









没有花太多功夫 只是翻译了一下 配合英文论文食用
摘要
关键词:GNN、记忆网络、双线性函数
在许多推荐系统中,用户-物品交互的时间顺序可以反映用户行为的时间演化和顺序。
用户将与之交互的项可能取决于过去访问的项。然而,随着用户和项目的大量增加,序列推荐系统仍然面临着不小的挑战
:(1)短期用户兴趣建模的难度;
:(2)获取长期用户兴趣的难度;
(3)项目共现模式的有效建模。
为了解决这些挑战,我们提出了一个内存增强图神经网络(MA-GNN)来同时捕捉长期和短期用户兴趣。具体地说,我们应用一个图神经网络来建模短期内的项目上下文信息,并利用一个共享的记忆网络来捕捉项目之间的长期相关性。除了对用户兴趣进行建模外,我们还使用了双线性函数来捕获相关项的共现模式。
我们在五个真实世界的数据集上广泛地评估我们的模型,与几种最先进的方法进行比较,并使用各种性能指标。实验结果证明了该模型对Top-K序列推荐任务的有效性。
随着互联网服务和移动设备的快速发展。**个性化推荐系统在现代社会中发挥着越来越重要的作用。减少信息过载,满足多样化的服务需求。这种制度至少给两方带来了重大兴趣。它们可以:(i)帮助用户轻松地从数百万候选产品中发现产品,(ii)为产品供应商创造增加收入的机会。**在互联网上,用户访问在线产品或项目时间顺序排列。用户将来与之交互的项可能强烈地依赖于他/她在过去访问过的项。此属性有助于实际应用场景顺序推荐。在顺序推荐任务中。除了一般用户的兴趣所捕获的所有一般推荐模型。我们认为有三个额外的重要因素
用户短期兴趣、用户长期兴趣和项目共现模式。
1、用户短期兴趣描述在短期内给定几个最近访问的项的用户首选项。
2、用户的长期兴趣捕获了先前访问的项和用户将来将访问的项之间的长期依赖关系。
3、项目共现模式说明了共同出现的相关项目,如手机和屏幕保护器。
虽然许多现有的方法已经提出了有效的模型,但我们认为它们并没有完全抓住上述因素。第一。方法如Caser(唐和Wang(2018),MARank(Yu等,2019)和Fossil(He等)McAuley 2016a)只对短期用户兴趣建模,忽略了项目序列中项目的长期依赖关系。捕获长期依赖的重要性已经被证实(Belletti, Chen,和Chi 2019)第二,像SARSRec (Kang和McAuley 2018)这样的方法并没有明确地为用户短期兴趣建模。忽略用户的短期兴趣,使得推荐系统无法在短期内理解用户的时变意图。第三,方法像GC-SAN(徐和GRU4Rec+ (Hidasi和Karatzoglou 2018)不要显式捕获项序列中的项共生模式。密切相关的项目对经常出现一个接一个,推荐系统应该考虑到这一点。
为了综合上述因素,我们提出一种记忆增强图神经网络(MA-GNN)来处理顺序推荐任务。它包括一般兴趣模块、短期兴趣模块、长期兴趣模块。和一个同现module。
在一般兴趣模块中,我们采用矩阵因子分解:不考虑项目顺序动态而对一般用户兴趣进行建模的术语。
在短期兴趣模块中,我们使用一个GNN来聚合项目的邻居,以形成短期内的用户意图。这些可以在短期内捕获本地上下文信息和结构(Battaglia et al. 2018)。
为了对用户的长期兴趣进行建模,我们使用一个共享的键值存储网络来生成基于用户的长期项目序列的兴趣表示。在做的事情。这样,当推荐商品时,其他有类似偏好的用户也会被考虑在内。
结合短期和长期的兴趣,我们在GNN框架中引入了一个限制机制。这类似于长短时记忆(LSTM) (Hochreiter and Schmidhuber 1997)。这控制了长期或短期兴趣表示对组合表示的贡献。在项同现模块中。e .我们应用双线性函数来捕获项目序列中一个接一个出现的密切相关的项目。我们在五个真实数据集上广泛地评估了我们的模型。将其与使用各种性能验证指标的许多先进方法进行比较。实验结果不仅验证了模型相对于其他基线的改进,而且表明了该方法的有效性。
综上所述
**本文的主要贡献是:**为了建模用户的短期和长期兴趣,我们提出了一种记忆增强图神经网络来捕捉项目的短期上下文信息和长期依赖关系。为了有效地融合短期和长期兴趣,我们在GNN框架中加入了一个控制机制,以自适应地结合这两种hid表示形式。为了明确地对项的共现模式建模,我们使用双线性函数来捕获项之间的特征相关性。对5个真实数据集的实验表明,所提出的MA-GNN模型显著优于最先进的顺序推荐方法
相关工作
一般建议早期的推荐研究:
主要集中于明确的反馈(Koren 2008)。最近的研究重点是****向隐数据转移(Tran等,2019;协同过滤(CF)与隐式反馈通常被视为Top-K项推荐任务。将向用户推荐用户可能感兴趣的项目列表。它更实用,更具挑战性(Pan et al. 2008),更符合真实的推荐场景。
早期的工作大多依赖于矩阵分解技术(Hu, Koren, and Volinsky 2008 Rendle et al. 2009)来了解用户和tems的潜在特征。由于他们的能力,学习突出的代表性。
(dee p)基于神经网络的方法(He et al. 2017)也被采用。
基于自编码的方法也被提出用于Top-K recommendation深度学习利用ing技术对传统的矩阵分解和机器分解方法进行了改进。
序列推荐:
序列推荐任务以时间项序列作为输入。马尔可夫链(Cheng et al.),是数据建模的经典选择。之前对个性化的马尔科夫链进行因式分解,将基于相似性的模型与高阶马尔科夫链相结合。
XXX提出了一种基于翻译的顺序推荐方法。最近,受序列学习在自然语言处理中的优势启发,研究人员提出了基于(深度)神经网络的方法来学习序列动力学。例如Caser (Tang and Wang, 2018)运用卷积神经网络(convolutional neural network, CNN)处理item的嵌入序列。基于递归神经网络(RNN)的方法,特别是基于门控递归单元(GRU)的方法dasi和Karatzoglou已用于为基于会话的推荐任务的顺序模式建模。
Self-attention (Vaswan et al. 2017)在顺序学习中表现出了很好的性能,并开始在顺序推荐中使用。SASRec (Kang和McAuley, 2018年)利用自我关注,自适应地考虑项目之间的相互作用。记忆网络(Chen et al. 2018 Huang et al. 2018)也被用来记忆那些将在预测未来用户行为中发挥作用的项目。
然而,我们提出的模型不同于以往的模型。我们利用带有外部记忆的图神经网络来捕捉短期项目上下文信息和长期项目依赖关系。此外。我们还引入了项共现模块来对密切相关的项之间的关系进行建模。
问题公式化
本文所考虑的推荐任务以序列隐式反馈作为训练数据。用户偏好由一个用户-项序列表示,按照时间顺序,Su= (I1,I2, …, I|su|),其中I*是用户u与之交互的项索引。鉴于之前的M个用户的序列S(t <|S"),问题是从N个项目(K<N)中向每个用户推荐一个包含K个项目的列表,并评估下一个序列中的项目是否出现在推荐列表中。
方法论
在本节中,我们将介绍所提出的模型MA-GNN。该方法将记忆增广图神经网络应用于顺序推荐任务。我们介绍了四个影响用户偏好和意图学习的因素。然后介绍了该模型的预测和训练过程。

通常的兴趣建模
用户的一般兴趣或静态兴趣捕获用户的固有首选项,并假设随着时间的推移是稳定的。为了获得一般用户的兴趣,我们使用矩阵分解项,而不考虑项目的顺序动态。这一项的形式是Pu.qi,式中,p为useru的嵌入,qi E Rd为条目i的输出嵌入,d为潜在空间的维数。
短期兴趣建模
用户的短期兴趣描述用户当前的偏好,并基于短期内最近访问的几个项。用户在不久的将来与之交互的物品很可能与她刚刚访问的物品密切相关,这一用户行为属性在之前的许多著作(Tang and Wang 2018)中得到了证实
因此,在顺序推荐中,有效地为用户的短期兴趣建模是非常重要的,最近访问的条目反映了这一点。
为了明确地对用户短期兴趣进行建模,我们采用滑动窗口策略将项目序列拆分为细粒度子序列。然后,我们可以将注意力集中在最近的子序列上,以预测下一个出现的项,而忽略影响较小的不相关项。
对于每个用户u,我们提取每个连续的|L|项作为输入,它们的下一个|T|项作为要预测的目标,其中 为用户u的第L个子序列。
则问题可表示为:在用户项交互序列Su中,给定一个|L|个连续项的序列,预测的项与该用户的目标|T|项符合的可能性有多大。
由于GNN具有进行邻域信息聚合和局部结构学习的能力,因此它非常适合于对Lu,l,中的项目进行聚合,以学习用户的短期兴趣
项目图施工。
由于项目序列不是用于GNN训练的固有图形,因此我们需要构建一个图形来捕获项目之间的连接。对于项目序列中的每个项目,我们提取几个后续项目(在我们的实验中有三个项目),并在它们之间添加边。我们为每个用户执行此操作,并计算所有用户中提取的项对的边数。然后我们对邻接矩阵行规范化。这样,序列中出现的相关项就可以被提取出来。一个例子:我们将提取的邻接矩阵表示为A,其中A表示第k项相对于第i项的归一化节点权重,第i项的邻接项记为Ni。
短期兴趣聚合
为了获取用户的短期兴趣,我们使用一个双层 GNN来聚合L中的邻近项,以学习用户的短期兴趣表示。形式上,对于第j个短期窗口Lu,l中的第l项,其输入嵌入表示为ej。
用户短期兴趣为: 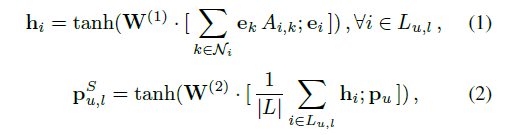
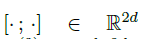 表示垂直级联,w(1)、w(2)表示图神经网络中的可学习参数,上标S表示表示来自用户短期兴趣。通过聚合Lu,l中的项目邻居。Pu.lS,代表一个工会级别的总结(Tang和Wang 2018;表示哪些项目与Lu,l.中的项目密切相关。根据汇总的用户短期兴趣,可以推断出用户接下来要访问的项。
表示垂直级联,w(1)、w(2)表示图神经网络中的可学习参数,上标S表示表示来自用户短期兴趣。通过聚合Lu,l中的项目邻居。Pu.lS,代表一个工会级别的总结(Tang和Wang 2018;表示哪些项目与Lu,l.中的项目密切相关。根据汇总的用户短期兴趣,可以推断出用户接下来要访问的项。
然而,直接应用上述GNN进行预测,显然忽略了过去Hu的长期用户兴趣,l= (I1, I2,…,Il−1)。在短期窗口Lu,l之外可能有一些项目可以表达用户偏好或指示用户状态。这些项可以在预测在不久的将来将要访问的项方面发挥重要的作用。这种长期依赖在之前的许多著作中得到了证实(Liu et al. 2018;Xu等人2019年;Belletti, Chen和Chi 2019)。因此,如何建立长期依赖的模型,并使其与短期环境相平衡,是顺序推荐中的一个关键问题。
Long-term Interest Modeling长期兴趣建模
为了获得长期的用户兴趣,我们可以使用外部内存单元(Sukhbaatar et al. 2015;(Zhang et al. 2017)在H_u,l中存储用户访问的时变用户兴趣,l= (I1, I2,…,I_l−1)。然而,为每个用户维护内存单元会有巨大的内存开销来存储参数。同时,存储器单元可以捕获与嵌入pu的用户所表示的信息非常相似的信息。因此,我们建议使用一个内存网络来存储所有用户共享的潜在兴趣表示,其中每个内存单元代表一种特定类型的潜在用户兴趣,例如针对不同类别的电影的用户兴趣。给定用户在过去Hu,l中访问的项目,我们可以学习不同类型兴趣的组合,以反映用户在Lu,l之前的长期兴趣(或状态)。
与在原始内存网络中执行求和操作来生成查询不同,我们应用多维关注模型来生成查询嵌入。这使得能够更好地反映用户偏好的有区别的信息项能够对相应的外部内存单元的定位产生更大的影响。形式上,我们表示项目嵌入到Hu,las Hu,l∈Rd×|Hu,l|中。生成查询嵌入zu,l的多维注意力,计算为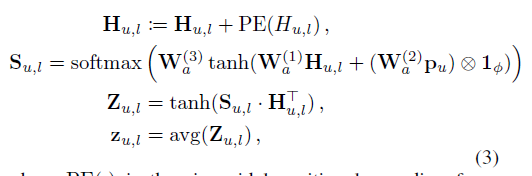
其中PE(•)是将项目位置映射到位置嵌入的正弦位置编码函数,与Transformer中使用的位置编码函数相同。φ= |Hu,l |,⊗表示外积。W(1) a,W(2) a, W(3) a是注意模型中的可学习参数,h是控制注意模型维数的超参数。Su,l∈Rh×|Hu,l|为注意分值矩阵。Zu,l查询的矩阵表示。H的每一行表示查询的不同方面。最后,zu,l对不同方面求平均值的组合查询嵌入。
给定嵌入zu,l的查询,我们使用这个查询来查找内存网络中共享用户潜在兴趣的适当组合。形式上,内存网络的键值(Sukhbaatar et al. 2015;记为K∈Rd×mand V∈Rd×m,其中m为内存网络中的内存单元数。因此,用户的长期兴趣嵌入可以建模为 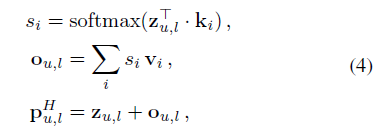
其中ki,vi∈Rdare为第i个内存单元,上标H表示表示来自用户长期兴趣。
兴趣融合
我们得到了用户的短期兴趣表示和长期兴趣表示。下一个目标是将这两种隐藏的表示形式结合到GNN框架中,以促进用户对未评级项的偏好预测。在这里,我们修改Eq. 2,将用户的短期兴趣和长期兴趣联系起来。
具体来说,我们借用了LSTM的想法,它使用了可学习的gate门来平衡当前的输入和历史隐藏节点。类似地,我们提出了一个可学习的门控来控制最近的用户兴趣表示和长期的用户兴趣表示对组合用户兴趣的贡献,用于项目预测: 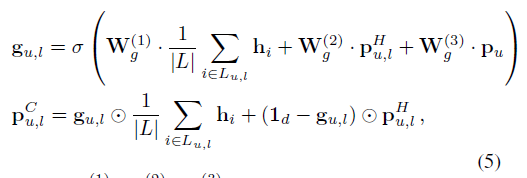
其中,W(1) g,W(2) g,W(3) g∈Rd×dare为gating层中的可学习参数,○.表示元素对应位置的乘法,并且gu,l可学习gate。上标C表示长期兴趣与短期兴趣的融合。
项目同现的建模
成功地学习成对的项目关系是推荐系统的一个关键组成部分,因为它的有效性和可解释性。许多推荐模型在顺序推荐问题中,密切相关的项目可能会在项目序列中依次出现。例如,购买手机后,用户更有可能购买手机外壳或保护套!
为了捕获物品的共现模式,我们使用双线性函数来显式地建模items、Lul、other items之间的物品之间的两两关系。该函数采用这种形式
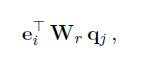 其中Wr是一个可学习参数的矩阵,捕捉到项的潜在特征之间的相关性。
其中Wr是一个可学习参数的矩阵,捕捉到项的潜在特征之间的相关性。
预测和训练
为了推断用户的偏好,我们有一个预测层,将上述因素结合在一起:
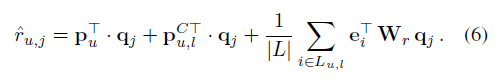
由于训练数据来自于用户的隐式反馈,我们根据贝叶斯个性化排名目标(Rendle et al. 2009)通过梯度下降对所提出的模型进行了优化。这涉及到优化正面(观察到的)和负面(未观察到的)项目之间的两两排序: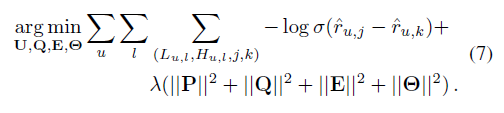
J是Target items中的正例,k是负例中的随机样本,theta是模型中可学习的参数,λ是正则化的参数。P* q* e*分别是矩阵PQE的列向量。在对目标函数求最小值时,利用梯度下降法和反向传播法计算各参数的偏导数。
方法研究
为了证明我们的模型的有效性,我们比较了以下推荐方法:(1)BPRMF,基于贝叶斯个性化排名矩阵分解(Rendle et al. 2009),这是一种学习成对项目排名的经典方法;(2)推荐门控递归单元GRU4Rec (Hidasi et al. 2016),使用递归神经网络对项目序列建模,实现基于会话的推荐;(3) GRU4Rec+,是GRU4Rec (Hidasi和Karatzoglou 2018)的改进版本,采用了先进的损失函数和采样策略;(4) GC-SAN, Graph context - alized Self-Attention Network (Xu et al. 2019),利用Graph neural Network和Self-Attention机制实现基于会话的推荐;(5) Caser,卷积序列嵌入推荐,(Tang and Wang 2018),通过卷积运算捕获高阶马尔科夫链;(6) SASRec,基于自我注意的顺序推荐(Kang and McAuley 2018),使用注意机制识别相关预测项目;(7) MARank,多阶关注排序模型(yu等,2019),该模型将个体和个体层面的条目交互统一起来,从多个视角推断用户偏好;(8) MA-GNN模型,采用记忆增广的GNN结合近期用户兴趣和历史用户兴趣,采用双线性函数显式捕获项目-项目关系。
在实验中,所有模型的潜维度都设置为50。对于基于会话的方法,我们将短期窗口中的项目视为一个会话。对于GRU4Rec和GRU4Rec+,我们发现学习速率为0.001,批处理大小为50可以实现良好的性能。这两种方法分别采用Top1损耗和BPR-max损耗。GC-SAN,我们设置权重因数0.5ω,self-attention k到4块。对于Caser,我们按照作者提供的代码中的设置设置|L| = 5, |T| = 3,水平过滤器的数量为16,垂直过滤器的数量为4。对于SASRec,我们将selfattention块的数量设置为2,批处理大小设置为128,最大序列长度设置为50。对于MARank,我们按照原论文设置子条目数为6,隐藏层数为4。上述方法的网络架构被配置为与原文中描述的相同。超参数在验证集上进行调优。对于MA-GNN,我们按照Caser中的相同设置设置|L| = 5和|T| = 3。超参数在验证集上通过网格搜索进行调整,嵌入大小d也设置为50。h和m的值从{5,10,15,20}中选择。学习速率和λ是设置为0.001和0.001,分别。批处理大小设置为4096。
性能比较
性能比较结果如表2所示。对我们模型的观察。首先,本文提出的模型MA-GNN在所有5个数据集上都取得了最优的性能,说明了本文模型的优越性。其次,MA-GNN的性能优于SASRec。虽然SASRec采用注意模型来区分用户访问过的条目,但它忽略了两个密切相关条目之间的共同条目共现模式,这是我们的双线性函数所捕捉到的。第三,MA-GNN的性能优于Caser、GC-SAN和MARank。一个主要原因是这三种方法只在短期窗口或会话中对用户兴趣进行建模,而不能捕获长期项依赖关系。相反,我们有一个存储网络来产生长期的用户兴趣。第四,MA-GNN获得结果优于GRU4Rec和GRU4Rec+。一个可能的原因是GRU4Rec和GRU4Rec+是基于会话的方法,它们没有明确地为用户的一般兴趣建模。第五,MA-GNN优于BPRMF。BPRMF只捕获用户的一般兴趣,而不包含用户-项交互的顺序模式。因此,BPRMF无法抓住用户的短期利益。其他观察结果。首先,所有关于movielens的结果报告- 20m, goodreadschildren和GoodReadsComics比其他数据集的结果更好。主要原因是其他数据集比较稀疏,数据稀疏性对推荐性能有负面影响。其次,MARank、SASRec和GC-SAN在大多数数据集上的表现都优于Caser。其主要原因是这些方法能够自适应地度量项目序列中不同项目的重要性,这可能导致更加个性化的用户表示学习。第三,在大多数情况下,Caser比GRU4Rec和GRU4Rec+获得更好的性能。一个可能的原因是,Caser显式地将用户嵌入输入到其预测层中,这允许它了解一般的用户兴趣。第四,GRU4Rec+在所有数据集上的性能都优于GRU4Rec。原因是GRU4Rec+不仅捕获用户-项目序列中的顺序模式,而且还具有一个更好的目标函数- bpr -max。第五,所有方法都优于BPR。这说明,只能对一般用户兴趣进行有效建模的技术无法充分捕捉用户的顺序行为。
总结
在本文中,我们提出一个记忆扩充图神经网络(MA-GNN)序贯推荐。MAGNN将一个GNN应用于模型项的短期上下文信息,并利用一个内存网络来捕获长期项依赖关系。在用户兴趣建模的基础上,利用双线性函数对项目之间的特征关联进行建模。在5个真实数据集上的实验结果清楚地验证了我们的模型相对于许多最先进的方法的性能优势,并证明了所提出的模块的有效性。
实验结果图:


















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









