





 本文介绍了如何避免在多维分析中过度使用MDX,而是利用T-SQL进行数据过滤。作者通过一个具体的例子展示了如何利用SQL Server 2016的WideWorldImportersDW数据库创建数据源、数据源视图和多维数据集,并最终通过T-SQL和OpenQuery函数在报告中过滤OLAP数据。
本文介绍了如何避免在多维分析中过度使用MDX,而是利用T-SQL进行数据过滤。作者通过一个具体的例子展示了如何利用SQL Server 2016的WideWorldImportersDW数据库创建数据源、数据源视图和多维数据集,并最终通过T-SQL和OpenQuery函数在报告中过滤OLAP数据。
olap 多维分析
介绍 (Introduction)
Last month I ran two Business Intelligence pre-conferences in South Africa. A interesting request arose during the course of the preconference in Cape Town. The individual wanted an approach to extracting data from an OLAP cube that would avoid intensive utilization of MDX and more reliance upon T-SQL. His main concern was with filtering the data at run time, via the report front end.
上个月,我在南非举行了两次商务智能会议。 开普敦会前会议期间提出了一个有趣的要求。 个人希望从OLAP多维数据集中提取数据的方法能够避免大量使用MDX和更多地依赖T-SQL。 他主要关心的是通过报表前端在运行时过滤数据。
In this “fire side chat” we shall do just that, utilizing the cube that comes with the new Microsoft database “WideWorldImporters” and we shall learn how we can get from this
在此“炉边聊天”中,我们将利用新的Microsoft数据库“ WideWorldImporters”随附的多维数据集来做到这一点,我们将学习如何从中获得收益
SELECT NON EMPTY { [Measures].[Quantity - Sale], [Measures].[Unit Price - Sale],
[Measures].[Ext Revenue], [Measures].[WWI Invoice ID] } ON COLUMNS
, NON EMPTY { ([Customer].[Customer].[Customer].ALLMEMBERS * [City].[City].[City].ALLMEMBERS
* [Invoice Date].[Date].[Date].ALLMEMBERS
* [City].[State Province].[State Province].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION,
MEMBER_UNIQUE_NAME ON ROWS FROM [Wide World Importers DW]
CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
to this!
为此!
准备工作 ( Preparitory work )
Should you not have a copy of the WideWorldImportersDW, please do download a copy of the relational database. The relational database may be found at this link
如果您没有WideWorldImportersDW的副本,请下载关系数据库的副本。 关系数据库可以在此链接找到
Simply restore the database to your desired SQL Server 2016 instance.
只需将数据库还原到所需SQL Server 2016实例即可。
We are now ready to begin.
我们现在准备开始。
入门 (Getting started)
Opening Visual Studio 2015 or the latest version of SQL Server Data Tools for SQL Server 2016, we create a new Analysis Services project as shown below.
打开Visual Studio 2015或SQL Server 2016SQL Server数据工具的最新版本,我们创建一个新的Analysis Services项目,如下所示。

Opening Visual Studio of SQL Server Data Tools, we select “New” and “Project” (see above).
打开SQL Server数据工具的Visual Studio,我们选择“新建”和“项目”(请参见上文)。
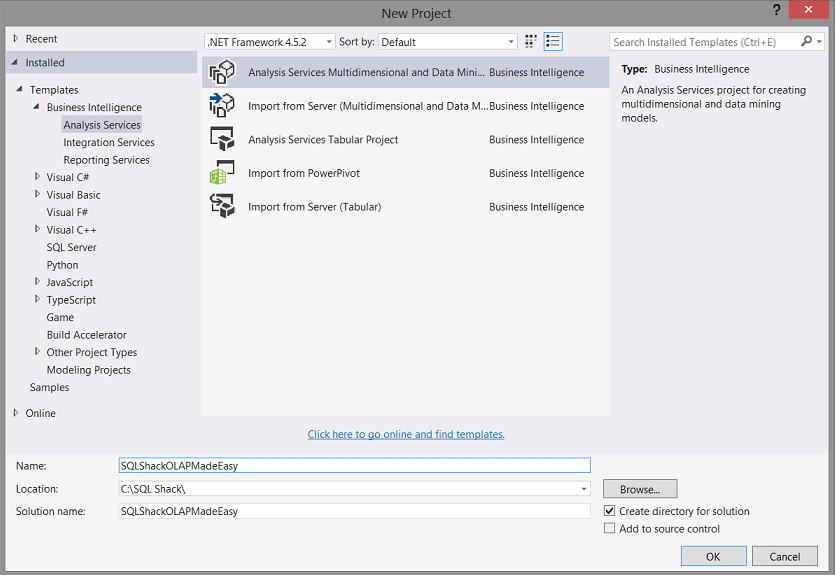
We give our project a name and select the “Analysis Services Multidimensional and Data Mining…” option (as shown above). We click “OK”.
我们为项目命名,然后选择“ Analysis Services多维和数据挖掘…”选项(如上所示)。 我们点击“确定”。

Our design surface is brought into view (see above).
我们的设计图面已经可见(见上文)。
Our first task is to add a data source. We right click upon the “Data Sources” folder shown above.
我们的首要任务是添加数据源。 我们右键单击上面显示的“数据源”文件夹。

We select “New Data Source” (see the screenshot above).
我们选择“新数据源”(请参见上面的屏幕截图)。

The “Data Source Wizard” is brought into view. We click “Next” (see above).
出现“数据源向导”。 我们单击“下一步”(见上文)。

We are presented with a list of existing data connections. The “eagle eyed” reader with note that a connection to the relational database already exists however we shall create a NEW connection for those of us whom are not that familiar with creating NEW connections.
向我们提供了现有数据连接的列表。 “老鹰眼”的读者注意到,已经存在到关系数据库的连接,但是我们将为那些不熟悉创建新连接的人创建一个新连接。
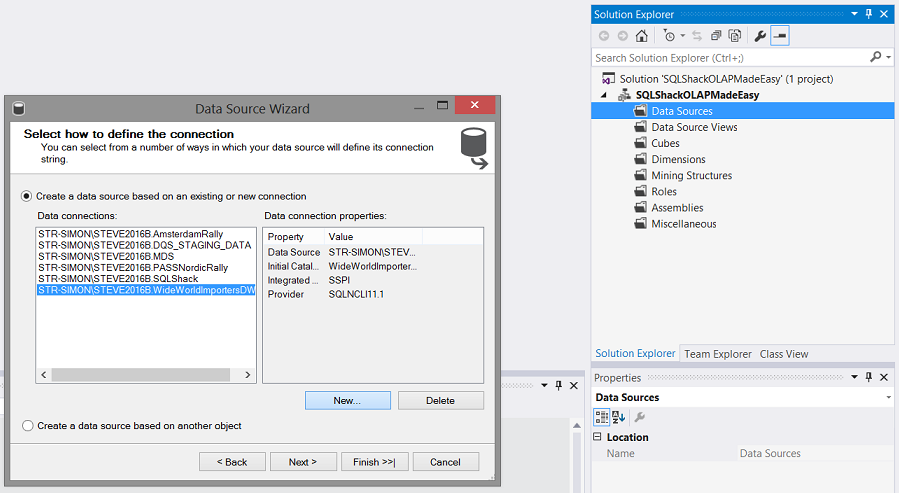
We click the ”New” button as may be seen above.
我们点击上方的“新建”按钮。

The “Connection Manager” wizard appears. We set our server instance name and select the “WideWorldImportersDW” relational database (as may be seen above). We then test the connection and we click “OK” to exit the wizard.
出现“连接管理器”向导。 我们设置服务器实例名称,然后选择“ WideWorldImportersDW”关系数据库(如上所示)。 然后,我们测试连接,然后单击“确定”退出向导。

We find ourselves back upon back within the “Data Source Wizard”. We select our new connection and click “Next” to continue.
我们在“数据源向导”中发现了自己。 我们选择我们的新连接,然后单击“下一步”继续。

The reader will note that we are now request to enter our “Impersonation Information”. In this instance I have opted to utilize a specific user name and password. This data will be used to validate that we have to necessary rights to publish our project to the Analysis Server.
读者将注意到,我们现在要求输入“模拟信息”。 在这种情况下,我选择使用特定的用户名和密码。 此数据将用于验证我们具有将项目发布到Analysis Server的必要权利。
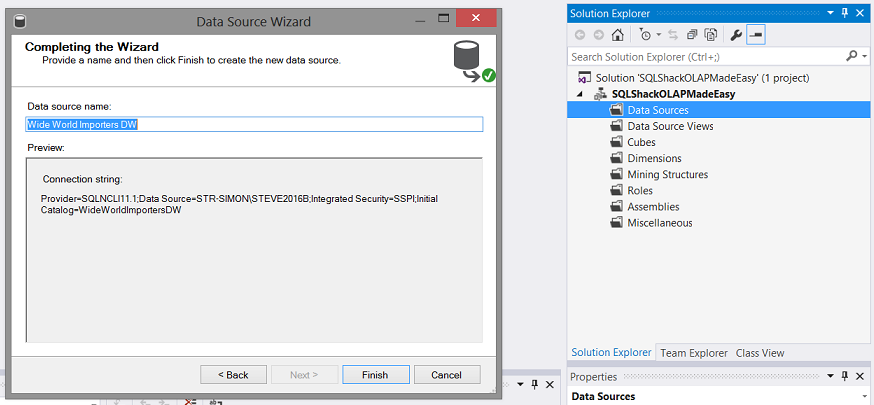
Finally, we give our data source a name and click “Finish” to complete the process (see above).
最后,为数据源命名,然后单击“完成”以完成该过程(请参见上文)。

The data source that we have just created may now be seen under the “Data Sources” folder as shown above.
如上所示,现在可以在“数据源”文件夹下看到我们刚刚创建的数据源。
创建“数据源视图” (Creating the “Data Source View”)
Our next task is to create a “Data Source View”. Whilst we have created a data connection, all that the connection does is to permit our project access to the relational database. Now we must tell our project, which data we want to view and this is achieved through the “Data Source View”.
我们的下一个任务是创建“数据源视图”。 尽管我们创建了数据连接,但该连接所做的只是允许我们的项目访问关系数据库。 现在我们必须告诉我们的项目,我们要查看哪些数据,这是通过“数据源视图”实现的。

We right click upon the “Data Sources Views” folder and select “New Data Source View” (as may be seen above).
我们右键单击“数据源视图”文件夹,然后选择“新数据源视图”(如上图所示)。

The “Data Source View Wizard” is brought into view. We click “Next”.
将显示“数据源查看向导”。 我们点击“下一步”。
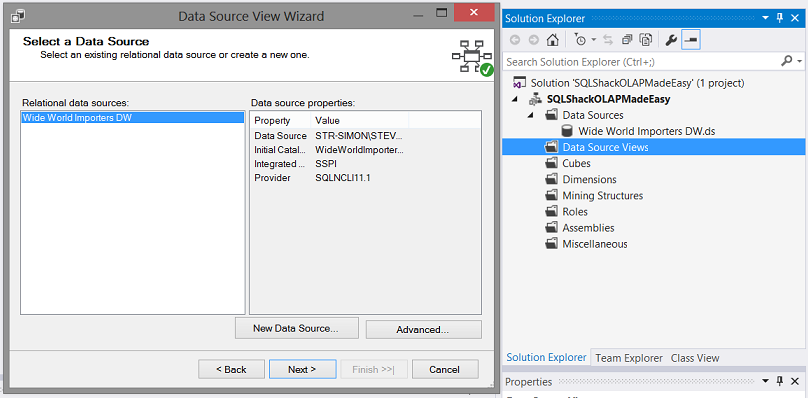
The wizard now shows us our “Wide World Importers DW” data connection that we created above. We select this connection and click “Next”.
向导现在向我们显示了我们在上面创建的“ Wide World Importers DW”数据连接。 我们选择此连接,然后单击“下一步”。
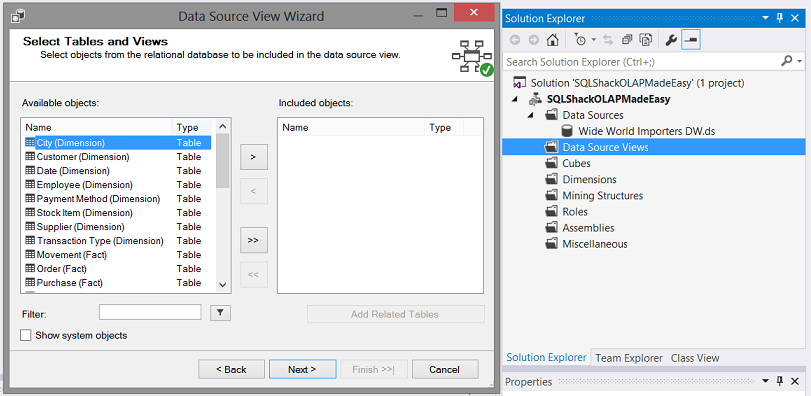
A list of table now appears. We select the tables that we wish to work with, as may be seen below:
现在出现一个表列表。 我们选择希望使用的表,如下所示:
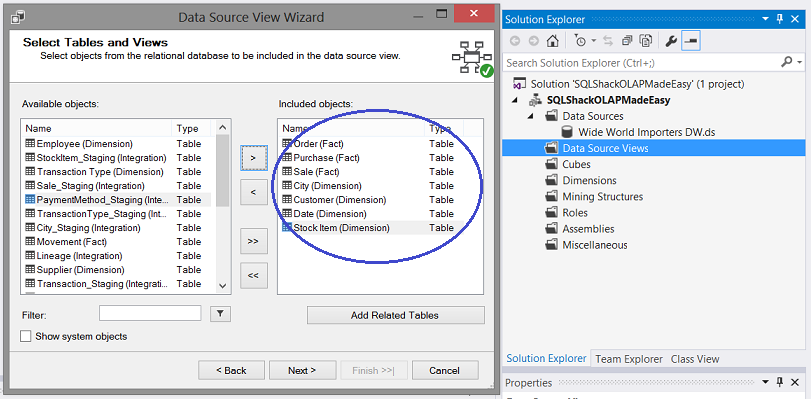
Viewing the “Included objects” dialog box we note the tables that we shall include within our view. All the table “inter-relationships” (e.g. keys and foreign keys) will be respected and this is why we must ensure that all the necessary tables are included in the model that we are creating. Failure to do so, will result in issues within the cube.
在查看“包含的对象”对话框时,我们注意到将包含在视图中的表。 所有表“相互关系”(例如键和外键)都将受到尊重,这就是为什么我们必须确保所有必要的表都包含在我们创建的模型中的原因。 否则,将导致多维数据集内出现问题。
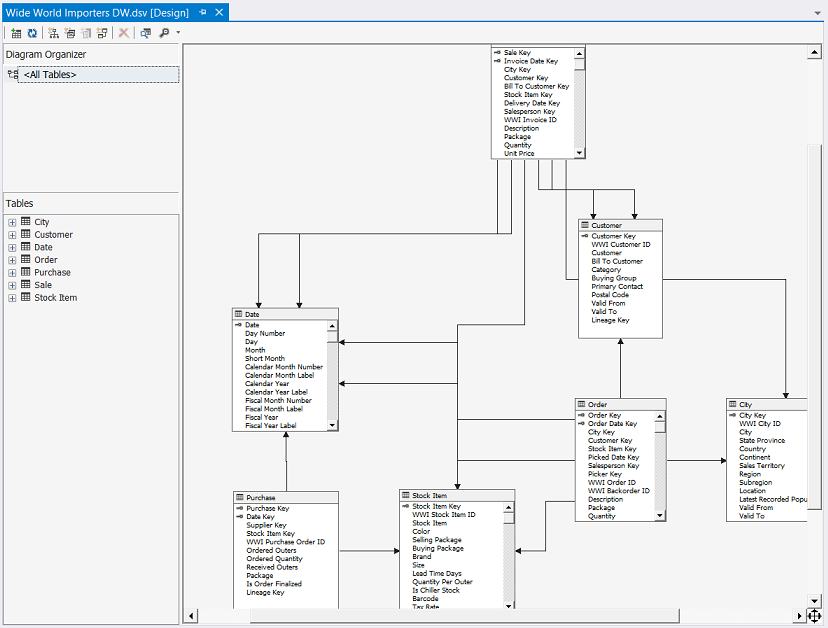
Upon completion of the “Data Source View” we are returned to our drawing surface and our completed “relationship diagram” appears (see above).
完成“数据源视图”后,我们将返回到绘图图面,并显示完成的“关系图”(请参见上文)。
创建我们的立方体 (Creating our cube)
In order to create our desired cube, we right click on the “Cubes” folder and select “New Cube” (see below).
为了创建所需的多维数据集,我们右键单击“ Cubes”文件夹,然后选择“ New Cube”(请参见下文)。

The “Cube Wizard” appears.
出现“多维数据集向导”。
We click “Next” (see above).
我们单击“下一步”(见上文)。
We opt to “Use existing tables” (see above). We now click “Next”.
我们选择“使用现有表”(见上文)。 现在,我们单击“下一步”。
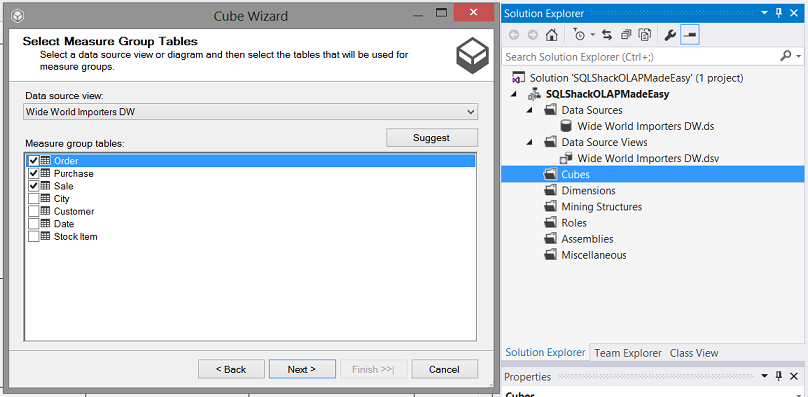
We are requested to select our “Fact / Measures” tables. These are the tables that contain data such as the monitary values of purchases / sales / orders. These tables are the quantifiable tables.
我们被要求选择“事实/措施”表。 这些表包含诸如采购/销售/订单的法定价值之类的数据。 这些表是可量化的表。
We select Order, Purchase and Sale (see above). We then click next.
我们选择订单,购买和销售(见上文)。 然后单击下一步。
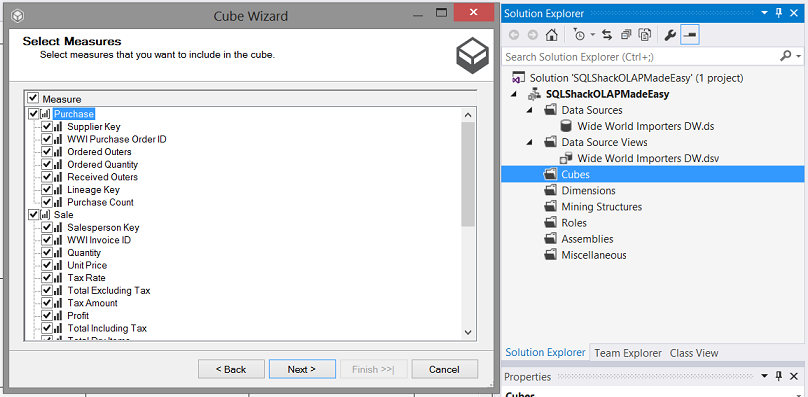
We are now presented with the “attributes” (of these fact tables) that will be included within the cube. We have the option to remove any unwanted attributes however for our present exercise, we shall accept all the attributes. We click “Next”.
现在,我们将获得(这些事实表的)“属性”,这些属性将包含在多维数据集中。 我们可以选择删除所有不需要的属性,但是对于我们当前的练习,我们将接受所有属性。 我们点击“下一步”。
选择我们的维度或“定性属性” (Selecting our dimensions or “qualitative attributes”)
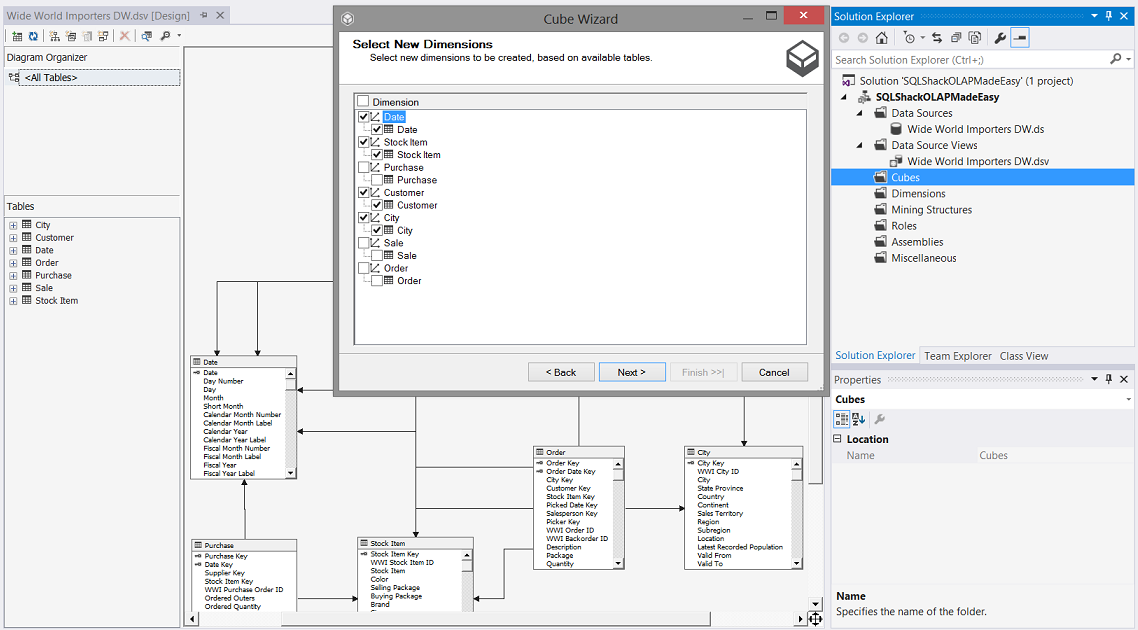
We are now asked to select our “Dimensions” (see above). We select “Date”, “Stock Item”, “Customer” and “City” (see above). We click “Next”.
现在,我们被要求选择“尺寸”(见上文)。 我们选择“日期”,“库存项目”,“客户”和“城市”(请参见上文)。 我们点击“下一步”。
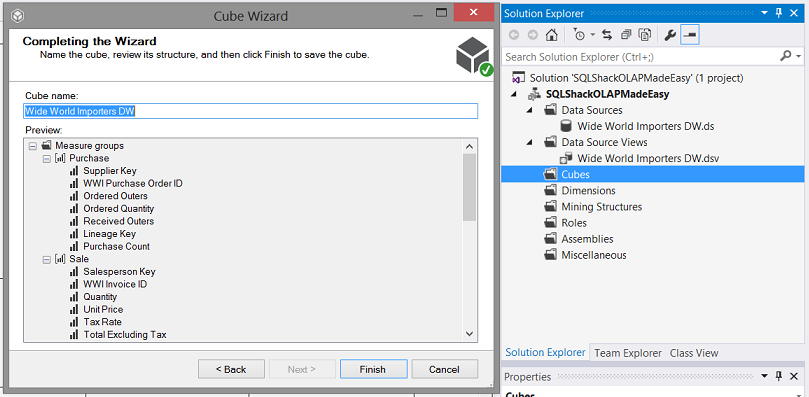
The fields within the Dimensions are shown to us and we click “Finish”.
向我们显示了尺寸中的字段,我们单击“完成”。
自定义尺寸 (Customizing our Dimensions)
Prior to continuing we have one further task to perform on our dimensions. Whilst the dimensions themselves exist, not all the necessary ATTRIBUTES are present within the “dimension” itself (see below).
在继续之前,我们还有另一项任务要在尺寸上执行。 尽管维度本身存在,但“维度”本身内并没有所有必需的属性(请参阅下文)。
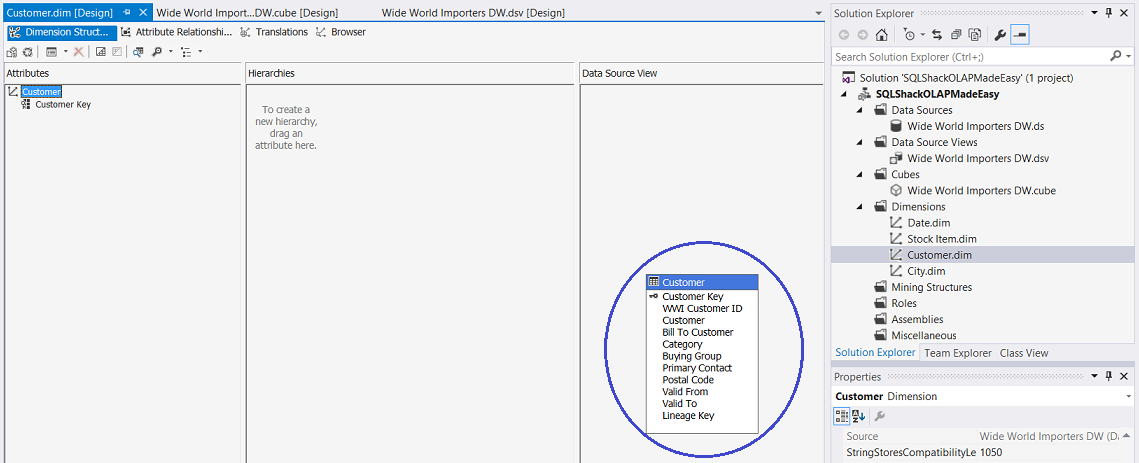
Double clicking upon the “Customer” dimension (see above), we open the attribute editor. We note that only the key is shown. We require more attributes and these attributes are located within the Customer table shown above.
双击“客户”维度(见上文),我们打开属性编辑器。 我们注意到,仅显示密钥。 我们需要更多属性,这些属性位于上面显示的“客户”表中。
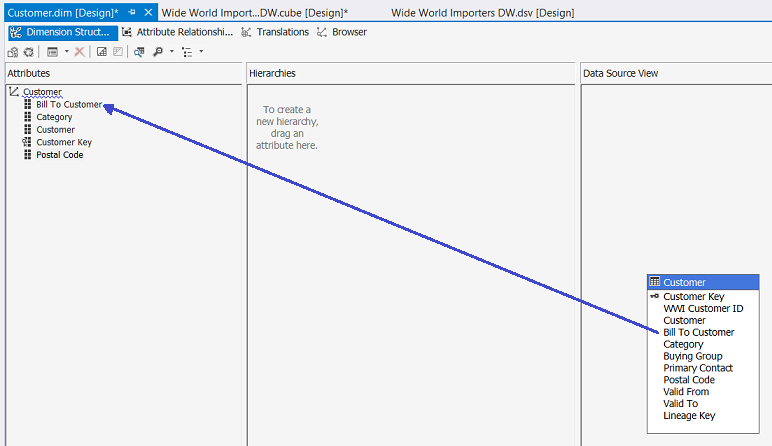
We drag “Bill to Name”, “Category”, “Customer” and “Postal Code” to the Attributes box from the bottom right list of Customer attributes (see above).
我们将“ Bill to Name”,“ Category”,“ Customer”和“ Postal Code”从“ Customer”属性的右下角列表拖到“ Attributes”框中(请参见上文)。
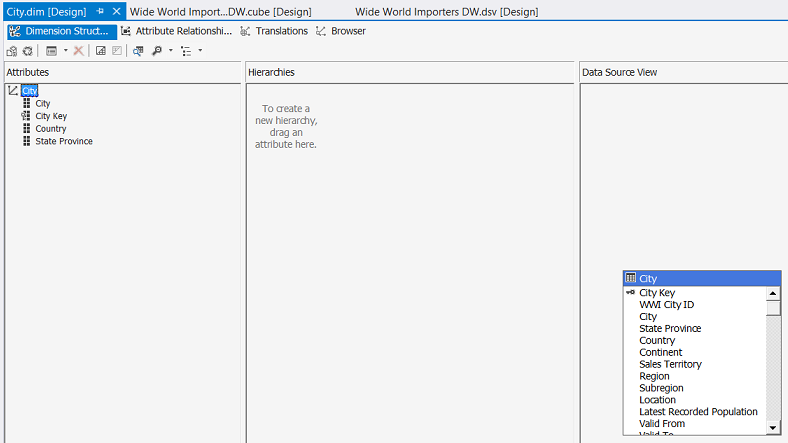
We do the same for the “City” attributes as may be seen above.
我们对“城市”属性进行了相同的操作,如上所示。
We now are in a position to process our cube and extract information from the Cube.
现在,我们可以处理多维数据集并从多维数据集中提取信息。
处理我们的立方体 (Processing our cube)
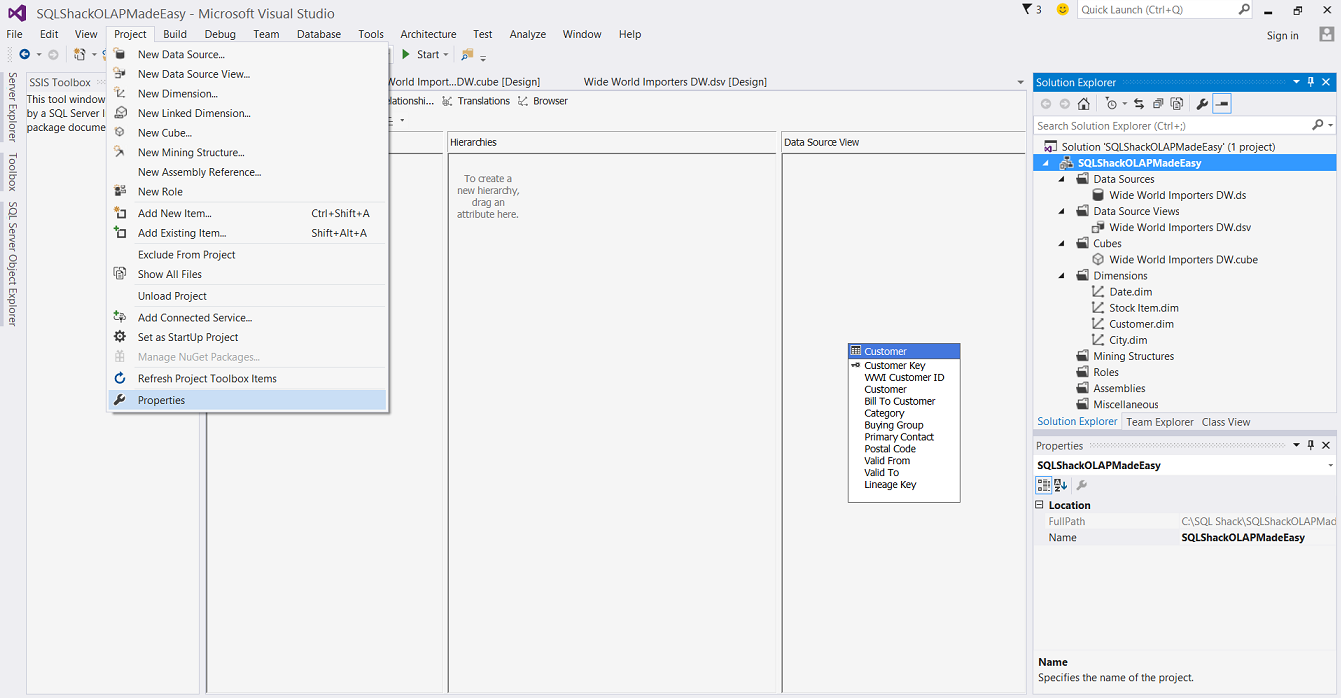
Clicking on the “Project” tab, we select the “Properties” (see above) .
单击“项目”选项卡,我们选择“属性”(见上文)。

We must now tell the system to where we wish to deploy our project, as well as to give the target OLAP database a name (see above). We click “OK” to leave the “Properties Page”.
现在,我们必须告诉系统我们希望将项目部署到何处,并为目标OLAP数据库命名(请参见上文)。 我们单击“确定”离开“属性页”。

We shall now “Build” or attempt to “Compile” our solution to detect any errors.
现在,我们将“构建”或尝试“编译”我们的解决方案以检测任何错误。
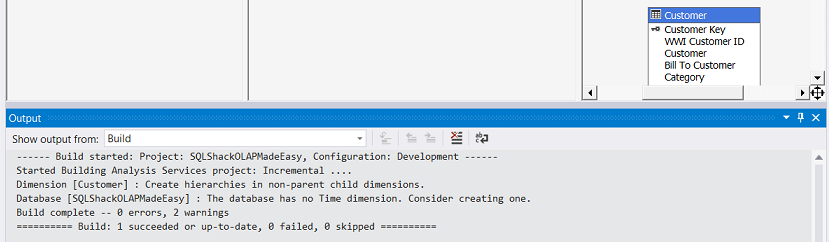
The “Build” succeeds.
“构建”成功。
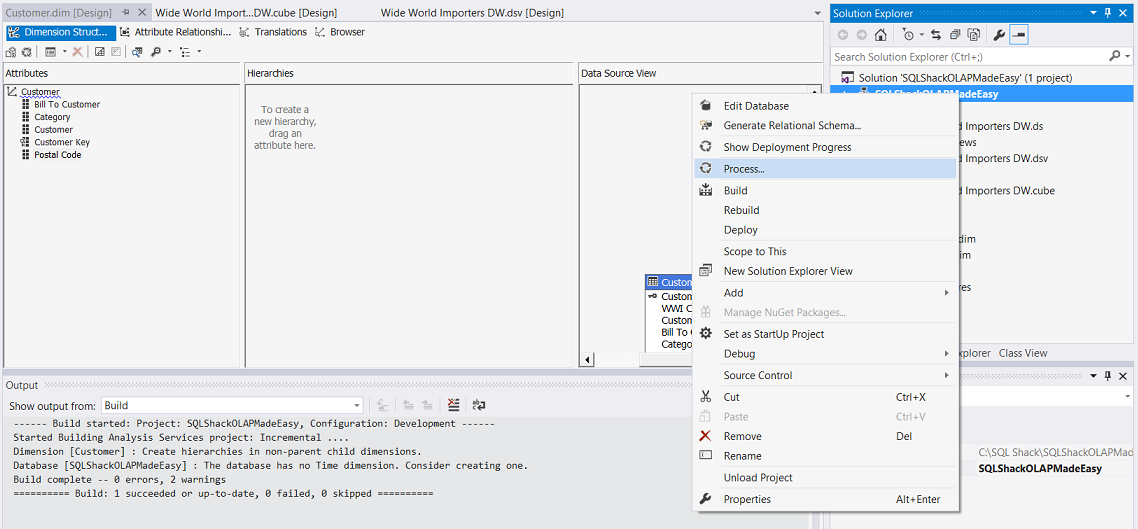
Once again, we right click upon our Project name (see above) and we select “Process” from the context menu (see above).
再次,我们右键单击我们的项目名称(见上文),然后从上下文菜单中选择“处理”(见上文)。

We are informed that the “Server content appears to be out of date”. We tell the system that we want to build and deploy the project.
我们被告知“服务器内容似乎已过时”。 我们告诉系统我们要构建和部署项目。
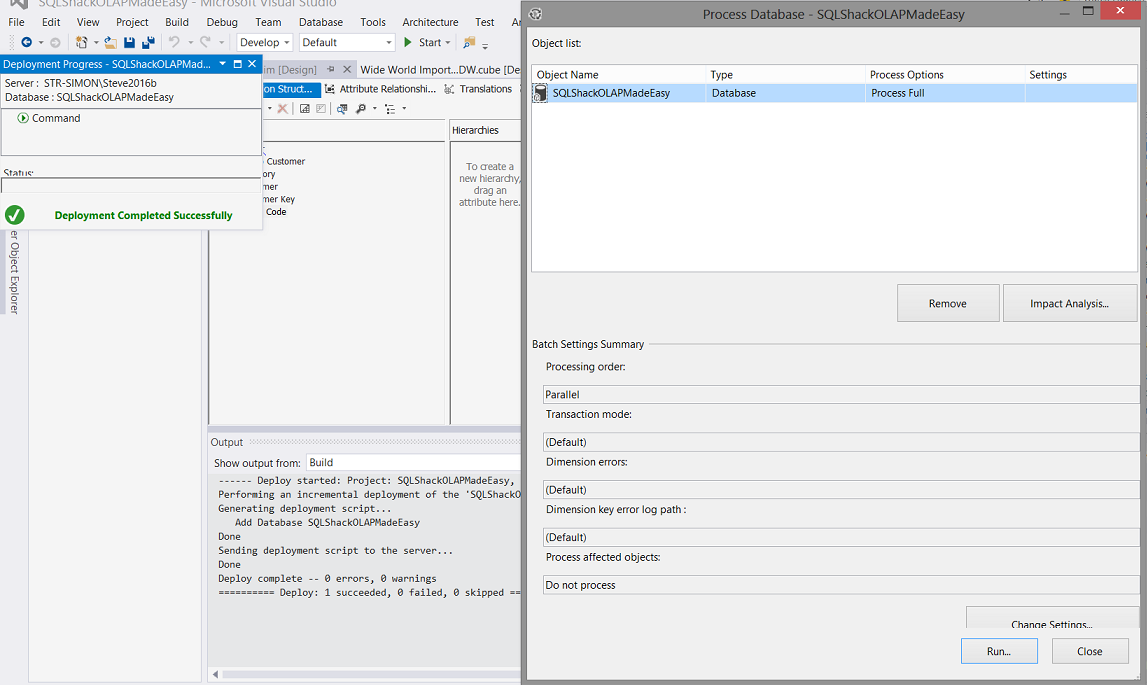
We are informed that the deployment was successful (see above in green) . The “Process Database” dialogue box appears asking us if we wish to process the database. We click “Run”.
我们获悉部署成功(请参见上面的绿色)。 出现“处理数据库”对话框,询问我们是否要处理数据库。 我们点击“运行”。

Upon completion of the processing and if no errors were encountered, we are informed of “Successful processing” (see above). What this “processing” achieved was to create aggregated financial results for all customers, for all cities within the realm of the given data. We close all open processing windows.
处理完成后,如果未遇到任何错误,我们将被告知“成功处理”(见上文)。 该“处理”的目的是为给定数据范围内的所有城市的所有客户创建汇总的财务结果。 我们关闭所有打开的处理窗口。
We now find ourselves back within the Cube designer surface. Let us see what kind of results we can observe.
现在,我们回到了Cube设计器表面。 让我们看看我们可以观察到什么样的结果。
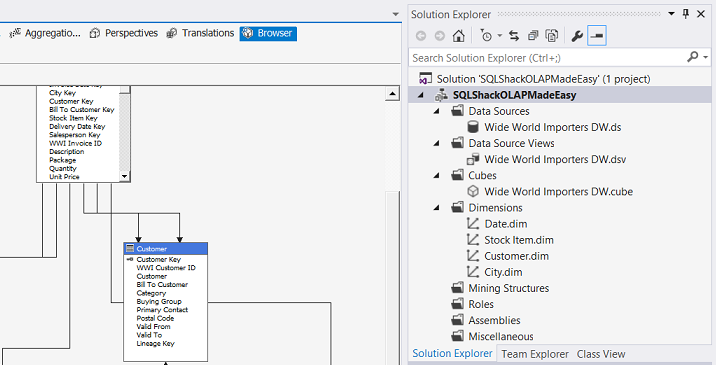
Clicking upon the “Brower” tab, brings up the “Cube Browser” (see above)
单击“ Brower”选项卡,打开“ Cube Browser”(请参见上文)
Prior to creating our first MDX query, we decide that we wish to create a calculated field for “Revenue”.
在创建第一个MDX查询之前,我们决定希望为“收入”创建一个计算字段。
Revenue is defined as the quantity sold * unit price. We click upon the “Calculations” tab and create a new “Calculation”.
收入定义为已售数量*单价。 我们单击“计算”选项卡并创建一个新的“计算”。
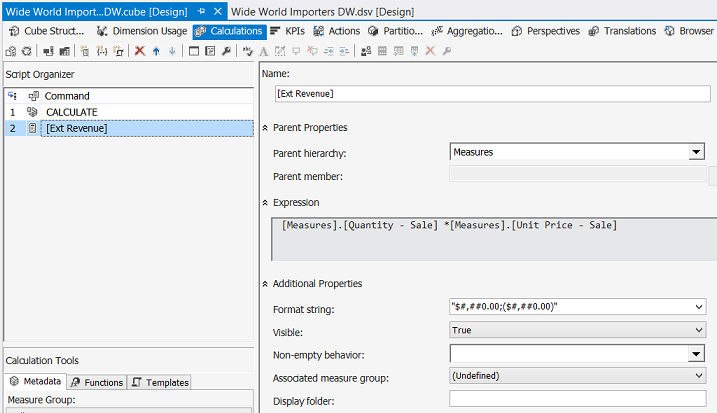
Our new calculated field may be seen above and it is defined as “Quantity – Sale” * “Unit Price – Sale”.
我们新的计算字段可以在上方看到,其定义为“数量-销售” *“单价-销售”。
With our calculated field being designed, we are now in a position to browse our cube. We reprocess the cube and then click upon our Broswer tab (see above) .
通过设计计算字段,我们现在可以浏览多维数据集。 我们重新处理多维数据集,然后单击“浏览器”选项卡(请参见上文)。

We note that our calculated field appears below the measure tables. This is normal and the calculation is ready for us to utilize.
我们注意到,我们的计算字段显示在度量表下方。 这是正常现象,计算已准备就绪,可供我们使用。

We drag “Quantity- Sale” , “Unit Price – Sale” and our calculated field “Ext Revenue” onto the design surface. The reader will note that the aggregated values of all the data are shown in the one row above. Further using a calculator and mulitplying the figure together, we confirm that our calculated field is working accurately. The only issue being that the one aggregated row is of little use.
我们将“数量-销售”,“单价-销售”和计算出的字段“额外收入”拖到设计图面上。 读者将注意到,所有数据的汇总值显示在上方的一行中。 进一步使用计算器并将这些数字混合在一起,我们确认我们计算出的字段正确运行。 唯一的问题是,一个聚合行几乎没有用。
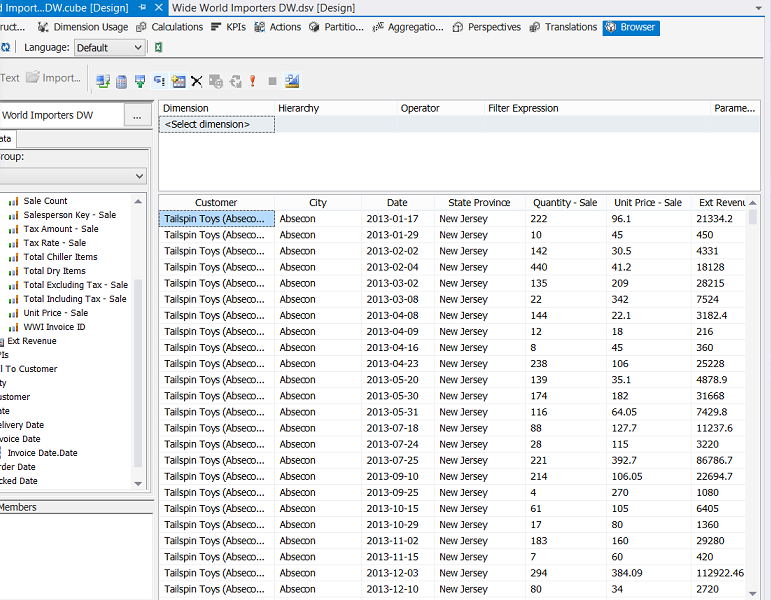
By adding the “Customer Name”, the “City” ,the “Invoice Date”, Invoice No” and the “State Province” we see the revenue from each invoice for each invoice date. In short we have more meaningful results.
通过添加“客户名称”,“城市”,“发票日期”,发票编号和“州”,我们可以看到每个发票日期的每个发票的收入。 简而言之,我们得到了更有意义的结果。
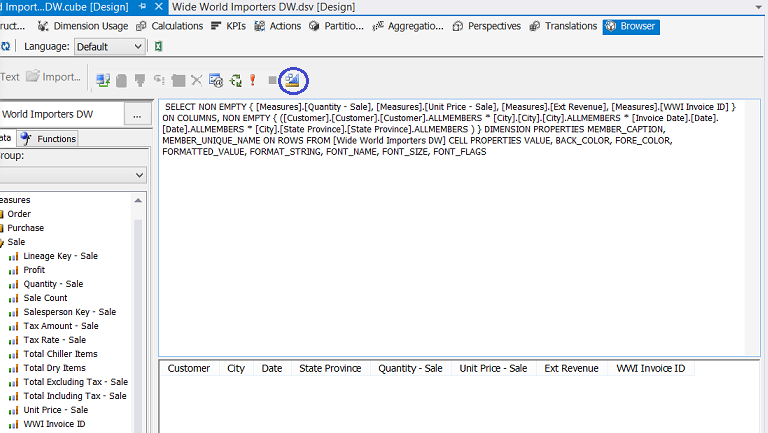
By clicking on the “Design Mode” tab we see that MDX code behind the data extract that we created above. This code becomes important as we shall use this code for the report query that we shall create in a few minutes.
通过单击“设计模式”选项卡,我们可以看到在上面创建的数据提取后面的MDX代码。 该代码非常重要,因为我们将在几分钟内使用此代码进行报表查询。
As a double check that we are in fact on the right footing, we now call up SQL Server Management Studio and login to our OLAP server. We select the SQLShack OLAP database that we just created.
仔细检查一下我们实际上是否处于正确的位置,我们现在调用SQL Server Management Studio并登录到OLAP服务器。 我们选择刚创建SQLShack OLAP数据库。
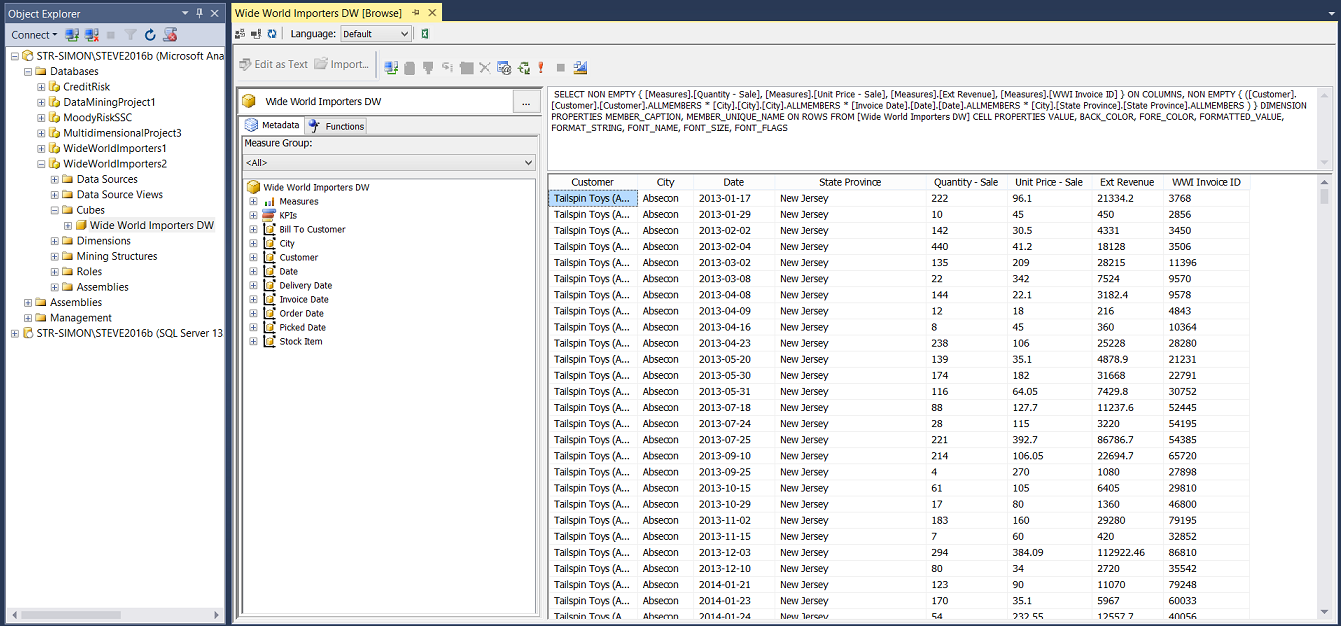
Utilizing the MDX code from our Visual Studio project we can copy and paste the same code into the Cube Browser within SQL Server Management Studio. The results may be seen above.
利用Visual Studio项目中的MDX代码,我们可以将相同的代码复制并粘贴到SQL Server Management Studio的多维数据集浏览器中。 结果可以在上面看到。
“通配符” (The “Wild Card”)
Before proceeding to create our reports, we have one final task to perform. We are going to create a linked server to our Analysis database that we have just constructed.
在继续创建报告之前,我们需要完成最后一项任务。 我们将创建一个到我们刚刚构建的Analysis数据库的链接服务器。
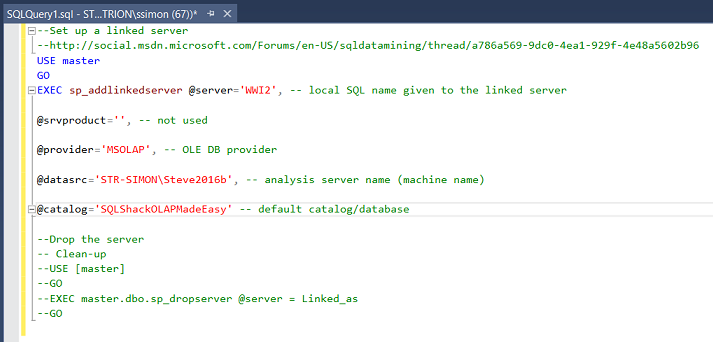
This is the code that we shall utilize and the code itself may be found in Addenda 2.
这是我们将要使用的代码,并且代码本身可以在附录2中找到。
Now that our linked server has been created, we are in a position to begin with our report query!
现在已经创建了链接服务器,我们可以开始查询报告了!
创建我们的报告查询 (Creating our report query)
Opening SQL Server Management Studio, we open a new query. Utilizing the DMX code that we obtained, we place that code within an “OpenQuery” utilizing our new linked server (see below).
打开SQL Server Management Studio,我们打开一个新查询。 利用获得的DMX代码,我们使用新的链接服务器将代码放在“ OpenQuery”中(请参见下文)。
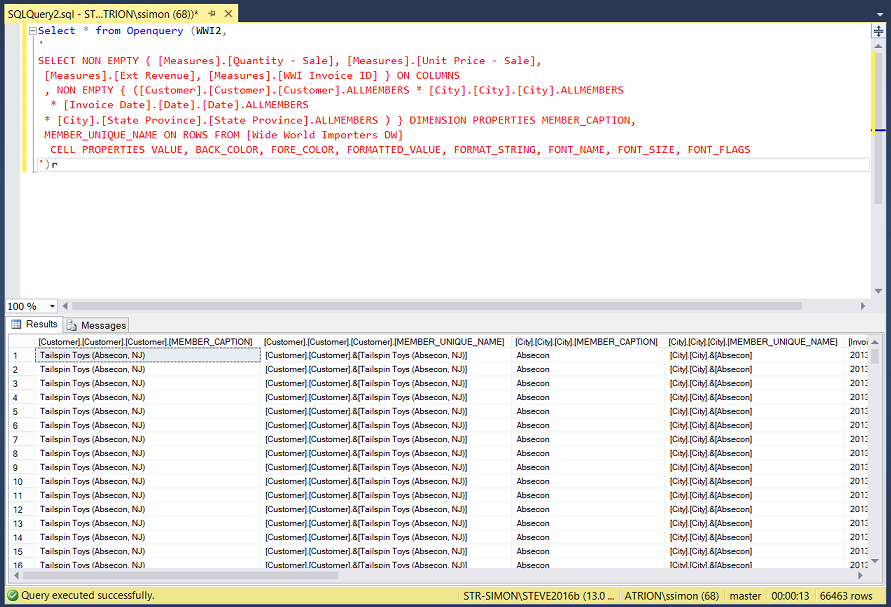
Now, the “wise acre” will question, why are we doing this. The answer is fairly simple. The sub query is the MDX query and the outer query is developed in T-SQL! Being developed in T-SQL permits us to filter the result set utilizing all the “goodies” such as case logic within the T-SQL portion predicate. Yes, we are pulling all the AGGREGATED data from the cube however if the data is properly aggregated during the processing of the cube , then the “hit” is not that bad.
现在,“英亩”将提出疑问,我们为什么要这样做。 答案很简单。 子查询是MDX查询,外部查询是在T-SQL中开发的! 用T-SQL开发允许我们利用所有“好东西”(例如T-SQL部分谓词中的案例逻辑)过滤结果集。 是的,我们正在从多维数据集中提取所有已聚合的数据,但是,如果在处理多维数据集期间正确地聚合了数据,那么“命中”还算不错。
The one point that is not immediately obvious is that the true names of the extracted fields are not what one would expect. Normally and as a once off we publish the results of the query to a table. This will enable us to determine the correct names of the fields as seen by SQL Server (see below).
一点不是立即显而易见的一点是,所提取字段的真实名称不是人们所期望的。 通常,一次将查询结果发布到表中。 这将使我们能够确定SQL Server看到的字段的正确名称(请参见下文)。

Modifying the query slightly we can now add a T-SQL date predicate (see below):
稍微修改查询,我们现在可以添加一个T-SQL日期谓词(见下文):
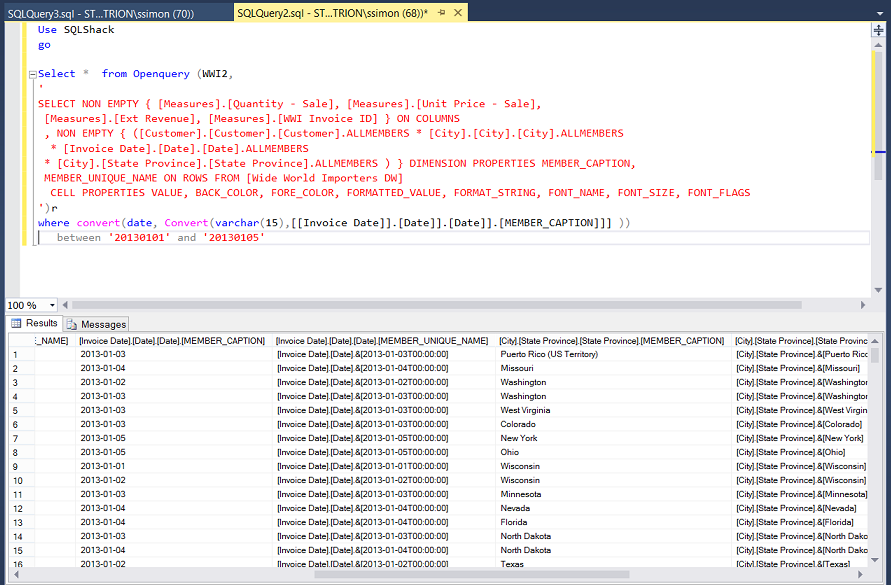
The reader will note that the start and end dates have been hard wired. We are going to alter this so that the predicate accepts a start and end date from parameters (see below):
读者会注意到,开始日期和结束日期已经过硬连线。 我们将对此进行更改,以使谓词接受参数的开始日期和结束日期(请参见下文):
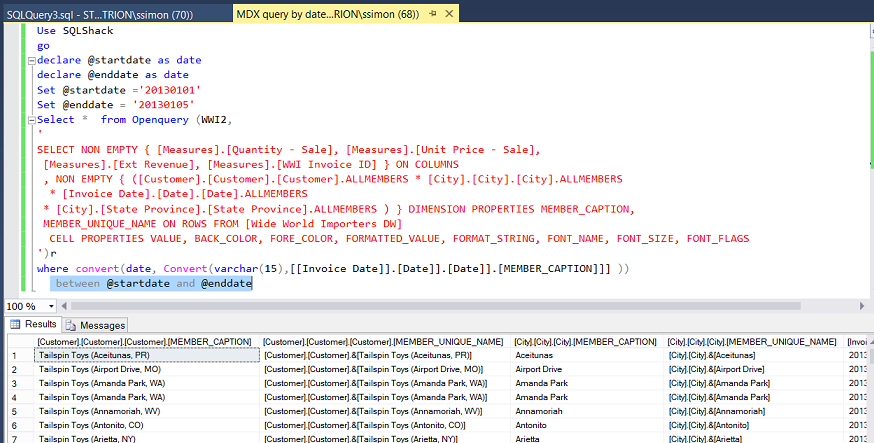
Our last modification to our query is to create a stored procedure, which will be utilized by our report.
我们对查询的最后修改是创建一个存储过程,该存储过程将由我们的报表使用。
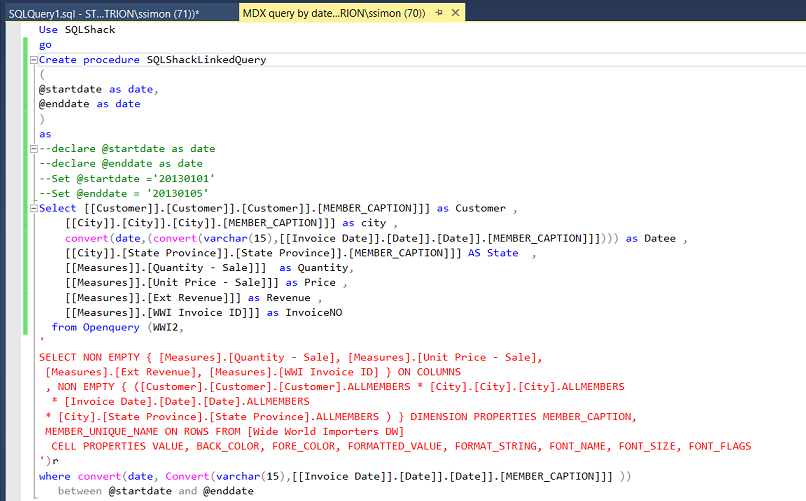
The reader will note that we have selected a subset of the fields necessary for our report. As a reminder the field names appear a bit wonky however this is the way that SQL Server “sees“ them.
读者会注意到,我们已经选择了报告所必需的部分字段。 提醒一下,字段名称看起来有些奇怪,但这是SQL Server“查看”它们的方式。
创建我们的报告 (Creating our report)
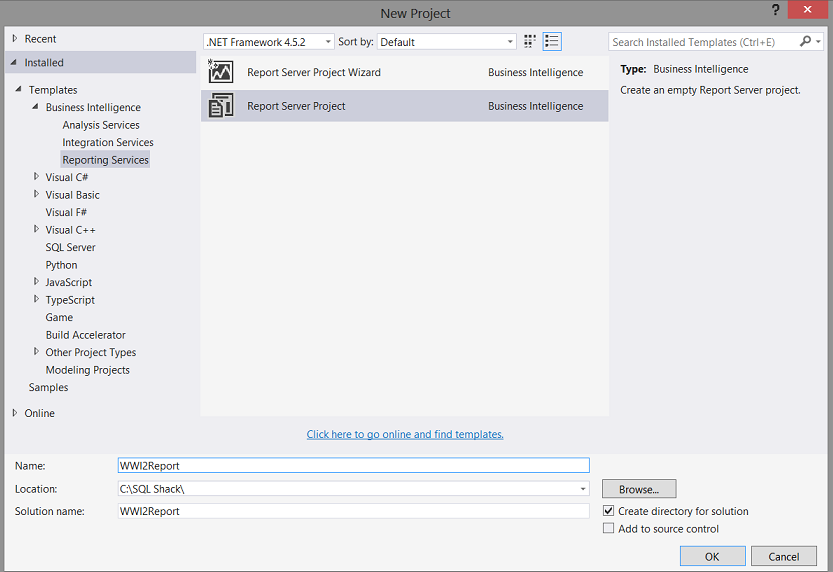
Once again we open Visual Studio 2015 or SQL Server Data Tools version 2010 or above. This time however we choose a “Report Services Project” (see above). We give our project an name and click “OK” (see above).
我们再次打开Visual Studio 2015或SQL Server Data Tools版本2010或更高版本。 但是,这次我们选择“报告服务项目”(请参见上文)。 我们给我们的项目起一个名字,然后单击“确定”(见上文)。

Having created the project we are now brought to our design surface. Our next task is to create a new “Shared Data Source” which will connect to our relational database table. As we have discussed in past “get togethers”, the database may be likened to the water faucet on the side of your house. The “data source” may then be likened to a water hose that will carry the data to where it is required.
创建项目后,我们现在进入了设计工作。 我们的下一个任务是创建一个新的“共享数据源”,它将连接到我们的关系数据库表。 正如我们过去讨论过的“聚在一起”一样,该数据库可以比喻为房屋侧面的水龙头。 然后,可以将“数据源”比喻为将数据携带到所需位置的水管。

We right click on the “Shared Data Sources” folder (as above). We select “Add New Data Source”.
我们右键单击“共享数据源”文件夹(如上所述)。 我们选择“添加新数据源”。

The “Connection Properties” dialogue box opens. We tell the system the name of the SQL Server Instance and database to which we wish to connect (see above).
“连接属性”对话框打开。 我们告诉系统希望连接SQL Server实例和数据库的名称(请参见上文)。

We are returned to the “Shared Data Source Properties” dialogue box (as may be seen above). We click “OK” to continue.
我们返回到“共享数据源属性”对话框(如上所示)。 我们单击“确定”继续。
配置我们的新报告 (Configuring our new report)

Our next task is to create our report. To do so we right click upon the “Reports” folder and select “Add” and then “New Item”.
我们的下一个任务是创建报告。 为此,我们右键单击“ Reports”文件夹,然后选择“ Add”,然后选择“ New Item”。
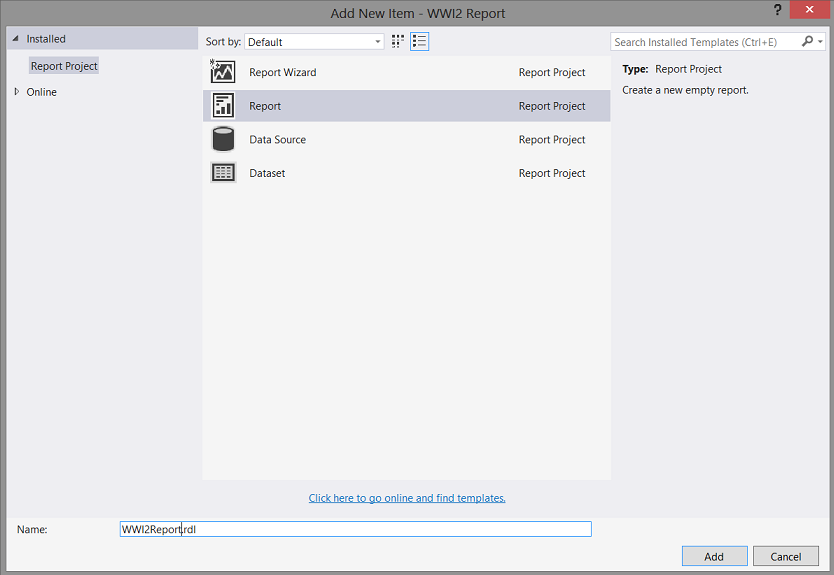
We find ourselves on the “Add New Item” screen. We select “Report” and give our report a name (as shown above). We click “Add” to continue.
我们发现自己在“添加新项目”屏幕上。 我们选择“报告”并给我们的报告起一个名字(如上所示)。 我们单击“添加”继续。
We find ourselves on our report design surface.
我们发现自己在报告设计图面上。
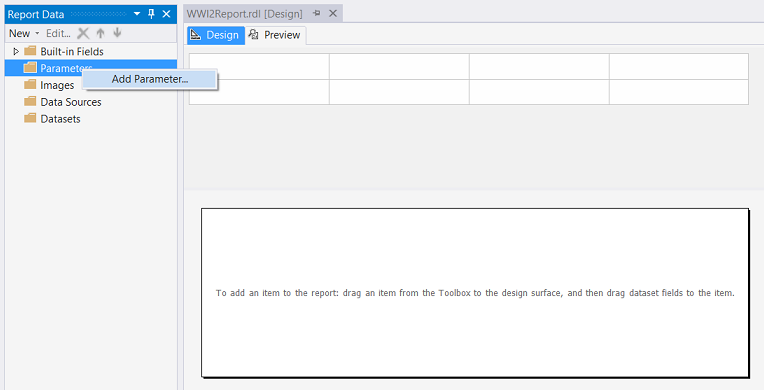
Now that we are on the report design surface, our first task is to define two parameters that may be utilized to pass a start and end date to our report query. The reader is reminded that when we created the initial query that we extracted records for a certain time frame. This time frame will be determined by the arguments passed to the query via the two parameters.
现在我们处于报表设计界面,我们的第一个任务是定义两个参数,这些参数可用于将开始日期和结束日期传递给我们的报表查询。 提醒读者,当我们创建初始查询时,我们提取了特定时间范围内的记录。 该时间范围将取决于通过两个参数传递给查询的参数。
We right click upon the “Parameters” folder and select “Add Parameter” (see above).
我们右键单击“ Parameters”文件夹,然后选择“ Add Parameter”(请参见上文)。

We assign a name to our parameter and set the data type to “Date / Time” (see above).
我们为参数分配一个名称,并将数据类型设置为“日期/时间”(参见上文)。
In a similar fashion we create and initialize our End Date parameter.
我们以类似的方式创建并初始化“结束日期”参数。

Our drawing “canvas” now appears as follows(see above).
现在,我们的图形“画布”如下所示(见上文)。
创建我们的本地数据集 (Creating our Local Dataset)
Now that we have created our parameters, we have one last structural task to complete and that is to create a dataset.
现在我们已经创建了参数,我们还有最后一个结构任务要完成,那就是创建数据集。

To create this dataset (which may be compared to a watering can which contains a “subset” of the water from the faucet on the house) , we right click on the “Dataset” folder and select “Add dataset”. As with the water can example, our dataset will contain the data that is extracted from our OLAP database via our query AND our linked server.
要创建此数据集(可以与其中包含房屋水龙头“子集”的喷壶进行比较),我们右键单击“ Dataset”文件夹,然后选择“添加数据集”。 与“水罐”示例一样,我们的数据集将包含通过查询和链接服务器从OLAP数据库中提取的数据。

The “Dataset Properties” dialogue box opens. We give our dataset a name and as our dataset is a “local” dataset, we are required to create a new local data source that will be connected to the “Shared data source” that we just created. We click the “New” button (see above).
“数据集属性”对话框打开。 我们给数据集起一个名字,并且由于我们的数据集是一个“本地”数据集,因此我们需要创建一个新的本地数据源,该数据源将连接到我们刚创建的“共享数据源”。 我们点击“新建”按钮(见上文)。

Having clicked the “New” button, we find ourselves on the “Data Sources Properties” dialogue screen. We give our local datasource a name and link it to our “Shared Data Source” (see above). We click “OK” to continue. We are returned to the ‘DataSet Properties” screen (see below).
单击“新建”按钮后,我们将在“数据源属性”对话框屏幕中找到自己。 我们为本地数据源命名,并将其链接到“共享数据源”(请参见上文)。 我们单击“确定”继续。 我们返回到“数据集属性”屏幕(如下所示)。

We select “Stored Procedure” for the “Query type” and using the drop down box, we select the stored procedure that we created above (see above).
我们为“查询类型”选择“存储过程”,并使用下拉框选择上面创建的存储过程(见上文)。

Having selected our stored procedure, we click the “Refresh Fields” button to bring in the list of fields that will be available to our report (see above).
选择了存储过程后,我们单击“刷新字段”按钮以引入可用于我们的报告的字段列表(请参见上文)。

By clicking upon the “Fields” tab (upper left of the screen shot above) we may now see the fields that will become available to our report.
通过单击“字段”选项卡(在上面的屏幕截图的左上方),我们现在可能会看到可用于我们报告的字段。

Clicking on the “Parameters” tab we note that the two parameters that we created with our stored procedure are now visible. These are the “Parameter Name” . The “Parameter Value” will come from user input (as arguments) via the two report parameters that we just created. Hence, we must assign the correct arguments to the stored procedure parameters.
单击“参数”选项卡,我们注意到使用存储过程创建的两个参数现在可见。 这些是“参数名称”。 “参数值”将通过我们刚刚创建的两个报告参数来自用户输入(作为参数)。 因此,我们必须为存储过程参数分配正确的参数。

The screen shot above shows us the correct configuration.
上面的屏幕截图显示了正确的配置。
添加我们的报告控件 (Adding our report controls)
Now that we have our report infrastucture or “plumbing” established, we are in a position to add the necessary controls required to allow the end user to view his or her data.
现在我们已经建立了报告基础结构或“管道”,我们可以添加必要的控件以允许最终用户查看其数据。
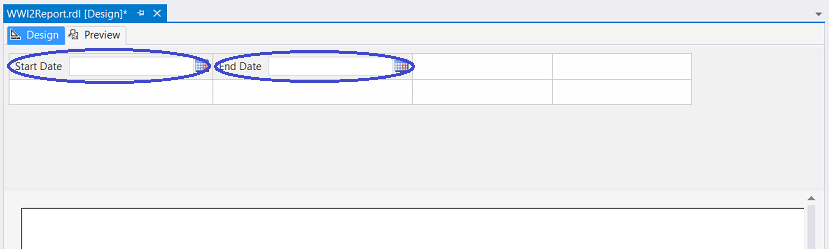
Our design surface shown above,the astute reader will note the two calendar controls (parameters) that we have just created.
上面显示的设计图,精明的读者会注意到我们刚创建的两个日历控件(参数)。

We drag a”Matrix” control from the tool box onto the drawing surface (see above).
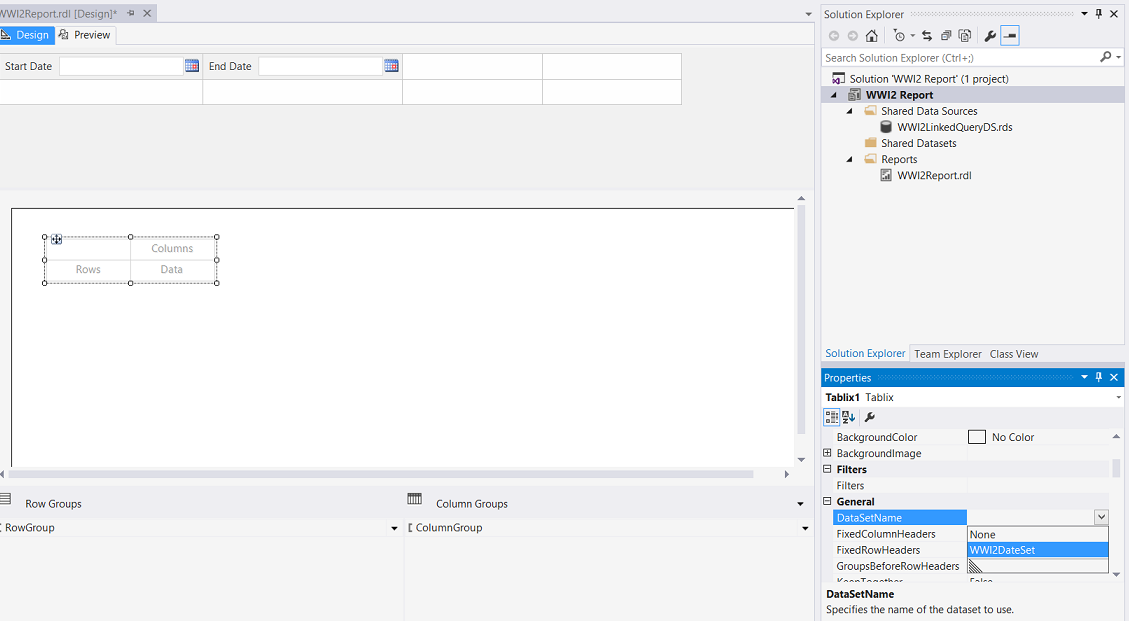
We click F4 to bring up the properties box of the matrix that we have just added to our work surface. We set its “DataSetName” property to the name of the dataset that we created above (see above).
单击F4调出刚添加到工作表面的矩阵的属性框。 我们将其“ DataSetName”属性设置为上面创建的数据集的名称(请参见上文)。
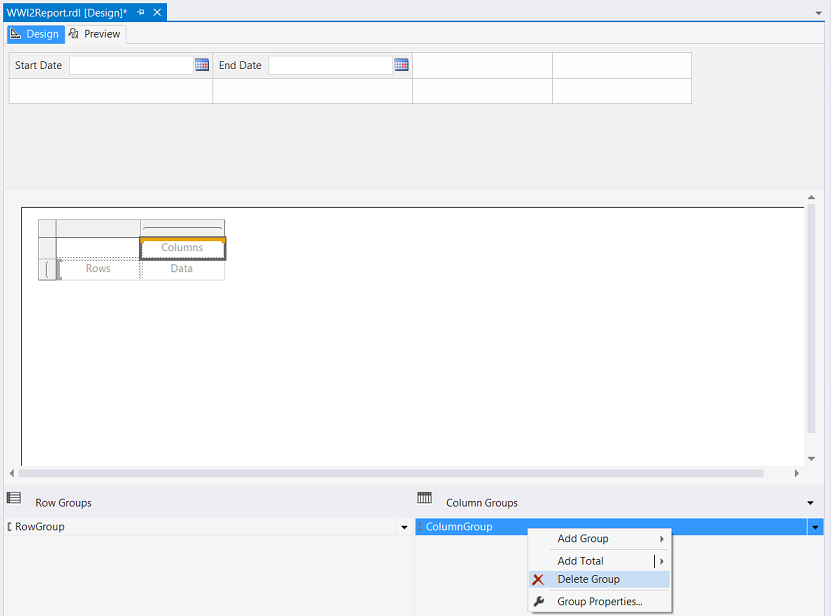
As we shall not be utilizing “Column Grouping”, we decide to remove the column grouping by right clicking upon the “ColumnGroup” and selecting “Delete Group” (see above).
由于我们将不使用“列分组”,因此我们决定通过右键单击“ ColumnGroup”并选择“ Delete Group”来删除列分组(请参见上文)。
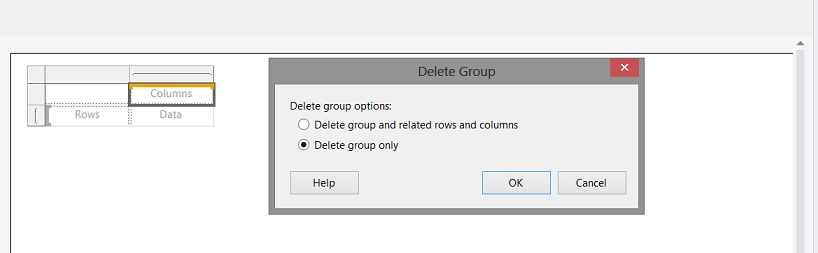
We are asked if we wish to delete the group and its related rows and columns OR merely to delete the grouping itself. We select “Delete group only” (see above).
我们被问到是否要删除该组及其相关的行和列,还是仅删除该组本身。 我们选择“仅删除组”(请参见上文)。
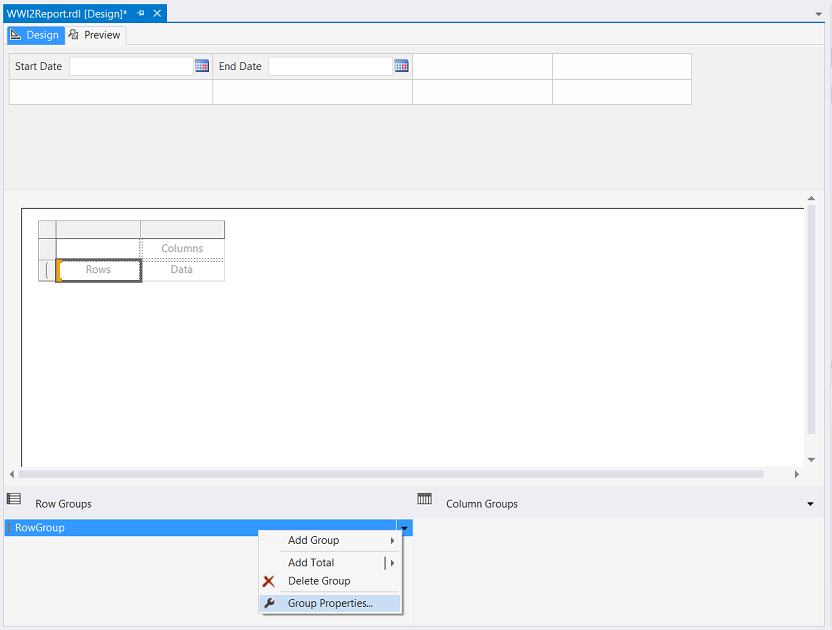
We do however wish to set the “Row Grouping” as we shall want to view our data as a summation of revenue by invoice number. We click upon the “Group Properties” tab.
但是,我们确实希望设置“行分组”,因为我们希望将数据视为按发票编号的收入总和。 我们单击“组属性”选项卡。

In the screen shot above, we set the grouping to be based upon invoice number.
在上面的屏幕截图中,我们将分组设置为基于发票编号。
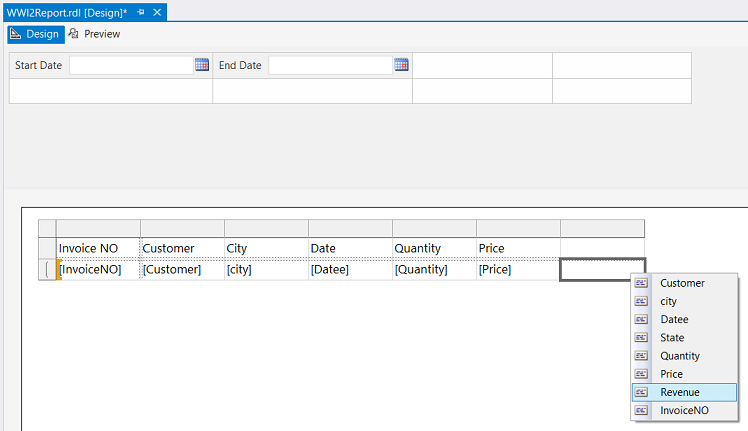
Our next task is to add the fields from the stored procedure to our matrix. This is shown above. We have discussed this process in detail in numerous past “chats”.
我们的下一个任务是将存储过程中的字段添加到矩阵中。 如上所示。 我们已经在过去的许多“聊天”中详细讨论了此过程。
Our report construction is now complete.
我们的报告构建现已完成。
让我们旋转一下 (Let us give it a whirl)

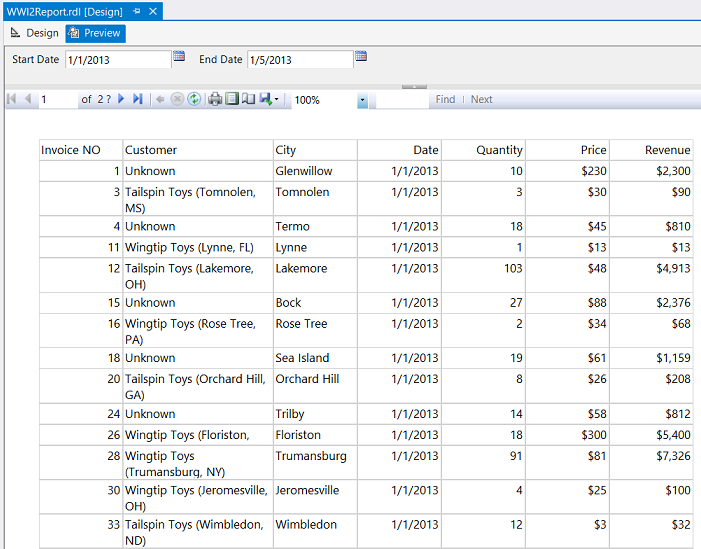
Clicking the “Preview” tab, we select the “Calendar” control and set the start date to 1/1/2013 (see above).
单击“预览”选项卡,我们选择“日历”控件,并将开始日期设置为2013年1月1日(请参见上文)。

In a smilar fashion we set the end date to 1/5/2013 (see above). We now click “View Report”.
我们以笑容的方式将结束日期设置为1/5/2013(请参见上文)。 现在,我们单击“查看报告”。

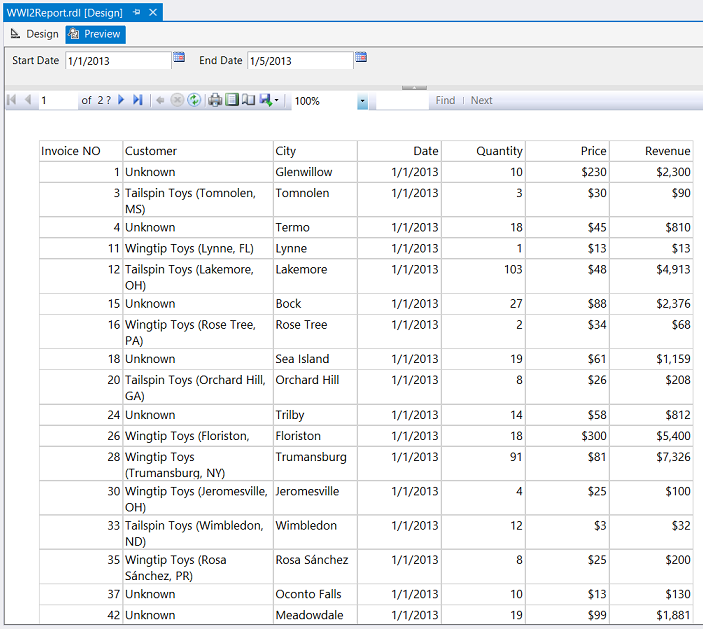
We note that our data is now visible to the user and that our report is now complete. Naturally the reader will want to sort and format the data. We have covered this as well in numerous past “get togethers” however the screen dump below shows our data sorted by invoice number and the numeric values have been rounded to the nearest dollar (see below).
我们注意到,我们的数据现在对用户可见,并且我们的报告现已完成。 读者自然会希望对数据进行排序和格式化。 我们在过去的许多“聚会”中也对此进行了介绍,但是下面的屏幕转储显示了我们的数据按发票编号排序,并且数值已四舍五入到最接近的美元(请参见下文)。
In order to polish up the data it is necessary to convert a few of the fields to numeric values. This is most easily achieved within the stored procedure itself. I have included the final code sample in Addenda 3 (below).
为了完善数据,有必要将一些字段转换为数值。 这在存储过程本身中很容易实现。 我将最终的代码示例包含在附录3(如下)中。
结论 (Conclusions)
Oft times we are all faced with the delema of having to work with MDX. Filtering the data via MDX is a challenge even at the best of times. This is especially true when predicates are complex and change periodically.
通常,我们所有人都不得不面对与MDX合作的麻烦。 即使在最佳时间,通过MDX过滤数据也是一项挑战。 当谓词很复杂并且定期更改时,尤其如此。
Through the usage of a small piece of MDX code within a subquery, we are able to pull the necessary data and efficiently and effectively filter it via T-SQL; if we utilize a linked server and the OpenQuery function.
通过在子查询中使用一小段MDX代码,我们能够提取必要的数据,并通过T-SQL对其进行有效过滤。 如果我们使用链接服务器和OpenQuery函数。
So we come to the end of another “fire side chat”. As always, should have any questions, please do feel free to contact me.
因此,我们来到了另一个“火边聊天”的结尾。 与往常一样,如有任何疑问,请随时与我联系。
In the interim ‘Happy programming’.
在过渡期间“快乐编程”。
附录1(OLAP查询) ( Addenda 1 (OLAP Query) )
SELECT NON EMPTY { [Measures].[WWI Invoice ID], [Measures].[Quantity - Sale], [Measures].[Unit Price - Sale], [Measures].[Ext Revenue] } ON COLUMNS, NON EMPTY { ([Date].[Date].[Date].ALLMEMBERS * [City].[City].[City].ALLMEMBERS * [Customer].[Customer].[Customer].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM [Wide World Importers DW] CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
附录2(创建链接服务器) ( Addenda 2 (Creating a linked server) )
--Set up a linked server
--http://social.msdn.microsoft.com/Forums/en-US/sqldatamining/thread/a786a569-9dc0-4ea1-929f-4e48a5602b96
USE master
GO
EXEC sp_addlinkedserver @server='WWI2', -- local SQL name given to the linked server
@srvproduct='', -- not used
@provider='MSOLAP', -- OLE DB provider
@datasrc='STR-SIMON\Steve2016b', -- analysis server name (machine name)
@catalog='SQLShackOLAPMadeEasy' -- default catalog/database
--Drop the server
-- Clean-up
--USE [master]
--GO
--EXEC master.dbo.sp_dropserver @server = WWI2
--GO
附录3(我们最终的链接服务器查询) ( Addenda 3 (Our final Linked Server Query) )
Use SQLShack
go
Alter procedure SQLShackLinkedQuery
(
@startdate as date,
@enddate as date
)
as
--declare @startdate as date
--declare @enddate as date
--Set @startdate ='20130101'
--Set @enddate = '20130105'
Select [[Customer]].[Customer]].[Customer]].[MEMBER_CAPTION]]] as Customer ,
[[City]].[City]].[City]].[MEMBER_CAPTION]]] as city ,
convert(date,(convert(varchar(15),[[Invoice Date]].[Date]].[Date]].[MEMBER_CAPTION]]]))) as Datee ,
[[City]].[State Province]].[State Province]].[MEMBER_CAPTION]]] AS State ,
[[Measures]].[Quantity - Sale]]] as Quantity,
Convert(Decimal(38,2),Convert(varchar(20),[[Measures]].[Unit Price - Sale]]])) as Price ,
Convert(Decimal(38,2),Convert(varchar(20),[[Measures]].[Ext Revenue]]])) as Revenue ,
Convert(int,Convert(varchar(20),[[Measures]].[WWI Invoice ID]]])) as InvoiceNO
from Openquery (WWI2,
'
SELECT NON EMPTY { [Measures].[Quantity - Sale], [Measures].[Unit Price - Sale],
[Measures].[Ext Revenue], [Measures].[WWI Invoice ID] } ON COLUMNS
, NON EMPTY { ([Customer].[Customer].[Customer].ALLMEMBERS * [City].[City].[City].ALLMEMBERS
* [Invoice Date].[Date].[Date].ALLMEMBERS
* [City].[State Province].[State Province].ALLMEMBERS ) } DIMENSION PROPERTIES MEMBER_CAPTION,
MEMBER_UNIQUE_NAME ON ROWS FROM [Wide World Importers DW]
CELL PROPERTIES VALUE, BACK_COLOR, FORE_COLOR, FORMATTED_VALUE, FORMAT_STRING, FONT_NAME, FONT_SIZE, FONT_FLAGS
')r
where convert(date, Convert(varchar(15),[[Invoice Date]].[Date]].[Date]].[MEMBER_CAPTION]]] ))
between @startdate and @enddate
order by InvoiceNO
参考资料 (References)
- OPENQUERY (Transact-SQL)OPENQUERY(Transact-SQL)
- Create Linked Servers (SQL Server Database Engine)创建链接服务器(SQL Server数据库引擎)
- Formatting Numbers and Dates (Report Builder and SSRS)格式化数字和日期(报表生成器和SSRS)
翻译自: https://www.sqlshack.com/effectively-extract-data-from-olap-cube-by-relying-upon-tsql/
olap 多维分析















 5995
5995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









