







机器学习之感知机模型
写在前面
这部分主要是基于李航老师的《统计学习方法》以及参考部分博客完成,写出来让自己更好理解。
感知机模型的初步理解
感知机模型应该是机器学习中最简单的模型,是一种二分类的线性分类模型。感知机学习旨在求出将训练数据进行线性划分的超平面。
自我理解
以苹果为例子,现在我们面前有一堆苹果要卖,我们需要将苹果分成两部分,一部分又大又好看的,卖的贵一点,一部分又小又不好看的分为另一部分,卖的便宜点。对于我们来说,我们需要将两个,尽可能的分开,因为如果不好看的掺杂在好看的苹果中,影响口碑。好看的掺杂在不好看的中间,会影响收入。那么,我们现在根据苹果的颜色和体积,得到一个数据集如下:

上面的数据咱们一眼就看出来,中间有个很明显的分界,有人会问,如果两边的数据集有交叉呢?那就是线性不可分的数据集,不在我们研究的范围内。感知机模型研究的是求得一个能够将训练集正实例点和负实例点 完全正确分开的分离超平面。
好,继续回到分苹果。我们得到数据集之后,可以很明显在中间将数据分为两部分,但是如果这个操作让计算机来,他怎么确认哪一个是我们需要的直线?或者说计算机通过什么标准,来确定划分直线的优劣。比如,我们现在得到如下图的三条分割线:
从直观上,我们能看出A和B将数据集完全的分开了,C分割后还存在误分类点。现在如果新来了一批苹果,将新来的数据放入这个图中,哪个直线能更好的将数据分开?对于感知机模型来说,它是没办法找到一个最优直线的,它的要求是,只要这条直线可以将数据集完全正确的分为两部分,就是一条好的直线。也就是A和B对于感知机模型来说,都是一个好的直线。
对于计算机来说,我们需要将这个评判过程进行量化,也就是,给个标准,告诉计算机,什么时候这个直线足够好了。那么根据感知机模型的定义,将数据集完全正确分类,也就是不存在误分类点,那么,我们很容易想到,我们将一条直线划分数据集后,误分类的点数作为评判标准。误分类点越多,这条直线越差,误分类点为0,就是一条好直线。
感知机模型建立
模型: 既然我们打算量化误分类点,那么首先,我们需要对于该点是否正确分类有一个定义。我们定义如下函数:
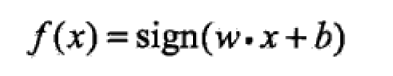
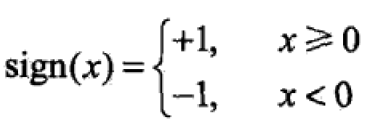
在这个函数中,wx + b = 0 为对应特征空间中的一个超平面,将数据集完全隔离开来。sign(x)是一个符号函数。我们知道,在一个二维平面上,wx + b = 0 表示该平面上的一条直线,那么,数据就分布在直线的两侧。符号函数的作用,就是判断,对应数据点,位于直线的哪侧。
思想: 模型建立完成之后,那么我们需要确定一个思想,也就是我们通过什么方法,去找到最后的结果。根据我们上面的描述,我们需要找到一条直线,将数据完全分离开来。假设我们现在随机初始化一条直线C(如上面的图),我们会发现,这条直线,有误分类的情况。那么我们需要调整直线的斜率和截距,最终将误分类点的数目降到零。这条直线就是我们想得到的直线(如A和B)。那么我们的整体思想就是,将误分类点的数目降到零。也就是错误驱动。
策略: 明确了建立感知机模型的思想,我们需要针对以上的描述,建立感知机学习策略。
(1)数据集的线性可分性
这是感知机模型建立的最基础条件,书中定义如下:

说的简单点,就是在特征空间中,这些数据必须能被一个超平面完整的分隔开。否则这个数据集就是线性不可分的。
(2)感知机的学习策略:
我们前面随机生成了直线C,然后将直线C进行调整,得到最后的直线。但是直线C应该怎么调整呢?根据上述的思想,我们定义损失函数如下:

这是按照我们的思想,建立的损失函数,其中L(w)表示误分类点的个数。接下来,我们对这个函数,进行处理,求得L(w)的最小值。我们常用的方法,就是对这个函数求导,但是我们会发现以下的问题:

那么,我们需要转变思路,不能单纯的用误分类点的个数作为损失函数。在书中,感知机模型选择了另一种思路,也就是误分类点到超平面的总距离。首先,我们写出输入空间任一点x0到超平面的距离为:
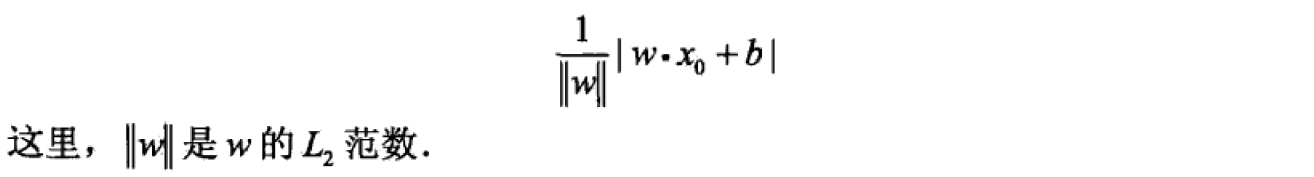
接下来,我们针对误分类点进行分析。

这一步的主要目的,是针对误分类点的特性,将原式中的绝对值符号去除。感知机模型的最终目的是没有误分类点。也就是L(w) = 0。那么为了简化运算,我们对最终结果没有影响的||w||去除,也就得到了感知机的损失函数:

那么,这个损失函数是否可导呢?当直线在进行调整时,每个点对于直线的距离是线性函数,最小值为零。在我们的定义中,误分类点与直线间的距离为正值。所以,损失函数L(w,b)是w和b的连续可导函数。
算法: 针对损失函数,我们采用常用的随机梯度下降法(SGD),来求得最终的极值。
首先任意选取一个超平面,然后利用梯度下降不断地极小化目标函数(2.5)。最理想地状态,我们使所有的误分类点的梯度下降,但是一口吃不成胖子。感知机模型中是定义随机选取一个误分类点使其梯度下降。


对偶形式
通过上述的梳理,针对感知机模型的形式有了一定的了解。但是存在一个问题。每一次的感知模型的循环,我们都需要针对w和xi进行内积运算,针对小批量的数据,现在的计算机的计算能力并没有很吃力。但是如果特征空间维度很高时,则感知机模型的算法会很慢。于是,感知机模型的对偶形式被提出了。
算法:



那么为什么对偶形式可以提高运算速度呢?
首先对于原始形式来说,每一次的参数改变,所有的矩阵计算全部需要重新计算。但是对偶形式的存在,将参数展开成样本之间的点乘形式。这样,随着更新迭代,样本之间的内积不会改变,我们就可以提前将Gram矩阵算出,在程序中,如果用到就直接查找就好,提高了运算速度。














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









