







 本文介绍了使用CNTK实现深度强化学习(DQN)解决Cart Pole游戏的详细过程,包括环境设置、DQN模型构建、ε-greedy探索策略和经验回放技术。通过游戏实例解释了DQN如何从无训练数据开始学习,并逐步优化策略,最终成功解决游戏挑战。
本文介绍了使用CNTK实现深度强化学习(DQN)解决Cart Pole游戏的详细过程,包括环境设置、DQN模型构建、ε-greedy探索策略和经验回放技术。通过游戏实例解释了DQN如何从无训练数据开始学习,并逐步优化策略,最终成功解决游戏挑战。
如需转载,请指明出处。
前言
前面一篇文章,CNTK与深度强化学习笔记之一: 环境搭建和基本概念,非常概要的介绍了CNTK,深度强化学习和DQN的一些基本概念。这些概念希望后面还有文章继续展开深入:),但是只看理论不写代码,很容易让人迷惑。学习应该是一个理论和实践反复的过程。上一章的公式太多,这一章没有公式,只有代码。建议大家这两章来回看,把理论和代码对应起来。我们先来一个简单的例子看一下。这个例子来自CNTK的官方文档:CNTK 203: Reinforcement Learning Basics,做了一些修改。
上一篇文章之后,有几个问题可能是比较让人困惑的,先列举在这里,然后我们通过示例看看是如何解决的:
- 一开始没有任何的训练数据和标记,深度神经网络是如何被训练的呢?是不是能像上文提到的,从一堆垃圾数据里面,学到有意义的东西?
- 经历重放技术确实有效吗?
- ε-greedy exploration算法如何实现,确实有效吗?
gym的Cart Pole环境
Cart Pole在OpenAI的gym模拟器里面,是相对比较简单的一个游戏。游戏里面有一个小车,上有竖着一根杆子。小车需要左右移动来保持杆子竖直。如果杆子倾斜的角度大于15°,那么游戏结束。小车也不能移动出一个范围(中间到两边各2.4个单位长度)。如下图所示:
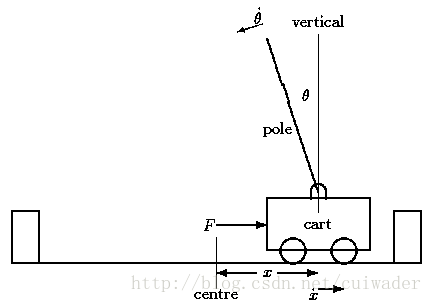
在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env都会返回一个+1的reward。到达200个reward之后,游戏也会结束。
该环境的详细描述在这里。在这个链接里面大家可以看到别人的模型和玩的成绩。另外每个state和action值的含义也在这里:CartPole-v0 wiki。
下面几个词后面的代码会用到(通过变量名体现):
- observation: 代表了对环境的观察,即环境的State
- Spaces: 包括action space,表示有哪些action,和observation space,表示有哪些state。
CNTK的DQN模型实现
针对这个游戏和DQN,我们来看看如何实现模型。下面分段讲解代码。
准备工作
import numpy as np
import math
import os
import random
import gym
import cntk as C
env = gym.make('CartPole-v0')
n_state = env.observation_space.shape[0]
n_action = env.action_space.n
print('CartPole-v0 environment: %d states, %d actions' % (n_state, n_action))这段代码建立了CartPole-v0的环境。n_state保存了observation数组的大小,即环境用多大的数组来表示状态。n_action保存了系统中action的数目。对于Cart Pole来说,这两个值分别是4和2。
reward_target = 195
epoch_baseline = 100 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









