






 本文介绍了SQL Server中时间序列的使用,强调了时间序列的五大部分:趋势、周期性、季节性、随机性和交叉性。通过AdventureWorksDW2017数据库的vTimeSeries视图展示了如何创建和配置时间序列模型,包括关键参数如.AUTO_DETECT_PERIODICTY、.FORECAST_METHOD和.PERIODICITY_HINT。文章还讨论了模型参数对数据环境的影响,以及如何处理缺失值。
本文介绍了SQL Server中时间序列的使用,强调了时间序列的五大部分:趋势、周期性、季节性、随机性和交叉性。通过AdventureWorksDW2017数据库的vTimeSeries视图展示了如何创建和配置时间序列模型,包括关键参数如.AUTO_DETECT_PERIODICTY、.FORECAST_METHOD和.PERIODICITY_HINT。文章还讨论了模型参数对数据环境的影响,以及如何处理缺失值。
sql server序列
The next topic in our Data Mining series is the popular algorithm, Time Series. Since business users want to forecast values for areas like production, sales, profit, etc., with a time parameter, Time Series has become an important data mining tool. It essentially allows analyzing the past behavior of a variable over time in order to predict its future behavior.
我们的数据挖掘系列中的下一个主题是流行的算法“时间序列”。 由于业务用户希望使用时间参数来预测生产,销售,利润等领域的值,因此时间序列已成为重要的数据挖掘工具。 它实质上允许分析变量的过去行为,以预测其未来行为。
时间序列中的组成部分 (Components in Time Series)
A time series consists of five components:
时间序列包含五个部分:
- Trend: Trend is the movement of the values. Typically, a given series will have an upward or downward trend 趋势:趋势是价值的移动。 通常,给定的序列将具有上升或下降的趋势
- Cyclical: Upward or downward repetitive movement of the values over a longer period of time 周期性 :数值在较长时间段内向上或向下重复移动
- Seasonal: Similar to cyclical, but there can be multiple movements of the values over shorter periods of time, such as hourly, daily, weekly, monthly, etc. 季节性:类似于周期性,但在较短的时间内可以有多个值的移动,例如每小时,每天,每周,每月等。
- Random: There can be movements in the data values which are totally random but will have an impact on the time series trend. A time-series analysis should identify these exceptions, and account for them in predictions 随机:数据值中的移动可能是完全随机的,但会对时间序列趋势产生影响。 时间序列分析应确定这些异常,并在预测中说明它们
- Cross: Other factors may affect the trend of a time series. For example, sales of item A may be dependent on seasonal factors, but may also be affected by the sales of item B. If we take the production of a crop as an example, it will be dependent on rainfall or temperature trends 交叉:其他因素可能会影响时间序列的趋势。 例如,项目A的销售可能取决于季节因素,但也可能受项目B的销售影响。如果我们以农作物的生产为例,则取决于降雨或温度趋势
SQL Server中的Times系列 (Times Series in SQL Server)
To demonstrate time series analysis using SQL Server, we will use the vTimeSeries view in the AdventureWorksDW2017 sample database. Here is the sample data set:
为了演示使用SQL Server进行时间序列分析,我们将使用AdventureWorksDW2017示例数据库中的vTimeSeries视图。 这是样本数据集:
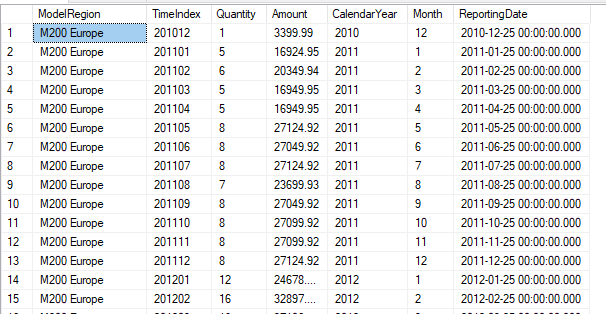
We will use only the first four columns, which are ModelRegion, TimeIndex, Quantity and Amount.
我们将仅使用前四列,即ModelRegion,TimeIndex,Quantity和Amount。
As discussed in the first article, create a sample analysis service project with Visual Studio or SQL Server Data Tools (SSDT). Then, create a Data Source connection to the AdventureWorksDW2017 database and add the vTimeSeries view to the Data Source View.
如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









