





java瀑布流线性布局代码

When talking about "bad code" people almost certainly mean "complex code" among other popular problems. The thing about complexity is that it comes out of nowhere. One day you start your fairly simple project, the other day you find it in ruins. And no one knows how and when did it happen.
在谈论“错误代码”时,人们几乎可以肯定会在其他流行问题中指“复杂代码”。 关于复杂性的事情是无处不在。 有一天,您开始了相当简单的项目,另一天,您发现了它的废墟。 而且没人知道它是如何发生的以及何时发生的。
But, this ultimately happens for a reason! Code complexity enters your codebase in two possible ways: with big chunks and incremental additions. And people are bad at reviewing and finding both of them.
但是,这最终是有原因的! 代码复杂度通过两种可能的方式进入您的代码库:大块和增量添加。 而且人们不善于审查和发现它们两者。
When a big chunk of code comes in, the reviewer will be challenged to find the exact location where the code is complex and what to do about it. Then, the review will have to prove the point: why this code is complex in the first place. And other developers might disagree. We all know these kinds of code reviews!
当有大量代码进入时,审阅者将被要求查找代码复杂的确切位置以及处理方法。 然后,审查将必须证明这一点:为什么此代码首先很复杂。 其他开发人员可能会不同意。 我们都知道这类代码审查!
The second way of complexity getting into your code is incremental addition: when you submit one or two lines to the existing function. And it is extremely hard to notice that your function was alright one commit ago, but now it is too complex. It takes a good portion of concentration, reviewing skill, and good code navigation practice to actually spot it. Most people (like me!) lack these skills and allow complexity to enter the codebase regularly.
进入代码的第二种复杂性方法是增量加法:向现有函数提交一两行时。 很难注意到您的函数在一个提交之前就可以了,但是现在它太复杂了。 要真正发现它,需要花费很大的精力,复习技巧和良好的代码导航实践。 大多数人(像我一样!)缺乏这些技能,并且允许定期输入代码库的复杂性。
So, what can be done to prevent your code from getting complex? We need to use automation! Let's make a deep dive into the code complexity and ways to find and finally solve it.
因此,如何防止代码变得复杂? 我们需要使用自动化! 让我们深入研究代码的复杂性以及找到并最终解决它的方法。
In this article, I will guide you through places where complexity lives and how to fight it there. Then we will discuss how well written simple code and automation enable an opportunity of "Continous Refactoring" and "Architecture on Demand" development styles.
在本文中,我将指导您遍历复杂性生活的地方以及如何与之抗衡。 然后,我们将讨论编写良好的简单代码和自动化如何为“连续重构”和“按需架构”开发风格提供机会。
复杂性解释 (Complexity explained)
One may ask: what exactly "code complexity" is? And while it sounds familiar, there are hidden obstacles in understanding the exact complexity location. Let's start with the most primitive parts and then move to higher-level entities.
有人可能会问:“代码复杂性”到底是什么? 虽然听起来很熟悉,但在理解复杂度的确切位置方面存在隐藏的障碍。 让我们从最原始的部分开始,然后转到更高层次的实体。
Remember, that this article is named "Complexity Waterfall"? I will show you how complexity from the simplest primitives overflows into the highest abstractions.
还记得本文被命名为“复杂性瀑布”吗? 我将向您展示从最简单的原语到最高抽象的复杂性。
I will use python as the main language for my examples and wemake-python-styleguide as the main linting tool to find the violations in my code and illustrate my point.
我将使用python作为示例的主要语言,并使用wemake-python-styleguide作为主要的工具,以发现代码中的违规并阐明我的观点。
表达方式 (Expressions)
All your code consists of simple expressions like a + 1 and print(x). While expressions themself are simple, they might unnoticeably overflow your code with complexity at some point. Example: imagine that you have a dictionary that represents some User model and you use it like so:
您所有的代码都包含简单的表达式,例如a + 1和print(x) 。 尽管表达式本身很简单,但是它们有时可能会在一定程度上引起代码的复杂性溢出。 示例:假设您有一个代表某些User模型的字典,并且您像这样使用它:
def format_username(user) -> str:
if not user['username']:
return user['email']
elif len(user['username']) > 12:
return user['username'][:12] + '...'
return '@' + user['username']It looks pretty simple, doesn't it? In fact, it contains two expression-based complexity issues. It overuses 'username' string and uses magic number 12 (why do we use this number in the first place, why not 13 or 10?). It is hard to find these kinds of things all by yourself. Here's how the better version would look like:
看起来很简单,不是吗? 实际上,它包含两个基于表达式的复杂性问题。 它overuses 'username'字符串,并使用了魔幻数字 12 (为什么我们首先使用这个数字,为什么不使用13或10 ?)。 很难自己找到所有这些东西。 更好的版本如下所示:
#: That's how many chars fit in the preview box.
LENGTH_LIMIT: Final = 12
def format_username(user) -> str:
username = user['username']
if not username:
return user['email']
elif len(username) > LENGTH_LIMIT: # See? It is now documented
return username[:LENGTH_LIMIT] + '...'
return '@' + usernameThere are different problems with expression as well. We can also have overused expressions: when you use some_object.some_attr attribute everywhere instead of creating a new local variable. We can also have too complex logic conditions or too deep dot access.
表达也有不同的问题。 我们还可以使用一些过度使用的表达式 :在各处使用some_object.some_attr属性而不是创建新的局部变量时。 我们还可能具有过于复杂的逻辑条件或太深的点访问 。
Solution: create new variables, arguments, or constants. Create and use new utility functions or methods if you have to.
解决方案 :创建新的变量,参数或常量。 如果需要,创建并使用新的实用程序功能或方法。
线数 (Lines)
Expressions form code lines (please, do not confuse lines with statements: single statement can take multiple lines and multiple statements might be located on a single line).
表达式形成代码行(请不要将行与语句混淆:单个语句可以使用多行,并且多个语句可能位于一行上)。
The first and the most obvious complexity metric for a line is its length. Yes, you heard it correctly. That's why we (programmers) prefer to stick to 80 chars-per-line rule and not because it was previously used in the teletypewriters. There are a lot of rumors about it lately, saying that it does not make any sence to use 80 chars for your code in 2k19. But, that's obviously not true.
线的第一个也是最明显的复杂性度量是其长度。 是的,您没听错。 这就是为什么我们(程序员)更喜欢遵循每行80字符的规则,而不是因为它以前是在电传打字机中使用的。 最近有很多关于它的谣言,说在2k19中使用80字符作为代码没有任何意义。 但是,那显然不是事实。
The idea is simple. You can have twice as much logic in a line with 160 chars than in line with only 80 chars. That's why this limit should be set and enforced. Remember, this is not a stylistic choice. It is a complexity metric!
这个想法很简单。 在160字符的行中,逻辑的数量是仅80字符的行的逻辑数量的两倍。 这就是为什么应该设置和强制执行此限制。 请记住,这不是样式选择 。 这是一个复杂性指标!
The second main line complexity metric is less known and less used. It is called Jones Complexity. The idea behind it is simple: we count code (or ast) nodes in a single line to get its complexity. Let's have a look at the example. These two lines are fundamentally different in terms of complexity but have the exact same width in chars:
第二种主线复杂性度量标准鲜为人知,使用较少。 这称为琼斯复杂度 。 它背后的想法很简单:我们在一行中计算代码(或ast )节点以获取其复杂性。 让我们看一个例子。 这两行的复杂度从根本上不同,但字符的宽度完全相同:
print(first_long_name_with_meaning, second_very_long_name_with_meaning, third)
print(first * 5 + math.pi * 2, matrix.trans(*matrix), display.show(matrix, 2))Let's count the nodes in the first one: one call, three names. Four nodes totally. The second one has twenty-one ast nodes. Well, the difference is clear. That's why we use Jones Complexity metric to allow the first long line and disallow the second one based on an internal complexity, not on just raw length.
让我们计算第一个节点:一个调用,三个名称。 总共四个节点。 第二个节点有21个ast节点。 好吧,区别很明显。 这就是为什么我们使用琼斯复杂度度量标准来允许第一条长行并基于内部复杂性而不是仅基于原始长度来禁止第二条长行。
What to do with lines with a high Jones Complexity score?
琼斯复杂度得分高的线怎么办?
Solution: Split them into several lines or create new intermediate variables, utility functions, new classes, etc.
解决方案 :将它们分成几行,或创建新的中间变量,实用函数,新类等。
print(
first * 5 + math.pi * 2,
matrix.trans(*matrix),
display.show(matrix, 2),
)Now it is way more readable!
现在,它更具可读性!
结构体 (Structures)
The next step is analyzing language structures like if, for, with, etc that are formed from lines and expressions. I have to say that this point is very language-specific. I'll showcase several rules from this category using python as well.
下一步是分析由线条和表达式组成的语言结构,如if , for , with ,等。 我必须说,这一点是非常特定于语言的。 我还将使用python展示该类别的一些规则。
We'll start with if. What can be easier than a good-old if? Actually, if starts to get tricky really fast. Here's an example of how one can reimplement switch with if:
我们将从if开始。 有什么可以比一个好大的更容易if ? 实际上, if真的开始变得棘手的话。 这是一个如何使用if reimplement switch的示例:
if isinstance(some, int):
...
elif isinstance(some, float):
...
elif isinstance(some, complex):
...
elif isinstance(some, str):
...
elif isinstance(some, bytes):
...
elif isinstance(some, list):
...What's the problem with this code? Well, imagine that we have tens of data types that should be covered including customs ones that we are not aware of yet. Then this complex code is an indicator that we are choosing a wrong pattern here. We need to refactor our code to fix this problem. For example, one can use typeclasses or singledispatch. They the same job, but nicer.
此代码有什么问题? 好吧,想象一下,我们有数十种数据类型应该涵盖,包括我们尚不了解的海关数据类型。 然后,这个复杂的代码表明我们在这里选择了错误的模式。 我们需要重构代码以解决此问题。 例如,可以使用typeclass ES或singledispatch 。 他们做的一样,但是更好。
python never stops to amuse us. For example, you can write with with an arbitrary number of cases, which is too mentally complex and confusing:
python永不停止逗我们。 例如,你可以写with与案件的任意数量 ,这也太弱智复杂和混乱:
with first(), second(), third(), fourth():
...You can also write comprehensions with any number of if and for expressions, which can lead to complex, unreadable code:
您还可以使用任意数量的if和for表达式编写理解,这可能导致复杂的,不可读的代码:
[
(x, y, z)
for x in x_coords
for y in y_coords
for z in z_coords
if x > 0
if y > 0
if z > 0
if x + y <= z
if x + z <= y
if y + z <= x
]Compare it with the simple and readable version:
将其与简单易读的版本进行比较:
[
(x, y, z)
for x, y, x in itertools.product(x_coords, y_coords, z_coords)
if valid_coordinates(x, y, z)
]You can also accidentally include multiple statements inside a try case, which is unsafe because it can raise and handle an exception in an expected place:
您还可以multiple statements inside a try案例中意外地包含multiple statements inside a try ,这是不安全的,因为它可以在预期的位置引发并处理异常:
try:
user = fetch_user() # Can also fail, but don't expect that
log.save_user_operation(user.email) # Can fail, and we know it
except MyCustomException as exc:
...And that's not even 10% of cases that can and will go wrong with your python code. There are many, many more edge cases that should be tracked and analyzed.
而且即使是10%的情况下, python代码也可能会出错。 还有很多更多的边缘情况需要跟踪和分析。
Solution: The only possible solution is to use a good linter for the language of your choice. And refactor complex places that this linter highlights. Otherwise, you will have to reinvent the wheel and set custom policies for the exact same problems.
解决方案 :唯一可能的解决方案是为您选择的语言使用优质棉绒 。 并重构此短绒棉突出的复杂场所。 否则,您将不得不重新发明轮子并为完全相同的问题设置自定义策略。
功能 (Functions)
Expressions, statements, and structures form functions. Complexity from these entities flows into functions. And that's where things start to get intriguing. Because functions have literally dozens of complexity metrics: both good and bad.
表达式,语句和结构构成函数。 这些实体的复杂性转化为功能。 这就是事情开始吸引人的地方。 因为函数实际上具有数十种复杂性指标:好坏。
We will start with the most known ones: cyclomatic complexity and function's length measured in code lines. Cyclomatic complexity indicates how many turns your execution flow can take: it is almost equal to the number of unit tests that are required to fully cover the source code. It is a good metric because it respects the semantic and helps the developer to do the refactoring. On the other hand, a function's length is a bad metric. It does not coop with the previously explained Jones Complexity metric since we already know: multiple lines are easier to read than one big line with everything inside. We will concentrate on good metrics only and ignore bad ones.
我们将从最著名的代码开始: 圈复杂度和以代码行衡量的函数长度。 循环复杂度表明您的执行流程可以执行多少次:它几乎等于完全覆盖源代码所需的单元测试数。 这是一个很好的度量标准,因为它尊重语义并帮助开发人员进行重构。 另一方面,函数的长度是不好的指标。 因为我们已经知道,所以它与先前解释的Jones复杂性度量标准不兼容:多行比内部所有内容的大行更容易阅读。 我们将只关注好的指标,而忽略坏的指标。
Based on my experience multiple useful complexity metrics should be counted instead of regular function's length:
根据我的经验,应该计算多个有用的复杂性指标,而不是常规函数的长度:
- Number of function decorators; lower is better 功能装饰器的数量; 越低越好
- Number of arguments; lower is better 参数数量; 越低越好
- Number of annotations; higher is better 批注数量; 越高越好
- Number of local variables; lower is better 局部变量数; 越低越好
- Number of returns, yields, awaits; lower is better 回报数量,收益,等待; 越低越好
- Number of statements and expressions; lower is better 语句和表达式的数量; 越低越好
The combination of all these checks really allows you to write simple functions (all rules are also applied to methods as well).
所有这些检查的组合实际上允许您编写简单的函数(所有规则也适用于方法)。
When you will try to do some nasty things with your function, you will surely break at least one metric. And this will disappoint our linter and blow your build. As a result, your function will be saved.
当您尝试使用功能进行一些令人讨厌的事情时,您肯定会破坏至少一个指标。 这会让我们的小子失望,炸毁你的身材。 结果,您的功能将被保存。
Solution: when one function is too complex, the only solution you have is to split this function into multiple ones.
解决方案 :当一个功能过于复杂时,您唯一需要解决的就是将该功能拆分为多个功能。
班级 (Classes)
The next level of abstraction after functions are classes. And as you already guessed they are even more complex and fluid than functions. Because classes might contain multiple functions inside (that are called method) and have other unique features like inheritance and mixins, class-level attributes and class-level decorators. So, we have to check all methods as functions and the class body itself.
函数之后的下一个抽象级别是类。 就像您已经猜到的那样,它们比函数还要复杂和灵活。 因为类内部可能包含多个函数(称为方法),并且具有其他独特功能,例如继承和混合,类级属性和类级装饰器。 因此,我们必须将所有方法都检查为函数和类主体本身。
For classes we have to measure the following metrics:
对于班级,我们必须衡量以下指标:
- Number of class-level decorators; lower is better 类级别装饰器的数量; 越低越好
- Number of base classes; lower is better 基类数量; 越低越好
- Number of class-level public attributes; lower is better 类级别的公共属性的数量; 越低越好
- Number of instance-level public attributes; lower is better 实例级公共属性的数量; 越低越好
- Number of methods; lower is better 方法数量; 越低越好
When any of these is overly complicated — we have to ring the alarm and fail the build!
如果其中任何一个过于复杂,我们都必须响起警报,并使构建失败!
Solution: refactor your failed class! Split one existing complex class into several simple ones or create new utility functions and use composition.
解决方案 :重构您失败的课程! 将一个现有的复杂类拆分为几个简单的类,或创建新的实用程序函数并使用组合。
Notable mention: one can also track cohesion and coupling metrics to validate the complexity of your OOP design.
值得注意的是:还可以跟踪内聚和耦合度量,以验证OOP设计的复杂性。
模组 (Modules)
Modules do contain multiple statements, functions, and classes. And as you might have already mentioned we usually advise to split functions and classes into new ones. That's why we have to keep and eye on module complexity: it literally flows into modules from classes and functions.
模块确实包含多个语句,函数和类。 正如您可能已经提到的,我们通常建议将函数和类拆分为新的函数和类。 这就是我们必须注意模块复杂性的原因:它实际上是从类和函数流入模块的。
To analyze the complexity of the module we have to check:
要分析模块的复杂性,我们必须检查:
- The number of imports and imported names; lower is better 进口数量和进口名称; 越低越好
- The number of classes and functions; lower is better 类和功能的数量; 越低越好
- The average complexity of functions and classes inside; lower is better 内部函数和类的平均复杂度; 越低越好
What do we do in the case of a complex module?
如果是复杂的模块,我们该怎么办?
Solution: yes, you got it right. We split one module into several ones.
解决方案 :是的,您做对了。 我们将一个模块分成几个模块。
配套 (Packages)
Packages contain multiple modules. Luckily, that's all they do.
软件包包含多个模块。 幸运的是,这就是他们所做的一切。
So, he number of modules in a package can soon start to be too large, so you will end up with too many of them. And it is the only complexity that can be found with packages.
因此,包中的模块数量很快就会开始变得太大,因此最终您将拥有太多的模块。 这是可以在包中找到的唯一复杂性。
Solution: you have to split packages into sub-packages and packages of different levels.
解决方案 :您必须将程序包分为子程序包和不同级别的程序包。
复杂性瀑布效应 (Complexity Waterfall effect)
We now have covered almost all possible types of abstractions in your codebase. What have we learned from it? The main takeaway, for now, is that most problems can be solved with ejecting complexity to the same or upper abstraction level.
现在,我们已经涵盖了代码库中几乎所有可能的抽象类型。 我们从中学到了什么? 到目前为止,主要的收获是,大多数问题可以通过将复杂性提高到相同或更高的抽象级别来解决。
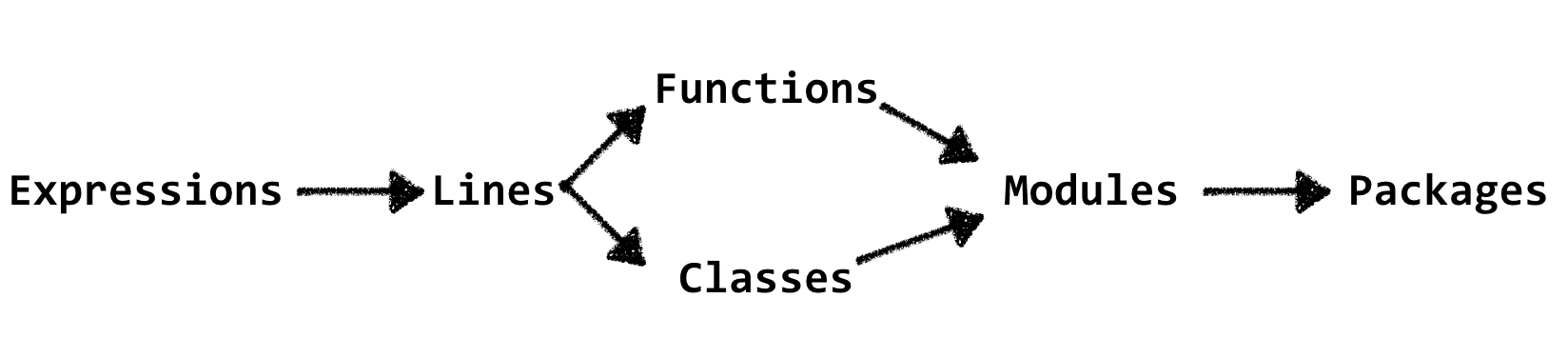
This leads us to the most important idea of this article: do not let your code be overflowed with the complexity. I will give several examples of how it usually happens.
这使我们引出本文最重要的想法:不要让您的代码充满复杂性。 我将举几个例子说明它通常如何发生。
Imagine that you are implementing a new feature. And that's the only change you make:
想象一下您正在实现一项新功能。 这是您所做的唯一更改:
+++ if user.is_active and user.has_sub() and sub.is_due(tz.now() + delta):
--- if user.is_active and user.has_sub():Looks ok, I would pass this code on review. And nothing bad would happen. But, the point I am missing is that complexity overflowed this line! That's what wemake-python-styleguide will report:
看起来还不错,我会在审核时通过此代码。 不会发生任何不良情况。 但是,我缺少的一点是复杂性溢出了这条线! 这就是wemake-python-styleguide将报告的内容:
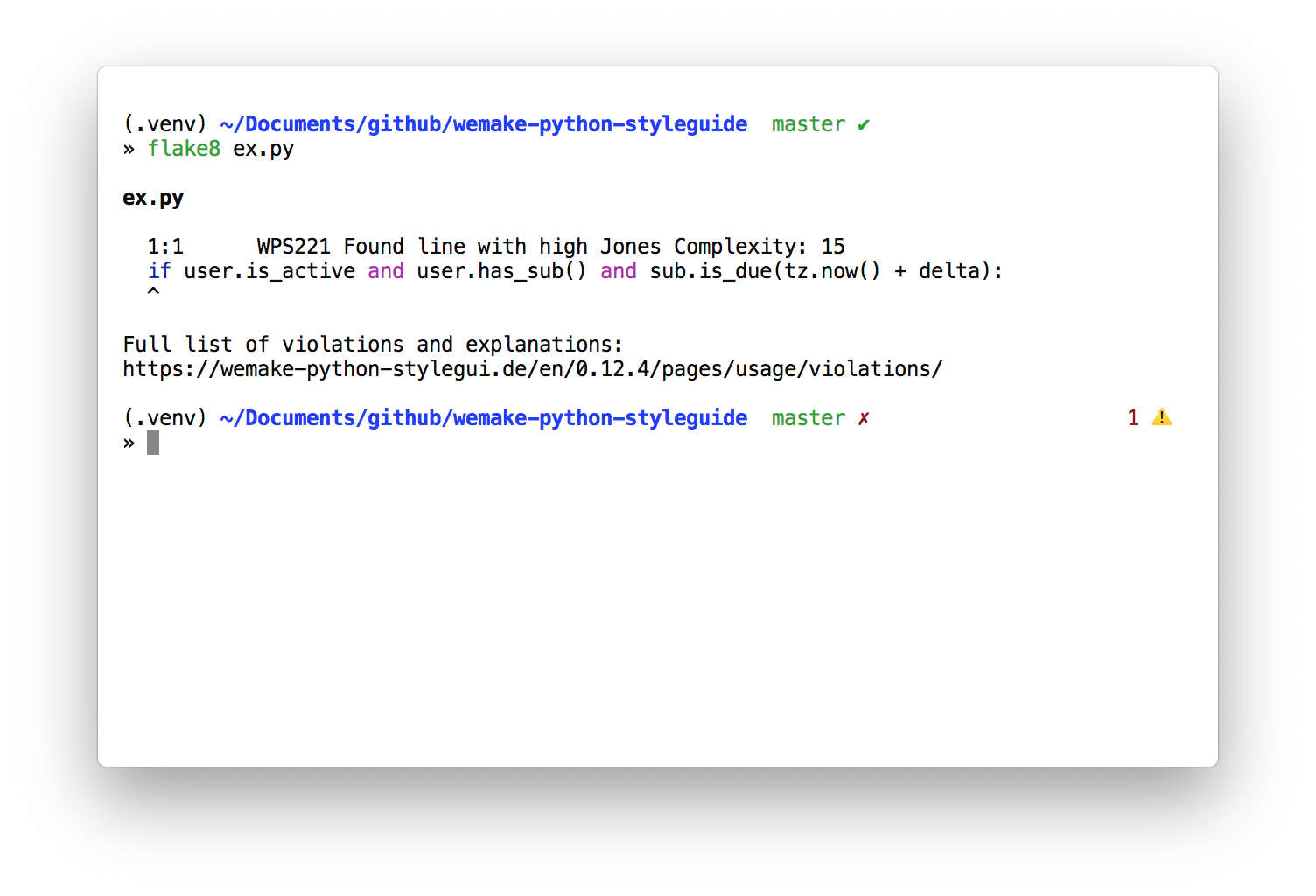
Ok, we now have to solve this complexity. Let's make a new variable:
好的,我们现在必须解决这种复杂性。 让我们创建一个新变量:
class Product(object):
...
def can_be_purchased(self, user_id) -> bool:
...
is_sub_paid = sub.is_due(tz.now() + delta)
if user.is_active and user.has_sub() and is_sub_paid:
...
...
...Now, the line complexity is solved. But, wait a minute. What if our function has too many variables now? Because we have created a new variable without checking their number inside the function first. In this case we will have to split this method into several ones like so:
现在,解决了线路复杂性。 但是,请稍等。 如果我们的函数现在变量太多了怎么办? 因为我们创建了一个新变量,但没有先检查函数内部的编号。 在这种情况下,我们将不得不将此方法拆分为几个方法,如下所示:
class Product(object):
...
def can_be_purchased(self, user_id) -> bool:
...
if self._has_paid_sub(user, sub, delta):
...
...
def _has_paid_sub(self, user, sub, delta) -> bool:
is_sub_paid = sub.is_due(tz.now() + delta)
return user.is_active and user.has_sub() and is_sub_paid
...Now we are done! Right? No, because we now have to check the complexity of the Product class. Imagine, that it now has too many methods since we have created a new _has_paid_sub one.
现在我们完成了! 对? 不,因为我们现在必须检查Product类的复杂性。 想象一下,自从我们创建了一个新的_has_paid_sub以来,它现在拥有太多的方法。
Ok, we run our linter to check the complexity again. And turns out our Product class is indeed too complex right now. Our actions? We split it into several classes!
好的,我们运行我们的linter再次检查复杂性。 事实证明,我们的Product类现在确实太复杂了。 我们的行动? 我们将其分为几类!
class Policy(object):
...
class SubcsriptionPolicy(Policy):
...
def can_be_purchased(self, user_id) -> bool:
...
if self._has_paid_sub(user, sub, delta):
...
...
def _has_paid_sub(self, user, sub, delta) -> bool:
is_sub_paid = sub.is_due(tz.now() + delta)
return user.is_active and user.has_sub() and is_sub_paid
class Product(object):
_purchasing_policy: Policy
...
...Please, tell me that it is the last iteration! Well, I am sorry, but we now have to check the module complexity. And guess what? We now have too many module members. So, we have to split modules into separate ones! Then we check the package complexity. And also possibly split it into several sub-packages.
请告诉我,这是最后一次迭代! 好吧,很抱歉,但是我们现在必须检查模块的复杂性。 你猜怎么着? 现在我们有太多的模块成员。 因此,我们必须将模块拆分为单独的模块! 然后我们检查程序包的复杂性。 并且也可能将其拆分为几个子包。
Have you seen it? Because of the well-defined complexity rules our single-line modification turned out to be a huge refactoring session with several new modules and classes. And we haven't made a single decision ourselves: all our refactoring goals were driven by the internal complexity and the linter that reveals it.
你见过它么? 由于定义良好的复杂性规则,我们的单行修改原来是一个包含几个新模块和类的巨大重构会话。 而且我们自己还没有做出一个决定:我们的所有重构目标都是由内部复杂性和揭示它的棉绒驱动的。
That's what I call a "Continuous Refactoring" process. You are forced to do the refactoring. Always.
这就是我所说的“连续重构”过程。 您被迫进行重构。 总是。
This process also has one interesting consequence. It allows you to have "Architecture on Demand". Let me explain. With "Architecture on Demand" philosophy you always start small. For example with a single logic/domains/user.py file. And you start to put everything User related there. Because at this moment you probably don't know what your architecture will look like. And you don't care. You only have like three functions.
这个过程也有一个有趣的结果。 它使您可以拥有“按需架构”。 让我解释。 有了“按需架构”的哲学,您总是从小做起。 例如,使用单个logic/domains/user.py文件。 然后,您开始将所有与User相关的内容都放在这里。 因为此时您可能不知道您的体系结构是什么样。 而且你不在乎。 您只有三种功能。
Some people fall into architecture vs code complexity trap. They can overly-complicate their architecture from the very start with the full repository/service/domain layers. Or they can overly-complicate the source code with no clear separation. Struggle and live like this for years (if they will be able to live for years with the code like this!).
有些人陷入架构与代码复杂性陷阱之间。 从一开始,他们就可能使整个存储库/服务/域层的架构过于复杂。 或者,它们可能使源代码过于复杂,而没有明确的分隔。 像这样努力奋斗并生活多年(如果他们能够使用这样的代码生活多年!)。
"Architecture on Demand" concept solves these problems. You start small, when the time comes — you split and refactor things:
“按需架构”的概念解决了这些问题。 当时间到来时,您从小处开始-拆分并重构事物:
You start with
logic/domains/user.pyand put everything in there您从
logic/domains/user.py开始,然后将所有内容放入其中Later you create
logic/domains/user/repository.pywhen you have enough database related stuff稍后,当您具有足够的数据库相关内容时,可以创建
logic/domains/user/repository.py/repository.pyThen you split it into
logic/domains/user/repository/queries.pyandlogic/domains/user/repository/commands.pywhen the complexity tells you to do so然后,当复杂性告诉您这样做时,将其拆分为
logic/domains/user/repository/queries.py和logic/domains/user/repository/commands.py。Then you create
logic/domains/user/services.pywithhttprelated stuff然后,您可以使用与
http相关的内容创建logic/domains/user/services.pyThen you create a new module called
logic/domains/order.py然后,您创建一个新的模块,称为
logic/domains/order.py- And so on and so on 等等等等
That's it. It is a perfect tool to balance your architecture and code complexity. And get as much architecture as you truly need at the moment.
而已。 它是平衡您的体系结构和代码复杂性的理想工具。 同时获得您真正需要的尽可能多的体系结构。
结论 (Conclusion)
Good linter does much more than finding missing commas and bad quotes. Good linter allows you to rely on it with architecture decisions and help you with the refactoring process.
好的短毛绒比发现缺少逗号和错误的报价要多得多。 优良的短毛绒使您可以依靠它来进行体系结构决策,并帮助您进行重构过程。
For example, wemake-python-styleguide might help you with the python source code complexity, it allows you to:
例如, wemake-python-styleguide可能会帮助您解决python源代码的复杂性,它使您能够:
- Successfully fight the complexity at all levels 成功应对各个层面的复杂性
- Enforce the enormous amount of naming standards, best practices, and consistency checks 强制执行大量的命名标准,最佳实践和一致性检查
Easily integrate it into a legacy code base with the help of
diffoption orflakehelltool, so old violation will be forgiven, but new ones won't be allowedEnable it into your [CI](), even as a Github Action
甚至作为Github操作将其启用到您的[CI]()中
Do not let the complexity to overflow your code, use a good linter!
不要让复杂性溢出您的代码,请使用优质的lint !
java瀑布流线性布局代码















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









