLoaded'
AND latency > 3000
ORDER BY latency DESC
LIMIT 100寻找其他机会(次因)
虽然BFF延迟不算主因,但这是个服务层面指标,从中应该可以找到其他的一些简单可行的机会。
我们分析用户的访问轨迹,一般都是酒店查询首页跳转到酒店列表页。从点击查询按钮到用户看到列表,需要经历网络传输+列表资源下载,我们完全可以把服务端的列表处理提前,从而充分利用这块损耗。如下图所示:
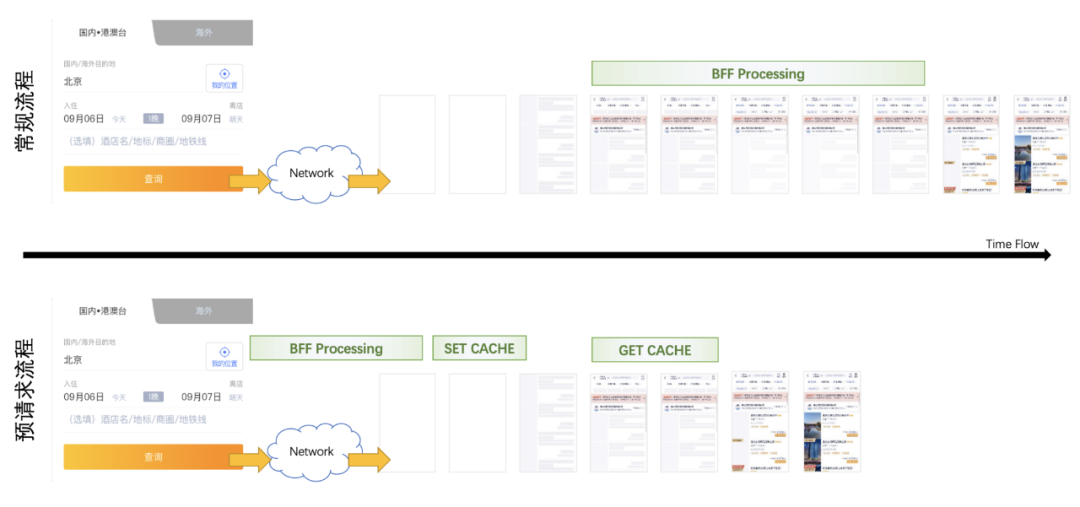
但这个过程引入了缓存,增加了整体复杂度,我们需要解决两个问题:
1)缓存设多少过期时间合适?
2)列表页的起价房型的房态房价和后续详情页看到房型的房价房态不一致的比例能否在可控范围内?
很明显,第1个问题其实影响着第2个问题。设太短的话和常规流程没有区别,设太长的话影响价格一致性(或者变价率)。从有效性角度来考虑,可以统计下历史上两个页面之间访问间隔的分布情况。我们利用HIVE中内置的UDAF函数 histogram_numeric() 可以很轻松地计算出结果:
;WITH dx AS (
SELECT d, ts, userId, sessionId, pageId
, ROW_NUMBER() OVER (PARTITION BY userId, sessionId ORDER BY ts) AS sortRank
FROM mytracedb.edw_corp_frontend_tracelog
WHERE d = date_sub(current_date, 1)
)
SELECT histogram_numeric(duration, 10) AS histo
FROM (
SELECT a.d, b.ts - a.ts AS duration
FROM dx a
JOIN dx b
ON a.d = b.d
AND a.sessionId = b.sessionId
AND b.sortRank - a.sortRank = 1
WHERE pageId IN ('prePageId')
AND pageId IN ('postPageId')
)
GROUP BY dhistogram_numeric (col, n) 的作用是将col列里的数据分到n个桶里(对应柱状图的一根柱子),返回一个struct数组,数组中的每个元素的x代表分桶后每个桶的中心点的横坐标,y代表桶(柱子)的高度,y越大,说明x值附近范围内的占比越多。我们尝试n取20,从输出结果中看到,指定的两个页面间的间隔大多数在17s以内。
于是对于问题1,有了一个可参考的值。
[
{
"x": 11428.630652725085,
"y": 97453.0
},
{
"x": 63523.86956521735,
"y": 92.0
},
{
"x": 165816.81585677728,
"y": 391.0
},
{
"x": 278073.38000000006,
"y": 150.0
},
{
"x": 375393.6851851851,
"y": 54.0
},
{
"x": 448590.52380952373,
"y": 42.0
},
{
"x": 524167.9024390245,
"y": 41.0
},
...
]同理,对于问题2,可以从日志中计算出目前价格一致性(或者变价率)的数据。但需要在发布过程中,能够实时地发现价格一致率的变化情况,以尽量减少未知异常对生产的影响,所以我们需要做到对价格一致性(或者变价率)在发布阶段进行实时监控。
由于一致性的计算需要两个页面间的数据计算,这不管在前端还是后端计算,都需要增加复杂度,增加开发和测试成本。事实上,列表页BFF接口输出的所有信息和详情页BFF接口输出的所有信息都以文本形式存在clickhouse的日志表里(只存几天),于是我们想到,仍旧通过clickhouse来尝试做两个接口日志报文间的关联计算,得到一个近实时的变价率。麻烦的是,详情页的数据结构是一个hotelid对应一个price list数组,而列表页的数据结构是n个hotelid一一对应n个price,我们还需要通过行列转换,找到对应的hotelid和price list里的第一个值(用户看到的第一个价格)。这里就需要用到clickhouse的高级查询语法“Array Join”,示例如下:
SELECT toUInt32(toStartOfInterval(toDateTime(detailTS, 'Asia/Shanghai'), INTERVAL 2 MINUTE)) * 1000 AS t,
countIf(priceDelta != 0) / count() AS `price changed %`
FROM (
SELECT b.t AS listTS,
a.t AS detailTS,
toInt32(a.t) - toInt32(b.t) AS duration,
a.hotelid,
a.price AS detailPrice,
b.price AS listPrice,
toFloat32OrZero(replaceRegexpAll(a.price,'[^0-9\.]',''))
- toFloat32OrZero(replaceRegexpAll(b.price,'[^0-9\.]','')) AS priceDelta
FROM
(
-- 通过正则解析详情页的hotelid和第一个房型的price
SELECT ts AS t, userId,
extract(requestBody, '"hotel":"([0-9]+)"') hotelid,
extract(responseBody, '"rooms":.*?"price":([0-9\.]+)') price
FROM myckdb.corp_bff_tracelog
WHERE ts >= toDateTime('2021-09-01 10:00:00')
AND ts < toDateTime('2021-09-01 12:00:00')
AND ...
AND length(hotelid) > 0
) a
LEFT JOIN
(
SELECT t,
idx,
userId,
tupleElement(h_p,1) AS hotelid,
tupleElement(h_p,2) AS price
FROM
(
SELECT t,
userId,
-- 类似python的zip函数
arrayMap((x,y)-> (x, y), hotels, prices) AS hotel_price_map
FROM
(
-- 通过正则解析列表页的hotel列表和对应的price列表
SELECT ts AS t, userId,
extractAll(responseBody, '"hotelid":([0-9]+)') hotels,
extractAll(responseBody, '"hotelid":[0-9]+,.*?,"price":"([^"]+)"') prices
FROM myckdb.corp_bff_tracelog
WHERE ts >= toDateTime('2021-09-01 10:00:00')
AND ts < toDateTime('2021-09-01 12:00:00')
AND ....
AND length(hotels) = length(prices)
)
)
-- 行转列
Array JOIN hotel_price_map AS h_p, arrayEnumerate(hotel_price_map) AS idx
ORDER BY t, idx
) b ON a.hotelid = b.hotelid
AND a.userId = b.userId
WHERE listTS < detailTS AND toInt32(a.t) - toInt32(b.t) < 120
ORDER BY t, duration, hotelid
)
GROUP BY t
ORDER BY t最后在Grafana上,我们就有了可观察的实时变价率看板。

第四步:实施与监控
有了前三步,很容易可以找到针对主因和次因的可尝试的方案。由于本文侧重点在“数据思维”,所以这里只是简述优化方案细节。
针对FMP,我们尝试了SSR、JS拆包、调用链优化等等。如下图FMP的趋势,在灰度测试结束后可以看到有明显的降低。
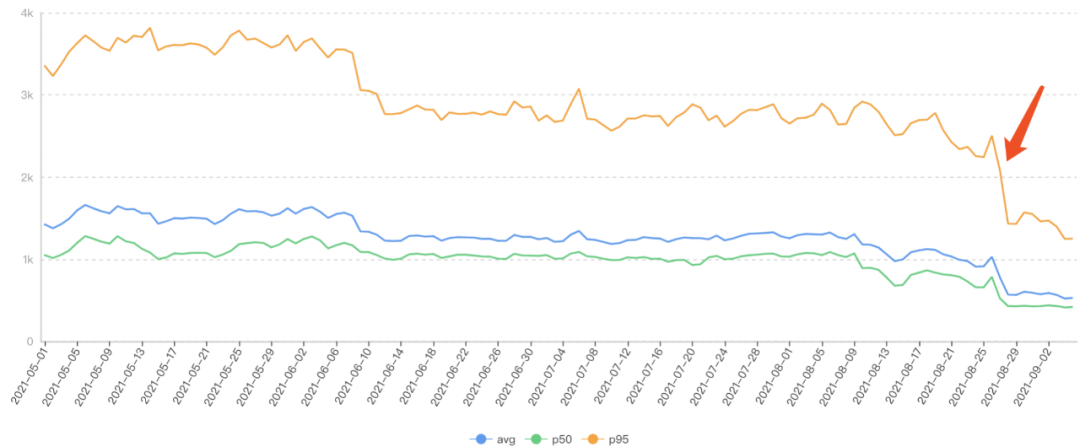
针对BFF的预加载方案,在灰度测试过程中,下面的自采TTI指标住逐步下降。
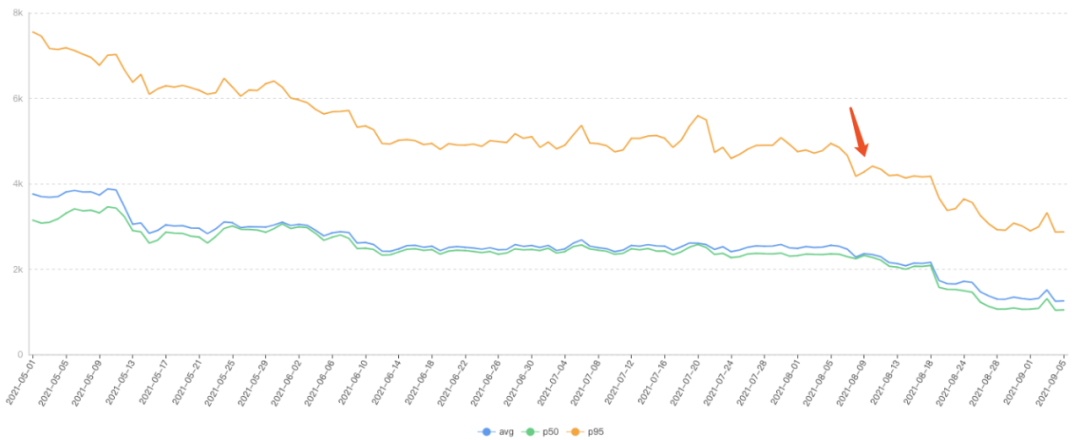
同时,通过实时的新老版本的指标比对,可以观察到明显的结果:
从BFF接口视角,高峰时间段,命中预请求方案(B版)有大约500ms左右的优势,平均缓存命中率达92%。

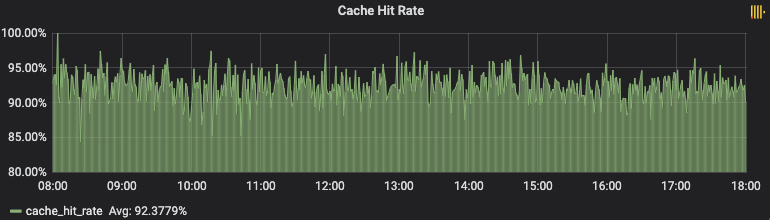
从客户端视角,同样的高峰时间段,命中预请求方案(B版)有大约850ms左右的优势,其中包括了客户端其他优化点。而之前提到的变价率稍有变大,但并没有太大的变化,符合预期。
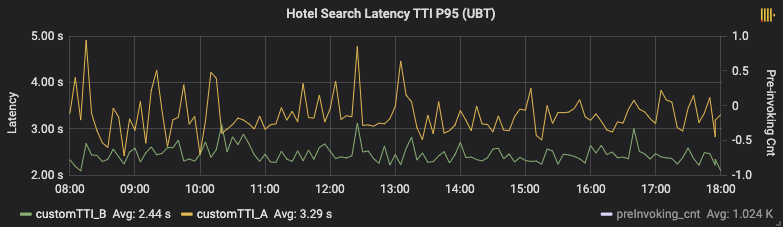
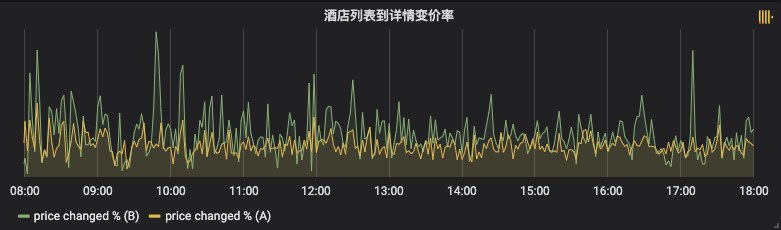
至此,通过实时与非实时数据指标,论证了我们的实施措施是有效的。最后再补一个对比效果视屏,印证感官上的体验。
第五步:持续迭代
回顾之前定义的目标,其中有个不完美的地方就是没有定义出针对某个指标的目标值。我理解这是一次用有限的资源做的一次尝试性的性能优化,也可以认为这一次尝试是在帮助我们指明下个明确的目标。在这次尝试后,我们就可以定义下一个优化目标,而且优化次数越是多,每次优化的目标应该更清晰,或者说应该有几个更具象的目标数字。
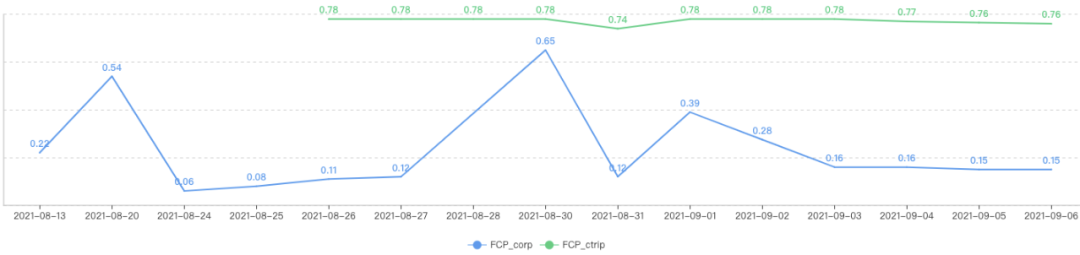
针对本次优化,在几个自采指标上看到明显的正向变化,但和我们对标的大住宿的酒店列表相比,几个lighthouse指标还有明显的差距,于是我们定义下次迭代的优化目标:对齐大住宿的FCP评分达到75分以上。
五、总结
我认为“数据思维”中说的“数据”其实并不难,而大多数反对“数据论”者主要的理由或许是“如何用有限的成本并且快速得到正确的数据”。确实,我们在这次性能优化之前,其实已经花了近3个月时间去梳理、设计、coding近3000个埋点,随着业务迭代,仍旧存在遗漏,需要不断补充。
我们在分析过程中,最痛苦的往往就是突然发现缺失埋点或者数据错误。另外,有些数据源自非自己领域可控的范畴,比如CDN访问日志、上面说的lighthouse评分之类,我们还需要花时间去定制脚本去采集。而在deadline的压力下,一些常规的技改或者业务迭代过程中,可能并没有引入“埋点设计”、“数据采集”、“数据分析”等步骤,或者预留足时间。
但事实上,我认为这些工作往往是一本万利的,一次投入持续受益。借用经济学中的一种说法,它的边际收益很高。所以如果认同数据的价值,那在一个体系内,完全可以自上而下地驱动做一些初期的技术投入和数据建设。
本文花了大量篇幅陈述了一些相关的数据建设的工具使用、方法技巧,主要的技术栈也集中在SQL、Bash、Python等比较通用的脚本语言,目的也是想说明在理清思路后,技术的实现手段并没有那么复杂。
然而,真正难的是“思维”,我理解其“难”主要表现在:
理解数据背后的意义
不同数据之间的关系
从数据中发现潜在问题或者机会
这就只能通过工作中的项目,不断地利用这个流程,实践我们的“数据思维”方法论,从而形成一种工作习惯,从而可以真正可靠、高效地达成我们的业务目标。
团队招聘信息
我们是携程集团商旅事业部,是中国领先差旅管理公司(Travel Management Company),我们为企业客户提供一站式差旅产品出行及咨询服务并协助企业管理差旅费用。
携程商旅的技术团队深入B端技术架构生态,勇于尝试创新,乐于数据思维推进技术和业务并行发展。我们提倡工程师文化,热情开放,非常适合有想法的你来这个平台大展身手,期待与你共事。
目前有前端/后端Java开发/测试开发等岗位正在火热招聘。简历投递邮箱:junyizhu@trip.com,邮件标题:【姓名】-【携程商旅研发部】- 【投递职位】
【推荐阅读】

“携程技术”公众号
分享,交流,成长

















 4456
4456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









