





In the article, Python scripts to format data in Microsoft Excel, we used Python scripts for creating an excel and do various data formatting. Python is an interesting high-level programming language. You can go through various use cases of Python on SQLShack.
在本文中, Python脚本用于在Microsoft Excel中格式化数据 ,我们使用Python脚本来创建excel并进行各种数据格式化。 Python是一种有趣的高级编程语言。 您可以在SQLShack上介绍Python的各种用例。
In this article, we will look at removing duplicate data from excel using the Python.
在本文中,我们将研究使用Python从excel中删除重复数据。
快速概述删除Microsoft Excel中的重复行 (A quick recap of removing duplicate rows in Microsoft Excel)
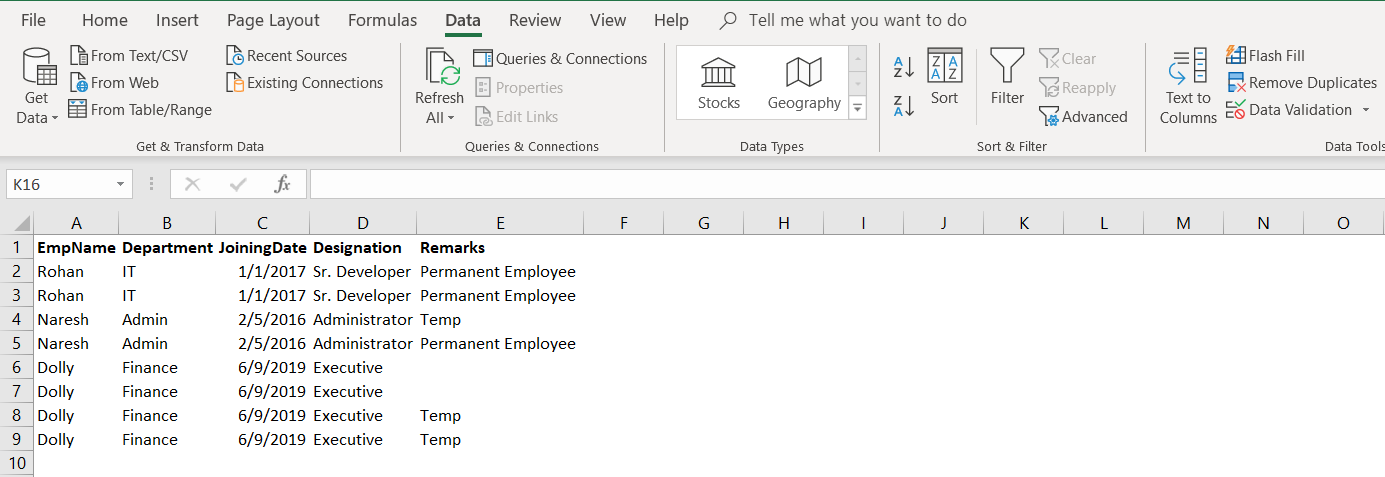
Suppose we have the following data in an excel sheet. We want to get rid of duplicate values in this sheet.
假设我们在excel工作表中有以下数据。 我们希望摆脱此工作表中的重复值。
In Microsoft Excel, we use the Remove Duplicates button from the Data menu. This option checks duplicate values and retains the FIRST unique value and removes other values.
在Microsoft Excel中,我们使用“数据”菜单中的“ 删除重复项”按钮。 此选项检查重复值,并保留第一个唯一值并删除其他值。
Let’s click on Remove Duplicates and select all columns.
让我们单击“删除重复项”并选择所有列。
Click ok, and it removes the duplicate values 3 duplicate values and retains 5 unique values.
单击确定,它将删除重复值3个重复值并保留5个唯一值。
We have the following data after removing duplicates from this.
从中删除重复项后,我们得到以下数据。
Suppose you are working in excel using Python language. If that excel contains duplicate values, we might not want to use Excel functionalities for it. Our script should be capable of handling such duplicate data and remove per our requirements such as remove all duplicates, remove all but the last duplicate, remove all but first duplicate.
假设您正在使用Python语言在excel中工作。 如果该excel包含重复值,则我们可能不想为其使用Excel功能。 我们的脚本应具有处理此类重复数据的能力,并能够按照我们的要求进行删除,例如删除所有重复项,删除除最后一个重复项之外的所有副本,删除除第一个重复项之外的所有副本。
Let’s look at the Python way of handling duplicate data in excel.
让我们看一下在excel中处理重复数据的Python方法。
用于在Excel中删除重复项的Python脚本 (Python scripts for removing duplicates in an excel)
Before we start with Python, make sure you run through the pre-requisites specified in the article, Python scripts to format data in Microsoft Excel.
在开始使用Python之前,请确保您已完成文章Python脚本中指定的先决条件, 以在Microsoft Excel中格式化数据 。
Launch SQL Notebook in Azure Data Studio and verify pandas, NumPy packages existence. You can click on Manage Extensions in Azure Data Studio for it.
在Azure Data Studio中启动SQL Notebook,并验证熊猫,NumPy包是否存在。 您可以为此单击Azure Data Studio中的“管理扩展”。

Once you click on Manage Packages, it gives you a list of installed packages. Here, we can see both pandas and NumPy package along with pip utility.
单击“管理软件包”后,它将为您提供已安装软件包的列表。 在这里,我们可以看到pandas和NumPy软件包以及pip实用程序。
We use the pandas read_excel() function to import an excel file. Create a new code block in SQL Notebook and execute the code. Here, the print statement prints the data frame that consists of excel sheet data.
我们使用pandas read_excel()函数导入一个excel文件。 在SQL Notebook中创建一个新的代码块并执行代码。 在这里,打印语句将打印由excel工作表数据组成的数据框。
First, we import the pandas library to read and write the excel sheets.
首先,我们导入pandas库以读写excel表格。
In this data, few columns contain NaN in the remarks column. Python display NaN for the cells that do not have any value/text.
在此数据中,很少有列在“备注”列中包含NaN。 Python对没有任何值/文本的单元格显示NaN。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
print(data)
In the output, we also see index values for individual rows. The first row starts with index id 0 and increments by 1 with each new row.
在输出中,我们还可以看到各个行的索引值。 第一行以索引ID 0开始,每增加新行,索引号就增加1。

We use drop_duplicates() function to remove duplicate records from a data frame in Python scripts.
我们使用drop_duplicates()函数从Python脚本中的数据框中删除重复的记录。
Python脚本中drop_duplicates()的语法 (Syntax of drop_duplicates() in Python scripts )
DataFrame.drop_duplicates(subset=None, keep=’first’, inplace=False)
DataFrame.drop_duplicates(subset = None,keep ='first',inplace = False)
- Subset: In this argument, we define the column list to consider for identifying duplicate rows. If it considers all columns in case, we do not specify any values 子集 :在此参数中,我们定义要考虑的列列表以标识重复的行。 如果考虑所有列以防万一,我们不指定任何值
- Keep: Here, we can specify the following values: Keep :在这里,我们可以指定以下值:
- First: Remove all duplicate rows except the first one 第一:删除除第一行外的所有重复行
- Last: Remove all duplicate rows except the last one 最后:删除除最后一行以外的所有重复行
- False: Remove all duplicate rows False:删除所有重复的行
- Inplace: By default, Python does not change the source data frame. We can specify this argument to change this behavior Inplace :默认情况下,Python不会更改源数据框架。 我们可以指定此参数来更改此行为
示例1:使用不带任何参数的drop_duplicates() (Example 1: Use drop_duplicates() without any arguments)
In the following query, it calls drop.duplicates() function for [data] dataframe.
在以下查询中,它为[data]数据帧调用drop.duplicates()函数。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
#print(data)
data.drop_duplicates()
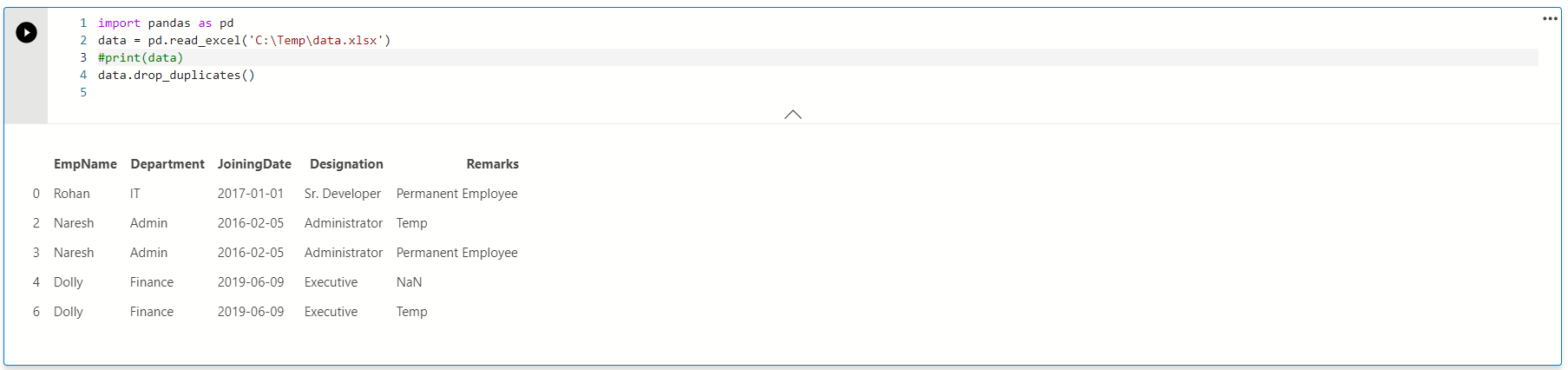
In the output, we can see that it removes rows with index id 1,5 and 7. It is the default behavior of the drop_duplicate() function. It retains the first value and removes further duplicates.
在输出中,我们可以看到它删除了索引ID为1,5和7的行。这是drop_duplicate()函数的默认行为。 它保留第一个值,并删除其他重复项。
示例2:将drop_duplicates()与列名一起使用 (Example 2: Use drop_duplicates() along with column names)
By default, Pandas creates a data frame for all available columns and checks for duplicate data. Suppose, we want to exclude Remarks columns for checking duplicates. It means if the row contains similar values in the rest of the columns, it should be a duplicate row. We have few records in our excel sheet that contains more duplicate values if we do not consider the remarks column.
默认情况下,Pandas为所有可用列创建一个数据框并检查重复数据。 假设我们要排除“备注”列以检查重复项。 这意味着如果该行在其余各列中包含相似的值,则它应该是重复的行。 如果我们不考虑“备注”列,则excel工作表中的记录很少,其中包含更多重复值。
In the following Python scripts, we specify column names in the subset argument. Pandas check for these columns and remove the duplicate values. It excludes the remarks column in this case.
在以下Python脚本中,我们在subset参数中指定列名称。 熊猫检查这些列并删除重复的值。 在这种情况下,它不包括“备注”列。
示例2a:Keep =“ first”参数 (Example 2a: Keep=” first” argument)
We also specify another argument keep=first to instruct Python to keep the first value and remove further duplicates. It is the default behaviors so that we can exclude this parameter here as well.
我们还指定了另一个参数keep = first来指示Python保留第一个值并删除其他重复项。 这是默认行为,因此我们也可以在此处排除此参数。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="first")
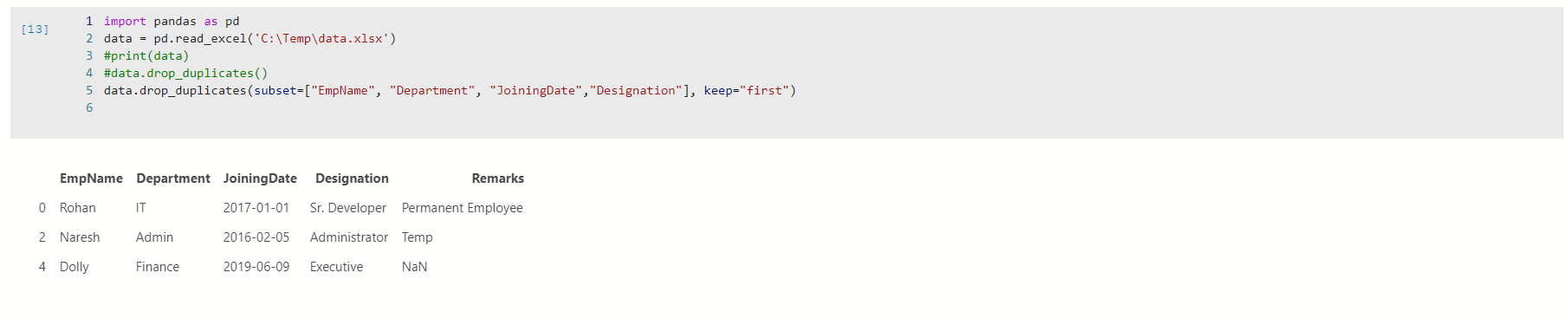
Look at the output, and we have only three records available. It removed all duplicate rows for the specified columns. We have rows with index id 0,2 and 4 in the output by using the first value in keep argument.
查看输出,我们只有三个记录。 它删除了指定列的所有重复行。 通过使用keep参数的第一个值,我们在输出中具有索引ID为0、2和4的行。
示例2b:Keep =“ last”参数 (Example 2b: Keep=” last” argument)
We can change the argument keep=last. It keeps the last row from the duplicates and removes previous duplicate rows. Let’s change the argument and view the output.
我们可以更改参数keep = last 。 它保留重复项的最后一行,并删除先前重复的行。 让我们更改参数并查看输出。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="last")
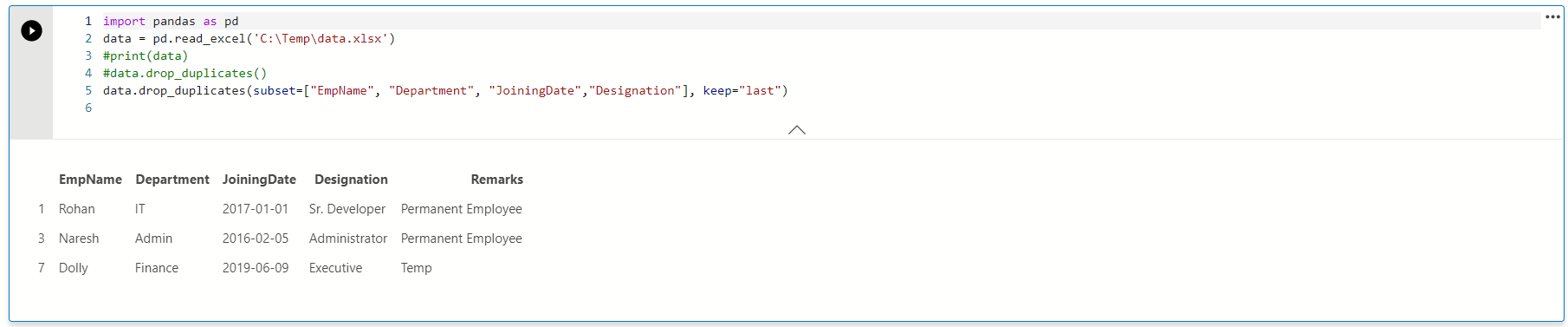
In this case, the output changes and we have rows with index id 1,2,7 in the output.
在这种情况下,输出会发生变化,并且输出中有索引ID为1,2,7的行。
示例2c:Keep =“ false”参数 (Example 2c: Keep=” false” argument)
Previously, we kept either first or last rows and removed other duplicate rows. Suppose we want to remove all duplicate values in the excel sheet. We can specify value False in the keep parameter for it.
以前,我们保留第一行或最后一行,并删除其他重复的行。 假设我们要删除excel工作表中的所有重复值。 我们可以在keep参数中为其指定值False。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep="False")
If we execute the above Python Script, we get the following error message.
如果执行上述Python脚本,则会收到以下错误消息。
ValueError: keep must be either “first”, “last” or False
ValueError:keep必须为“ first”,“ last”或False
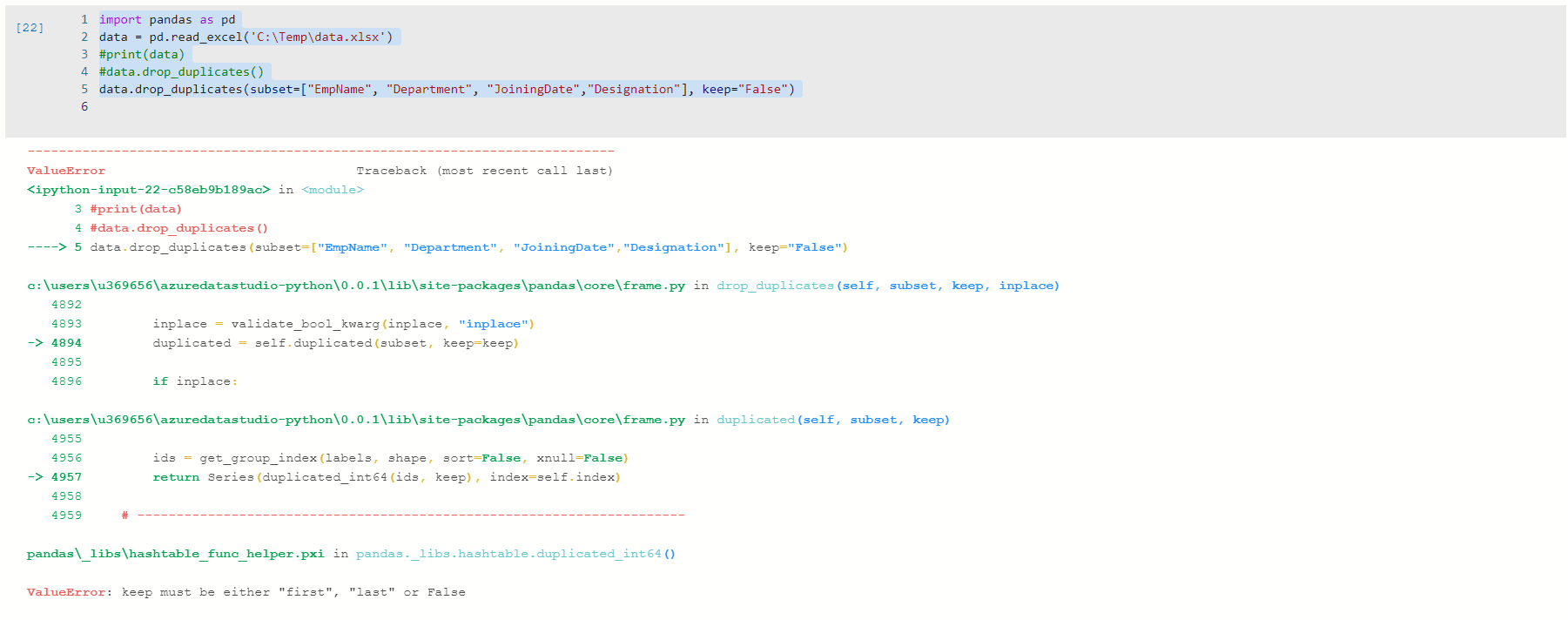
For the first and last value, we use double-quotes, but we need to specify False value without any quotes. Let’s remove the quote and execute the code.
对于第一个和最后一个值,我们使用双引号,但是我们需要指定不带任何引号的False值。 让我们删除引号并执行代码。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False)
In the output, we do not get any row because we do not have any unique rows in the excel sheet.
在输出中,我们没有得到任何行,因为我们在excel工作表中没有任何唯一的行。

To test the above code, let’s add a new row in the excel and execute the above code. We should get the row in the output. The script works, and we get unique rows in the output.
为了测试上面的代码,让我们在excel中添加新行并执行上面的代码。 我们应该在输出中获得该行。 该脚本有效,并且在输出中获得唯一的行。

示例3:通过保留最大值和最小值来删除重复项 (Example 3: Remove duplicates by keeping the maximum and minimum value)
Now, suppose we have a new column Age in the excel sheet. Someone has entered the wrong age for the employees. We want to remove the duplicate values but keep the row that has maximum age value for an employee. For example, Rohan has two entries in this sheet. Both rows look similar; however, one row shows age 22 while another row has age value 23. We want to remove the row with a minimum age. In this case, the row with age 22 for Rohan should be removed.
现在,假设我们在excel表中有一个新列Age。 有人为员工输入了错误的年龄。 我们要删除重复的值,但保留具有员工最大年龄值的行。 例如,Rohan在此工作表中有两个条目。 这两行看起来相似; 但是,一行显示年龄22,另一行显示年龄值23。我们要删除年龄最小的行。 在这种情况下,应删除Rohan年龄22岁的行。
For this requirement, we use an additional Python script function sort_values(). In the following code, we sort the age values in ascending order using data.sort_values() function. In the ascending order, data is sorted from minimum to maximum age so we can keep the last value and remove other data rows.
为此,我们使用了额外的Python脚本函数sort_values()。 在以下代码中,我们使用data.sort_values()函数对年龄值进行升序排序。 按照升序排列,数据从最小年龄到最大年龄进行排序,因此我们可以保留最后一个值并删除其他数据行。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
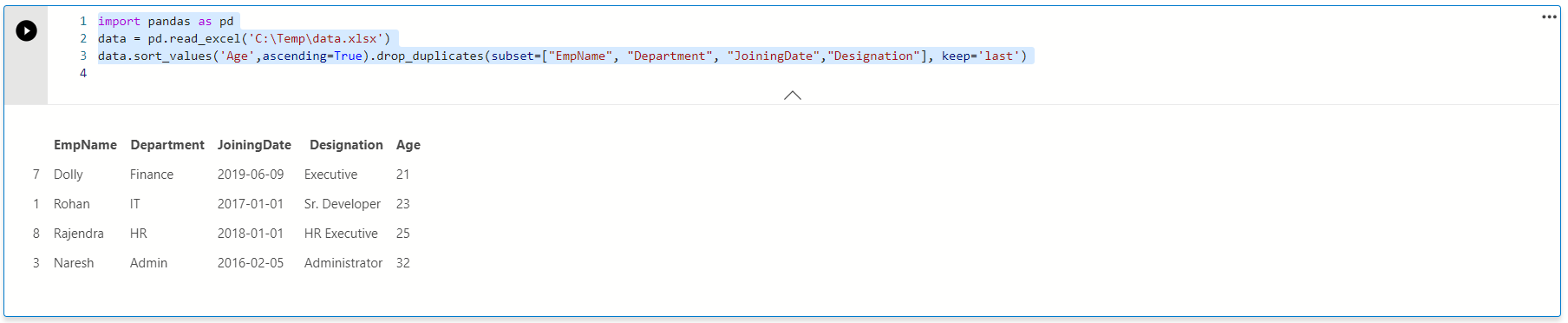
data.sort_values('Age',ascending=True).drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep='last')
In the output, we can see it has rows with maximum age for each employee. For example, Rohan shows age 23 that is the maximum age available from both records.
在输出中,我们可以看到每个员工的行都有最大年龄。 例如,罗汉(Rohan)显示年龄23,这是两个记录中可用的最大年龄。
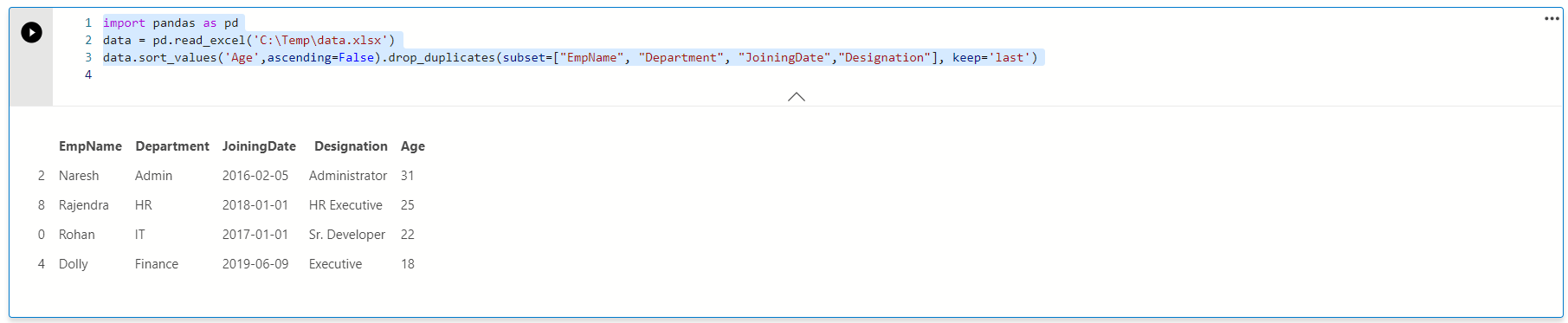
Similarly, we can change the data sort in descending order and remove the duplicates with minimum age values.
同样,我们可以按降序更改数据排序,并删除具有最小年龄值的重复项。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.sort_values('Age',ascending=False).drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep='last')
示例4:使用inplace参数的drop_duplicate()函数 (Example 4: drop_duplicate() function using inplace argument )
By default, Pandas returns a new data frame and does not changes the source data frame. We can specify the argument inplace=True, and it changes the source data frame also.
默认情况下,Pandas返回一个新的数据框,并且不更改源数据框。 我们可以指定参数inplace = True,它也会更改源数据帧。
Execute the following query and call the data frame in the end; it returns the content of the source data frame.
执行以下查询,最后调用数据框; 它返回源数据帧的内容。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False,inplace = False)
data
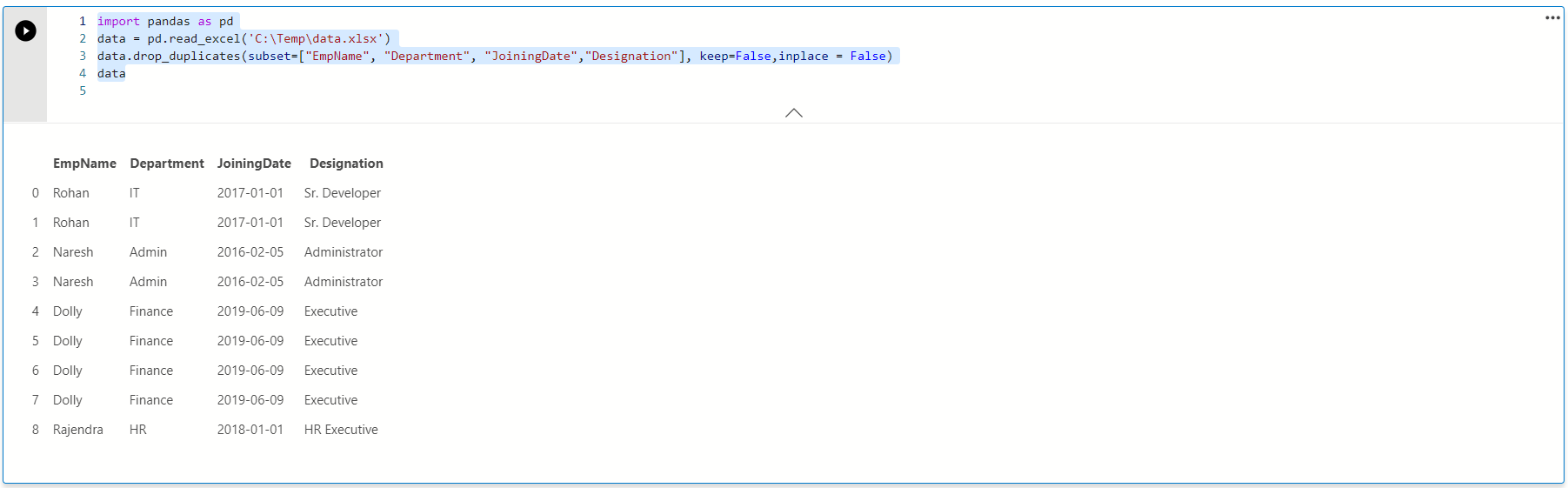
Let’s change the default value of inplace argument and view the change in the output.
让我们更改inplace参数的默认值,并查看输出中的更改。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
data.drop_duplicates(subset=["EmpName", "Department", "JoiningDate","Designation"], keep=False,inplace = True)
data

使用自定义颜色代码突出显示重复的值 (Highlight duplicate values with custom color codes)
In many cases, we just want to check the duplicate data instead of removing it. Instead, we require to highlight the duplicate values and send them to the appropriate team for correction. It might be feasible in case we are receiving data from a third party.
在许多情况下,我们只想检查重复的数据而不是删除它们。 相反,我们需要突出显示重复的值,并将其发送给适当的团队进行更正。 如果我们正在从第三方接收数据,这可能是可行的。
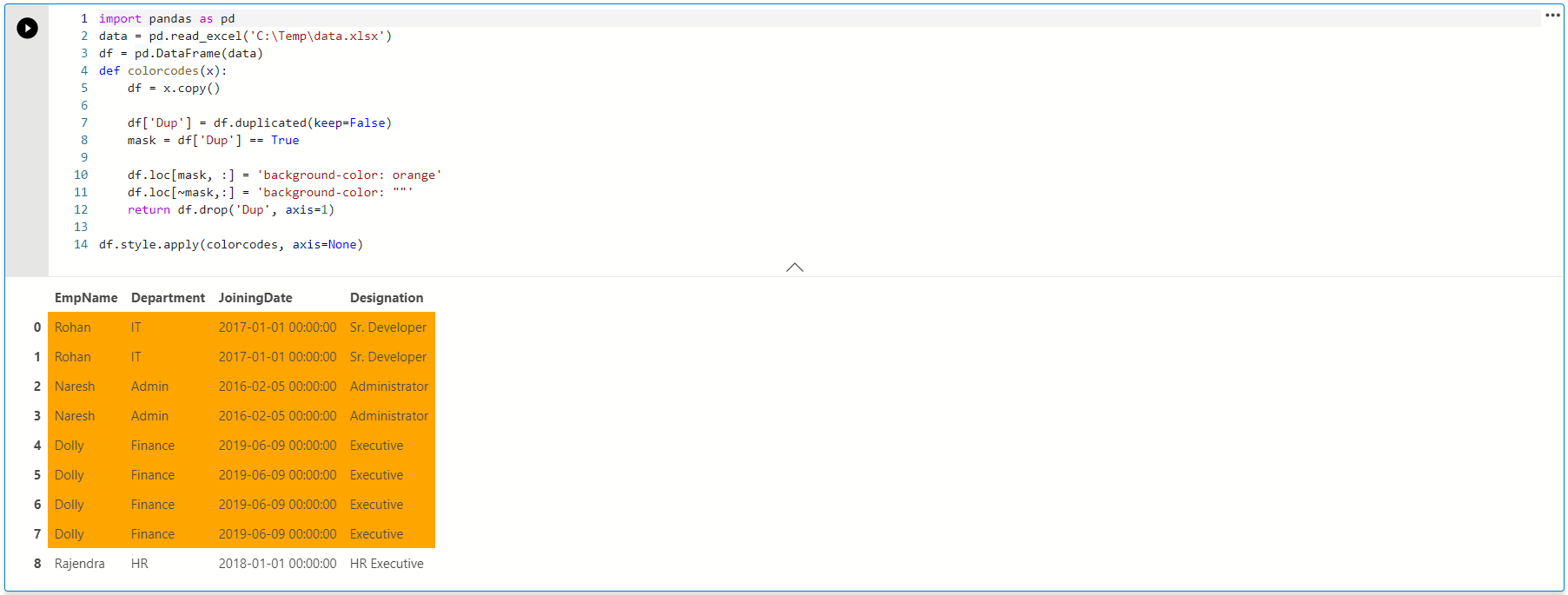
We can use conditional formatting and give a visual style ( color coding ) to duplicate rows. In the following code, we define a Python script function to highlight duplicate values in the orange background color. We will cover more about conditional formatting in upcoming articles.
我们可以使用条件格式,并给出视觉样式(颜色编码)来复制行。 在下面的代码中,我们定义一个Python脚本函数以橙色背景色突出显示重复的值。 我们将在后续文章中介绍有关条件格式的更多信息。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
df = pd.DataFrame(data)
def colorcodes(x):
df = x.copy()
df['Dup'] = df.duplicated(keep=False)
mask = df['Dup'] == True
df.loc[mask, :] = 'background-color: orange'
df.loc[~mask,:] = 'background-color: ""'
return df.drop('Dup', axis=1)
df.style.apply(colorcodes, axis=None)
It gives us the following output, and we can easily interpret which rows contain duplicate values. It is useful, especially when we have a large number of rows. We cannot go through each row in this case, and color-coding helps us to identify the duplicate values.
它提供了以下输出,并且我们可以轻松地解释哪些行包含重复值。 这很有用,尤其是当我们有很多行时。 在这种情况下,我们无法遍历每一行,而颜色编码可帮助我们识别重复的值。
Alternatively, we can use further functions such as GROUPBY and count the duplicate rows.
或者,我们可以使用其他功能(例如GROUPBY)并计算重复的行。
import pandas as pd
data = pd.read_excel('C:\Temp\data.xlsx')
df = pd.DataFrame(data)
df.groupby(df.columns.tolist(),as_index=False).size()
If any row count is greater than 1, it is a duplicate row. In the following output, we can note than Dolly appeared 4 times in the excel sheet which means it is a duplicate row. Rajendra does not contain any duplicate row, so its count is 1 in the output.
如果任何行计数大于1,则为重复行。 在以下输出中,我们可以注意到Dolly在excel表中出现了4次,这意味着它是重复的行。 Rajendra不包含任何重复的行,因此在输出中其计数为1。

结论 (Conclusion)
In this article, we explored the process to remove duplicate rows in an Excel sheet using Python scripts. I liked the way to deal with Excel files using Python. We will cover more useful scripts in the upcoming articles. Stay tuned!
在本文中,我们探讨了使用Python脚本删除Excel工作表中重复行的过程。 我喜欢使用Python处理Excel文件的方法。 我们将在后续文章中介绍更多有用的脚本。 敬请关注!
翻译自: https://www.sqlshack.com/removing-duplicates-in-an-excel-sheet-using-python-scripts/

















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









