







最近用excel在单列进行去重,数据大于2W时候,卡的的不行,也达不到我最终想要的结果(大概率excel水平太渣导致…)所以只能靠python pandas来救命了,直接上例子
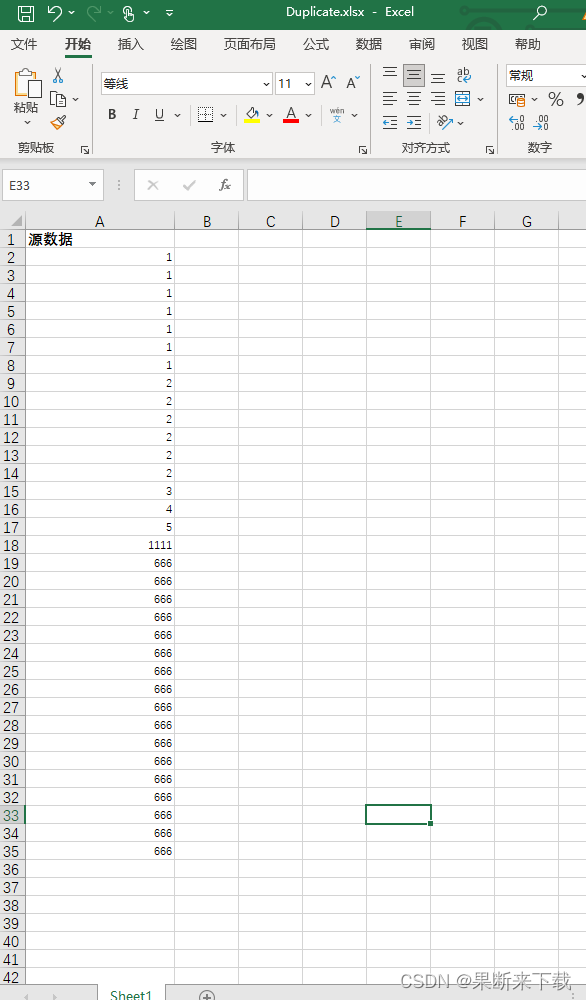
首先准备好一个包含重复数据excel表格
然后我们可以看见文件里面包含一些重复的数据…
然后上“热菜”直接可用代码
下面展示一些 内联代码片。
import pandas as pd
import os
# 检查文件是否存在
file_path = 'Duplicate.xlsx' # 你的excel,放在py文件相同目录
if not os.path.exists(file_path):
raise FileNotFoundError('文件不存在')
# 读取Excel文件
df = pd.read_excel(file_path)
# 筛选出第一列中不重复的数据
non_duplicate_data = df.iloc[:, 0].drop_duplicates().reset_index(drop=True)
# 创建一个与筛选后的数据长度一致的新列,并将筛选后的数据赋值给新列
df['new_column'] = non_duplicate_data
# 保存修改后的新生成Excel文件
df.to_excel('data_modified.xlsx', index=False)
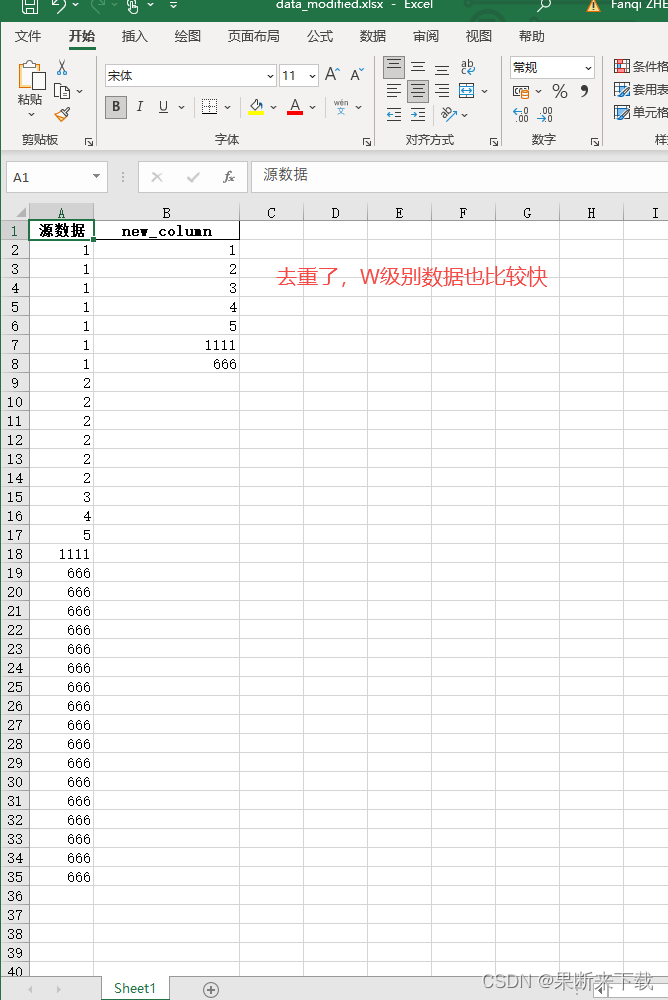
然后我们看下效果















 1948
1948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









