





那是什么 (What is that)
Scraper tracks several GitHub repos in a single Google Sheet (GS) table. You can see all of the opened and done issues, related PRs, priorities, your teammates comments, use coloring, filtering, sorting and other GS functions. That's a good integration, here is how it looks:
Scraper在一个Google Sheet(GS)表中跟踪多个GitHub仓库。 您可以查看所有尚未解决的问题,相关的PR,优先级,您的队友注释,使用着色,过滤,排序和其他GS功能。 这是一个很好的集成,看起来是这样的:
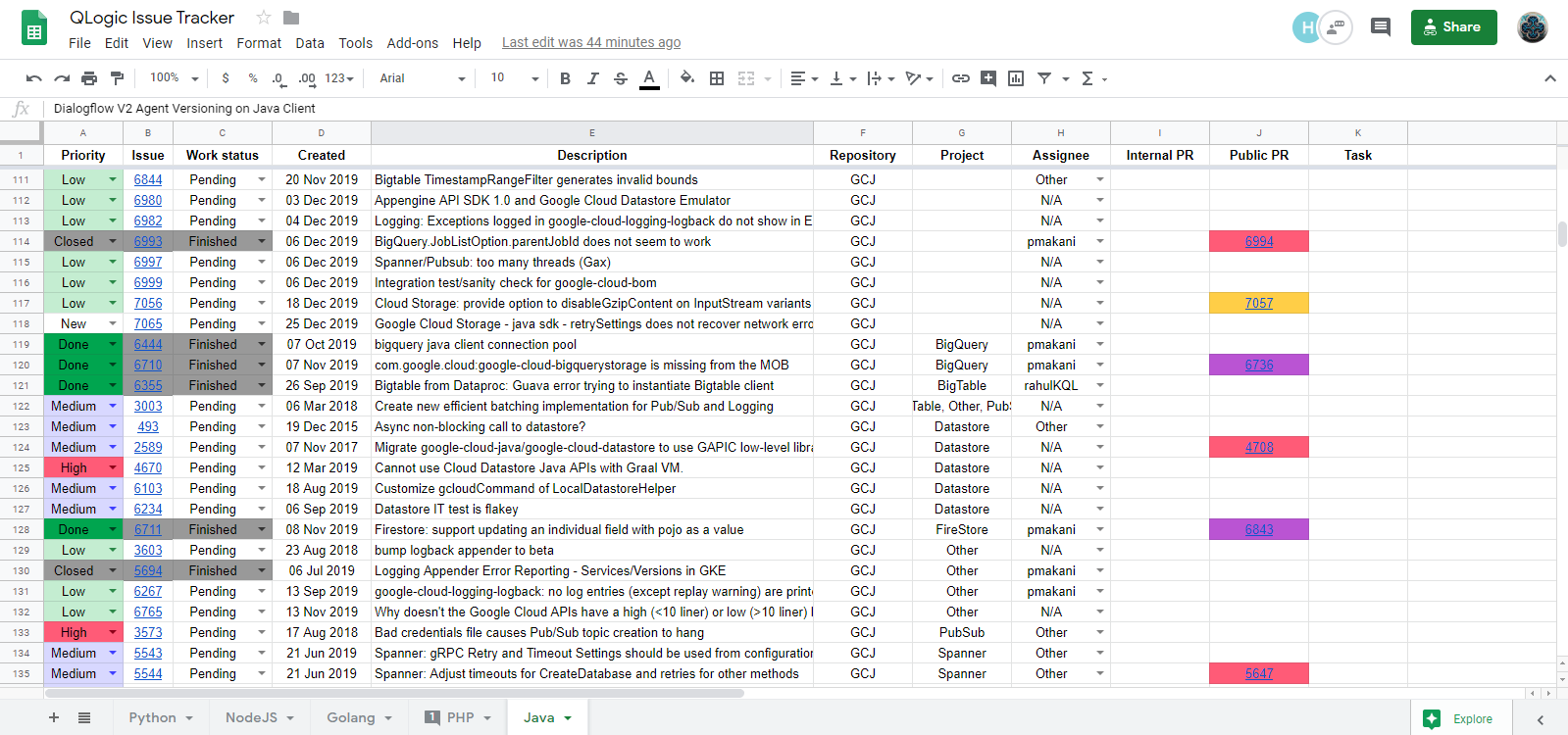
近期如何运作 (How does it work, shortly)
There is Spreadsheet() class which contain several Sheet() objects, each of which have it's own configurations, described in config.py. When Scraper updates a sheet, it loads configurations, sees list of repos to track, requests info from GitHub, builds a table and sends it to GS service. Sounds easy, but there were several tough to deal with things, which I've solved mostly with support of my work experience in Google projects, and which I consider as good patterns. Take a pen.
有一个Spreadsheet()类,其中包含几个Sheet()对象,每个对象都有自己的配置,如config.py中所述 。 当Scraper更新工作表时,它会加载配置,查看要跟踪的回购清单,从GitHub请求信息,构建表并将其发送到GS服务。 听起来很容易,但是要处理一些困难,我主要依靠在Google项目中的工作经验来解决这些问题,我认为这是很好的模式。 拿一支笔。
配置模块 (Config modules)
The first problem was large Scraper configurations. You need to describe parameters for every column in your table: alignment, possible values, width, colors, etc. It's not hard to write them, they are intuitive, but when you see them first time… well…
第一个问题是大型刮板配置。 您需要为表中的每一列描述参数:对齐方式,可能的值,宽度,颜色等。编写它们并不难,它们很直观,但是当您第一次看到它们时……很好……
Problem was solved by keeping configurations completely in Python modules. It's much more easier to load py-file than txt (as you'll don't have to parse raw text) or pickle (user will be able to redact configurations in any moment, and you don't need to invent interfaces for such causes). And, of course, py-files can be easily reloaded (to pull new configurations in case they changed) with just a couple of lines:
通过将配置完全保留在Python模块中解决了问题。 加载py文件比txt(因为您不必解析原始文本)或pickle(用户随时可以修改配置,并且无需为此发明接口)要容易得多。原因)。 而且,当然,只需几行代码就可以轻松地重新加载py文件(以防更改新配置以提取新配置):
import importlib
config = importlib.reload(config)例子 (Examples)
The second problem is related to big configurations as well. When you have hundreds of lines in configurations, you probably should write docs to teach users to use it. But there is another way: add a completely workable examples with small comments. It's easier for user to understand the program this way, you'll don't have to write large docs, and potentially users will don't have to write their configurations from zero point — they'll be using those you wrote with small changes. They in fact will be able to run the app without writing configurations at all — just to check if it works.
第二个问题也与大型配置有关。 当配置中有数百行时,您可能应该编写文档来教会用户使用它。 但是还有另一种方法:添加带有小注释的完全可行的示例。 用户以这种方式更容易理解该程序,您不必编写大型文档,并且潜在的用户将不必从零点开始编写其配置-他们将使用您编写的内容进行较小的更改。 实际上,他们无需编写配置就能运行该应用程序-只是检查它是否有效。
So, examples were written in the separate directory, and original files (for which examples were written) were added into .gitignore. Why? To let users, who're tracking Scraper repo, feel comfortable with their configurations — as files are not be Git-tracked, users can do whatever they want in them, and pull (or push) changes without conflicts.
因此,示例被写在单独的目录中 ,原始文件(为其编写示例)被添加到.gitignore中 。 为什么? 为了使正在跟踪Scraper存储库的用户对它们的配置感到满意-由于文件没有进行Git跟踪,因此用户可以在文件中进行所需的任何操作,并在没有冲突的情况下提取(或推送)更改。
批处理 (Batching)
Scraper can generate a lot of requests for GS service. Processing 200 requests can be slow, it requires to increment socket timeout. To partially deal with this problem such a class was written:
Scraper可以为GS服务生成大量请求。 处理200个请求可能很慢,它需要增加套接字超时。 为了部分解决这个问题,编写了这样的类:
class BatchIterator:
"""Helper for iterating requests in batches.
Args:
requests (list): List of requests to iterate.
size (int): Size of a single one batch.
"""
def __init__(self, requests, size=20):
self._requests = requests
self._size = size
self._pos = 0
def __iter__(self):
return self
def __next__(self):
"""Return requests batch with given size.
Returns:
list: Requests batch.
"""
batch = self._requests[self._pos : self._pos + self._size] # noqa: E203
self._pos += self._size
if not batch:
raise StopIteration()
return batchYou're instancing Iterator, passing list of requests into it, like:
您正在实例化Iterator,将请求列表传递到其中,例如:
for batch in BatchIterator(requests):And Iterator gives you these requests in batches of the given size. It works in one direction, without cycling, thus, it's very primitive, but it's one of the good Python patterns (which is usually out of the table somewhy). And sending requests piece by piece excluded app freezing as well as timeout errors.
而且Iterator会以给定大小的批量向您提供这些请求。 它沿一个方向工作,没有循环,因此,它是非常原始的,但是它是良好的Python模式之一(通常出于某种原因而无法使用)。 并逐条发送请求可排除应用程序冻结以及超时错误。
手动模拟 (Manual mocks)
Now of unit tests. As Scraper works with two services: GitHub and Google Sheets, and requires two accounts, it's not easy to mock Scraper objects. It requires to write three-five different patches to run method isolated, and that's not an option. The way to solve this problem (the way not all consider, as practise shows) is to use OOP itself. We can inherit real class, override some methods — those, which speak with remote services, and make them return values valid for tests. With this we don't have to write patches again and again. This is what was done in Scraper.
现在进行单元测试。 由于Scraper使用两种服务:GitHub和Google Sheets,并且需要两个帐户,因此模拟Scraper对象并不容易。 它需要编写三到五个不同的补丁来隔离运行方法,这不是一个选择。 解决此问题的方法(实践证明,并非所有人都考虑)是使用OOP本身。 我们可以继承真实的类,重写某些方法(与远程服务交互的方法),并使它们返回对测试有效的值。 这样,我们不必一次又一次地编写补丁。 这是在Scraper 中完成的。
导入黑客以使GitHub Actions正常运行 (Import hack to make GitHub Actions work)
The last thing I'd like to share is not very beautiful. It's a good practise to add GitHub Actions into repo to automate tests and lint checks (and a lot of other stuff) on a PR creation. But Actions in fact can only use code from the repo — nothing more, nothing less.
我想分享的最后一件事不是很漂亮。 将GitHub Actions添加到回购中以自动执行PR创建中的测试和皮棉检查(以及许多其他内容)是一个好习惯。 但是Action实际上只能使用仓库中的代码,仅此而已。
As you remember, original configuration files were added into .gitignore. That means, there are no such a files in Scraper's repo. But Scraper is using them! And when Action starts, we're getting an ImportError. Sounds like while bringing convenience to users we're brought inconvenience to ourselves. Yes, that's tough to deal with, but Python importing system gives us some magic.
您还记得,原始配置文件已添加到.gitignore中 。 这意味着,Scraper的回购中没有这样的文件。 但是Scraper正在使用它们! 当Action开始时,我们得到一个ImportError 。 在给用户带来便利的同时,给我们带来了不便。 是的,这很难解决,但是Python导入系统给了我们一些魔术。
As we already understood, there are no configuration files in the repo, but there are examples for them. And they are completely workable. So, let's do the bad thing, and add examples into Python modules, but with names of the original configurations:
如我们已经了解的,存储库中没有配置文件,但是有一些示例。 而且它们是完全可行的。 因此,让我们做一件坏事,然后将示例添加到Python模块中,但要使用原始配置的名称:
import sys
import examples.config_example
sys.modules["config"] = examples.config_exampleYes! Now when any Scraper's module will try to import config, it'll get examples.config_example under the hood. Python is okay with it, and Actions are now working! Our only concern is that code is not as cute as it should be, but unit tests is ancillary code in fact, so we can use some freedom.
是! 现在,当任何Scraper的模块将尝试导入config时 ,它将在后台获取examples.config_example 。 Python可以使用它,并且Actions现在可以工作了! 我们唯一需要担心的是代码并不像它应该的那样可爱,但是单元测试实际上是辅助代码,因此我们可以使用一些自由度。
That's all I have, hope, was useful. Stay wise!
我所希望的就是所有这些都是有用的。 保持智慧!
—
—
Ilya,
伊利亚
QLogic LLC,
QLogic LLC,
Python/Go developer
Python / Go开发人员
GitHub acc | GitHub acc | Personal page 个人页面














 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









